基于改进K-means的大数据清洗方法
2021-12-09林女贵吴元林
林女贵, 吴元林
(1.国网福建省电力有限公司, 福建 福州 350001;2.国网信通亿力科技有限责任公司, 福建 福州 350001)
0 引言
随着智能化技术的发展,海量的网络数据被采集到各个系统,有效地利用海量数据挖掘数据中存在的价值,最关键的一点是提高数据质量[1-2]。目前的大数据中存在的低质量数据主要包括冗余数据、缺失数据和异常数据[3]。一直以来的研究对于冗余数据和缺失数据的处理已经比较完善,而对于大数据中异常数据的处理还处于初级阶段[4]。为了提高数据质量,达到数据清洗的目的。Hadoop平台是有效处理大数据的软件,利用其对数据进行清洗,可以得到高质量的数据。
由于数据挖掘的效果受数据质量影响较大,所以需要对大数据进行数据清洗以提高数据利用效率。目前数据的采集量越来越大,针对大数据清洗的研究也受到了人们的广泛关注。文献[5]对输变电设备的异常数据进行了分类,采用一种基于时间序列分析的双循环迭代检验法,对变压器和线路的数据进行清洗,得到了较高质量的数据。文献[6]针对并行数据的清洗问题进行了研究,提出了基于任务合并的优化技术,对冗余计算和同一文件进行合并,降低了系统的运行时间,提高了数据清洗的效率。文献[7]采用条件合并方法把关联数据放在一起,提出了一种自动清洗结构,对数据进行检测和修复,并对关联数据的一致性和时效性进行了判断,经过实验对比验证了该方法的有效性。文献[8]针对风电机组采集的风速功率数据,采用组内方差清洗方法,对风机的发电状况进行判断,该方法能够准确识别风机功率曲线并检测出异常工作状态。文献[9]分析了异常负荷数据的产生原因,采用基于密度的负荷数据流异常辨识方法和基于协同过滤推荐算法的负荷修复方法,将该方法在实际负荷数据上进行实验,验证了该方法能够有效提高配电网数据质量。文献[10]采用栈式自编码器方法,对输变电设备正常及异常的数据进行学习,建立起缺失数据和设备异常的模型,实验结果证明,该方法能够有效过滤干扰数据。文献[11]在采用大数据方法评估变压器状态的时候,针对数据中存在数据缺失和异常的问题,建立数据之间的关联规则模型,采用基于密度的聚类方法检查数据的缺失值和异常点,采用小波神经网络对异常数据进行修复,提高清洗数据的质量。
