基于轨迹数据的出租车交接班时空分布识别方法
2021-12-07邹复民罗思杰陈志辉廖律超
邹复民,罗思杰*,陈志辉,廖律超
(1.福建省汽车电子与电驱动技术重点实验室(福建工程学院),福州 350118;2.福建省北斗导航与智慧交通协同创新中心(福建工程学院),福州 350118;3.数字福建交通大数据研究所(福建工程学院),福州 350118)
0 引言
交通轨迹数据暗藏了城市丰富的潜在信息,蕴含了交通结构化要素[1-2],可有效挖掘出人车流动模式、路网变更、能源消耗分布[3-5]等,对城市交通资源配置、管理和规划有着非常重要的指导作用[6]。出租车是城市交通的重要组成成分,其交接班的地点与时间是否合理对出租车的运行效率、公众的便捷出行以及城市的交通状况的有着重要影响[7]。
出租车交接班行为是指前一位驾驶员停止运营且车辆停止运行到后一位驾驶员接替车辆开始运行的过程。交接班地点为交接班行为中停留的地点,交接班时间定义为前一位驾驶员交完后,后一位驾驶员接的时间[8]。目前,针对出租车交接班的时间与地点的理想布局与实际布局已展开了大量研究。文献[9]基于出租车的使用效率和出租公司的收益为综合指标,建立出租车交接班时间优化模型,给出了最佳的出租车交接班时间段,文献[10]建立了预测出租车需求量的数学模型,提供了出租车数量、交接班地点的配置建议,这两种出租车交接班方法理论上具有参考价值,但真实的交接班存在各种不可控因素,理想模型与实际情况会有较大区别。文献[8]利用多尺度滑动窗口模型对出租车交接班事件在多个时间、空间尺度进行搜寻,并定义交接班事件支持度对搜寻结果进行评估,借用卷积神经网络中的卷积窗的思想,对交接班行为与时间进行滑窗检测。这种方法会受到时间、空间窗尺度的约束,即交接班行为必须在设定好的同个时间、空间窗内进行才能够被识别,缺乏一定的灵活性;其次,此方法以停留次数为交接班地点的参考因素,容易造成交接班地点大多聚集在待客、送客的人流量密集区域,影响交接班地点的真实性。文献[11]通过对出租车交接班行为进行数学建模,发现交接班时空序列特征近似符合高斯分布,通过训练样本得出高斯模型的拟合参数对出租车交接班行为进行识别,以时序特征间隔时间、间隔距离、事件时长、空载距离四项参数为交接班点的评定标准,但不同城市的各项特征可能存在差异或交接班行为与四项特征的关联性不强,交接班识别的准确性也会因此受到影响。文献[12-13]通过IC 卡记录数据与轨迹数据相结合来挖掘交接班行为。IC卡数据中记录了运营者的上下班时间,读取前一位运营者的下班时间与下一位的上班时间之间间隔时间即可得到交接班时间范围,对交接班时间范围内速度为0 的停留点进行聚类,簇中存在多天的停留点即交接班地点。该方法提取数据中存在的交接班特性进行交接班识别,克服了模型拟合的弊端,适用范围广。但仍存在一些不足:1)未对停留点分类进行深入研究,速度为0 的点可能是车辆非运营状态的停留点,可能也为车辆运营状态的停留点,只有在车辆非运营下的停留点才有可能为交接班地点,将速度为0 的点作为交接班的识别缺乏科学性。2)交接班地点识别没有时间间隔判定,可能会存在小于8 h或大于12 h工作时间的非交接班事件误判行为。3)交接班时间识别过分依赖于IC 卡打卡数据,而许多出租车运营监管系统并未要求驾驶员上下班打卡,以致于IC 卡打卡数据缺失将无法识别交接班时间,从而具有一定局限性。
