基于多特征LSTM-Self-Attention文本情感分类
2021-12-10谢斌红董悦闰潘理虎张英俊
谢斌红,董悦闰,潘理虎,2,张英俊
(1.太原科技大学计算机科学与技术学院,山西 太原 030024;2.中国科学院地理科学与资源研究所,北京 100101)
1 引言
文本情感分析又称意见挖掘或观点分析[1],是运用自然语言处理技术对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。情感分类作为其中一项最基本的任务,旨在根据文本表达的情绪进行自动分类[2]。它对舆情控制、民意调查及心理学研究[3]等具有重要的意义,因此,近些年受到了众多研究者的密切关注,并取得许多进展[4]。
文本情感分类方法的研究经历了基于词典的方法、基于机器学习的方法和基于深度学习的方法三个阶段[5]。其中,由于基于深度学习的方法具有更强的特征表示,而且还能更好地学习从数据到情感语义的复杂映射函数,最重要的是解决了传统机器学习方法的数据稀疏和维度爆炸的问题。因此,越来越多的学者将深
度学习应用到文本情感分类领域。Bespalov等[6]提出利用潜在语义分析(latent semantic analysis)来进行初始化词向量,然后使用带权重的n-gram特征的线性组合表征整篇文档的情感特征。但是利用n-gram特征必须具备关于整个文献库和分类的知识,且需要大量人工进行处理。Glorot 等[7]使用除噪堆叠自编码器(stacked denoising autoencoder,SDA)来解决大量评论数据情感分类中在不同领域中的适应性问题(domain adaptation)。Socher等[8-10]使用一系列基于递归神经网络(Recursive Neural Network,RNN)的分类模型来解决文本情感分类问题,但是递归神经网络在训练过程中存在一些梯度爆炸和消失问题等缺点。Kim Y[11]则利用卷积神经网络(Convolutional Neural Networks,CNN)来对英文电影评论进行分类,实验结果表明,CNN的分类性能明显优于递归神经网络。为了解决RNN梯度消失和梯度爆炸的问题,Zhu[12]提出使用长短期记忆网络(Long Short Term Memory,LSTM),将评论语句建模成词序列来解决情感分类问题,该网络可以学习长距离依赖信息,对时间序列中间隔或延长较长的事件处理和预测时比较适用。梁军等[13]将LSTM模型变型成为基于树结构的递归神经网络,并根据句子上下文词语间的相关性引入情感极性转移模型。如今LSTM 已经被应用在了许多领域,如机器翻译[14]、图像分析[15]、语音识别[16]等。由于LSTM解决了梯度爆炸和梯度消失的问题;此外,它更加真实地表征了人类行为、逻辑发展的认知过程,并且具有对词向量依赖小的特点,能够处理更加复杂的自然语言处理任务,成为当下解决自然语言处理问题的主流探究方向。
由于自注意力机制具有可减少神经网络训练时所需要的文本特征,降低了任务的复杂度,并且能够有效捕获远距离的特征等优点,已广泛应用于机器翻译[17,18]等自然语言理解任务中,并取得了较好的效果。另外,词性作为词语的关键信息,包含了较丰富的情感信息,通常作为一种辅助特征与词语等特征相结合[19,20],并利用CNN或LSTM网络对文本进行情感分类,使性能得到了一定提升。
综上所述,本文将词语、词性特征相融合,以LSTM网络作为主干网,并引入自注意力机制,提出了一种改进的基于多特征LSTM-Self-Attention模型对文本情感进行分类。实验表明,自注意力机制和词性特征可以提高情感分类的效果,比经典的LSTM网络模型取得了更高的准确率。
2 基于多特征LSTM-Self-Attention文本情感分类模型
基于多特征LSTM-Self-Attention模型主要由文本预处理、Word2vec、LSTM、自注意力机制和SoftMax分类器5部分组成,其模型结构如图1所示。其中,文本预处理模块是将文本处理成词语的形式,Word2vec模块是将词语训练成计算机可以理解的稠密向量,LSTM模块提取出稠密向量中的特征,自注意力机制模块是进一步提取出特征中对分类结果更有影响的特征,最后,使用SoftMax分类器按照提取的重要特征对文本情感进行分类。

