上下文感知的安卓应用程序漏洞检测研究
2021-12-08秦佳伟张华严寒冰何能强涂腾飞
秦佳伟,张华,严寒冰,何能强,涂腾飞
(1.北京邮电大学网络与交换技术国家重点实验室,北京 100876;2.国家计算机网络应急技术处理协调中心,北京 100029)
1 引言
近几年,安卓应用一直在快速增长中,但是随之增长的还有应用所产生的漏洞。2020 年,国家信息安全漏洞共享平台(CNVD,China National Vulnerability Database)收录安全漏洞中移动互联网漏洞占全年收录数量的8.0%。因为所有的软件漏洞都存在被攻击者潜在利用的可能[1-3],所以发现漏洞并修复它,才是避免软件遭受攻击的有效方法。2018 年,PIAnalyzer[4]分析并提取了PendingIntent权限绕过漏洞的规则,基于静态检测的方法实现对改漏洞的检测。目前,与Intent 机制相关的研究[5-12]主要关注APP 隐私泄露问题。过辰楷等[5]提出了一种基于安全要素语句插装的泄露检测方法。AmanDroid[7]通过跟踪APP 组件间的交互信息来识别隐私泄露问题。
另外,为了降低人工依赖和提高对未知漏洞的发现能力,基于学习的漏洞检测成为技术发展趋势之一[13-25]。基于学习的漏洞检测研究主要集中在Java 语言的漏洞方面。早期的基于学习的Java 源代码漏洞检测研究[21,24]解决了基于规则的漏洞检测方法依赖人工经验的问题,但是漏洞代码的抽象表示缺乏语义特征,从而影响漏洞识别的准确率。2017 年,Ma 等[22]提出将Java 代码转换成抽象语法树(AST,abstract syntax tree)的特征,然后采用机器学习模型来对Java 程序进行漏洞检测。AST 特征可以保留程序对象之间的语义信息,但是包含与漏洞代码无关的噪声数据会导致误报[26-28]。Java 程序不具有APP 的生命周期特性和组件间通信机制(ICC,inter-component communication),所以无法适用于检测无源码的APP 的漏洞。2018 年,王持恒等[13]依据APP 的流量数据和权限列表信息采用聚类方法检测广告漏洞,但是该方法仅适用于广告漏洞检测场景。2021 年,Gencer 等[29]研究直接依赖于时间的APP 漏洞,并采用时间序列、多层感知器等多种模型生成了漏洞预警模型。
基于学习的APP 漏洞检测缺少针对安卓本身运行机制所导致的漏洞的研究。现有的2 种特征提取方法会导致漏洞检测的准确率下降。其中,基于代码中关键字符串计数的特征方法无法表现语义信息,也无法体现漏洞的上下文关联信息;AST 的漏洞提取方法会存在误报[26-28]。在针对其他编程语言的程序漏洞检测方面[15-16,19-20,30],2019 年,Zou 等[15]针对C 语言的程序漏洞提出一种名为code gadgets的程序特征表示方法,由此设计并实现了基于深度学习的漏洞检测系统。因为C 语言的程序分析不涉及对回调方法的处理,所以该方法无法直接适用于APP 漏洞检测。安卓APP 不仅有Java 语言的漏洞,还有不正确地使用平台的应用程序接口(API,application program interface)所导致的漏洞,危害更严重。例如,安卓ICC 不仅允许同一个APP 的不同组件间进行数据传递,而且允许不同的APP 之间的数据传递。这就给APP 带来了安全风险——使用该机制实现的功能的各个对象的属性设置都可能导致漏洞。因此不能通过Java 代码的规则匹配检测相关漏洞。
要实现针对安卓本身运行机制的漏洞检测,且克服人工提取特征的局限性,需要解决以下3 个问题。1) 目前缺少可供深度学习使用的APP 漏洞数据集,如何获取一批可用的数据集?2) 面对安卓应用特有的ICC 方式和无主程序入口的运行启动方式,如何进行程序分析和漏洞特征提取?3) APP 漏洞特征表示方法方面,如何在不缺少关键信息的情况下对程序进行语义化的特征抽象?