针对以上存在的问题,本文提出了一种既有普适性又有科学性的交接班识别算法——基于轨迹数据挖掘的交接班识别算法。首先,深入分析轨迹数据中的语义信息,规整歧义信息,精准提取出租车停留点;其次,计算出轨迹点最佳聚类半径,保证密度聚类算法DBSCAN(Density-Based Spatial Clustering of Applications with Noise)[14]对停留点聚类的最优范围以保证潜在交接班地点数据的可靠性和科学性;然后,通过地点到达频繁度指标与停留周期指标对潜在的交接班地点进一步筛选,剔除不符合交接班特征的数据,确保了交接班地点的准确性;最后,基于交接班地点的时间维度,对每辆车的所有交接班时间进行核密度估计[15],挖掘出交接班地点的时间规律,克服了IC 卡识别的局限性。以福州市的出租车为数据样本,对福州市出租车的交接班时间与空间分布进行挖掘,有效地识别出5639个出租车交接班地点,时间主要分布在凌晨4:00~6:00与傍晚16:00~18:00,实验结果符合出租车交接班规律。
1 相关概念与定义
出租车交接班时空分布识别主要基于轨迹数据挖掘,对出租车的停留、移动行为中隐含的信息进行知识发现。其中涉及部分交通领域的专业名词,因此对其相关概念进行描述与定义。
1)交通轨迹是车辆有目的的移动,由时空点序列构成,主要包含有时间、地点、速度等数据属性,如定义1所示。
定义1轨迹数据由多个轨迹点构成,Traj={D0,D1,…,DN},轨迹点包含有位置P、时间T、速度V等属性,Di=(Pi,Vi,Ti),Pi为经纬度信息P={(Plon0,Plat0),(Plon1,Plat1),…,(PlonN,PlatN)},Ti是时间全序轴上的点值,均来自于实数域,Vi是在Ti时的速度信息,0 ≤i≤N,∀i≤j,Ti≤Tj。
2)轨迹数据根据速度属性可划分为停留点数据和移动段数据。停留点即速度为0的连续轨迹点,移动段即速度不为0的连续轨迹点,如定义2所示。
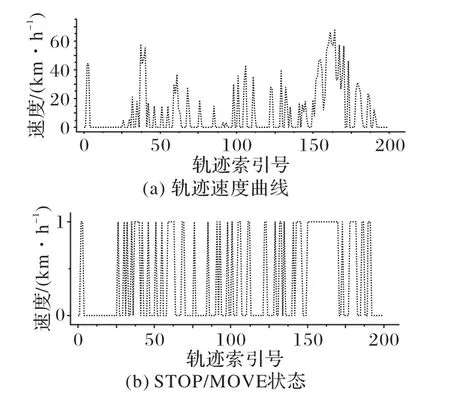
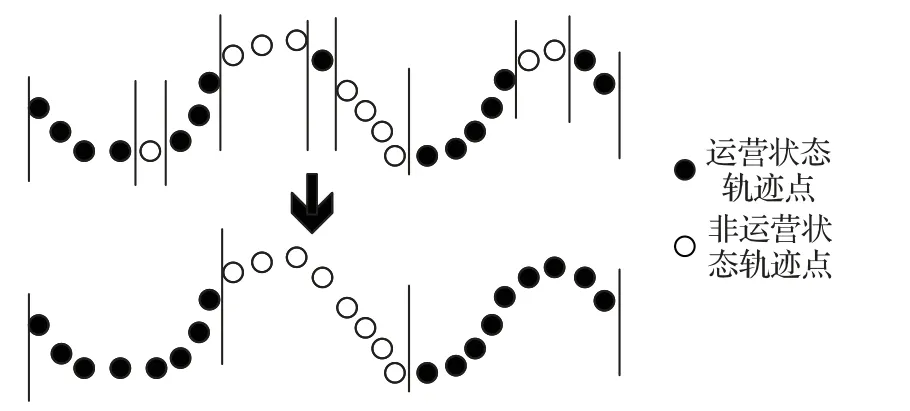
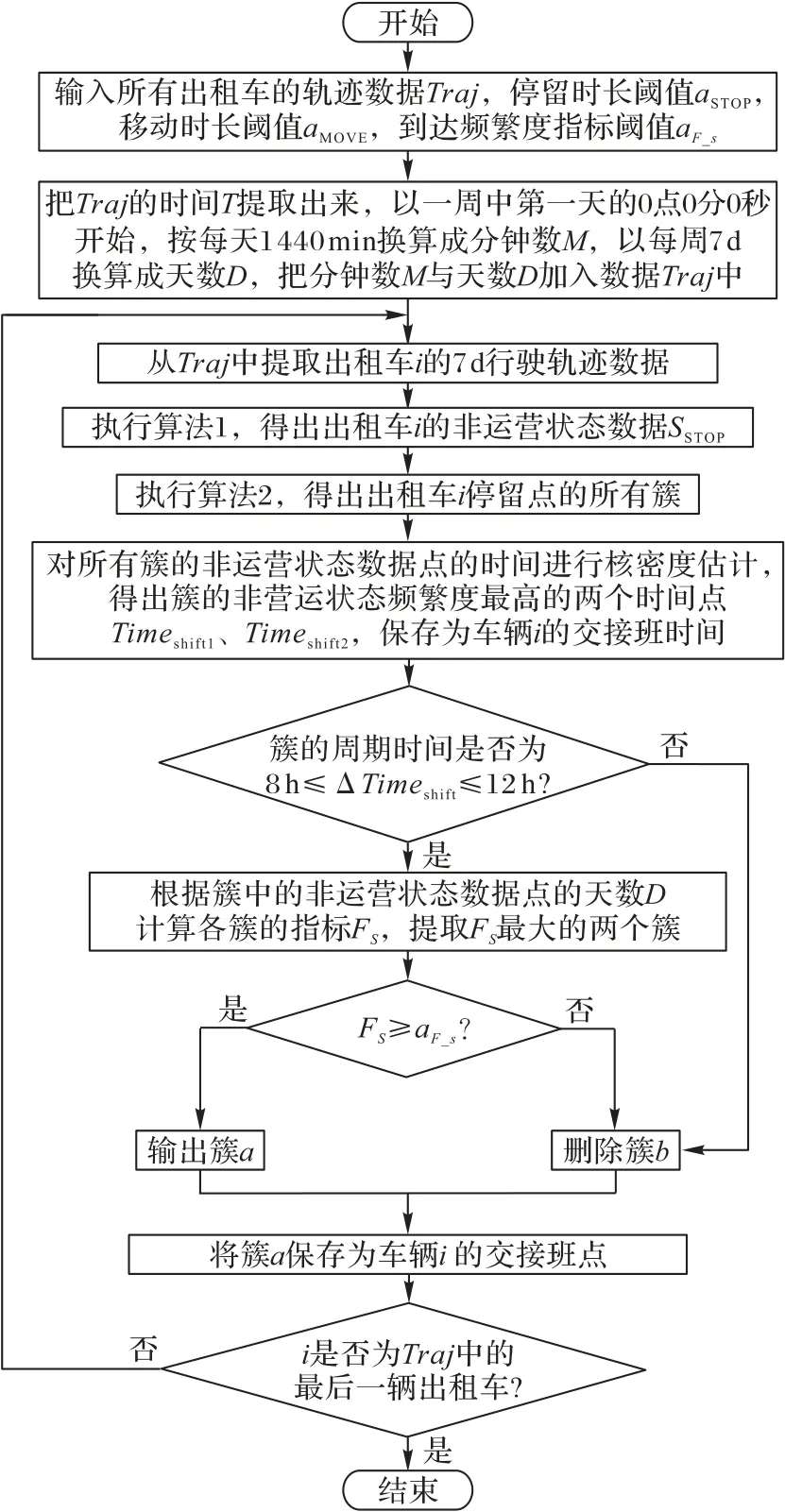
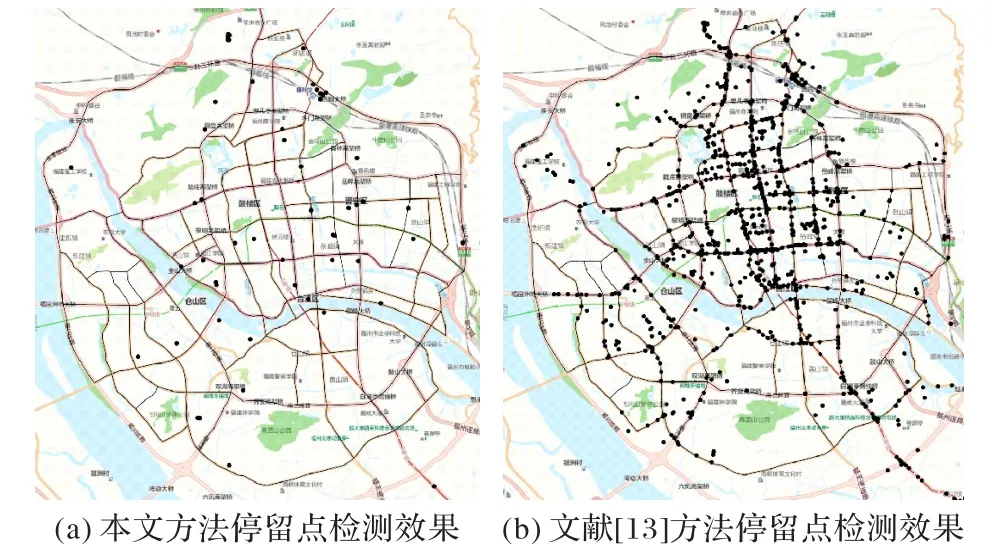
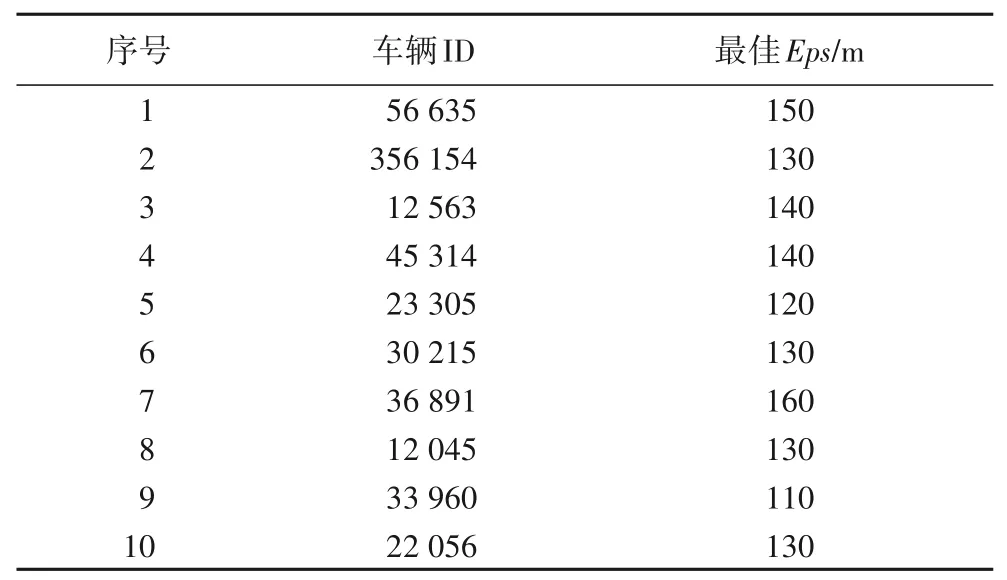
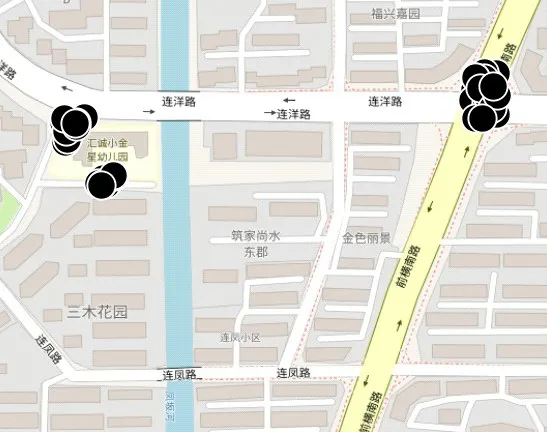
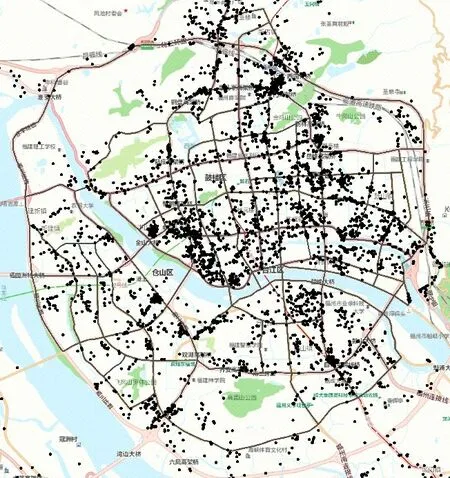
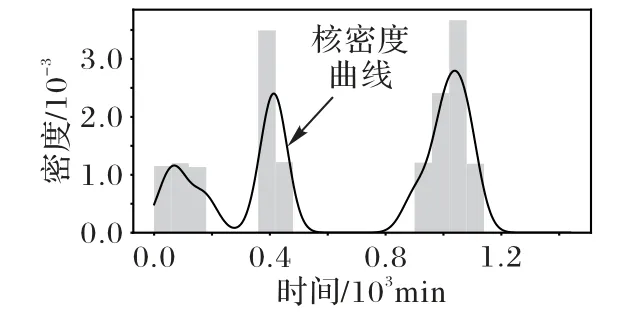
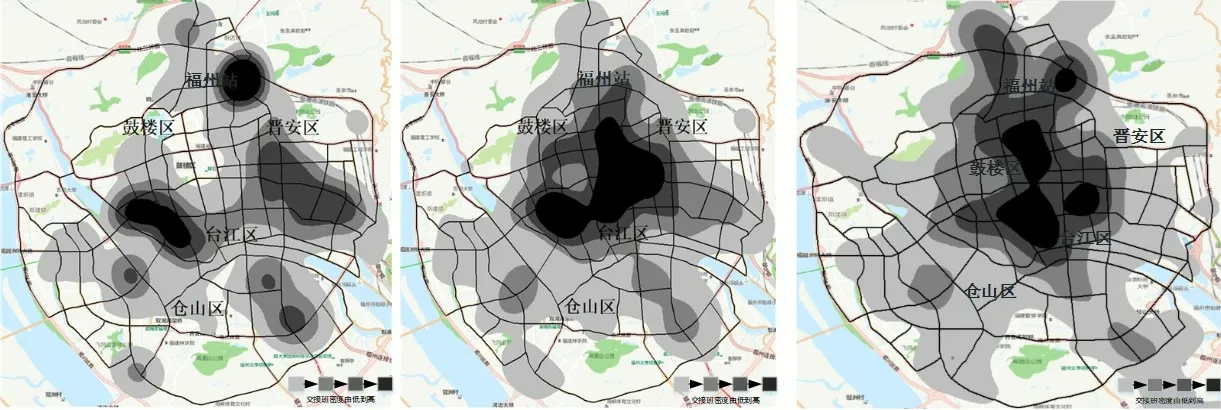
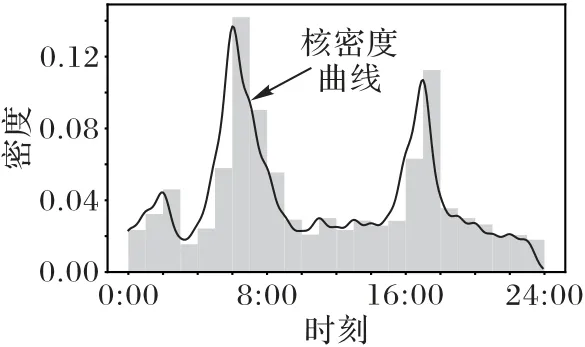
定义2停留点STOP由多个连续的数据点组成,STOP={Ds,Ds+1,…,De},轨迹点的速度信息都为零,0 3)车辆运营状态为车辆在持续行驶过程的状态,无效运营是车辆速度短暂不为0 但处于运营状态中,车辆非运营状态为即车辆持续停留的状态,无效非运营即车辆速度短暂为0但处于非运营状态中,如定义3所示。 定 义3任意停留点STOPj={Ds,Ds+1,…,De},ΔT=Te-Ts,如果时间差ΔT小于停留时间阈值α1,停留点将转换为移动段的轨迹:{Ds,Ds+1,…,De}→MOVE。任意移动段MOVEo={Du,Du+1,…,Dc},ΔT=Tc-Tu,如果时间差ΔT小于移动时间阈值α2,移动段将转换为停留点数据:{Du,Du+1,…,Dc}→STOP。 