基于无监督聚类和频繁子图挖掘的电力通信网缺陷诊断与自动派单
2021-12-10吴季桦朱鹏宇吴子辰顾彬洪涛郭波王晶王敬宇
吴季桦,朱鹏宇,吴子辰,顾彬,洪涛,郭波,王晶,王敬宇
基于无监督聚类和频繁子图挖掘的电力通信网缺陷诊断与自动派单
吴季桦1,朱鹏宇2,吴子辰3,顾彬3,洪涛3,郭波3,王晶1,王敬宇1
(1. 北京邮电大学网络与交换国家重点实验室,北京 100876;2. 国网电力科学研究院有限公司,江苏 南京 210012;3. 国网江苏省电力有限公司信息通信分公司,江苏 南京 210024)
缺陷诊断一直是电力通信领域研究的难点之一。基于人工规则的缺陷诊断已经无法应对告警数据的海量增长。基于有监督学习的智能方法需要大量的标注数据和较长的系统构建时间,且大多面向指标性数据,实现部署缺乏可行性。面向告警数据,提出一种基于无监督聚类和频繁子图挖掘实现告警归并和缺陷模式发现的自学习算法,设计了一个自动化完成缺陷诊断及处置的架构。该架构具有良好的可扩展性和迭代更新能力,并部署于实际缺陷自动派单系统中。通过真实场景数据集进行实验验证,结果显示出良好的性能表现,实现了对缺陷的及时发现及精准派单维护。
电力通信;缺陷诊断;无监督聚类;频繁子图挖掘
1 引言
电力通信网中的海量告警数据显示了网元设备的健康状态以及网元设备间的交互情况。面向告警的缺陷诊断方法先对告警进行告警归并,基于得到的告警归并集合,进一步进行缺陷检测和缺陷定位。
目前国内外主要使用基于规则匹配的方法进行告警归并[1]。随着告警数据的海量增长,基于规则匹配的方法及其相关改进方法难以适应当前的数据环境。Madziarz[2]在移动通信网领域提出了基于-means聚类的告警聚类方法,尝试引入无监督聚类以摆脱对规则的依赖。虽然该方法无须大量人力资源的投入,但实际归并效果不理想,且需要业务专家参与预测缺陷的数量,有着极大的局限性。
缺陷诊断分为事件检测和定位。事件检测和定位则基于事件分类。基于人工经验的缺陷诊断方法,主观因素影响较大,并且难以应对指数级增长的海量告警信息。已经有许多研究将人工智能技术运用到电力通信网事件分类和缺陷诊断领域中以摆脱对规则的依赖。人工智能技术应用到缺陷诊断领域时,常针对的是信号等指标性数据,如Wen等[3]利用卷积神经网络(convolutional neural networks,CNN)提取信号的特征,Xiao等[4]利用贝叶斯神经网络以建筑管理系统的测量和人工测试指标作为输入依据,进行变风量通风空调系统的缺陷诊断。这些方法都在各自的数据集上取得了较好的成果。但是电力通信领域缺少大量完整标注的数据,同时,实际的缺陷诊断的主要依据不是指标性的信号数据,而是各个网元上非结构化的告警数据。电力通信网中基于告警完成缺陷诊断的缺陷信息隐藏在告警数据以及其时空关联关系中。
本文在自适应标记筛选及再学习[5]和基于拓扑信息解决时间序列数据异常检测问题[6]的工作基础上,提出了一种基于密度聚类(density-based spatial clustering of applications with noise,DBSCAN)实现告警归并,并且基于频繁子图挖掘(frequent subgraph mining,FSM)完成缺陷模式发现的自学习算法,并设计了一个面向电力通信网告警数据,尽力摆脱对规则的依赖,减轻人力资源投入的自动化缺陷诊断及派单的架构。如图1所示,该算法主要应用于告警归并、缺陷诊断以及自动派单模块,模块间松耦合,具有良好的可扩展性。该算法展现出良好的稳健性,具备迭代更新能力,减少缺陷诊断过程对于人工规则的依赖,并在实验中呈现出良好的结果。