为了克服上述挑战,本文以隐式Intent 通信漏洞(IISV,implicit Intent security vulnerability)和PendingIntent 权限绕过漏洞(BPPAV,bypass PendingIntent permission audit vulnerability)为研究对象,针对安卓运行机制导致的漏洞检测提出了一种上下文感知的安卓应用程序漏洞检测方法。该方法可以从APP 中提取出只与漏洞相关的代码信息,并且将特征代码中的自定义函数名与变量名进行统一格式化处理,既保留语义逻辑性也具有可读性。本文主要贡献如下。
1) 本文从GooglePlay 获取了5 000 个样本,采用工具和人工分析的方法对其进行漏洞标记,得到包含IIS 的漏洞样本1 806 个和包含PLP 的漏洞样本95 个,提取41 812 条特征代码段。经特征化处理后,本文数据集与APP 无直接关联关系,但是因为漏洞信息的敏感性,该数据集仅通过邮件提供。
2) 在APP 漏洞特征表示上,本文提出一种包含语义信息的特征抽象方法——CIS。该方法可以保留程序的执行流程的结构信息,从APP 中提取只与漏洞相关的代码信息,并且将特征代码中的自定义函数名与变量名进行统一格式化处理,既保留语义逻辑性也具有可读性。针对APP 没有明确的唯一主函数入口的情况,本文给出了9 个入口点,可以更全面地构建APP 内部代码逻辑与数据关系。
3) 基于CIS 方法,本文选取Bi-LSTM 算法构建了一个针对 APP 漏洞的深度学习检测模型VulDGArcher,针对本文分析的2 种漏洞,其识别准确率达到了96%。
2 代码语义特征化
漏洞代码特征化应最大化保留语意信息和影响漏洞形成的因素。本文提出了一种特征抽象方法CIS,利用APP 漏洞点的上下文信息,提取与漏洞点有关的语义信息,减少无关变量和函数信息。
2.1 漏洞语义特征
APP 源码中包含很多逻辑处理流程,一个功能的实现需要用到其他的变量或者方法。在对某一种漏洞分析时,本文只关注和这个漏洞触发点相关的变量和方法,其他代码在这种场景下都是噪声。
以IIS 为例,代码1 是一个APP(MD5 是51da27661a8eff2f0cb37b7756e576b3)中使用隐式Intent 的方法实现发送邮件的功能函数,第11)行~第15)行实现了一个隐式Intent 对象,该对象中加入了过滤条件Intent.ACTION_SENDTO,同时该对象中包含了全部邮件内容。该APP 并没有设定发送邮件的APP,也没有强制设置用户选择所有可以响应该Intent 的应用程序,这种现象就会导致该APP 存在IIS。
代码1IIS 的示例代码
综上,IIS 风险与Intent 的使用有关。所以从APP 的源代码角度分析,该风险应主要关注Intent的对象及其用到的方法。如代码1 所示,影响该漏洞的代码只有第12)行~第18)行,其他是噪声数据。
代码2 是某个Android 系统中“设置”APP(CVE-2014-8609)使用PendingIntent 方法实现添加用户功能。在第3)行中,一个PendingIntent 对象mPendingIntent 被创建,并带有一个空的Intent 对象。因为是系统内置APP,所以mPendingIntent 对象具有系统权限。当恶意 APP 注册接收该mPendingIntent 对象时,因为mPendingIntent 注册的Intent 是空的,所以恶意APP 可以修改Intent 对象中的Action 和Extra data 属性,再以具有系统权限的mPendingIntent 对象发送出去,以此达到权限绕过目的。