为了深入挖掘出租车轨迹数据中的停留行为,首先对出租车运动状态的特性进行分析。运动状态根据车辆速度分为行驶与停留两种模式,行驶模式为出租车速度不为0 的状态,停留模式即出租车速度为0 的状态。本文将轨迹分为两类,即运营状态以及非运营状态。其中运营状态主要分为车辆在寻找客源与载客两种,非运营状态为休息、吃饭、交接班等。本文主要分析挖掘轨迹数据中的非运营状态数据,实现对出租车交接班的停留点的检测。 STOP/MOVE 模型[16]可表述为轨迹在运营与非营运两种状态下的切换过程。如图1(a)所示,一条轨迹含有200 条数据;将速度大于0 的运营轨迹点(MOVE 状态)标记为1,速度为0(STOP 状态)的非运营轨迹点标记为0,标记结果如图1(b)所示。将轨迹数据的运营状态数据与非运营状态数据单独提取出来,即可根据特定需求对不同状态的数据进行挖掘。但轨迹数据中存在歧义信息,即运营数据与非运营数据中存在许多无效运营数据与无效非运营数据。由图1(b)可以看出,在索引25到150之间出现了多次STOP与MOVE之间的状态切换,这种情况可能是发生交通拥堵或者车辆在路口停车等绿灯通行,车辆停停走走,速度时而为0时而不为0,但车辆是实际在运营状态,其中速度短暂为0 的STOP 状态应归类为MOVE 状态。反之亦然,在司机休息时进行短时间的挪车、倒车等动作车辆速度不为0 但却没有处于实际的运营中,因此此类速度不为0 的运营状态属于无效运营,应归为STOP状态。 图1 STOP/MOVE状态映射效果Fig.1 Mapping effect of STOP/MOVE state 为避免无效运营、无效非运营事件的提取,使数据准确地表达属性,本文使用速度序列线性聚类(Velocity Sequence Linear Clustering,VSLC)算法[17]对数据进行规整。首先设置状态持续时间阈值对运营数据与非运营数据进行筛选,如果停留时间或移动时间小于设定的阈值,就将其状态标签进行转换,避免交通拥堵与短时的挪车等行为对车辆状态分类准确性的干扰。参考文献[16-18],本文设置移动时间阈值α2为120 s,停留时间阈值α1为300 s,如图2 所示,白色轨迹为非运营状态的轨迹,黑色为运营状态的轨迹,白色轨迹即速度为0的停留点数据,可用于交接班行为的识别。 图2 VSLC算法示意图Fig.2 Schematic diagram of VSLC algorithm 本文方法将出租车的运营与非运营状态区分开来,改正了无效运营、无效非运营数据,避免了歧义信息对非运营停留点检测干扰,保证了非运营停留点的准确性。算法伪代码如算法1所示。 算法1 非运营停留点检测算法。 出租车交接班行为具有一定的空间聚集性,文献[11]表明每日交接班行为范围不会超过5 km 并且大部分集中于1 km 以内。根据这种特点,本文采用基于密度的空间聚类算法DBSCAN 对出租车非运营停留地点进行空间聚类并将停留高度密集的地点标记为潜在交接区域。DBSCAN 算法可定义为:给出空间点集SSTOP={Pi},其中任意点Pi的邻域半径Eps内的点集以Pi为圆心、以Eps为半径范围对点进行搜索,如果密度可达点的个数大于样本最小阈值Minpts,则范围内的点集合为一个簇,如式(1)所示。聚类示意图如图3所示,以Eps聚类出两个簇N1、N2,N1、N2之外的点为噪声。 