利用Apriori算法实现变电站二次系统故障诊断
2021-12-10王鸣誉李铁成任江波
王鸣誉,李铁成,任江波,徐 岩
(1.华北电力大学电气与电子工程学院,保定 071003;2.河北省电力有限公司电力科学研究院,石家庄 050021;3.河北省电力有限公司,石家庄 050021)
智能变电站二次系统故障诊断主要凭借检修人员的经验,同时由于二次回路存在不可视的虚回路[1],虚回路中的数据通过光纤传输,这种隐蔽的数据传输方式导致很多情况下故障无法精确定位。同时虚回路由于存在交叉重叠,当某一元件在出现故障时可能会引起多个回路出现故障[2]。以往凭借经验判断的方法更加难以使用。
文献[3]介绍了一种基于拓扑结构生成的知识表示方法,该系统可以用来处理分布式变电站的多重故障,虽然直观有效,但由于不易补充完善,因此该方法的自学习能力差;文献[4-5]根据装置的自检信息,利用D-S证据理论,得出每个装置的故障概率,但这种方法需要在故障诊断时列出所有的二次回路,形成举证表,寻找每一个回路中的可疑故障元件,除此之外,在计算某装置的故障概率时还需要针对每一个不同的告警信息列出所有可疑装置的发生故障的概率,大大增加了故障诊断所需要的时间;文献[6]提出了一种基于故障树的诊断方法,其主要原理是以某一系统的故障树图为基础,求取最小割集和它的可靠性估计方差,优先改善每个组成单元中影响最大的部分;也可与Petri网结合[7],但是由于其方法需要找寻最优解,因此求解速度会受到一定影响;文献[8]利用神经网络实现了对二次系统故障的诊断,但由于需要的样本量太大,因此在搜集数据时存在较大的难度。
除了上述方法,现阶段关联分析也被用于分析二次系统的状态,但用在故障诊断方面的并不多。文献[9]将Apriori算法用以解决二次设备缺陷问题,并且证明了该方法简单可靠。综上所述,本文提出了一种利用Apriori算法实现变电站二次系统故障诊断的方法,建立了以关联规则为基础的二次故障诊断模型,并通过算例说明了Apriori算法可以根据二次系统运行数据得出二次系统故障类型以及故障装置。该方法只需要通过对历史数据进行分析,而故障诊断时不需要每次都对二次回路可疑的元件进行统计处理,因此该算法简单有效,可以缩短诊断时间,还具备不错的自学习能力。
1 关联规则及Apriori算法原理
1.1 关联规则的基本概念
关联分析通常用来找出某事物与某事物之间的隐藏关系,这个隐藏关系可用关联规则来表示。关联规则大致是用数据挖掘的手段找出不同事物之间的关联关系,以便了解事物之间的机理,最终实现对事物的预测及分析。
最常见的关联规则是“啤酒-尿布”案例,因为男士在给婴儿购买尿布的时候通常会选择同时购买几瓶啤酒,因此如果将这二者放在一起,那么顾客会乐于购买,其中的“啤酒”、“尿布”二者便存在关联关系。
对于关联分析这类算法,通常人们定义所含元素各不相同的集合为项集,其中元素个数称为项集的长度,记作k,该项集称为k-项集,用于关联分析的样本称为样本集,样本集是项集的子集。
文中用来衡量关联分析结果好坏的指标是支持度和置信度,支持度的含义是指发生某类事务的概率。置信度是指关联规则的可信程度,它表示的是某一种项集在包含另一种项集的事务中出现的次数。从统计学上讲,置信度也就是B在A发生的情况下发生的概率。
支持度s和置信度c的计算公式分别为