代码2PLP 的示例代码
综上分析,PLP 与PendingIntent 和Intent 的使用都有关,所以代码2 中影响该漏洞的代码只有第3)行和第4)行。
特征化方法既要将漏洞相关代码表示出来,又要保留代码之间的语义信息的特征化方法。本文针对这一需求定义了一种特征化代码的方式CIS,如式(1)所示。它是由全部影响漏洞存在的相关变量的上下文内容Ci组成的,也是由疑似漏洞点的直接或间接相关的所有代码组成的调用序列。
如式(2)所示,Ci是一个有向图,由一个相关变量i的前向关系语句和后向关联的语句组成;vi是第i个变量的关系图中的某个调用语句。当同一个变量的数据从vik传递到viw时,这2 个点之间存在边eikw。
代码3 是代码1 进行CIS 处理后的结果。第1)行表示声明了一个Intent 对象且该对象的临时编号是10;第2)行表示对编号为10 的这个Intent 对象进行了初始化操作且初始化传递的参数是String 类型;第3)行~第7)行依次表示编号为10 的这个Intent 对象进行设置属性等操作;第8)行表示Intent对象被发送。
代码3IIS 的CIS 示例代码
以上结果显示CIS 既包含Intent 相关的代码也保证了语句的原本调用序列。CIS 在包含疑似漏洞点的所有相关对象和语句的同时,去掉了与它无关的代码信息,顺序性保留了逻辑上的语义信息。
2.2 构建CIS
从一个APP 文件构建关于一个疑似漏洞点的CIS 的流程如图1 所示。
1) 反编译
本文对APP 进行漏洞分析的目标是APK文件,包含编译好的可执行文件。为了对源代码进行漏洞分析,本文基于WALA 实现了对APK 文件的反编译操作,从而获取到了APP 的Smali 形式的代码。
2) 构建控制流图
本文定义了如表1 所示的入口点,并以此为基础为安卓APP 构建必要的控制流图(CFG,control flow graph),如式(3)所示。
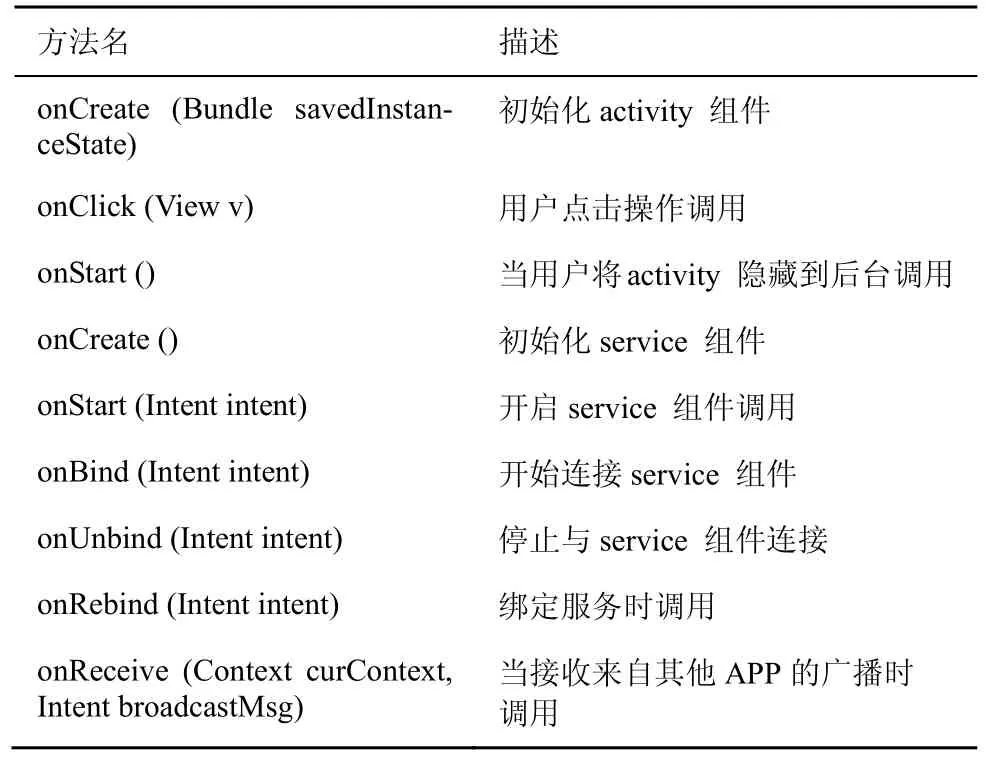
表1 定义的入口点
其中,N是全部节点集;程序中的每个语句都对应图中的一个节点nk,当nk存在调用nw的关系时,两者之前存在一条从nk指向nw的边ekw;nentry 和nexit 分别为程序的入口和出口节点。经过分析安卓的4 种组件的启动入口点和中间状态的转换关系以及安卓的UI 反射入口等特性。
3) 构建程序依赖图
程序依赖图(PDG,program dependency graph)是程序的一种图形表示,是带有标记的有向多重图,如式(4)所示。构建方法是以程序的CFG 为基础,去掉CFG 的控制流边,加入数据和控制流边。因此PDG 包括了数据依赖图和程序依赖图,数据依赖图定义了数据之间的约束关系,控制依赖图定义了语句执行情况的约束关系。PDG 全部节点集合为V',其中任意一个节点sk表示语句或控制谓词表达式,边E'表示程序组成部分之间的依赖关系,包括控制依赖和数据依赖。如果PDG 中的语句sk和sw可以通过控制流或者数据流来彼此关联,则两点之前存在一条边。因为PDG 既包含程序中语句之间的数据依赖关系,又包含控制依赖关系,所以可减少漏洞信息搜索空间。
4) 构建CIS
本文按照算法1 所描述的过程,选取一个疑似存在漏洞的风险点。如图1 所示,IIS 漏洞的疑似漏洞点是Intent