图3 DBSCAN算法聚类示意图Fig.3 Schematic diagram of clustering by DBSCAN algorithm 其中:S表示某车辆所有轨迹点的集合;Pi为某车辆7 d内的非运营停留点的集合;Q为核心点;P表示在半径Eps邻域内核心点Q密度可达的点;NEps则表示在地点Pi的半径Eps范围内以核心点Q所有密度可达的非运营停留点的集合。dist表示为点P与Q的距离,本文采用haversine对距离进行度量,因此半径范围的非运营停留点集合表示为式(2): DBSCAN 中的Eps参数对最终聚集效果具有决定性作用,为获得最好的聚类效果,本文通过K距离方法[19]对Eps参数进行调优。K距离方法即先提取一辆车的所有非运营停留地点,再计算所有点之间的互相距离,距离计算为式(3)所示。将得到的距离从小到大排列,将其用图形展示出来,距离曲线陡增位置的点即出租车非运营停留点相互距离的拐点就是最佳的聚类半径Eps。 本文方法通过空间点密度可达关系得到的最大密度相连的空间点集合。根据车辆的非运营停留点对一定区域内的密度可达的点进行搜索,若非运营停留点的密度可达点数量大于最小样本数则形成为一个簇,否则将点视为噪声点,最后所有形成的簇即潜在的交接班地点。算法伪代码如算法2所示。 算法2 出租车非运营停留高密度区域获取算法。 目前国内的出租车行业经营者主要分为出租汽车经营企业和出租汽车个体工商户两种,两种经营方式的交接班时间都是为早晚两个,所以理想的状态下,交接班时间的密度分布应为双峰状,而峰状分布数据几乎不会符合某种特定的性态,因此难以用参数方法进行拟合。核密度估计是一种概率密度函数的非参数检验方法,用来估计未知的密度函数,十分适用于未知分布样本,因此为搜寻停留结束时间比较集中的时段,本文通过核密度估计(Kernel Density Estimation,KDE)进行交接班时间的识别。 本文先通过核密度估计对各个潜在交接班时间点生成核密度曲线,再对集中较为密集的时间点进行标记,提取最为集中即密度最高的两个时间即出租车交接班时间Timeshift1与Timeshift2。核密度曲线计算如式(4)所示。 其中:timei为给定的停留结束时间样本;Kh()为核函数,本文选取高斯核;n为样本数量。为提取出概率密度最高的两个值,可以对生成的核密度曲线进行微分,计算所有f 'kernel(t)=0 所对应的概率密度,经过排序后取概率密度最高的两个t值,t值即为交接班的两个时间。 由于出租车行驶区域的广阔性与随机性,可能会在非交接班地点区域频繁停留,导致潜在交接班地点的误判,因此设置了两个交接班事件判断指标进一步对潜在交接班地点进行筛选,保证交接班地点的准确性。 1)到达频繁度指标。 出租车车主的就餐与上洗手间也为非运营状态的停留时间,在工作过程中,车主可能会对某一熟悉的餐厅或公共卫生间、加油(气、电)站等有使用偏好,停留频繁度相对较高。为防止车主就餐、上厕所等停留行为对交接班精准识别的影响,本文定义地点支持度对潜在交接班地点进行评估,支持度FS指的是驾驶员在某一地点的频繁度,即在一个工作周期k内同一地点停留的频率,计算方法如式(5)所示: 其中:NS为在区域S内的到达天数;k为工作周期,本文k取7即一周。 交接班是出租车每天都会进行的活动,基本上每天都会发生两次,而且地点比较固定。由于出租车的工作范围为整个市区,就餐与上厕所、加油(气、电)等行为主要根据车主工作位置而定,所有几乎不会存在每天同一地点进行就餐、上厕所行为。因此,本文设定到达频繁度指标筛选掉就餐、上洗手间等可能会干扰交接班行为准确识别的潜在因素,进一步保证交接班地点的准确性。