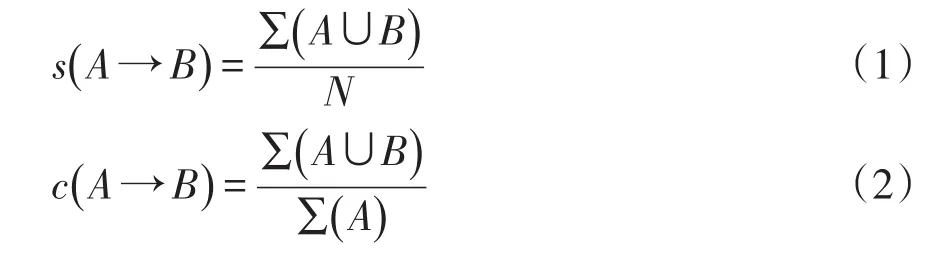
式中:A、B为挖掘出的项集个数;N为总项集数。
通常把支持度所要满足的最低值称为最小支持度,而置信度需要满足的最低值称为最小置信度。当某一个项集的支持度满足要求时,这个项集就是频繁项集。当某一规则同时满足这两者的要求时,被称作强关联规则。
1.2 Apriori算法的基本原理
Apriori的思想是在符合要求的候选项集中逐层搜索,最终生成最多项的频繁项集[10]。然后从结果中寻找关联规则,具体步骤如下。
步骤1扫描一遍全体数据,求出所有1-项集的支持度,依据指标要求对其进行筛选。将满足条件的1-项集留下。
步骤2连接。连接上一步中生成的1-项集,生成2-项集集合,此集合中由所有符合条件的1-项集组成。
步骤3剪枝。通过扫描该2-项集中的每一个事物确定所有事物的支持度,剪去所有不符合要求的子集。保留所有满足条件的2-项集。值得一提的是,当某集合中某项的某子集不符合支持度筛选要求的时候,就可以认定该项也不符合要求。也就是说,在剪枝步骤中剪去的集合,它们的超集一定不符合要求。由此,给后续步骤奠定基础。
步骤4将上述所有2-项集与1-项集再次使用上述两步操作,循环往复,生成集合Ck-1。
步骤5删除最终生成的集合Ck-1中所有不满足要求的项集。根据上述的剪枝步骤,逐步筛选,然后再经过连接步骤,生成集合Ck,该集合经筛选后没有不符合要求的子集,即Ck集合为生成的最大项集。
Apriori算法流程如图1所示。

图1 Apriori算法流程Fig.1 Flow chart of Apriori algorithm
在关联规则挖掘过程中,可能会遇到原因→故障的情况,也有可能会遇到故障→故障的情况,因此在创建故障特征信息数据库时,需要对数据进行一定的处理。本文将故障原因设置分类编号1,将变电站二次系统检测信息分类为2,从检修报告中筛选出这些数据,同时只挖掘1→2的关联规则,这样可以避免挖掘同类事物。
除了上述支持度和置信度的参数外,还引入了提升度[11]这个指标概念。提升度是指A项和B项一同出现的频率,其表达式为
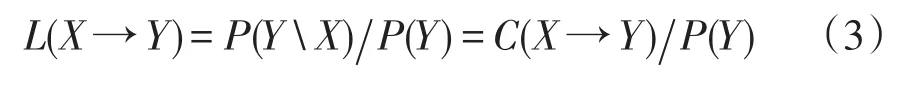
式中:L为提升度;P为某一项出现的概率;C为置信度;X和Y为项集。
提升度反映了两个变量的相关度,通常认为提升度越高,二者正相关性越明显。以1为界,当提升度为1时,二者并无相关性。
在结果中移除部分不符合提升度要求的个例,如线路保护采样值SV(sampled value)告警→合并单元DSP故障。当故障发生在合并单元DSP模块时,该模块会发出采样报警,与此同时保护装置也会发出SV告警。因此,虽然由线路保护SV告警→合并单元DSP故障关联规则计算出来的置信度符合要求,但是在分析中随着线路保护SV告警数据出现次数的提高,合并单元DSP故障的数据并无明显增长趋势,也就是说,二者之间并无直接关系,因此这种关联规则并不可靠。
2 二次系统故障模型的构建
2.1 二次故障回路的建立
智能变电站中,二次设备通常具有自检和报文功能[12-13]。自检信息主要包括装置自身的采样值、开关量信息以及装置自身软件和硬件的检测信息等。报文主要指SV和GOOSE(generic object-orient⁃ed substation event),其中,GOOSE报文是面向通用对象的变电站事件,包含智能电子设备之间的信息;SV报文主要是按照一定的采样率将同步采样的数字化信息进行定期传送。在故障诊断时,需要重点记录二次设备的自检报警信息以及网络报文的异常告警信息。