算法1基于疑似漏洞点构建代码抽象表示CIS'
输入存储切片代码tree Node,一个疑似漏洞点inp,APP 的程序依赖图PDG
输出疑似漏洞点的代码抽象表达式CIS'
CIS'包含自定义的变量名和API 等噪声数据,因此本节进一步优化数据特征以便模型更好地识别漏洞,优化过程如算法2 所示。
算法2对CIS'进行数据归一化处理
输入初步提取的所有疑似漏洞点的抽象代码特征CIS's
输出最终的代码特征CIS
①从APP 提出来的CIS'中包含了方法的异常处理信息,这些信息不会影响漏洞是否存在,但是会降低模型检测漏洞的准确率。经分析,这部分信息是在符号@后的字符。所以先获取@在CIS'中的位置Index,移除掉Index 后面的表示异常处理的字符串,得到新的CIS'。
②CIS'包含开发者自定义的变量信息。因为每个开发者自定义的变量命名不同,所以自定义变量就是噪声数据,会影响模型对漏洞的识别。本文将自定义方法进行统一的重新定义,计算出CIS'中每个自定义的变量vari,然后按照先后顺序i对其进行替换变成统一的命名VERi,这样CIS'中不同的自定义的变量只是编号不同,其他的都是用统一的VER 字符串表示。利用同样的方法,依次将自定义的方法名变成FUNi,自定义的类名变成CLASSi。不同的类、方法和变量将按照后边的序号i进行区分,相同的类、方法和变量在不同位置命名保持一致。
③代码特征化的结果中,系统API 的方法都是展示的完整的全限定位名,如Java/lang/String,也就是包含了类所在的包名。因为API 的类名就可以表现出该API 的行为和意义,包名对于漏洞的识别是无意义的变量信息。尽管存在少量的API 具有同样的类名,但是存在于不同的包名下,这些少量的API 主要是监听类,并没有实际的行为意义,即不会影响漏洞的存在。所以计算出CIS'中的每个以上类别的系统API(apii),去掉所有的包名只保留类名。例如,Java/lang/String 简化后为String。
④对于上述几步的处理优化后,本文对同对象的调用方法进行再一次的组合,最大限度地还原APP 的原本语句表达形式。最后得到含有最小噪声数据的代码特征值即CIS。
3 基于语义代码片段的漏洞识别模型
本文基于CIS 采用Bi-LSTM 算法构建了一个保留语意信息的APP 漏洞检测模型VulDG Archer,图2 为其训练过程。采用深度学习模型可以解决人工提取漏洞规则的漏报问题,并能克服依赖专家经验对新漏洞识别的局限性。
1) 构建CIS
构建CIS 的过程如算法3 所示。
算法3构建APP 的CIS
输入待分析的安卓应用APP,所有的入口函数EPs,疑似漏洞点集合inps
输出漏洞特征CISs
21) end for
22) 按照上述过程构建PDG
23) 按照算法1 构建一个疑似漏洞点inp 的CISs
①本文基于WALA 对APP 逆向处理得到smali 格式的代码。基于所有的入口点EBs 处理得到APP 的代码块集合EntryBs。
② 从集合EntryBs 中取出任意2 个不同的代码块ebi和ebj,如果从ebi的最后一个语句到ebj的前项存在条件分支或无条件分支,或者如果ebj以程序顺序紧随ebi且ebi不以无条件分支结束,则在ebi的基本块中添加一个有向边eij指向ebj。依次对所有的代码块进行同样的操作,就构建了APP 的CFG。
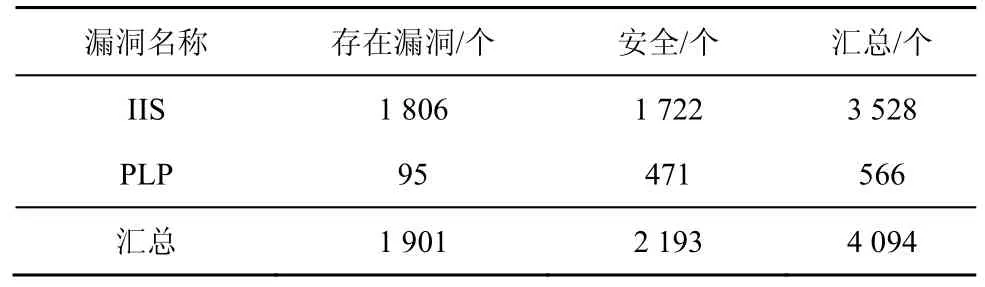