本文针对Hadoop平台下的大数据进行异常数据清洗的研究,以保障数据清洗的有效性。采用基于损失函数的Logsf方法对高维数据进行降维处理,采用Canopy方法对K-means进行改进,并采用改进的K-means方法对异常数据进行清洗。
1 Hadoop平台下数据清洗方法
在对数据分析之前,会对数据进行清洗,以查找数据中存在的“低质”数据[12]。清洗过后的数据需要数据质量评价,数据质量的评价主要包含2个元素:定量元素和非电量元素。定量元素主要是从如下方面对数据清洗结果进行评价:清洗数据的完整性;清洗数据的一致性;数据的唯一性;数据的准确性;数据的有效性;数据的时间性。非定量元素主要包括数据处理的目的,数据集的用途和数据集从采集到处理的过程描述。本文采用定量元素方法评价清洗过后的质量,并采用Hadoop平台,对处理后的数据的查全率和可扩展性进行分析。
数据清洗的过程如图1所示。

图1 数据清洗流程图
原始数据是指数据仓库中存储的数据信息;数据预处理指的是对原始数据进行简单的约束处理;特征选择指的是提取数据特征,剔除冗余信息;数据清洗指的是根据实际应用情况,清洗脏数据;清洗结果检查指的是根据清洗标准检验数据质量。
由于Hadoop在处理大数据上的优越性,采用Hadoop的分布式数据清洗方法,可以有效提高大数据清洗的效率。采用Hadoop方法清洗数据的时候,将数据分为存储层和清洗计算层。采用HDFS进行数据存储,在HDFS上层采用Hive数据仓库实现数据的转存,然后将数据库的数据按照指定格式进行处理,实现数据清洗前期的准备工作。本文采用MapReduce方法实现异常数据的分布式清洗,提高数据清洗的效率和准确性。Hadoop平台的异常数据清洗流程如图2所示。

图2 分布式异常数据清洗流程