考虑到换班、休班情况,本文设定每周的工作时间为5 天,即NS为5,FS的阈值为0.71。对于潜在交接班地点的簇中,如果非运营停留点的天数没有达到5 天,即FS小于0.71,将不予交接班地点考虑。交接班的地点与时间由出租车车主根据自身情况自由安排,地点可能为1个或2个,本文选取每辆车支持度FS最高的两个潜在交接班地点作为交接班地点候选,其中支持度FS大于0.71的潜在交接班地点作为交接班地点考虑。交接班位置主要可能在司机家附近区域或两个司机都方便的某个地铁口或公交车站附近,只要存在一周内5 天及以上停留,都会判别为交接班行为,任何地点进行交接班行为都可识别。 2)停留周期指标。 在城市中心区域、车站、机场等人流量高的区域,出租车需求量相对偏高,出租车停留密度也会相应增加,可能会存在在此处待客的行为,为避免将其误判为交接班地点,本文设置停留周期指标对交接班地点进行筛选,计算式如式(6)所示: 其中:Timeshift1与Timeshift2为在一个交接班潜在地点内停留结束时间最为密集的两个时段;ΔTimeshift为两个交接班行为的间隔时间。 根据出租车运营制度以及文献[11]统计,出租车交接班集中在两个时段且间隔时间一般在8~12 h,即只有8 h≤ΔTimeshift≤12 h,则判断为合理。如果潜在交接班地点的两个密度最大的非运营停留点结束时间不在8~12 h 的范围内,将不予认定为交接班地点。市中心和车站机场等高密度停留区域的停留待客时间比较随机,没有交接班这种停留结束时间在8~12 h 的停留规律,出租车基本不会存在每天都在8~12 h的间隔时间在同一区域待客,且就餐、上洗手间也没有10~12 h的规律,所以停留周期指标可以筛选掉此类影响交接班地点准确性的因素。 本文先精准提取出出租车非运营停留点,基于非运营停留点进行聚类获取非运营停留高密度区域即潜在的交接班地点,再通过非运营停留高密度区域各非运营停留点的停留结束时间进行核密度估计得出潜在交接班的时间与地点,最后根据交接班事件判断指标去掉非交接班事件得出有效的交接班地点与时间,算法具体流程如图4 所示。为验证本文方法的科学性,本文引入最新的交接班算法如文献[8]方法与权威的交接班算法如文献[13]方法进行对比分析。文献[8]方法以滑动窗口对研究范围内的轨迹数据进行检测,滑动窗口的大小代表交接班地点的范围。窗口尺寸从小到大进行检测,每进行一个尺寸的窗口滑动时,在窗口对轨迹的时间属性进行一个时间窗口的滑动,以时间窗口的大小作为交接班时间的范围。首先该方法对交接班地点与时间的精确性有一定不足,无法准确地获取出每辆车的交接班的地点和时间,只能得出一个范围,而本文方法可以精确地获取每个交接班的地点与时间。其次,该方法以车辆在某区域或时间的频次作为交接地点与时间确定的重要标准,没有对车辆在区域或事件的停留作具体分析是否为交接班行为,或者为某个人流量较高区域的待客、送客等行为,从而容易造成交接班事件的误判,而本文方法以筛选过短暂停留行为的停留点为交接班地点参考,短时间的待客停留、交通拥堵等不会认定为交接班事件。最后,文献[8]方法中每辆车只提取出了一个交接班地点,可能存在交接班地点的漏判。相较于文献[13]方法,本文的非运营停留点检测方法可规避交通拥堵、路口红灯停留等短暂停留数据对交接班地点识别的误导,而文献[13]方法未对停留点的行驶状态分类细化研究,将车辆运营状态下的停留点也归为交接班地点的计算中,可能会存在交班地点出现在某条经常拥堵的道路上或某个十字路口等的错误识别。