本文的贡献总结如下。
(1)提出了面向告警数据进行数据挖掘,基于无监督聚类和频繁子图挖掘算法完成告警归并以及缺陷诊断,智能化完成缺陷模式发现及识别,自动化完成派单检修,具备迭代更新的自学习能力架构,部署在自动派单系统中,以减轻运维压力,实现对缺陷的及时发现和处置。
(2)考虑基于规则的缺陷诊断方法受到人为因素的制约,基于有监督的学习方法受到缺少大量标注数据进行训练的制约,提出一个基于无监督学习以及数据挖掘的模型,在只有少量标注的情况下实现对缺陷模式的及时发现。
(3)考虑告警归并集合内告警存在时空相关,提出了将告警的文本信息向量化映射到向量空间的方法,使得具有相关关系的告警在向量空间之中彼此接近,并使用无监督聚类方法完成告警归并。
(4)考虑网络场景中发生告警的节点之间的拓扑关系,提出了对告警及其所处节点的拓扑关系进行模式挖掘,利用频繁子图挖掘方法完成缺陷模式发现。
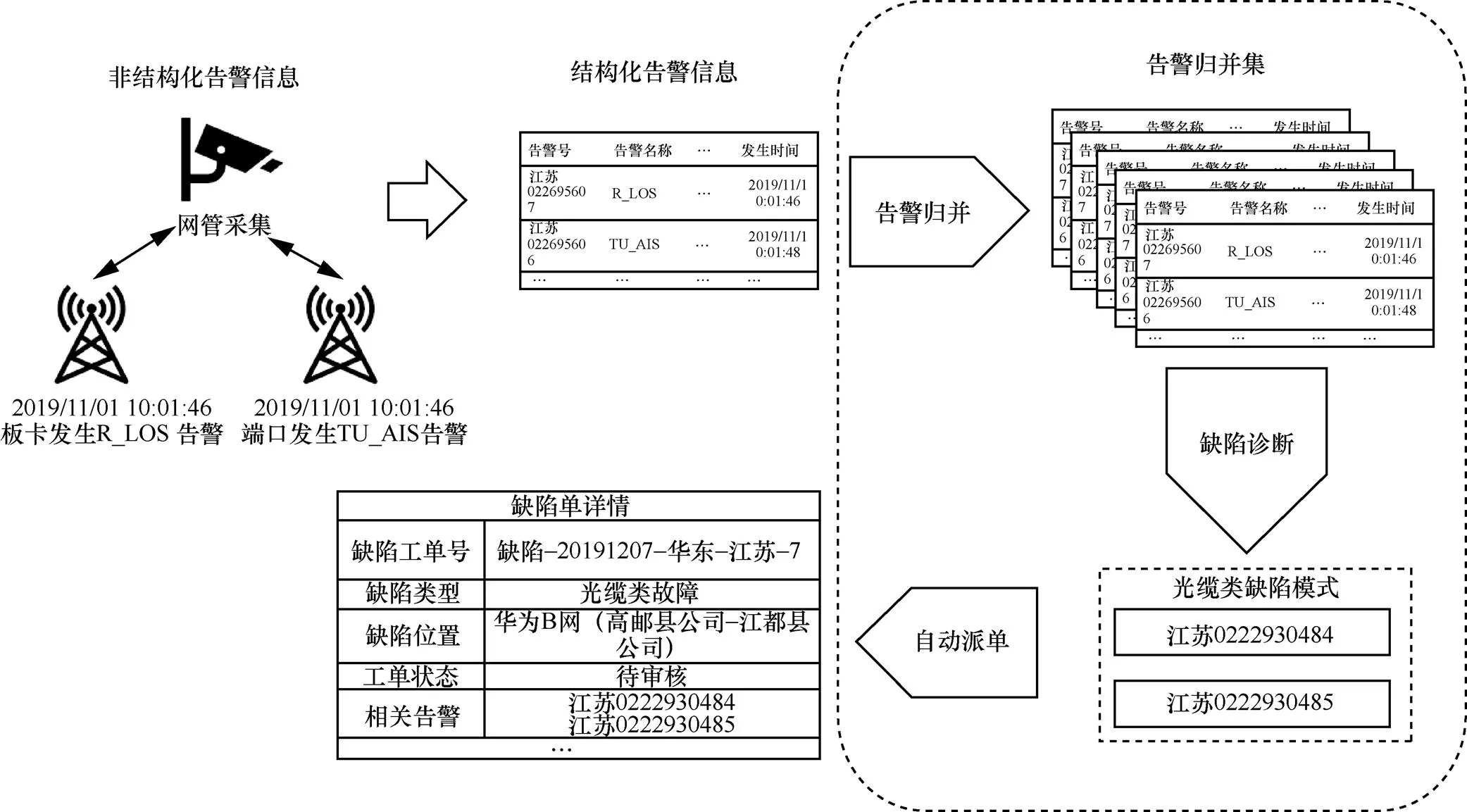
图1 电力通信网的缺陷诊断和自动派单架构
(5)在真实场景数据集上进行实验,结果表明基于无监督聚类和频繁子图挖掘的缺陷诊断方法取得了良好的性能表现。
2 告警归并模块
2.1 告警归并
告警归并是一个概念性的解释:将某些告警根据某种意义相关联。告警归并是以下几种网络管理任务中的一种通用方法[7]:压缩、计数、抑制。电力通信网中的告警归并是为了后续的缺陷诊断服务的。因此本文场景中的告警归并旨在将可能由同一个缺陷导致或者衍生的告警归并在同一个集合当中。在电力通信的生产场景中,运维人员依靠人工经验的积累梳理出告警衍生关系,并以此为依据完成告警归并。但是这意味着,基于规则完成的告警归并主观成分较大,整理的告警衍生关系也可能不完备。
告警归并任务的目标是将可能由同一个缺陷引起的告警关联在一起。同时,在一段连续时间内,一个缺陷可能会引起一个或多个设备持续输出相似告警。基于这两个前提,本文使用无监督学习来协助完成告警归并,采用基于密度的DBSCAN聚类捕获告警簇。
2.2 DBSCAN
DBSCAN算法作为经典的密度聚类算法,其在无监督密度聚类中的得到了广泛的应用。算法将点分类为核心点和非核心点,定义1~定义6描述了该算法[8]。
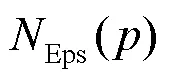
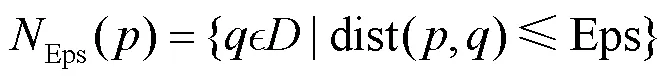
定义2(直接密度可达(directly density- reachable))点被称为从点直接密度可达,当且仅当:
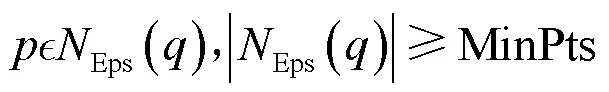
其中,MinPts为给定的使成为核心点的邻域内最小点数。

定义4(密度相连(density-connected))如果点和点都从点密度可达,则称点和点密度相连。
定义5(簇(cluster))对于集合,簇是的一个满足以下条件的子集。
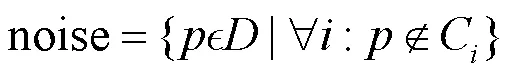
具体而言,在划分簇时,对于给定的边界距离Eps、最小核心节点数MinPts和非空节点集,簇构建时首先检测其密度直达性。首先将核心点中具有密度直达关系的点分类给簇,之后检测相连性,对剩下的点检测其与簇内任意一点的密度相连性,如果密度相连则归入簇。