具体的分布式数据清洗流程如下所述。
(1) 数据源加载。采用Sqoop和Hive对采集的数据进行加载和转存。
(2) 数据预处理。根据数据需求进行综合分析,以确保数据分析时数据的可用性。
(3) 特征选择。选择出影响数据质量的主要特征,剔除冗余特征,实现大数据的降维处理。
(4) 识别异常数据。采用改进的K-means算法,将距离相差越大异常性越强的数据,采用MapReduce方法实现并行化计算。
(5) 清洗结果检验。对清洗后的数据进行数据质量检查,确保数据质量。
2 基于改进K-means的异常数据清洗方法
2.1 基于Logsf的特征选择方法
Logsf可以描述为假设训练样本集R={M,N}={mi,ni}。其中,mi为第i个训练样本;ni为第i个样本的标记[13]。每个样本包含d维矢量,mi={mi1,mi2,mid}∈Rd。样本mi的损失函数定义为式(1)。
L(β,mi)=log(1+exp(-βTFi))
(1)

Logsf算法的评价函数可以表示为式(2)。
(2)
式中,K表示样本特征数量;e(β)是所有特征样本损失函数之和。如何确定最优的β′求取最小的损失函数,是需要研究的问题,本文采用梯度下降方法求取最优权重。
设步长为α,梯度下降法的迭代算式表示为式(3)。
(3)
将式(1)带入式(3),则可得到式(4)。
(4)
简化后可得到式(5)。
(5)
通过上述方法可以得到最优权重,但是在Logsf中存在着最邻近思想,确定特征样本相似度的方法为式(6)。
(6)
2.2 基于改进K-means算法的数据清洗方法
数据中存在着与主体数据不相符的数据,被称为异常数据。K-means算法的步骤[14-15]如下所述。
从训练样本{x1,…,xm},xi∈Rn,随机取k个中心点。
Step1:从{x1,…,xm}随机取k个样本,记作初始聚类中心μ1,μ2,…,μk∈Rn。
Step2:求取其他数据与该中心样本的距离,数据样本根据距离划分类别,如式(7)。
(7)
Step3:对每个类j,求取平均值确定中心点,如式(8)。