其次,本文方法的到达频繁度指标与停留周期指标可以筛选掉潜在交接班地点中加油(气、电)、就餐、上洗手间、等不频繁一地停留行为与周期严格在8~12 h 规律的簇,进一步保证了交接班识别的准确性。文献[13]方法以停留点聚类成的簇作为交接班地点的识别,交接班地点中可能会存在出租车司机频繁就餐的餐厅、公共卫生间、加油(气、电)站等区域。而且,文献[13]方法以停留点最多的地方为交接班地点,交接班地点只存在1 个,然而交接班地点为车主根据各自需求而定,可能为1个也可能为2个,所以文献[13]方法识别的交接班地点中可能存在缺漏。本文以符合停留周期指标且到达频繁度指标最高的两个交接班地点为候选交接班地点,取符合到达频繁度指标的候选交接班地点为交接班地点,交接班地点可能为1 个也可能为2 个,保证了交接班地点的完整性。最后,文献[13]方法的IC 卡信息准确地记录了运营者的上下班时间,可直接提取出交接班的时间,但大部分的出租车公司允许出租车车主自由安排交接班时间,并不需要记录驾驶员的上下班信息,IC卡数据获取交接班行为的方法有一定的局限性,而本文方法通过挖掘交接班地点中的时间规律,识别交接班时间,具有普遍适用性。 图4 出租车交接班地点、时间挖掘算法Fig.4 Algorithm for mining location and time of taxi shift 本文的实验运行环境是Windows 10 操作系统,实验设备的硬件配置是Intel Core i7-9750H CPU @2.60 GHz,内存为16 GB,算法采用Python 语言编写,实验数据来源于福建省北斗导航与智慧交通协同创新中心通过车载诊断系统设备采集于2018年6月11日至17日的4416辆出租车的轨迹数据。轨迹数据包含ID、经度、纬度、速度、方向、时间戳六个属性,具体见表1。其中方向属性范围为0°~360°,正北方向为0°,由顺时针方向逐渐趋于360°,经纬度坐标以GCJ-02为坐标系。 表1 交通轨迹数据属性Tab.1 Attributes of traffic trajectory data 对所有车辆的非运营停留点进行分析,每辆出租车平均每周停留197 次,车辆每周的非运营停留点个数主要集中在100~300。图5(a)表示为一辆出租车的非运营停留点分布,从图中可看出,出租车营业范围较广,覆盖区域几乎为整个市区,在琴声商务广场与西元大桥附近存在两个非运营停留点点数比较密集的区域,可能为此辆车的交接班地;图5(b)为文献[13]方法对同一辆车的检测效果,从中可看出,停留点数远多于本文方法的检测结果,文献[13]方法以速度为0 km/h的停留点作为交接班地点,短暂的堵塞或路口等绿灯通行的行为都会被判定为停留点,所以在图中存在许多在路网上的停留点。相较于文献[13]方法,本文方法对停留点的检测量少而精准,不存在误检,既提高了聚类的地点的准确性,同时又减少了算法运行时间。 图5 停留点分布检测效果对比Fig.5 Comparison of parking point distribution detection effect 为识别潜在交接班的地点,先通过K距离方法确定聚类的半径Eps,本文对一辆车7 d 内的非运营停留点计算K距离值,对其排序后如图6所示。 从图6 中可以看出,该车辆的非运营停留点在100 至130都是小幅度递增,130 至140 处开始出现大幅度递增,拐点的位置在130 左右。