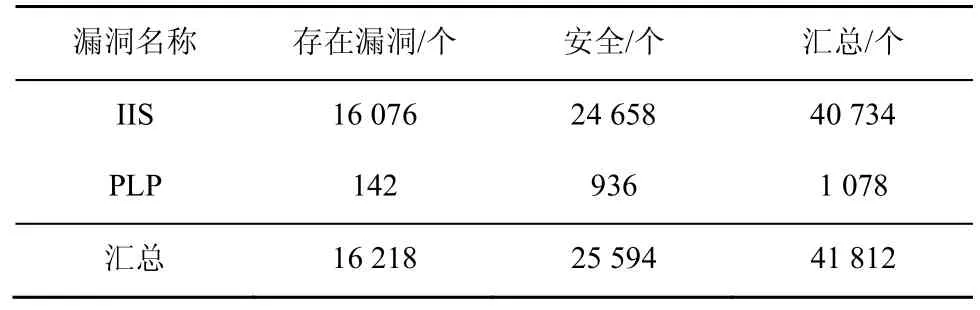
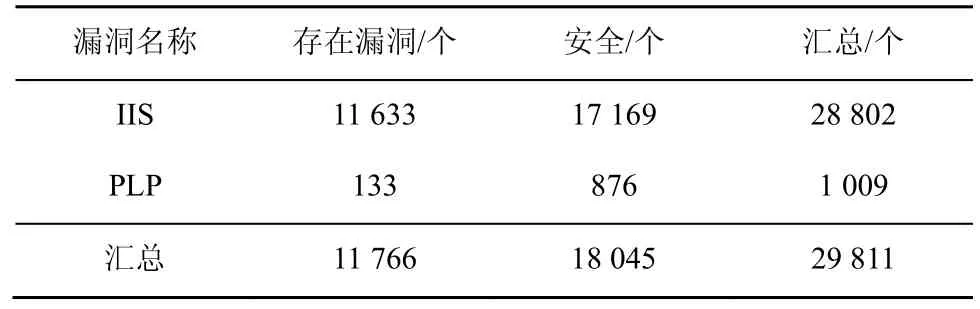
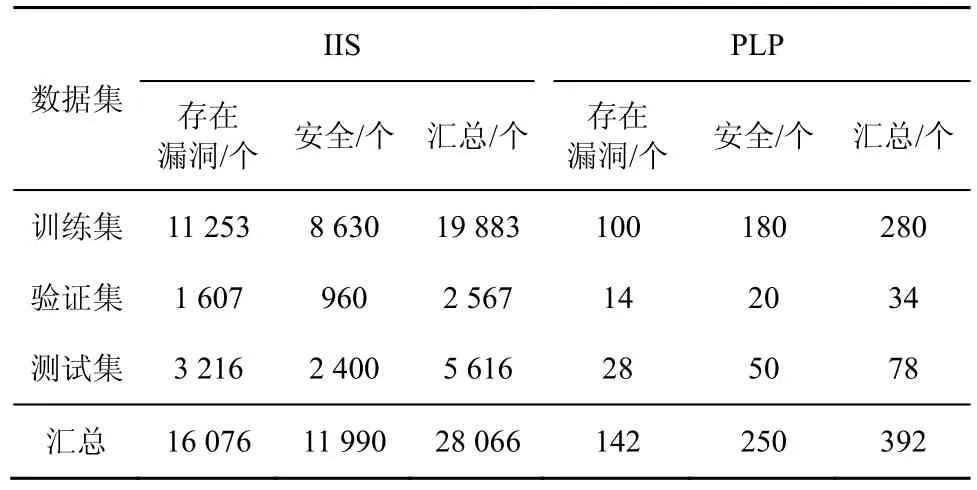
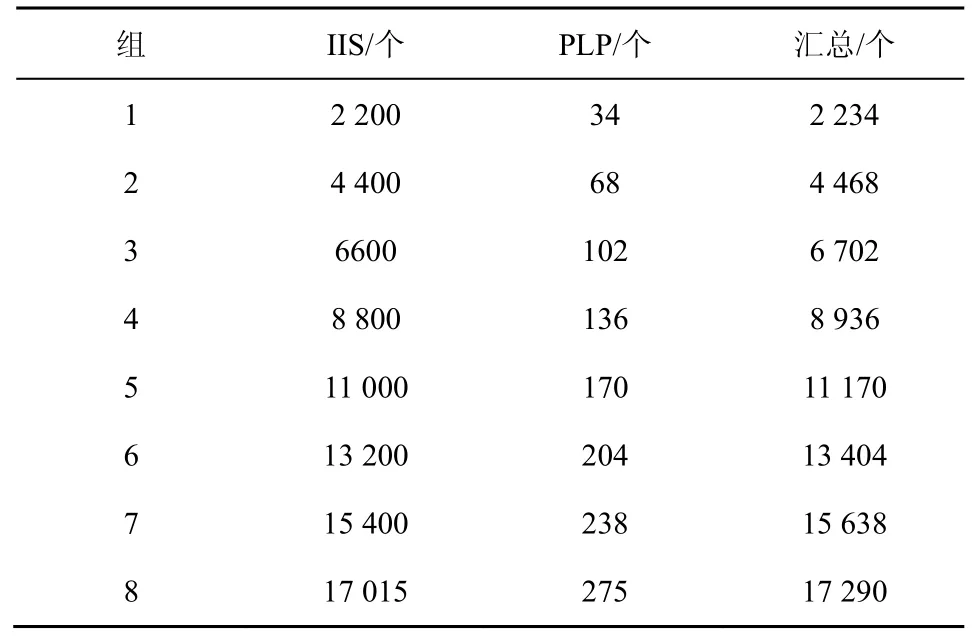
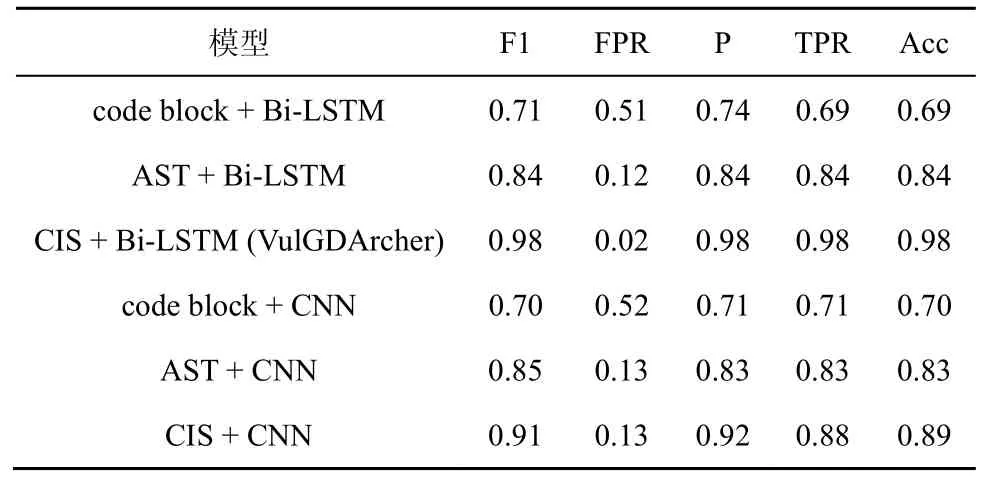
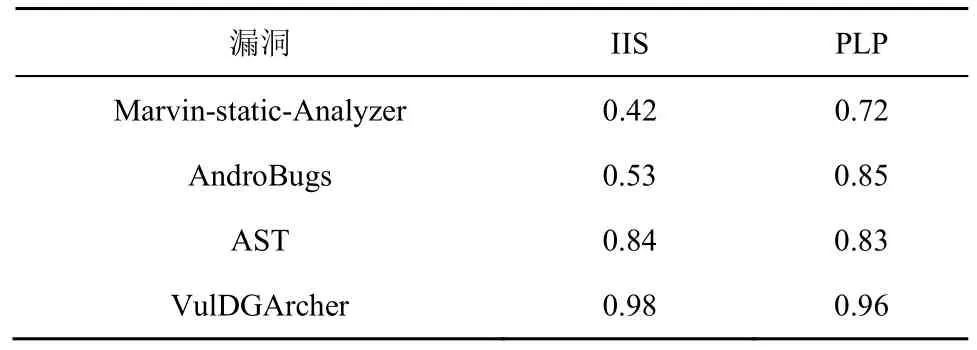
③CFG 只能呈现APP 的不同块之间的调用关系,为了分析具体APP 内部的数据传递过程,还要进一步得到APP 的数据传递情况。基于CFG 计算所有偏序PO 和所有的控制依赖关系CD。针对CD中的每一个偏序关系bbi→bbj,对于bbj中的每一个语句表达式vjk,都存在一条从bbi指向vjk的边eijk。这样就会得到语句之间的控制关系。对于任意2 个存在数据依赖关系的语句u与v,如果其所在的偏序关系为bb(u) ④ 基于PDG,本文使用算法1 对所有的疑似漏洞点构建对应的代码特征CIS。这样得到的是关于每一个疑似漏洞点的包含语义的代码特征,其中还记录了这个疑似漏洞点所在的类名和方法名。 2) 数据集标注 CIS 的抽象特征没有包含它是否存在漏洞的标签,这一步将提取的代码特征进行漏洞打标签。 ①本文将APP 文件中的疑似漏洞点所在的函数使用MobSF(mobile security framework)进行漏洞识别,对于识别出来的漏洞信息,本文再一次进行人工校验,最终整理出每个APP 的漏洞信息。漏洞信息包含包名(pj)、类名(cj)、方法名(mj)和漏洞类型(vjq),如式(5)所示。 ② CIS 中的一个疑似漏洞点ipj如式(6)所示,其中表示包名,表示类名,表示方法名。 3) 训练模型 经过上述阶段后的代码特征仍然是字符串的形式,这种格式的特征模型是无法直接识别的,所以也就无法将它当作输入变量。本文通过算法4 将其转换成模型可接收的向量,具体过程如下。 算法4训练模型算法 输入所有漏洞特征CISs,模型定义的向量长度阈值w 输出训练好的模型model ①本文使用word2vector 对字符串形式的代码特征CIS 进行向量化处理,得到模型可使用的词向量binData。因为训练数据需要保证统一的长度,所以应对binData 进行归一化处理。如果bin Data 长度小于规定的阈值w(本文w=200),在bin Data 后进行补0 操作;如果bin Data 长度大于阈值w,从后边进行截断操作。最后统一存在训练数据集train Data 中。 ② APP 的漏洞代码特征是基于数据流和控制流构建的,其中包含了疑似漏洞点的上下文相关调用逻辑代码。深度学习算法应能够学习到漏洞代码块的调用逻辑。其次,APP 是否存在漏洞受疑似漏洞点的前向代码和后向代码的影响。因此选择的深度学习网络应当满足如下特点:具有记忆性可以获取上下文关系;支持长句子,即长代码块;前向语句和后向语句的影响都能覆盖。技术成熟的深度学习网络中,Bi-LSTM 网络同时支持以上3 个特性,可以作为APP 漏洞检测的深度学习网络。 由于漏洞代码特征CIS 都是较长的语句,为了学习长句子的语义信息,本文选取的Bi-LSTM 模型中加入注意力机制,训练后得到漏洞识别模型。 本文用实验回答以下3 个研究问题。 RQ1:CIS 能否识别出APP 的多种漏洞? RQ2:与现有的APP 漏洞检测方法相比,VulDGArcher 的效果如何? RQ3:VulDGArcher 的效率如何,是否具有实用性? 