(8)
式中,每个样本含d个属性,第j类共m个数据,其中样本xi属于第j类,属于第j类的样本xi的第D个特征求和,再求平均值,即为第D个特征的质心。
Step4:若目标函数收敛,终止程序;否则转到Step2。
Canopy的思想:在数据集中随机点A,计算其余样本与A的距离,根据距离的大小划分类别。例如,小于T1的作为一类,[T1,T2]之间的为另一类。
采用Canopy算法优化K-means算法的过程如下。
(1) 原始数据存入数据集D中。
(2) 随机确定中心点,放入canopy centerlist,将该数据从D里删除。
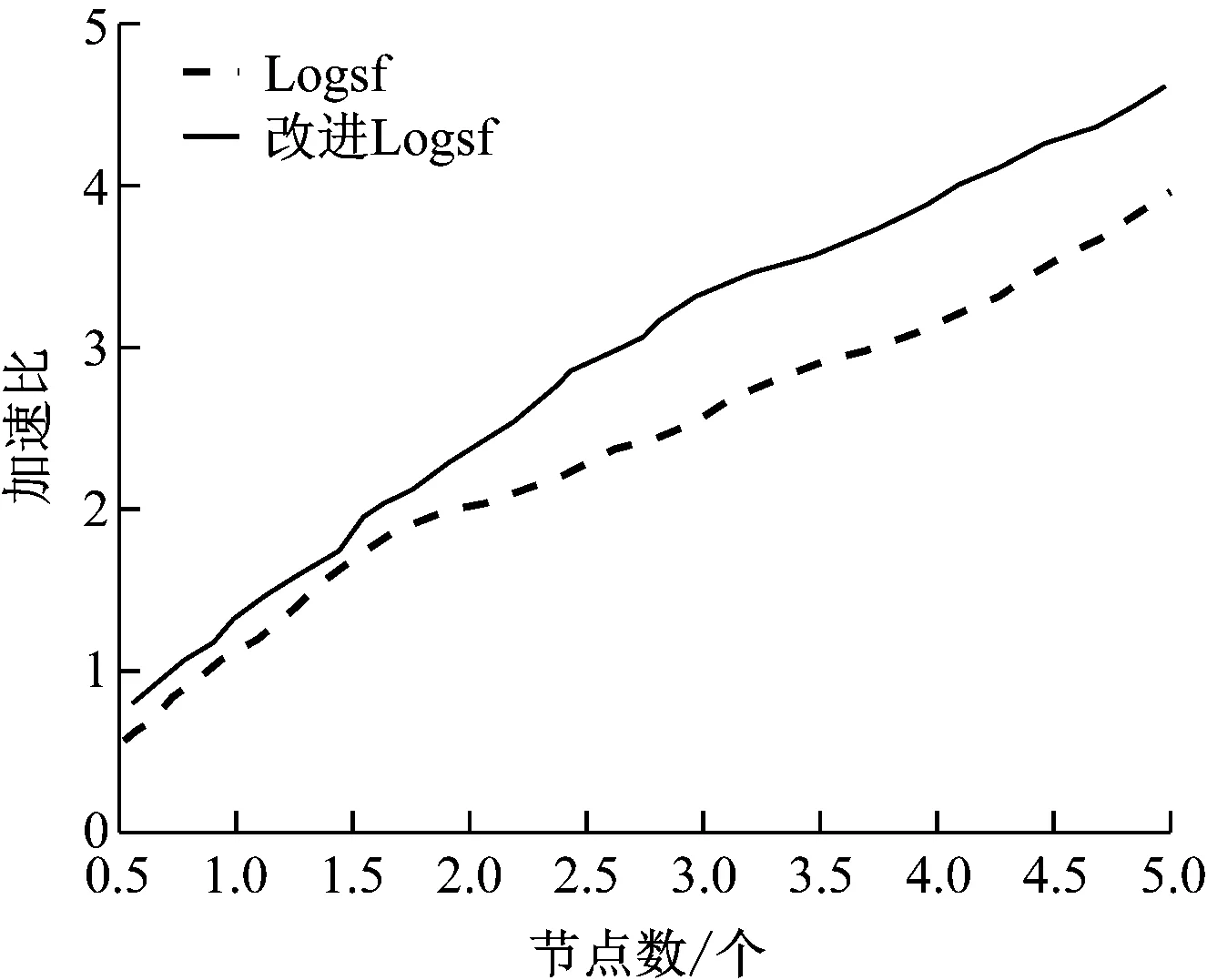
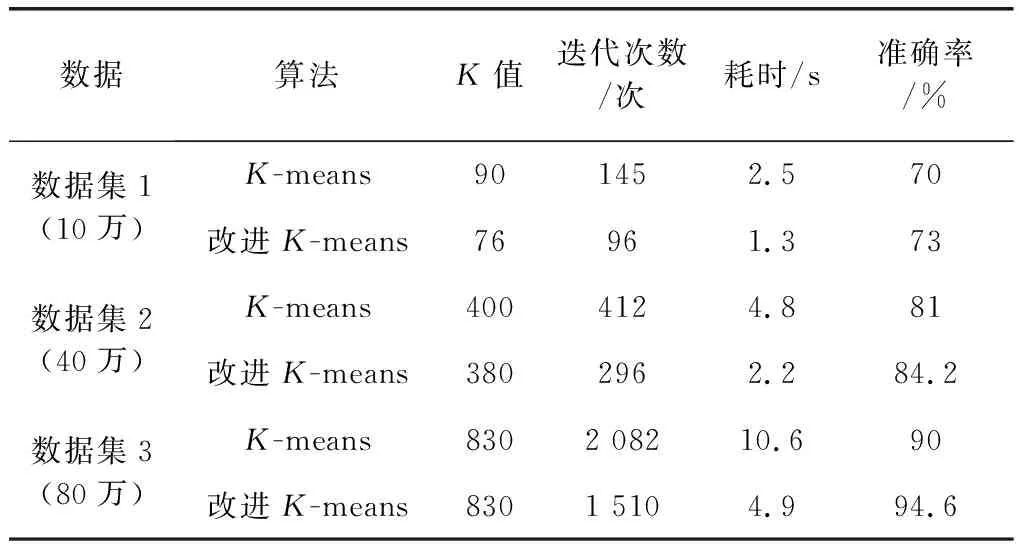
(3) 计算其他数据与canopy centerlist的距离。Dist[i] (4) 通过归类后得到了k个canopy。 (5) 计算k个聚类中心点。 (6) 计算每个数据与中心点的距离。将数据归类为Dist[i]最小的类。 (7) 将各类的平均值作为新的中心点。 (8) 再计算新中心点与canopy中心点的距离,按照(3)分类。 (9) 若达到收敛条件,停止循环;否则继续(6)—(8)。 具体流程图如图3所示。 图3 Canopy-K-means算法流程图 为了有效地对大数据进行降维和数据清洗,采用MapReduce方法,分别进行降维和数据清洗。在数据降维的时候,先采用梯度下降法求取最优权重值,采用Map函数根据权重大小将样本按照〈key,value〉存储。key为特征编号;value为数据编号。再采用Reduce函数将特征编号相同的样本放在一起存储到HDFS中。改进的K-means算法得到的异常数据,采用MapReduce方法处理也采用同样的方法处理。 为了验证本文所提方法的有效性和可靠性,选取某企业的3种传感器采集的信息进行仿真实验。选择其中10万条数据(100MB)作为训练集,另外分别选择40万条数据(200MB)和80万条数据(800MB)作为测试集。