为具体得到聚类半径的值,本文随机选取10辆车的非运营停留点进行验证,结果如表2所示,结合实验结果本文选取频率最高的130 m 作为Eps。交接班行为一般每日都会发生,但司机每周可能会休息一到两天,所以假定每周至少会上5 天班,也就是每个交接班地点出租车每周至少会有5次抵达,所以聚类的最小样本数Minpts设定为5。 图6 潜在出租车交接班地点范围Fig.6 Range of potential taxi shift locations 表2 潜在出租车交接班地点的最佳聚类半径Tab.2 Optimal clustering radius of potential taxi shift locations 选取一辆车的非运营数据进行DBSCAN 算法聚类分析,聚类结果如图7 所示,图中区域存在三个潜在交接班地点,其中两个不在道路上的潜在的交接班地点可能为交接班地点,而另外一个在十字路口的簇可能是等绿灯时的停留点所形成。图8 为所有的聚类结果,共聚类出8306 个簇即潜在交接班地点,覆盖了整个福州市区。 图7 DBSCAN算法的聚类结果Fig.7 Clustering results of DBSCAN algorithm 图8 福州市出租车潜在交接班地点分布Fig.8 Distribution of potential taxi shift locations in Fuzhou 交接班行为不仅在空间上具有相关性,在时间维度上也具有一定规律,为保证交接班事件识别的准确性,对每个潜在的交接班地点的时间维度进行进一步判别。对每个地点的停留离开时间进行核密度估计,得出潜在交接班地点的密度最大的两个时间。图9 为某个潜在交接班地点停留结束时间的概率分布,可以看出在400 min 与1000 min 处(6:30 以及16:30),停留结束事件最多,并且二者间隔约为10 h,因此可判断此处为交接班地点,交接班行为大约在上午6:30 以及下午4:30(16:30)。 图9 单辆车的潜在交接班时间的概率分布Fig.9 Probability distribution of one taxi’s potential shift time 在得出潜在交接班的时间后,通过交接班事件判断指标对潜在交接班地点在时间维度上进一步筛选,结合7 天时间内4416 辆出租车的运行轨迹进行实验,识别出交接班地点5639 个,图10 为本文方法交接班识别效果与文献[8]方法和文献[13]方法交接班识别效果,其空间分布投影于研究区域路网,结合电子底图显示交接班停留的空间分布情况,从白色到黑色表示交接班行为强度逐渐增强。 由图10 可以看出,本文方法识别出的交接班地点区域与文献[8]方法、文献[13]方法的交接班识别区域大体相同,交接班行为在鼓楼区、晋安区、台江区强度高。这三个区域囊括了福州市居民的主要工作区域、交通枢纽、商圈以及风景名胜。交接班行为最为活跃的区域是鼓楼区与仓山区的交接区域,这片区域是福州市最为繁华的娱乐性区域,包含了万象城、宝龙城市广场、中亭街等福州市发展最早的商圈区域。仓山区交接强度较小,这是由于仓山人口密度相对于中心区域人口密度较小,出租车司机通常会选择人口较为稠密、商业活动集中的中心地带作为开始工作的地点。与文献[8]方法和文献[13]方法相比,本文方法在交接班密集区域还是存在较大的差别。文献[8]方法的密集区域主要在鼓楼区的东街口、51 广场、台江区的万宝城以及福州站这些人流量密集区域,其他区域相对很低,这是由于文献[8]方法以车辆流动频次作为交接班评定的主要依据,而这些人流量大较且繁华的区域几乎为出租车每天必达区域,所有大多数出租车都在窗口滑动时在此区域时空频繁性相对要高,交接班事件的密度也就相对更集中于这些区域。