对于二次系统故障分析对象的选取,本文根据实际变电站的运行情况以及故障的获取方法[14-15],选择分析的对象为合并单元、智能终端和保护测控装置以及连接它们的光缆构成的系统。
在智能变电站中,由于虚回路与物理回路这两者之间难以一一对应[16-17],因此,在诊断故障之前需要先找到虚回路对应的物理回路,在智能站中,二次系统配置依赖于含有虚回路和端子对应关系[18]的变电站配置描述SCD(substation configuration de⁃scription)文件。本文利用SCD文件中的Port、Ca⁃ble、intAddr字段[19]来实现二次回路的构建。SCD文件中的Port字段和Cable字段分别记录了本侧物理端口和连接这个端口的光纤的信息,当2个物理端口的Cable字段相同时表明二者是通过光纤连接的,而intAddr字段记录了虚端子对应的物理端口,因此可以根据intAddr字段找到虚端子对应的物理端口信息。
结合Apriori算法,二次系统的故障诊断流程如下。
步骤1利用SCD文件列出虚实回路映射表;
步骤2记录发生故障时的特征信息;
步骤3利用Apriori对历史数据进行关联分析;
步骤4筛选符合要求的关联规则;
步骤5检修人员从结果中筛选出置信度较大者,进行重点排查。
2.2 故障数据库的建立
本文的数据是根据调度系统D5000以及相关的检修报告提取的,包括故障发生的时间、具体的厂站、发生故障时的告警内容及发生故障的实际装置。将这些不同来源、不同类型的数据经过抽取、处理后得到数据库模型,其故障数据如表1所示。

表1 故障数据Tab.1 Fault data
表1中,报警信号以及故障装置这两种数据的记录方式是自然语言,由于现有的技术还不够成熟,因此这两种数据需要人工配置编码来进行解析。在进行数据挖掘时,将同一次记录下的报警信号和故障装置合并成一个集合(合并单元SV告警,合并单元自检告警,合并单元),而在进行关联分析前,再把它们分解成独立的元素。在求取关联规则时,本文重点寻找报警信号与故障装置之间的关系。除此之外,还统计了故障设备的故障频率。
3 算例分析
首先对某市某110 kV智能变电站的SCD文件进行解析,得到该变电站的二次系统回路,并以线路保护为例进行分析。继电保护物理二次回路如图2所示。
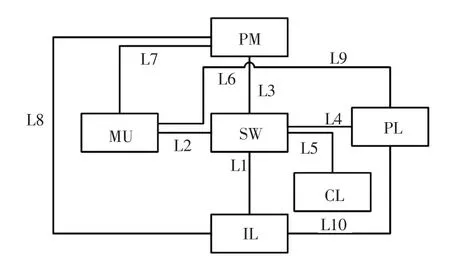
图2 继电保护物理二次回路Fig.2 Secondary circuit of relay protection
图2中PM为母差保护,SW为交换机,PL为线路保护,MU为合并单元,CL为线路测控装置,IL为线路保护的智能终端。
该变电站的虚实回路映射如表2所示。

表2 虚实回路映射Tab.2 Mapping between virtual and real circuits
在挖掘故障类型时将故障的特征信息和诊断结果作为特征量,对于不同类型的故障进行故障频繁项挖掘。在分析过程中,由于某些故障在数据库中出现次数不多,因此在挖掘故障频繁项集的过程中不宜将支持度设置过高,设置支持度为1%。各故障装置支持度如图3所示。在分析故障之前,首先使用Apriori算法统计出现发生故障最多的部位,筛选了部分频繁项集。