在分类完成后,对于不属于任何簇的孤立点,将其视为噪声[9]。
2.3 告警归并模块设计
DBSCAN是基于密度的算法,意味着输入的特征应当是对应空间的坐标点,或者是点之间的距离矩阵。在实际背景当中告警是连续的文本信息,因此告警的向量化过程应该体现为特征提取和特征向量之间的权重分配。
本文告警归并的目标对象应当是在时间上相近以及发生设备间有关联关系或者本身其他属性相近的一组告警,也就是DBSCAN聚类的目标是将拥有这些特性的属于同一缺陷的告警聚为一个簇。对告警而言,有两方面的信息较为重要:告警本身的相关参数(如告警种类、发生位置、设备类型、设备位置等)以及告警时间。
其中,告警本身的相关参数反映了告警之间的相关程度以及告警在空间上的相近程度,告警时间是当前告警产生的时间,蕴含了缺陷发生的时间信息。对于告警本身的相关参数,使用One-Hot方法[10]将其映射为特征向量,对于没有制定权重的One-Hot来说,告警之间任意一个特征的差距映射在空间上面距离相同,在DBSCAN算法当中作用相同,而通过调整各个特征的权重可以反映不同特征的重要性。
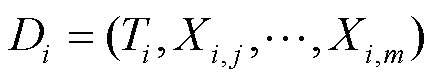

进一步,可以得到:
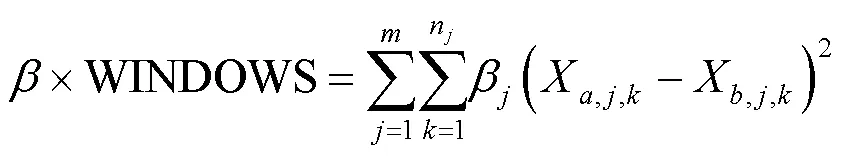
不同样本的距离综合考虑了告警本身相关参数距离和时间距离。以此对所有告警进行聚类,则最后得到的聚类结果应该是使得时间上较为聚集的相似告警或者时间上极为聚集的较相似告警成为同个簇。
基于无监督聚类告警归并模块的流程如图2所示,其中告警的文本化数据的向量化和空间映射过程在以上讨论中已经得到论述。上文证明了在时间上接近以及其他特征接近的告警数据会在向量空间中接近,DBSCAN算法会将向量空间中接近的告警聚为一个簇,从而完成告警归并的目标。进一步,告警归并的结果将会基于人工审核的缺陷单数据进行有效性评估,以此来调整算法的参数以及评价算法效果。
3 缺陷诊断和自动派单
3.1 缺陷诊断
大型通信网络中的缺陷诊断流程可以被分解为3个步骤[10]:故障检测、故障定位、故障诊断。应用于电力通信网的缺陷诊断的技术方法主要有专家系统、神经网络、优化技术、Petri网络、粗糙集理论、模糊集理论、贝叶斯网络、多Agent技术等[11]。
对于由同一种缺陷原因引发的缺陷,应当在设备类型、设备数量、拓扑连接等方面存在相似。类似于将无监督聚类方法应用于告警归并中的前提,数据分布中的相似性给予了人工智能技术发挥其长处的可能。具体地,缺陷诊断任务中数据的相似性体现在拓扑结构上的相似性。对于电力通信网络的缺陷相关告警数据的研究发现,与某一缺陷相关的告警所发生的设备通常具有物理相连关系或者逻辑相连关系。设备及其之上的告警,以及设备间的关联关系可以构成基本图结构。属于同一类缺陷的图结构之间经常存在子图结构的相似甚至相同。因此本文将电力通信的缺陷模式发现问题转化为基于图的模式发现问题进行解决。
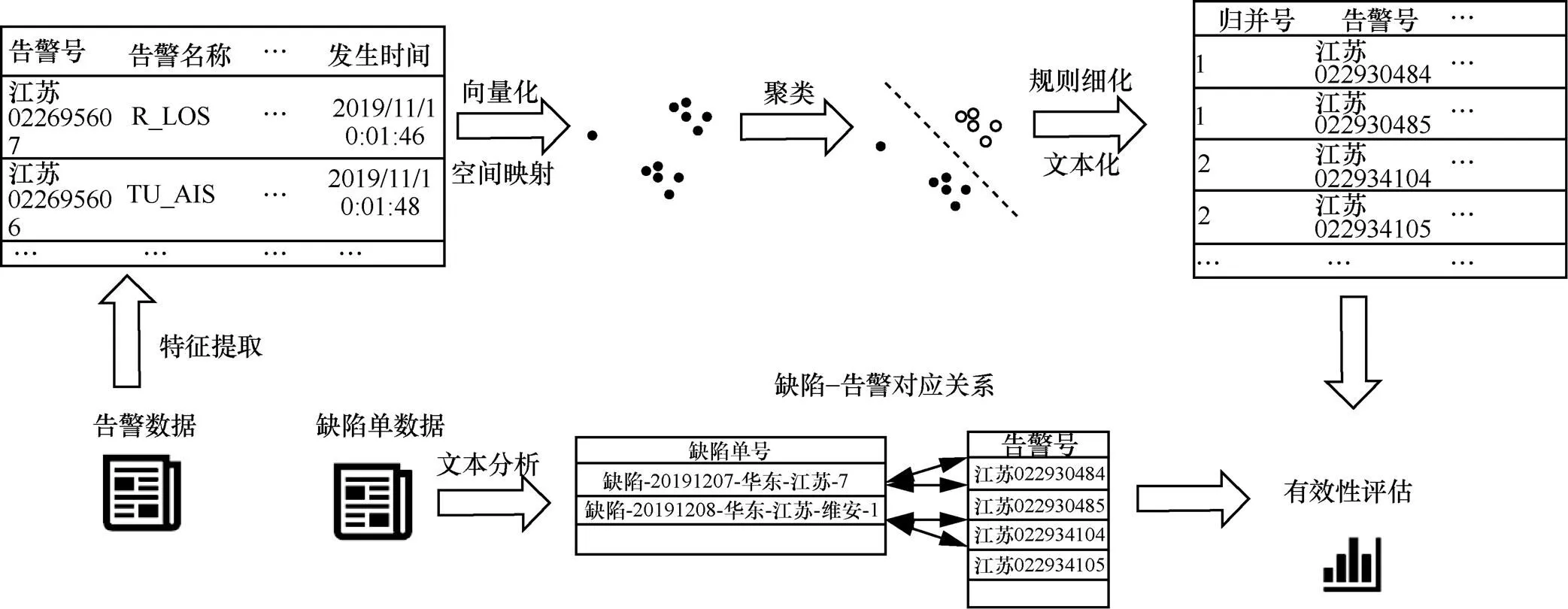
图2 基于无监督聚类告警归并模块流程
3.2 gSpan
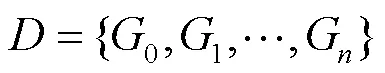
其中,频繁子图挖掘算法中gSpan(graph- based substructure pattern mining)由于其在时间复杂度以及空间复杂度的优秀表现,在频繁子图挖掘领域中得到了广泛的应用。gSpan的关键流程包括从规模为的频繁子图集合生成规模为+1的频繁子图候选集,以及检查候选集中的子图是否为同构子图以此修剪冗余部分。