因为相关的研究成果还没有开放出可用的安卓漏洞样本数据集,所以本文从Google Play 获取了5 000 个APP 样本,先用安卓漏洞检测工具MobSF 识别出APP 的疑似漏洞点和初步的漏洞标记,再对检测后的APP 进行人工的源码分析,分析应用程序中的疑似漏洞点上下文的数据流,标定出的所有APP 中存在IIS 或PLP 的样本数量如表2 所示。表2 中的安全是指APP 使用对应的API 操作且安全的样本。因为存在同一个APP 同时存在IIS 和PLP 这2 种漏洞,所以在数据统计时没有去重。 表2 数据集中存在不同的漏洞APP 数量 对APP 进行CIS 代码特征化处理后,现有APP样本中,属于某种漏洞的CIS 特征条数如表3 所示。为了对比实验,本文统计了现有APP 中存在漏洞的原始代码文件(.class)的数量,如表4 所示。因为同样一个源代码文件(.class)可能存在多个同类别的漏洞且表4 中记录的是原始代码的文件数(.class文件数),所以各种漏洞的数量和表3 所展示的特征化后的结果不一样。 表3 数据集中存在不同的漏洞CIS 数量 表4 数据集中疑似漏洞点原始代码段数量 实验环境为一台64 GB RAM,3 TB SSD,Intel Intel Xeon CPU E5-2640 v2 2.00 GHz 服务器。 本文的实验是检测多个漏洞,所以是一个多分类问题。本文分别计算每个漏洞的对应的指标值,然后将全部类别的对应指标值进行取平均值。以第i类漏洞的检测为例,本文的评价指标如下。 真正类TPi:样本的真实类别是i漏洞,模型预测的结果也是i漏洞。 假负类FNi:样本的真实类别是i漏洞,模型预测的结果不是i漏洞。 假正类FPi:样本的真实类别不是i漏洞,模型预测的结果是i漏洞。 真负类TNi:样本的真实类别不是i漏洞,模型预测的结果不是i漏洞。 误报率(FPR,false positive rate):不是i漏洞的样本被预测成i漏洞的占比。 召回率(TPR,true positive rate):真实存在漏洞的样本判定为存在漏洞。 精确度(P,precision):i漏洞的样本被预测为漏洞的比例。 F-Measure (F1):精确度和召回率加权调和的平均。 精度(Acc,accuracy):判为漏洞的样本数量占据样本总数量的比例。 1) 回答RQ1:CIS 特征在漏洞检测上的有效性 本文想验证基于CIS 特征的深度学习检测模型是否能够正确地检测出漏洞,并且是否可以实现多种漏洞的检测。本文选取了2 种安卓漏洞IIS 与PLP。在算法的选择上,由于CIS 的特征包含了interest point 的上下文,因此选取了具有后向反馈的Bi-LSTM 作为模型的算法。 如表5 所示,本文按照一定的比例将每种漏洞的数据拆分成了训练集、验证集和测试集。虽然其中IIS 的数量大于PLP 的数据量,但是在针对漏洞的CIS 特征中包含了interest point 的上下文语义信息,这样不同的漏洞之间的实现语句的明显不同,所以CIS 会有明显的差别。这样不同漏洞之间的数据量的差距也不会影响模型识别的结果出现样本不均衡的假阳性问题。从图3 中可以看出,CIS 特征在训练过程中随着训练迭代次数的增加,训练集和验证集的auc 参数都在逐步增加并逐渐达到一定的平稳状态,采用时训练集和验证集的loss 参数都在逐步的下降并达到平稳态。这说明基于CIS 的特征是可以实现针对安卓多种漏洞检测。 