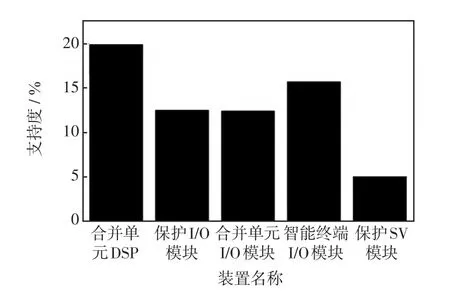
图3 各故障装置支持度Fig.3 Support degree of each fault device
除此之外,还要寻找故障报警信号和故障类型之间的关联关系,置信度阈值设为10%,筛选出符合要求的规则,然后再经过提升度的筛选,只筛选提升度大于2的关联规则。本文列举出部分置信度较高的强关联规则,如表3所示,表中的数据可以为检修人员提供参考。检修人员可以根据系统发出告警信号时,对二次系统发出的告警信号进行查询,将结果一一印证,最终找出故障原因。

表3 部分强关联规则Tab.3 Part of strong association rules
上述关联规则的置信度较高,均大于50%,同时具备较高的支持度,因此它们具有一定的代表性,可以作为故障诊断的依据。
在故障分析时,可以利用历史数据来进行关联分析,将报警信号作为条件,将关联规则中的后项集作为结果,便可得到诊断的结果。其中置信度越高,推测出的结论越可靠。
算例1:当该站发生保护拒动时,二次系统出现如下告警信息:智能终端GOOSE告警、保护装置GOOSE告警、智能终端通信异常。
利用历史数据进行数据挖掘,在上述3种前提条件下关联规则的置信度和提升度如图4所示。
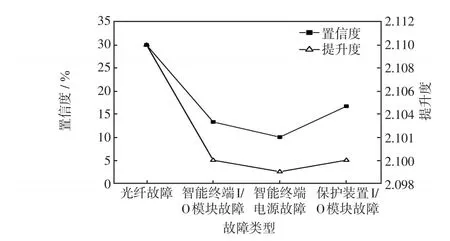
图4 算例1的置信度和提升度Fig.4 Confidence coefficient and improvement degree in Example 1
由图4可见,当关联规则前提条件为智能终端GOOSE告警、保护装置GOOSE告警、智能终端通信异常的情况下,光纤故障的关联规则置信度最高,即最有可能发生该故障的装置为连接智能装置与保护装置的光纤。运行维护人员应该重点检查该光纤,如果情况属实,应该立刻对其进行维修或者将其替换。
算例2:当该站发生某次保护拒动时,二次系统发出如下报警信号:合并单元装置异常告警、SV告警,保护装置SV告警。
将上述3种报警信号与关联分析后的结果进行对比,置信度和提升度如图5所示。
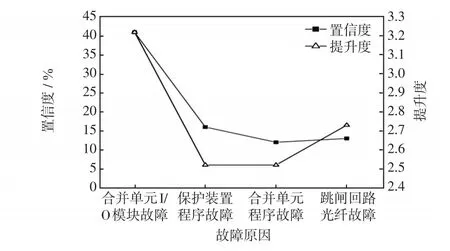
图5 算例2置信度和提升度Fig.5 Confidence coefficient and improvement degree in Example 2
从分析结果图5可以看出,最有可能发生故障的装置是合并单元I/O模块,也就是图2中合并单元与保护装置相连接的部分,其他装置发生故障的置信度都小于它,因此维修人员应该重点检查合并单元。
通过上述2种算例的结果,可以证明,本文提出的方法简单有效,不必依靠虚回路模型,只用将报警信息与历史数据的关联分析结果进行对比即可。
4 结语
本文提出了一种基于Apriori算法的变电站二次系统诊断模型,通过该算法生成的关联规则可以作为诊断结果,给二次系统检修人员提供参考依据和建议。该方法在处理故障报警信号时,不用对某个具体的二次回路进行分析,只需利用历史数据便可以得到关联规则,因此该方法不仅简单有效,而且诊断迅速。