检查子图同构问题是一个NP完全问题[13],因此在gSpan中利用最小DFS编码和DFS字典树解决子图同构的检查。
gSpan是一个较为复杂的算法,关键的DFS编码依据定义7~定义10[14]。
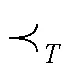
定义10(DFS编码树)在DFS编码树中,每一个节点代表了一个DFS编码。父节点和子节点之间的关系遵循以下的描述。
给定标记集合,DFS编码树应当包含无穷的图。因为本文只考虑有限集中的频繁子图,DFS编码树的规模也是有限的。DFS编码树中第层的节点包含(−1)条边的图的DFS编码。通过DFS编码树的深度优先遍历,所有的具有最小DFS编码的频繁子图都能被发现。特别地,如果节点中包含具有不同的DFS编码的重复的图,例如和表示同一个图但是具有更小的DFS编码,那么不是最小的DFS编码,将会被剪枝。
算法1和算法2描述了gSpan算法的伪代码。其中,表示图数据库,包含了挖掘结果。更多算法细节参考文献[14]。
算法1 GraphSet_Projection(D,S)
根据支持度对中的标记进行排序
移除不频繁的顶点和边
重新标记剩下的顶点和边
用e初始化s,用包含e的图设置s
break
算法2 Subgraph_Mining(D,S,s)
return
枚举每个图中的并且对其子节点计数
for 每个,属于的子节点 do
3.3 缺陷诊断和自动派单模块设计
针对网络拓扑中大规模KPI异常检测的场景,文献[6]提出了一种基于图的门控卷积编解码异常检测(graph-based gated convolution codec for anomaly detection,GAD)模型,通过提取节点间的空间特征,以挖掘详细的节点连接状态信息。GAD运用到大规模网络中获得了良好的表现效果。因此,本文考虑结合时空关系完成电力通信网的缺陷诊断。但是电力通信网场景中某一缺陷所关联的告警往往局限于一个小而准确的范围,需要捕捉到准确的缺陷模式。因此本文采用频繁子图挖掘方法对于缺陷模式进行捕捉。
将频繁子图挖掘方法应用到告警归并集合数据分析领域的首要任务是将归并集合转化成图数据。本文将通信网络中的网元转化成图中的顶点,将网元之间的物理联系(如经过光缆相连)以及网元之间的逻辑联系(如网元与网管之间保持的通信)转化为图中的边,网元上发生的告警转化为图中的标记。由于网元之间的联系是双向的,因此顶点之间的边为无向边。基于以上讨论,本文将告警归并集合转化为顶点带标记的无向连通图,并对此进行频繁子图挖掘。
特别地,在电力通信网的缺陷诊断的场景下,本文可以对gSpan得到的频繁子图模式进行进一步剪枝,对满足以下任一条件的子图,本文不视作可能存在的缺陷模式。
● 只有一个顶点的子图。
● 顶点数大于2且度为1的节点上没有告警发生的子图。
这是因为实际电力通信场景中的缺陷通常可归类为单网元不衍射到其他网元故障,或者是单网元可衍射到其他网元故障以及网元间介质故障。对于单网元故障,告警应当被网元及其从属的网管采集,至少存在两个顶点;对于单网元可衍射到其他网元故障及网元间介质故障,缺陷模式的最远点应当是故障影响范围的末端,也就是对应最远上报告警的网元。
基于以往面向区间异常检测进行自适应标记筛选和再学习[5]的工作基础,本文利用标记筛选以及基于历史数据实现训练和预测并行的思想,设计了缺陷模式发现以及缺陷诊断及自动派单流程。在模式标注前后,历史缺陷单数据将与对应出现的模式进行关联,使得模式之间的差异能被准确检测到。