图1 基于多特征LSTM-Attention文本分类模型
2.1 文本预处理


表1 部分词性标准对照表
2.2 Word2vec
在自然语言处理任务中,首先需要考虑文本信息如何在计算机中表示。通常文本信息有离散表示和分布式表示2种方式。文本分类的标签数量少且相互之间没有依存关系,因此,使用离散表示的方法来表示文本情感分类的标签yi,例如:高兴 [0,0,0,1,0]。本文使用Word2vec[21]将词语表示成一个定长的连续的稠密的向量(Dense Vector),能够表征词语之间存在的相似关系;Word2vec训练的词向量能够包含更多的信息,并且每一维都有特定的含义。它包含了Continuous Bag of Word(CBOW)和Skip-gram 两种训练模型(如图2和图3所示),两种模型都包括输入层、投影层、输出层,其中CBOW 模型利用词Wt的上下文Wct去预测给定词Wt,而Skip-gram 模型是在已知给定词Wt的前提下预测该词的上下文Wct。在此,本文使用Word2vec工具的Skip-gram 模型来训练数据集中的每个词语以及使用词性标注工具标注好的词性为计算机可理解的词向量和词性向量。

图2 CBOW模型 图3 Skip-gram模型

2.3 长短时间记忆网络LSTM


图4 LSTM模型单个神经元结构图
1)遗忘门
遗忘门决定了上一时刻的单元状态ct-1有多少保留到当前时刻ct,它会根据上一时刻隐藏层的输出结果ht-1和当前时刻的输入xt作为输入,来决定需要保留和舍弃的信息,实现对历史信息的存储[22],可以表述为
ft=sigmoid(whfht-1+wxfxt+bf)
(1)
2)输入门
输入门用于决定当前时刻xt有多少保留到单元状态ct。在t时刻,输入门会根据上一时刻 LSTM 单元的输出结果ht-1和当前时刻的输入xt作为输入,通过计算来决定是否将当前信息更新到LSTM-cell中【22】,可以表述为
it=sigmoid(whiht-1+wxixt+bi)
(2)
对于当前的候选记忆单元值cint,其是由当前输入数据xt和上一时刻LSTM隐层单元ht-1输出结果决定的【22】,可以表述为
cint=tanh(whcht-1+wxcxt+bcin)
(3)
当前时刻记忆单元状态值ct除了由当前的候选单元cint以及自身状态ct-1,还需要通过输入门和遗忘门对这两部分因素进行调节【22】,可以表述为
ct=ft.ct-1+it.cint
(4)
3)输出门
输出门来控制单元状态ct有多少输出到LSTM的当前输出值ht,计算输出门ot,用于控制记忆单元状态值的输出[22],可以表述为
ot=sigmoid(whoht-1+wxoxt+bo)
(5)
最后LSTM单元的输出ht,可以表述为
ht=ot.tanh(ct)
(6)
上述所有式中,“· ”表示逐点乘积。
2.4 自注意力机制

自注意力机制是注意力机制的一种特殊情况,其注意力机制的基本思想是用来表示目标文本Target中的某一个元素Query与来源文本Source中的每个元素keyi之间的重要程度,公式表示如式(7)所示。而自注意力机制是表示的是Source内部各元素之间或者Target内部各元素之间发生的注意力机制,即可以理解为Source=Target。自注意力机制的计算过程如图5所示,主要分为3个阶段。

图5 注意力机制计算过程
Attention(Query,Source)

(7)

s=wstanh(WwHT+bw)
(8)
阶段2是使用SoftMax函数对阶段1得到的权重向量s进行归一化处理,得到注意力向量u,例如图5所示的u=[u1,u2,u3,u4],公式如式(9)所示

(9)