表5 用于模型训练和验证的数据集的分布 为了进一步验证基于CIS 特征的模型的其他指标项随着训练样本数量的不同的变化情况,本文采用不同的训练集进行模型训练,训练后的模型都采用同样的测试数据集进行测评模型的各种指标项。在保证测试集不变的情况下,本文将表5 中的训练集分别拆分成8 组,详细如表6 所示。本文针对每组训练集都采用同样的模型和参数配置,图4显示的是不同的训练集下的CIS 的特征的模型的漏洞检测指标变化。从图4 可以看出,随着训练样本集的扩增,模型的精确度、召回率、F-Measure和精度都在逐步增长并达到最好的98%,误报率逐步下降到2%。 表6 用于模型训练和验证的数据集的分布 基于CIS 特征的深度学习检测模型VulDGArcher可以正确地检测出APP 中的多种漏洞。Bi-LSTM 算法可以捕获长句子的双向语义信息,基于该算法的漏洞检测模型精确度可以达到98%,所以Bi-LSTM 算法更适用于VulDGArcher 的检测任务。 2) 回答RQ2:VulDGArcher 与不同的漏洞检测方法进行对比漏洞检测效果 为了验证VulDGArcher 中CIS 的漏洞特征方法的有效性,本文采用不同的模型算法和不同的特征提取方法进行交叉实验。本文在模型算法方面选取Bi-LSTM 和CNN;在APP 的漏洞特征表示方法方面选取APP 的Java 源代码文本特征[24]、APP 的AST 特征[22]和CIS。APP 的Java 源代码文本特征(CB,code block),就是对待检测的目标APP 进行逆向处理,获取其源代码信息,去掉这些源代码信息中无意义的标记符号,最后转换成深度学习模型可识别的向量。代码4 是一个APP 的IIS 漏洞原始代码样例。APP 的AST 特征就是将APP逆向获取出来的源代码信息进行AST 表示,去掉其中的特殊标记符,然后将其转换成深度学习可识别的向量信息。图5 是代码4 所示的漏洞方法的AST 表示,由于篇幅限制,图5 中只展示了与Intent 相关的AST。 代码4IIS 的示例代码 表7 是不同模型在相同测试集上的结果。从表7 可以看出,基于原始的代码做漏洞检测模型的误报比较高,达到51%的原因包括:1) 原始的代码中包含了大量和漏洞形成无关的噪声数据;2) 原始代码中的自定义方法在每个APP 中都是不一样的。相比较,VulDGArcher 在代码特征化的过程中提取的是疑似漏洞点的语义上下文信息,去除了所有无关的代码,并且对于APP 自定义的方法名和类名也进行了归一化处理,这样才能使VulDGArcher 的误报率和漏报率很低。图6 可以更加直观地反映VulDGArcher 与基于其他2 种特征化方法的模型的效果。由图6 可知,VulDGArcher的APP 漏洞检测效果更好。CNN 的漏洞检测模型虽然也可以识别出漏洞,但是模型测试的各个指标都低于Bi-LSTM 算法。图7 是同样的数据下2 种算法的ROC 曲线。从图7 可以直观地看出,Bi-LSTM 算法更适合CIS 特征。 表7 不同类型的代码特征的数据进行模型训练的效果 为了验证上述观点,本文提取一个存在IIS 风险的APP,在实验验证过程中,VulDGArcher 可以识别出它存在该风险,但是基于原始代码文件的模型无法正确判断该APP 的这个风险。代码5 是代码4经过VulDGArcher将原始代码进行语义特征处理化后的结果。从代码5 中可以看出,特征化后的代码只包含和IIS 风险相关的语法信息。 