大型电商平台消费贷产品风控模型的构建
2021-12-05汪晓曦马颖
汪晓曦 马颖


摘 要: 信用评分模型的构建及应用实施是学术界及工业界不断研究创新的重要课题。从机器学习模型的构建出发,从建模指标、模型构建、模型上线后预期表现几个角度说明了模型应用策略。在建模指标处理方面,采用原始变量woe变换作为XGBoost等模型的输入变量,并验证了模型效果提升;在模型构建上,创新采用多种算法单独建模,用XGBoost算法拟合各单模型输出结果,证明复合模型效果有明显提升;在模型上线后预期表现方面,提出了确定模型切分点的方法,即从授信额度、风险级别以及群体分布三个维度,预测即将进件群体的坏账率。本研究最后结合模型表现及业务模式给出实施建议,即对于部署难度高的复合模型可采用预授信的模式,而LR评分卡模型部署可延用申请-授信的模式。
关键词: 信用评分; 风控模型; XGBoost; 机器学习; 模型应用策略
中图分类号: F832.39 文献标识码: A DOI: 10.3963/j.issn.1671-6477.2021.05.004
近6年来,随着电商平台的迅猛发展,消费金融产品层出不穷。这些产品依托电商平台的天然流量优势迅猛發展,从商城内扩展到商城外,不断拓展使用场景抢占市场。在版图的不断扩张中,信贷审批模型、模型在具体商业模式中的应用也随着用户流量的扩张、业务场景的拓展不断更新迭代[1]。目前,在信贷审批模型中,算法Logistic Regression(简称LR)依然是最为普及的,在一些特定的用户群体和场景下依然有难以替代的地位,依据该算法建立的评分模型规则简单、逻辑清晰、解释性强,便于用户理解。然而,LR模型并不能保证在各种场景、用户群体中都有良好表现。比如从模型稳定性考虑,LR模型用到的变量维度一般不超过15个,在整体自变量与因变量相关性都不高的情况下,有限的变量数量难以达到较好的模型表现。模型表现不够理想直接影响到通过率及日后坏账风险,会对商城信贷收益产生直接影响。在本研究项目中,商城平台主要信贷模型算法采用的就是LR模型,当前LR模型的应用在风控能力及通过率表现方面能基本达成一个平衡,但客户仍然希望尝试新的模型算法,通过提升模型效果达到保证坏账率不增长的前提下提高模型通过率的目的;此外,客户尤其强调好的模型需要应用于生产线产生实际效益,若一个模型太过复杂导致部署周期长、出错率高而难以实施也是没有意义的。根据用户的上述2个要求,项目组从模型构建出发,提出确定模型切分点预测坏账率的方法,并针对平台实际不同业务场景及业务要求确立模型应用的方法。
首先,在信贷风控模型构建上,笔者参考了如下学者提出的方法并将该方法应用在商城平台上,再根据平台数据特点以及模型表现作数据特征提取及模型算法的改善。近年来,信贷风控领域较受青睐的分类算法模型包括Decision Tree(决策树)[2]、SVM(支持向量机)[3-4]、Random Forest(随机森林)、GBDT(梯度提升决策树)、XGBoost(极度梯度提升算法)、神经网络算法(Neural Networks)[5-7]等。2014年,萧超武等在实证分析中将随机森林组合分类算法与KNN、SVM等单分类器模型以及组合模型GBDT比较,发现前者具有更高的精确度及稳定性[8]。2017年,Bequé将神经网络极限学习算法(ELM)用于消费信贷风险管理,通过实验发现该算法有计算量小、精准度高的特点[9]。2017年,Luo Cuicui采用LR、SVM、深度信念网络(DBN)算法进行信贷违约预测,发现DBN具有最好的预测效果[10]。2019年,陈秋华等探讨了不同连接函数下广义线性模型的分类问题,将线性模型评价指标与RF、SVM、XGBoost等模型进行分析比对,发现广义线性模型中LR模型与SVM预测效果最佳[11]。2019年,黄志刚等人提出多源数据普适模型栈的概念,通过数据分类的自由选择采用XGBoost算法生成子评分模型,再将子评分模型转换为评分卡,通过实测证实有效[12]。在参考上述学者选用的算法并结合商城平台数据特点,本文最终选用了LR算法、决策树算法、XGBoost算法建立单模型。在LR模型变量交互方面,参比陈秋华[11]提出的变量相乘的交互方式,本文提出了用相关系数法寻找交互变量的方法,并验证了该方法的有效性。受黄志刚[12]多源数据普适模型栈的想法启发,借用不同数据特点采用不同模型算法最后用XGBoost模型整合的思路,本文采取首先用多种算法建立单模型,再用各单模型的结果输出作为复合模型的输入建立复合模型的方法,经验证,复合模型效果较单模型有明显提升。