基于频繁子图挖掘的缺陷模式发现流程如图3所示。经过以上讨论的图数据结构设计,各个顶点上的告警经过告警编码,由告警归并模块得到的归并集合完成拓扑生成,得到带标记的无向连通图。由告警归并集合得到的带标记的无向连通图集合经过子图挖掘并且经过剪枝保留频繁子图模式,再一次进行告警解码后成为待标记的可能缺陷模式。待标记的可能缺陷模式在经过专家标注之后存入知识库,完成缺陷模式的发现。两个发生R_LOS告警的端口存在物理关联关系(端口分别从属的站点间存在光缆连接关系)和逻辑关联关系(端口分别从属的网管间存在通道关系)。告警编码时,假设告警集合大小为9,则告警编码序列长度为9,若R_LOS所处位置为0,则只发生R_LOS的告警编码对应为100 000 000,没有发生任何告警的告警编码对应为000 000 000。在子图挖掘并完成剪枝之后得到两个子图,经过告警解码后,子图重新还原为具有高可读性的可能缺陷模式,方便等待人工进行标注。
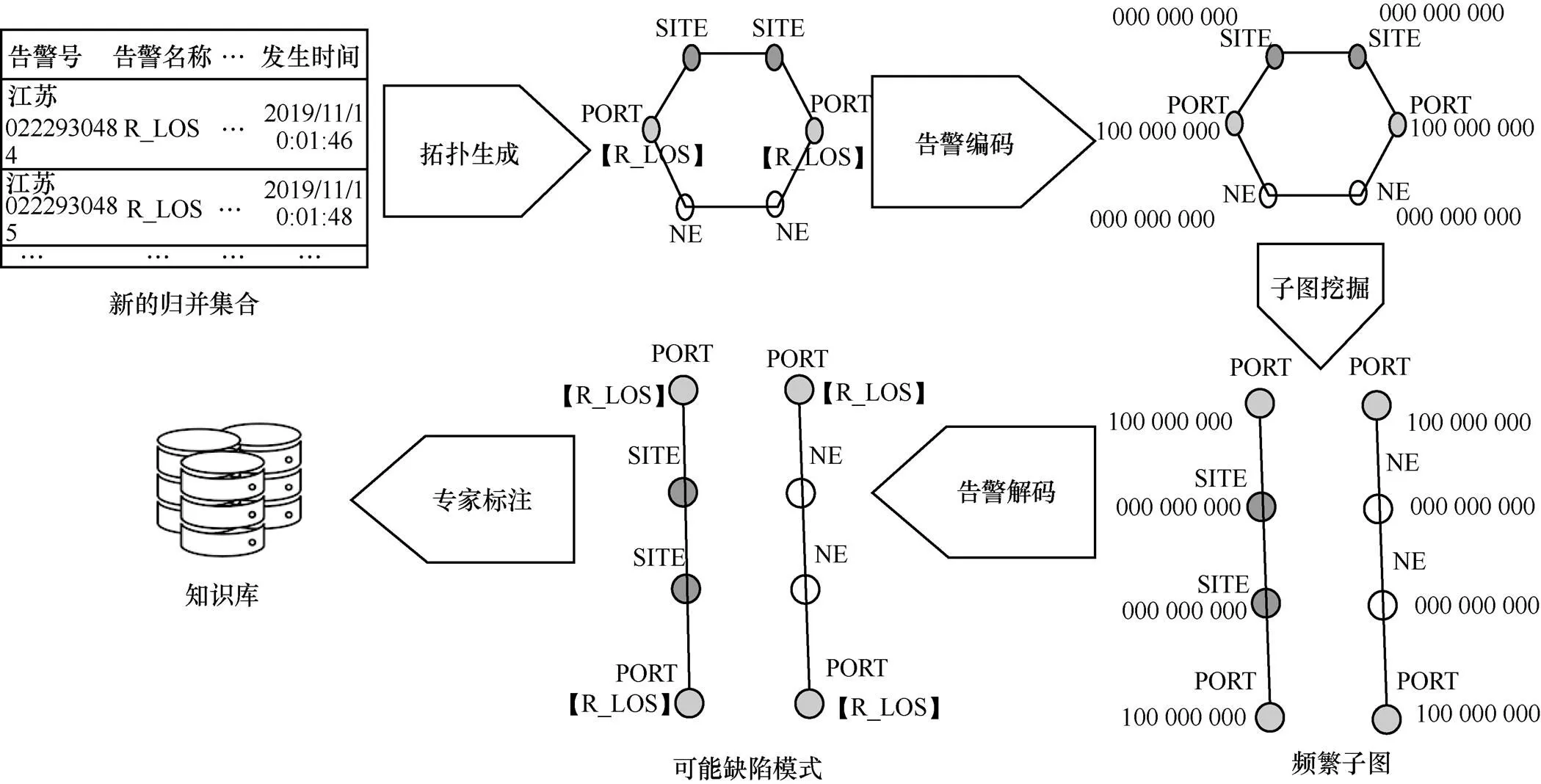
图3 基于频繁子图挖掘的缺陷模式发现流程

图4 缺陷诊断和自动派单模块流程4实验结果分析
缺陷诊断和自动派单模块流程如图4所示。当新的归并集合到达,得到拓扑生成图,使用知识库中已标记的缺陷模式进行模式识别。具体而言,若在图中识别到了缺陷模式,则根据识别出的模式在图中的映射位置完成缺陷定位,根据知识库中该模式对应的专家标注完成缺陷分类,从而完成缺陷诊断,并基于缺陷定位定级、业务影响分析完成缺陷单派发。若未在图中识别到知识库中的模式,则使图进入模式发现流程,记为新的待定模式。可见本文所提供的缺陷诊断架构具有强大的容错能力并且拥有迭代更新的能力。
4 实验结果分析
4.1 告警归并的有效性验证
归并结果的有效性验证[16]借鉴了聚类方法的评估指标,聚类方法的评价指标[17]分为外部指标和内部指标,内部评价聚类的估计趋势,体现数据的非均匀分布程度。在电力通信系统中,与数据的非均匀程度相比更加关注告警与实际场景的一致性(告警归并结果直接影响后续缺陷处理),因此借助缺陷和告警簇的分布情况通过外部指标来评价归并结果是否准确且完备。
根据以上的讨论,本文中告警归并任务要求将可能由同一个缺陷引起的告警关联在一起。本文使用的数据包括缺陷单数据和告警数据,经过告警流水号进行数据关联。这意味着,同一缺陷单关联的告警应当被归并在一起,且不同缺陷单关联的告警不应被归并在一起。告警归并的评估应该建立在归并集合以及实际缺陷单相关告警数据的一致性评估基础上。本文选择了V-measure[18]方法进行有效性评估。
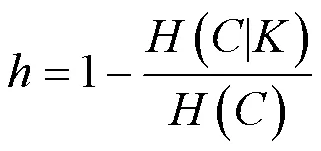



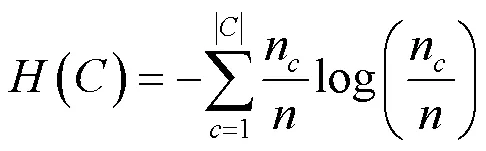
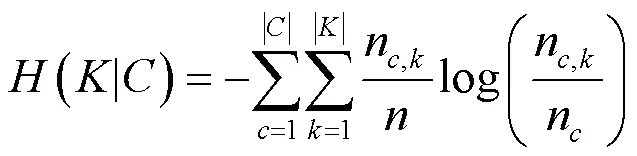

表1 不同告警归并方法的特性和效果对比
h-score、c-score和v-score分别表明了归并结果的同质性、完整性和同质性与完整性的调和平均值,取值为0到1,取值为1时为最理想结果。