代码5VulDGArcher 对IIS 提取特征的结果 相较于原始代码,代码5 去除了很多无用的噪声数据。这也反映了VulDGArcher 在漏洞识别上具有很好的效果,主要取决于基于语义的代码特征化处理。 通过上述结果可以看出,基于CIS 漏洞特征化的深度学习检测模型在APP 漏洞检测上效果更优。因为CIS 相较其他2 种方法提取的漏洞特征去掉了无用的代码信息,且包含的信息是疑似漏洞点的上下文相关的代码信息。 3) 回答RQ3:VulDGArcher 与不同的漏洞检测方法验证实用性 本文通过实验从检测漏洞的效率角度评估VulDGArcher 是否具有实用性。本实验增加2 种开源的基于规则的安卓漏洞检测器:AndroBugs 和Marvin-static-Analyzer。它们在Github 上具有很多的forks and stars,都支持IIS 脆弱性检测,但是不支持PLP 漏洞检测。本文将基于PIAnalyzer[4]分析出的 PLP 检测规则配置在 AndroBugs 和Marvin-static-Analyzer 工具中,使工具支持对2 个漏洞的检测。本文从测试的数据集中随机地选取了100 个APP,然后分别采用Andro Bugs、Marvinstatic-Analyzer、基于AST 的深度学习漏洞检测模型和VulDGArcher 进行漏洞检测。如表8 所示,针对同样的漏洞,基于学习的漏洞检测方法的准确率高于基于规则的检测方法。因为这2 个漏洞的检测方法需要考虑到漏洞点的上下文环境中涉及的多种对象属性配置,而基于规则的检测方法无法覆盖上述条件,所以检测准确率相对较低。 表8 不同检测方法的准确率 图8 是不同工具的耗时情况。VulDGArcher 的耗时主要是代码特征化处理,模型的漏洞识别部分接近毫秒级。因为VulDGArcher 需要构建APP 的PDG,然后对提取出来的特征进行向量化处理,所以这部分处理是耗时的过程。虽然如此,VulDGArcher 平均在5 s 以内就可以完成对一个APP 的漏洞检测。图9 和图10 分别是各漏洞检测工具的CPU 消耗比例和内存消耗比例。从图9 和图10可以看出,VulDGArcher 的内存消耗最多为22%,远低于Marvin-static-Analyzer 的48%;CPU 资源使用最多为30%,并且随着运行逐渐保持低于10%。 同种运行环境下,本文将VulDGArcher 与其他3 种漏洞检测引擎进行比较,从准确率、耗时和资源消耗等方面衡量发现,VulDGArcher 的代码特征化是相对耗时的,但是并不是极其耗费资源的。所以本文建议通过并发运行平衡掉耗时的缺点。 本文针对现有基于学习的APP 漏洞检测方法的特征表示结果缺乏语义信息而影响漏洞检测准确率的问题,提出了一种包含上下文语义信息的特征抽象方法CIS,并对由APP 的API 误用导致的漏洞提出了一种上下文感知的检测方法。CIS 可以从APP 中提取只和漏洞相关的变量信息,并且可以消除开发者自定义代码的类名、方法名和变量名对模型检测效果的影响。本文基于CIS 采用Bi-LSTM 和注意力机制构建了一个 APP 漏洞检测模型VulDGArcher。与基于AST 和原始代码为特征化的检测方法相比,VulDGArcher 可以有效识别APP 不正确使用安卓平台的API 所导致的漏洞。此外,本文构建了一个包含41 812 条特征代码段的数据集。4 实验和结果分析
4.1 数据集和实验环境
4.2 评价指标
4.3 实验分析
5 结束语