鼓楼区是福州市的文化、政治中心,相对于其他区域而言,交通管制更为严格,一般不会允许车辆长时间停留,因此几乎不存在交接班行为。文献[13]方法在鼓楼区中心区域交接班行为也较为密集是因为市区交通较为拥堵,存在许多走走停停的驾驶行为,短暂的停留行为视为停留点用来交接班行为识别,导致鼓楼区中心区域交接班密度也依旧较高。晋安区的福州站人口流量大,客源较多且位于郊区,所以交接班行为也较多。而文献[13]方法在福州站处密集度不够高是因为在鼓楼区与晋安区站交界处存在较多的短暂停留,在此区域的聚类成的簇也就更多,而每辆车只有一个交接班地点,所以在福州站附近密度就会较低。 图10 福州市出租车交接班地点的空间分布Fig.10 Space distribution of taxis shift locations in Fuzhou 在2021 年2 月24 日对本文中交接班密集区域进行了蹲点调查法,共收集到73 辆出租车的调查报告。根据数据统计可知,73辆车中51辆车为1个交接班地点,16辆车为2个交接班,6 辆车为个人驾驶,不存在交接班行为。关于交接班地点:其中,20 名出租车在福州站进行交接班,14 台出租车在晋安区进行交接班,10 台出租车在鼓楼区交通监管稍弱区域进行交接班,11 台出租车在仓山区区域进行交接班,8 台出租车在台江区进行交接班,5 台出租车在市区外的福州南站进行交接班,3 台出租车市区外的大学城进行交接班,2 台出租车为市区外的其他区域进行交接班,小样本调查结果与本文识别的交接班地点大体相符,进一步验证了本文方法的可靠性。 根据所有交接班时间的统计,交接班行为在各个时间段的比率如图11 所示,其中的核密度曲线反映了交接班行为随时间的变化趋势。从概率密度曲线可以看出,交接班行为在6:00—8:00与16:00—18:00交接班强度最高,在4:00—7:00以及15:00—18:00 交接班强度逐渐增高,与福州市民众出行规律相吻合。 图11 福州市出租车交接班时间概率密度图Fig.11 Probability density diagram of taxi shift time in Fuzhou 为有效提取出出租车交接班时空分布,本文提出了一种基于轨迹数据挖掘的交接班识别算法。该算法总共分为三个部分:一是出租车非运营状态停留点检测,有效地获取了出租车在城市的停留位置以及停留时长。二是出租车非运营停留高密度区域获取,得出每辆出租车的频繁停留区域即潜在的交接班地点。三是出租车交接班地点时间识别,精准提取出了出租车的交接班地点与时间。实验结果反映出出租车交接班的时空分布,表明了本文方法的可行性。出租车交接班具有一定的可变性,其地点、时间会存在部分变动,通过长时间的轨迹数据与有效的算法挖掘出城市中出租车交接班的变化规律将是下一步的研究方向。2 算法设计
2.1 非运营状态停留点检测算法

2.2 潜在交接班地点提取算法

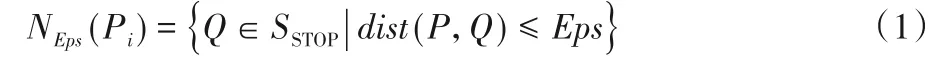
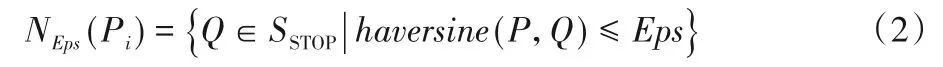



2.3 交接班时空分布识别算法
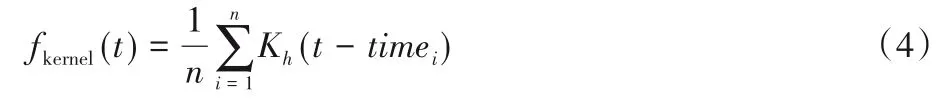


3 实验与结果分析
3.1 非运营停留点检测
3.2 潜在交接班地点提取

3.3 交接班时空分布识别
4 结语