可以直观地看出,几种方法在信息熵上的表现都能够有效消除不确定性。其中在同质性表现上,规则匹配和DBSCAN方法表现最佳,在完整性表现上,DBSCAN方法表现最佳,综合考虑同质性与完整性的表现,DBSCAN方法表现最佳且性能表现具有可解释性。-means方法在缺陷具有突发性的前提中并不适用,因此性能表现都不太理想。规则匹配方法得到的归并结果基于人工经验,因此归并的结果同质性较高,但是对于规则以外的模式无法进行捕获因此完整性欠缺。本文基于无监督聚类的告警归并方法在消除不确定性上表现更强,具有自学习能力,不需要预先人为预测缺陷数目。
基于规则匹配、-means、DBSCAN的告警归并方法的缺陷一致性对比见表2。
(1)归并与缺陷一对一
表明归并集合中仅包含一个缺陷且一个缺陷对应的告警被归并到了同一个集合中。归并与缺陷一对一表明告警被正确归并,显然本文所采用的DBSCAN方法显著优于其他方法。
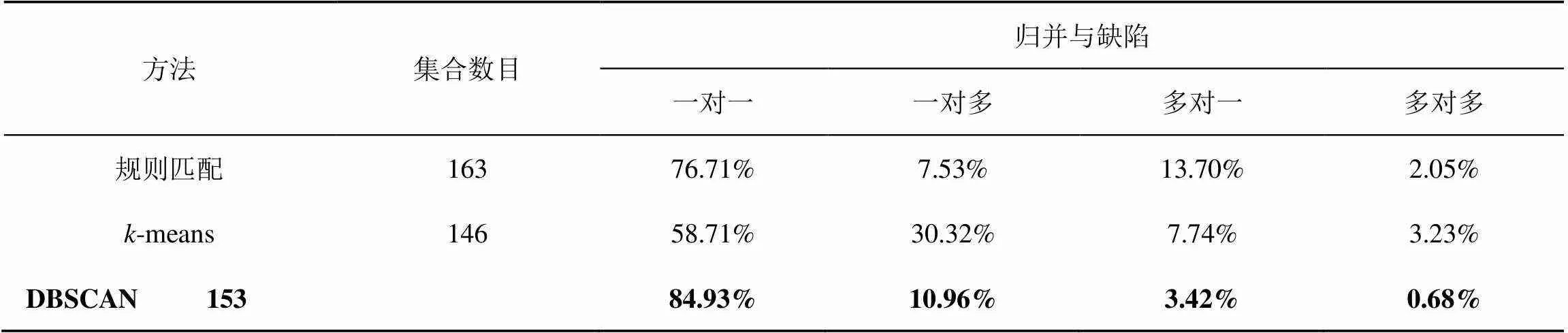
表2 不同告警归并方法的缺陷一致性对比
(2)归并与缺陷一对多
表明归并集合中包含多个缺陷但一个缺陷对应的告警被归并到了同一个集合中。归并与缺陷一对多表明部分集合被划分得过大,可以通过细化集合来降低该比例。
(3)归并与缺陷多对一
表明归并集合中仅包含一个缺陷但一个缺陷对应的告警被归并到了多个集合中。可见DBSCAN方法比起单纯的规则匹配降低了更多归并与缺陷多对一比例,提高了归并与缺陷一对一比例。
(4)归并与缺陷多对多
表明归并集合中包含多个缺陷且一个缺陷对应的告警被归并到了多个集合中。本DBSCAN方法在归并与缺陷多对多上占比最小,表现最优。
集合数目对应着归并告警集合数,也就是对应方法预测的缺陷数目。在集合的数目上,-means算法需要提前预设集合数目才能运行,预设集合数目设置为缺陷单数目146,因此生成集合的数目与缺陷总数保持一致,而其他方法生成集合的数目与实际缺陷数目有偏差。除了-means方法之外,其他方法不需要设定集合数目,因此集合的数目与实际缺陷数目的一致性部分显示了归并方法的准确性。
评估使用了146个缺陷单数据,其中12个缺陷单数据存在重复派单的现象,因此归并与缺陷一对多的比例较高。评估数据中的重复派单现象主要来源于:(1)实际环境中缺陷没有得到及时发现和消缺导致一段时间后告警再次产生,由于告警之间时间间隔较长,单一缺陷被归为多个缺陷单;(2)多个站点的共享线路或设备发生缺陷,基于人工或者规则的缺陷诊断将其判断为多个缺陷归档。本系统的自动派单会将算法得到的缺陷单向前归并到已产生但未处理完毕的缺陷单当中,遏制(1)导致的重复派单;相近时间内具有共享线路或设备的多站点缺陷会被归并到同一缺陷中,定位缺陷为该共享线路或设备,遏制(2)导致的重复派单。人工复查证明了算法结果有效核验了原始缺陷单数据,发现了原始缺陷单数据中的重复派单数据。综上,本文提出的基于DBSCAN的告警归并方法在归并与缺陷一致性表现上更强,不需要预设集合数目且生成集合与实际缺陷数目较为一致。
4.2 缺陷诊断的有效性验证
频繁子图挖掘得到的待标记模式和缺陷类型的相关程度如图5所示,基于146个缺陷单及其相关告警数据基于DBSCAN完成告警归并后,对于归并集合进行频繁子图挖掘得到的待标记的缺陷模式集合与实际缺陷单数据之间的分布一致性结果。验证实验中制定了4种缺陷类型,fiber breaking、power interruption、card abnormal以及power abnormal,分别对应的物理意义为光缆类故障、供电设备中断、板卡类故障以及供电设备故障。图5(a)~(d)给出了子图模式分别与4种缺陷类型的相关程度。其中,峰值表示该模式与对应缺陷类型之间存在强相关性。