(10)
2.5 SoftMax分类器


(11)
最后将特征拼接向量V输入到SoftMax函数对文本情感进行分类,并将分类结果转化为[0,1]之间的概率值。具体计算公式表述为:
yi=softmax(wcV+bc)
(12)
其中:上式中的softmax函数的计算公式为
(13)
其中xiL为式(13)在L层所计算得到K维矩阵的第i个分量。
3 实验过程及结果
为了验证基于多特征LSTM-Self-Attention模型的有效性,本文采用中文电影评论数据集进行验证。实验分为三组进行,实验一使用LSTM-Self-Attention模型和经典的LSTM模型做实验并进行对比分析;实验二采用经典的LSTM模型和多特征的LSTM模型进行实验对比;
实验三采用基于多特征LSTM-Self-Attention模型和经典的LSTM模型进行实验对比分析。
3.1 数据集及实验环境
本文的实验是在 Windows 7系统下进行,编程语言为 Python3.6,开发工具为PyCharm,使用到的深度学习框架为 TensorFlow。为了证明该模型的有效性,数据集是从谷歌公司旗下kaggle网站上提供的豆瓣电影简短评论数据集中选取的《复仇者联盟》和《大鱼海棠》两部电影评论,其情感分为5个级别,数据形式如表2所示。该数据集的情感级别越高代表对该电影的喜爱程度越高,例如5代表非常喜爱该电影,而1代表非常讨厌该电影,由于该数据集属于弱标注信息。弱标注信息与评论情感语义有一定的相关性,因此,可以用作训练情感分类问题。但由于使用弱标注数据的挑战在于如何尽量减轻数据中噪声对模型训练过程的影响,因此,在进行训练前还对该数据集进行了预处理,包括去燥,修改评论与评分不一致的数据;替换网络用语、表情符号等。在实验时该数据集被划分为3个子数据集,其中,训练集数据为11700条,验证集数据为1300条,测试集数据为1300条。

表2 电影评论数据
3.2 评价指标
为了评价本文提出的分类模型的效果,本文采用文本分类领域常用的评级指标——准确率(Accuracy,A)、精确率(Precision,P)和召回率(Recall,R)以及F1值对模型进行检验。根据分类结果建立的混合矩阵如表3所示。

表3 分类结果混合矩阵
准确率是指正确分类的样本数与样本总数之比率,其计算公式如下

(14)
精确率衡量的是类别的查准率,体现了分类结果的准确程度,其计算公式如下

(15)
召回率衡量的是类别的查全率,体现了分类结果的完备性,其计算公式如下
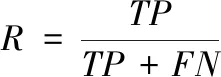
(16)
F1衡量的是查全率和查准率的综合指标,以及对它们的偏向程度,其计算公式如下

(17)
3.3 实验结果及分析
本文对经过预处理的电影评论进行实验,经过过多次训练获取模型的最优超参数集合如表4所示。

表4 模型训练参数
在模型训练完成后对实验结果进行分析,为了直观观察分析准确率和损失值随着训练次数迭代的变化情况,本文运用Origin工具将训练结果可视化处理。图6、图7分别为本模型在中文电影评论情感分类的准确率和损失值的变化图,其中黑色曲线表示训练集的训练结果,红色曲线表示验证集的结果。由图中可以看出,在中文电影评论情感分类的准确率最终平稳在51.0%左右,损失值平稳在1.31附近。

图6 中文电影评论情感分类准确率

图7 中文电影评论情感分类损失值
三组对比实验的结果如表5所示,从表中可以得出,LSTM-Self-Attention模型[22]的准确率为50.23%,比LSTM模型[12]的准确率49.50%提高了0.73%,证明了自注意力机制能够提高情感分类的准确率。基于多特征LSTM模型[19]的准确率50.00%,对比LSTM模型的精确率提高了0.05%,说明加入词性特征能够些微地提高电影评论情感分类效果。而本文提出的基于多特征LSTM-Self-Attentionde 的方法准确率为51.24%,相比经典的LSTM模型提高了1.74%,说明本文在LSTM模型上加入自注意力机制和词性特征能提高电影评论情感分类的准确率。

表5 中文电影评论情感分类结果
从图8各个评价指标的直方图可以更加直观的看出,本文提出的基于多特征LSTM-Self-Attention模型取得更高的分类准确率,证明本文提出的方法是有效的。

图8 中文电影评论情感分类直方图
4 结论
针对传统循环神经网络存在的梯度消失和梯度爆炸的问题,本文使用LSTM模型对文本情感进行分类,为了减少任务的复杂度,本文还将自注意力机制加入到LSTM模型中;此外,为了提高最终的分类效果,文本还将文本的词性特征作为模型的输入,并在最后使用中文电影评价数据集进行实验验证。实验结果表明了本文提出的多特征LSTM-Self-Attention方法的可行性,可以更准确对文本情感进行分类。但是注意力机制的缺点也不容小觑,计算成本的增加使得时间和空间复杂度增加,在计算过程中如若输入的文本长度过长,计算量呈爆炸式增长。此外,相比于经典的LSTM模型,LSTM-Self-Attention模型的实验结果并没有提高很多。下一步工作将对自注意力机制进行优化,减少计算量,进一步提高文本情感分类效率和准确率。