采用改进的Logsf和Logsf方法进行实验对比。各对比结果如图4-图7所示。 图4 准确率对比曲线 图5 训练集的加速比曲线 图6 测试集1的加速比曲线 图7 测试集2加速比曲线 选取经过改进后的Logsf算法降维的数据,采用本文所提的改进K-means算法进行异常数据清洗。分别对其准确率、运行时间和加速比进行分析。准确率的对比结果如表1所示。 表1 两种方法准确性对比 加速对比曲线如图8-图10所示。 图8 10万条数据加速比 图9 40万条数据加速比 图10 80万条数据加速比 从图4可以看出,随着样本数量的增加,改进的Logsf比传统的Logsf方法准确性有了很大提升。虽然数据量较小的时候,改进的Logsf低于Logsf的准确性,但是本文处理的是大数据,所以图4验证了改进后的算法更适用于大数据的特征提取。从图5-图7的对比曲线可以看出改进的Logsf的加速明显高于Logsf。以上实验说明了改进后的Logsf算法的有效性。 从表1可以看出,在对异常数据进行清洗的时候,传统的K-means算法准确率明显低于改进的K-means算法,从图8-图10的加速对比曲线可以看出,在处理相同数量级的数据时,改进的K-means算法比K-means算法的加速比更快,验证了本文所提方法的有效性。 针对大数据中含有的异常数据清洗问题,本文提出了改进的Logsf方法,选择特征,并进行数据降维处理,获得约简后的数据。采用Canopy方法对传统的K-means算法进行改进。然后采用MapReduce方法实现算法并行化。实验结果验证了改进的Logsf方法比传统的Logsf方法具有更高的特征提取准确度,改进的K-means算法比传统的K-means算法清洗数据后,具有更高的准确度和更快的处理速度,验证了本文所提方法的可靠性。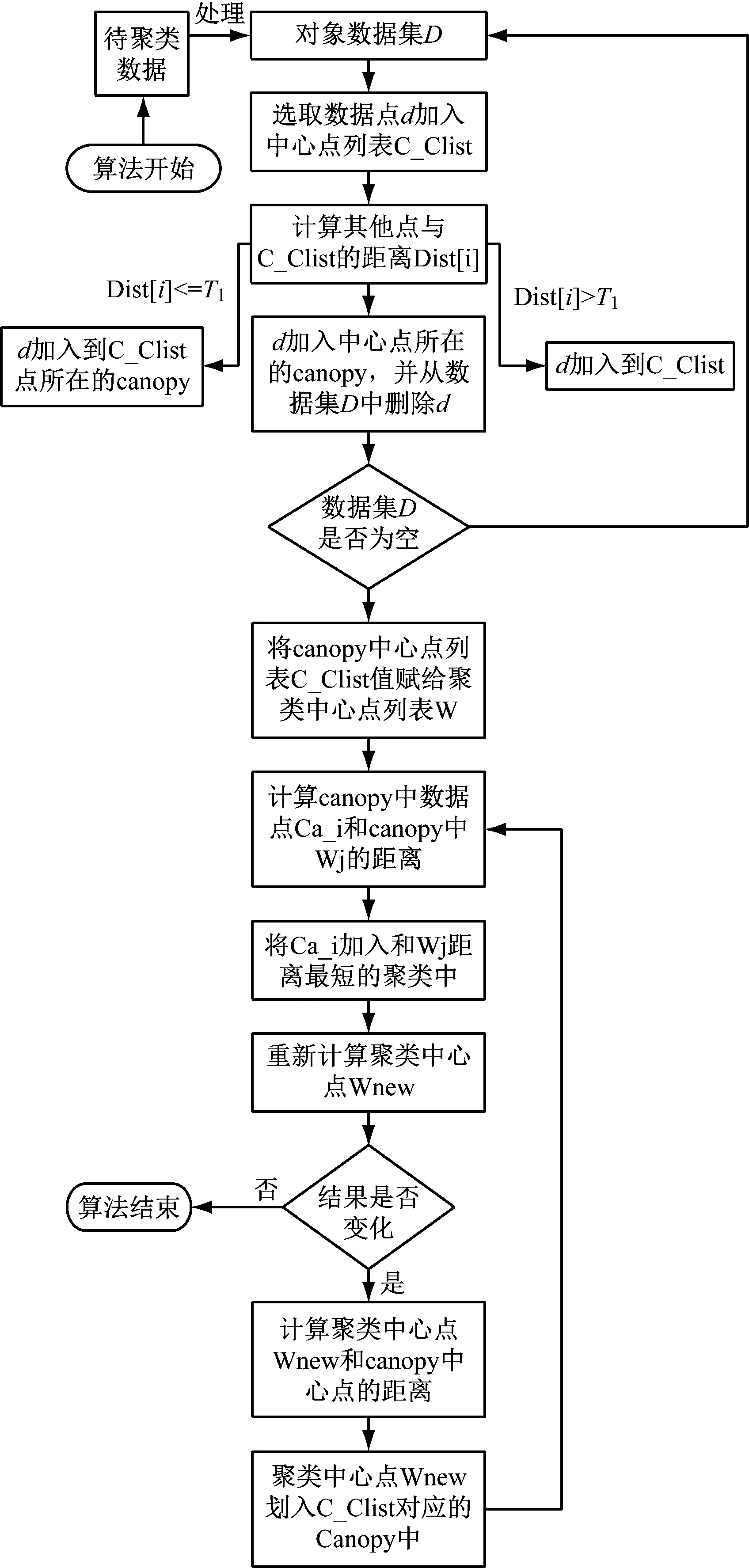
3 算例仿真
3.1 特征提取



3.2 数据清洗



3.3 结果分析
4 总结