其中图5(a)和图5(b)出现了多个峰值,相关程度在0%~100%,说明fiber_breaking和power_ interruption与多种模式相关,且模式较为复杂,模式间可能存在交叉;图5(c)出现了多个峰值,相关程度基本只分布在0%和100%两个点,说明card_abnormal模式简单,但是存在多种模式;图5(d)只出现了单峰值,说明power_abnormal只与单一模式高度相关,其结果与实际环境一致。其中,具有强相关性(图中相关度为100%)的待标记的缺陷模式在经过人工审核之后往往是对应缺陷类型下的关键模式。这意味着在没有人工参与的情况下,本文所提供的算法既可以自动化发现可能存在的缺陷模式,同时也可以给予人工标注建议,能够准确捕捉数据之间的相关性,并且可以准确区分不同类型数据。
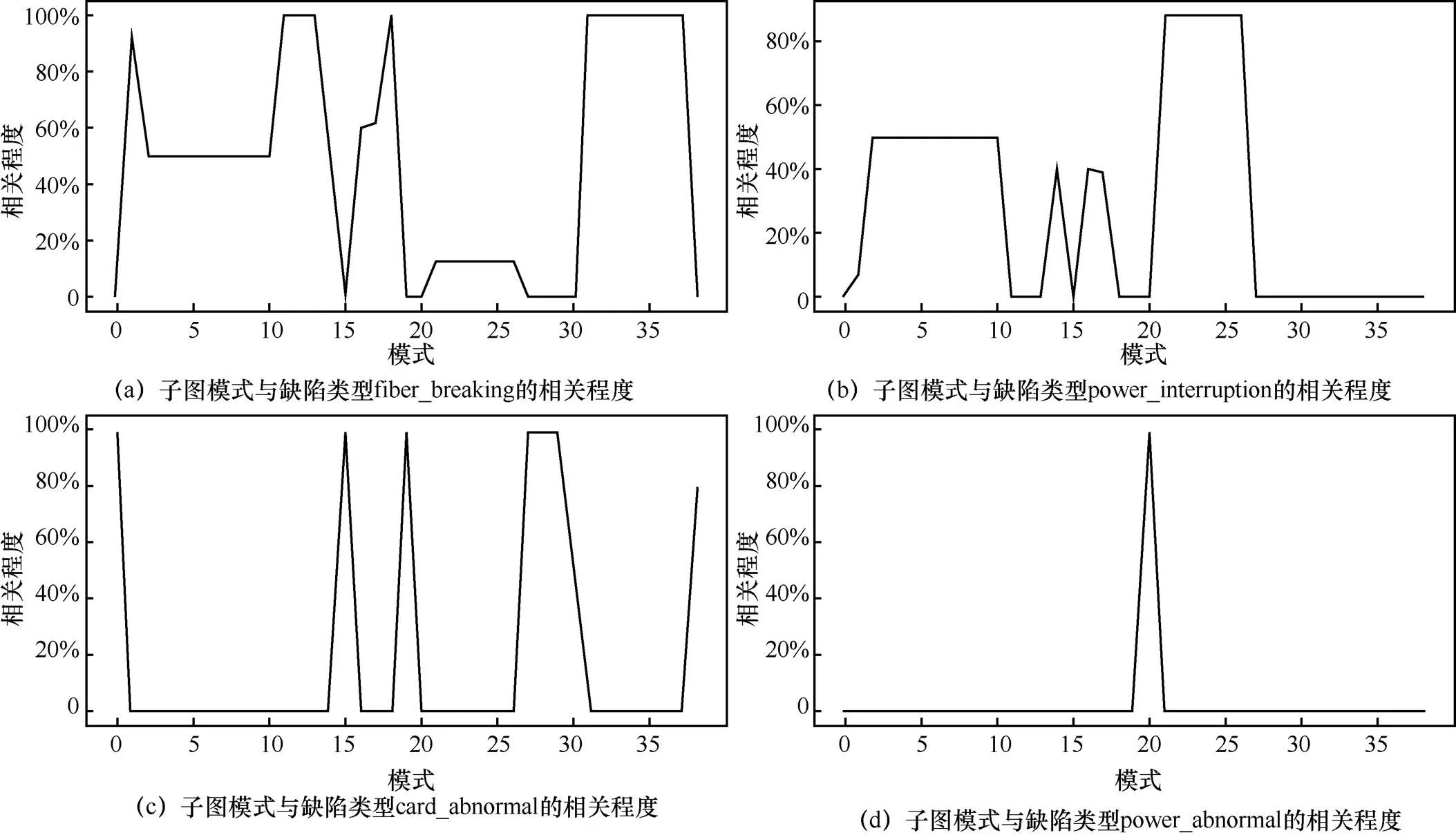
图5 频繁子图挖掘得到的待标记模式和缺陷类型的相关程度
本文提出的架构已经实际部署在缺陷诊断及自动化派单系统中,基于gSpan挖掘得到频繁子图并且经过人工标注选出关键模式之后进行图匹配得到的缺陷诊断混淆矩阵见表3。混淆矩阵的每一列代表了真实类别,每一列的总数表示预测为该类别数据的数目;每一行代表了数据的预测归属类别,每一行的数据总数表示该类别数据实例的数目。缺陷种类分为card abnormal、fiber breaking、power abnormal、power interruption。其中,card abnormal和power abnormal预测结果和真实结果完全一致,有两个fiber breaking被预测为power interruption,一个power interruption被预测为fiber breaking。也就是在card abnormal以及power abnormal的缺陷诊断任务上准确率为100%,fiber breaking类别中62个缺陷中有2个缺陷诊断错误,准确率为96.8%,power interruption类别中14个缺陷有1个缺陷诊断错误,准确率为92.9%。实验结果表明本文提出的缺陷诊断方法能够获得较高的准确性。
5 结束语
本文提出的面向电力通信网的缺陷检测和自动派单方法,基于无监督聚类和频繁子图挖掘算法,提供了一个具有自学习和迭代更新能力的架构。该架构为将无监督学习和数据挖掘等人工智能技术引入电力通信领域,减轻了运维压力,降低了人力资源投入,提升了系统安全性和可靠性。架构重点在于告警归并和缺陷诊断及自动派单模块,模块间功能清晰、相互独立,提供向外暴露的接口,具有良好的可扩展性,允许扩展为其他可行算法。本文中两大模块分别基于无监督聚类算法DBSCAN和频繁子图挖掘算法gSpan,摆脱了传统缺陷诊断方法对于人工规则的依赖,并在实验中取得了良好的性能表现。实验结果证明了该架构及其基础算法的可实施性和可部署性,对电力通信网络的智能化进程有一定的理论指导意义。

表3 缺陷诊断混淆矩阵
[1] GARDNER R D, HARLE D A. Methods and systems for alarm correlation[C]//Proceedings of Proceedings of GLOBECOM'96. 1996 IEEE Global Telecommunications Conference. Piscataway: IEEE Press, 1996: 136-140.