虽然学术界对风控模型算法的讨论十分热烈,然而对于客户提出的第二点要求,模型在生产线上的实际应用方面却略显单薄。本文花了大量篇幅讨论模型的应用问题。首先,传统LR模型、复杂机器学习模型在实际部署应用方面各有优劣:LR模型部署通常借用风控决策引擎[13]来完成,优势为部署门槛低、部署时间短、结果可靠性强,但模型效果不及复杂机器学习模型;而复杂机器学习模型虽在模型效果上更有优势,但在部署方面,由于受模型复杂程度、数据量级、部署场景、上线时间紧迫等因素制约,不是都能满足工程上的要求成功上线。所以,目前工业界在风控模型部署上,LR仍是主流[14],复杂机器学习模型部署还在不断尝试发展中,不同体量的电商平台复杂机器学习模型实施的普及程度也不一样。对于本项目,商城平台刚开始尝试复杂机器学习模型的部署,文章给出了两者并举的保守方案。本文首先提出风控模型在应用实施中不同切分点对应的预测坏账率,然后比较并验证了在相同风险前提下LR模型与XGBoost复合模型实际通过率差异,并结合具体业务模式及业务需求给出模型选择的依据及部署方式。
一、 模型效果指标评价
模型评价指标是用来评估模型对数据的拟合能力,二元分类的模型算法有很多,但无论是哪种模型算法都可以使用AUC[15]和KS这两个指标来衡量。AUC的取值为0.5~1,AUC值越高代表该算法对模型整体拟合能力越强,AUC等于0.5代表模型没有区辨能力,但大于0.9则模型拟合过于完美考虑异常,AUC在0.7~0.9之间的模型被视为可用。AUC在0.7与0.8之间代表模型有较好的区辨能力;AUC大于0.8代表模型有非常好的拟合能力。AUC取值与模型区辨能力对应关系如表1所示。
KS是评价模型优劣的另外一个常用指标,同样KS值越大代表模型对数据拟合能力越强,通常KS取值在0.2~0.75之间。与AUC不同的是,AUC是反应模型整体对数据的拟合能力,而KS则指出在某一区段模型对目标变量的辨识度最高。KS取值与模型区辨能力对应关系如表2所示。
本文分析比较的4个模型:LR模型、决策树模型、XGBoost单模型及XGBoost复合模型的效果均采用AUC值及KS值这两个指标来进行评价。
二、 建模实证分析
(一) 建模数据构成及变量预处理
目前,该平台信贷产品申请用户为在平台商城近1年内有过历史交易记录的用户,该产品运营已超过1年,有充足的坏用户积累。建模用户群体,我们选择授信前1年内在平台商城内有较为活跃表现的用户,授信后6~12个月内出账次数大于等于6的用户确立建模样本。
y定义方面,通过分析逾期天数与回款率关系,以及通过逾期用户M1~M4坏账滚动率分析后确定的[16]。相同样本,不同y定义,最终AUC和KS模型评价指标会有较大差异。通常y定义越严格,模型指标AUC及KS表现越好,比如把进入M4的用户定義为坏用户比把进入M2的用户定义为坏用户有更好的模型表现。然而,考虑到该评分卡是建立申请用户审批模型,目的不是把最坏的用户排除,而是把有可能进入M3或M4的用户拦截在外。所以,y用户定义采用进入M2或M3的用户,但由于M3用户数量有限,所以把多次进入M2的用户列为坏用户。经过多次尝试,得到y定义为至少有2次出账且2次出账的逾期天数均大于30天(进入M2)的用户为坏用户,其余为好用户。X变量共126个,为用户申请消费贷前平台商城的历史行为数据。从分类来看,可将X变量分为用户基本信息、用户申请渠道、用户信用资质、平台活跃度、平台交易信息、收货方式、收货人(地址)信息等类别。数据样本共11180个观测值,其中坏用户为1118个,odds比9∶1。采用分层抽样的方式将数据切分为7∶3两部分,前者用作模型训练及验证,后者用于模型测试。
在数据预处理环节,对每个X变量作单变量分析,进行变量一致性、完整性、准确性检验,剔除变量缺失率高于20%的变量;对变量进行woe转换并计算其iv值,预测每个自变量x与因变量y的相关程度。在作变量woe转换时,对自变量排序后切分为10等分进行粗分箱,然后对变量分箱进行合并,合并时确保变量woe值为单调趋势,各分箱观测值数量不低于25个,且相邻分箱的woe值有较大差异。最后计算变量iv值,结果如图1所示。
(二) Logistic Regression单模型
筛选出iv值大于0.1的经过woe转换的自变量作为模型输入变量,采用stepwise逐步回归法筛选变量,模型置信度设为95%,y变量共2个取值,“0”代表好用户,“1”代表坏用户,以“0”为目标构建模型。在模型变量调整上,通过计算自变量的相关性,使相关性较大的变量组合尽可能避免同时出现在模型中。根据模型输出结果,删除变量系数为正或者系数过小的变量,以减小共线性对模型效果的影响。检查进入模型的x变量分类,确保模型尽可能覆盖到每个分类。检查模型评分确保评分均匀分布。当出现超过样本量5%的观测值对应同一个评分时,找到是哪个变量造成的,用别的变量加以替换。最后确认模型,入模变量及模型参数如表3所示,模型变量分别为收货人数量、近12个月的货到付款次数、近3个月的货到付款次数、近12个月拒收次数、近12个月每个月都有交易的月份数、近3个月交易金额、近3个月信用卡支付金额、近3个月借记卡支付次数、近3个月使用app登录平台次数、用户婚姻状况、用户性别以及用户进件渠道。