[2] MAZDZIARZ A. Alarm correlation in mobile telecommunications networks based on k-means cluster analysis method[J]. Journal of Telecommunications and Information Technology, 2018(2): 95-102.
[3] WEN L, LI X Y, GAO L, et al. A new convolutional neural network-based data-driven fault diagnosis method[J]. IEEE Transactions on Industrial Electronics, 2018, 65(7): 5990-5998.
[4] XIAO F, ZHAO Y, WEN J, et al. Bayesian network based FDD strategy for variable air volume terminals[J]. Automation in Construction, 2014(41): 106-118.
[5] WANG J Y, JING Y H, QI Q, et al. ALSR: an adaptive label screening and relearning approach for interval-oriented anomaly detection[J]. Expert Systems With Applications, 2019(136): 94-104.
[6] QI Q, SHEN R Y, WANG J Y, et al. Spatial-temporal learning-based artificial intelligence for IT operations in the edge network[J]. IEEE Network, 2021, 35(1): 197-203.
[7] JAKOBSON G, WEISSMAN M. Alarm correlation[J]. IEEE Network, 1993, 7(6): 52-59.
[8] SCHUBERT E, SANDER J, ESTER M, et al. DBSCAN revisited, revisited[J]. ACM Transactions on Database Systems, 2017, 42(3): 1-21.
[9] YANG Y C, WANG Y P, WEI Y. Adaptive density peak clustering for determinging cluster center[C]//Proceedings of 2019 15th International Conference on Computational Intelligence and Security (CIS). Piscataway: IEEE Press, 2019: 182-186.
[10] BOULOUTAS A T, CALO S, FINKEL A. Alarm correlation and fault identification in communication networks[J]. IEEE Transactions on Communications, 1994, 42(234): 523-533.
[11] YOUSUF H, ZAINAL A Y, ALSHURIDEH M, et al. Artificial intelligence models in power system analysis[M]//Artificial Intelligence for Sustainable Development: Theory, Practice and Future Applications. Cham: Springer International Publishing, 2020: 231-242.
[12] DARRAB S, ERGENC B. Vertical pattern mining algorithm for multiple support thresholds[J]. Procedia Computer Science, 2017(112): 417-426.
[13] HARTMANIS J. Computers and Intractability[EB]. SIAM Review, 1982.
[14] YAN X F, HAN J W. gSpan: graph-based substructure pattern mining[C]//Proceedings of 2002 IEEE International Conference on Data Mining. Piscataway: IEEE Press, 2002: 721-724.
[15] YAN X F, HAN J W. gSpan: graph-based substructure pattern mining[C]//Proceedings of 2002 IEEE International Conference on Data Mining. Piscataway: IEEE Press, 2002: 721-724.
[16] XIONG H, LI Z M. Clustering validation measures[M]//Data Clustering: Chapman and Hall/CRC, 2018: 571-606.
[17] HOU J, LIU W X. Evaluating the density parameter in density peak based clustering[C]//Proceedings of 2016 Seventh International Conference on Intelligent Control and Information Processing (ICICIP). Piscataway: IEEE Press, 2016: 68-72.
[18] NOWOSAD J, STEPINSKI T F. Spatial association between regionalizations using the information-theoretical V-measure[J]. International Journal of Geographical Information Science, 2018, 32(12): 2386-2401.
Fault diagnosis and auto dispatchin of power communication network based on unsupervised clustering and frequent subgraph mining
WU Jihua1, ZHU Pengyu2, WU Zichen3, GU Bin3, HONG Tao3, GUO Bo3, WANG Jing1, WANG Jingyu1
1. State Key Laboratory of Networking and Switching Technology, Beijing University of Posts and Telecommunications, Beijing 100876, China 2. State Grid Electric Power Research Institute Co., Ltd, Nanjing 210012, China 3. Information and Communication Branch of State Grid Jiangsu Electric Power Co., Ltd., Nanjing 210024, China
Fault diagnosis is one of the most challenging tasks in power communication. The fault diagnosis based on rules can no longer meet the demand of massive alarms processing. The existing approaches based on the supervised learning need large sets of the labeled data and sufficient time to train models for processing continuous data instead of alarms, which are far behind the feasibility of deployment. As for alarm correlation and fault pattern discovery, a self-learning algorithm based on the density-based clustering and frequent subgraph mining was proposed. A novel approach for automatic fault diagnosis and dispatch were also introduced, which provided the scalable and self-renewing ability and had been deployed to the automatic fault dispatch system. Experiments in the real-world datasets authorized the effectiveness for timely fault discovery and targeted fault dispatch.
power communication, fault diagnosis, unsupervised clustering, frequent subgraph mining
TP393
A
10.11959/j.issn.1000−0801.2021253

吴季桦(1998−),女,北京邮电大学计算机学院硕士生,主要研究方向为云原生、知识图谱、子图挖掘。
朱鹏宇(1992−),男,国网电力科学研究院有限公司工程师,主要研究方向为电力通信、人工智能、知识图谱。

吴子辰(1988−),男,国网江苏省电力有限公司信息通信分公司高级工程师、信通调控中心副主任,主要研究方向为电力通信技术。
顾彬(1983−),男,博士,国网江苏省电力有限公司信息通信分公司高级工程师,主要研究方向为电力通信技术。
洪涛(1994−),男,国网江苏省电力有限公司信息通信分公司工程师,主要研究方向为电力光纤通信、计算机网络安全、人工智能技术等。
郭波(1977−),男,国网江苏省电力有限公司信息通信分公司高级工程师、副总工程师,主要研究方向为电力信息通信技术。
王晶(1974−),女,北京邮电大学计算机学院副教授,主要研究方向为业务网络、云网络、网络智能等。
王敬宇(1978−),男,博士,北京邮电大学计算机学院教授、博士生导师,主要研究方向为智能网络、智能运维、边缘计算等。
Science and Technology Project of State Grid Corporation (No.5700-202040367A-0-0-00)
2021−05−31;
2021−11−15
王晶,wangjing@ebupt.com
国家电网公司科技项目(No.5700-202040367A-0-0-00)