1.LR变量交互。在不改变入模变量数量的前提下,将入模变量与待选变量做交互,以达到提升模型整体效果的目的。通常待选变量iv值过小难以进入模型,但待选变量与模型变量涵盖信息不同,且与之交互的模型变量相关性低。为寻找待选变量,采用对需要交互的两变量计算Pearson相关系数的办法,最后发现两组可以通过变量交互提升模型的变量。第一组,“授信渠道”、“商城卡包提取标志”进行变量交互替代原模型中“授信渠道”变量;第二组,“婚姻状况”、“客单价”进行变量交互替代原模型中“客单价”变量;交互后模型效果提升如下表所示,可以看出交互前后AUC没有显著提升,但模型KS值约有6‰的提升。交互变量的加入可以小幅度提升模型效果,如表4所示。
2.决策树单模型。在决策树模型构建过程中使用了两种叶节点分裂的算法,一个是熵分裂标准,另一个是Kolmogorov-Smirnov(FastCHAID)分裂标准,剪枝过程中均采用误判率、最小叶子数作为剪枝标准[17-18]。两模型输入变量前者是原始变量,后者为经过woe转换后的变量。本模型采用SAS PROC HPSPLIT完成,通过对leafsize(叶节点最小观测数)、最小叶子数量、maxdepth(最大树深)、maxbranch(最大分枝数)参数调整完成决策树的构建。对每片叶子目标变量预测概率排序,通过计算每个概率分箱中累计好坏用户的占比,得到AUC及KS值。结果如表5所示。
3.XGBoost单模型。XGBoost算法是由Chen[19]基于Friedman[20]提出的gradient boosting模型设计并对其优化。XGBoost的思想是不断通过种树去迭代以减少上一轮的误差,最终达到分类的目的。每一次迭代就是增加一颗新的树,对上次残差进行拟合。每颗树的叶节点对应一个分数,将每棵树对应的分数相加得到样本的预测值。
模型输入变量为原始变量中定距(Interval)变量,以及定类(Nominal)、定序(Ordinal)变量经过woe变换的变量。调参过程中,首先确定eta(学习率)和num_rounds(迭代次数)进行粗调,再确定max_depth以及seed,最后采用网格搜索法对subsample、colsample进行调参,用cv交叉验证中early_stopping_rounds寻找最好迭代次数,最后微调eta和num_rounds确定最后参数。参数结果为:{eta=0.1,max_depth=1,seed=35,subsample=0.4,colsample_bytree=0.7,num_rounds=126,lambda=0.5},此参数下对应的训练集、测试集AUC及KS指标如表6所示。
4.XGBoost复合模型。将原变量、woe转换后的变量作为输入,Logistic单模型、XGBoost单模型、决策树模型的輸出结果作为复合模型XGBoost的输入,进行模型训练,输入指标如图2所示。XGB复合模型输入指标包括5个单模型的输出结果、原始变量以及经过woe转化后的变量,其中5个单模型的输出结果包含2种算法的决策树预测概率、逻辑回归模型预测概率及评分、XGB单模型的预测概率。上述模型输入用一个XGB模型整合得到最后的输出结果。复合模型调参步骤与XGB单模型类似,参数为{eta=0.1,eval_metric=auc,nthread=3,min_child_weight=1,max_depth=1,seed=30,subsample=0.2,colsample_bytree=0.7,num_rounds=150,lambda=1.5}。模型重要性指标如图3所示,重要性最高的为XGB单模型预测概率,其次为LR模型预测概率及转换评分。模型结果如表7所示。
5.模型指标比较与评价。比较上述模型KS及AUC指标发现,所有模型区辨能力都在可接受及之上,在本数据中决策树模型表现最差,在可接受区辨能力边缘;LR模型和XGBoost单模型AUC有较好的表现,其中XGBoost单模型比LR模型KS高出1.7%、AUC高出1.5%,整体表现略优于LR模型;表现最好的是XGBoost复合模型,AUC达到0.80,进入非常良好的区辨能力这一档。
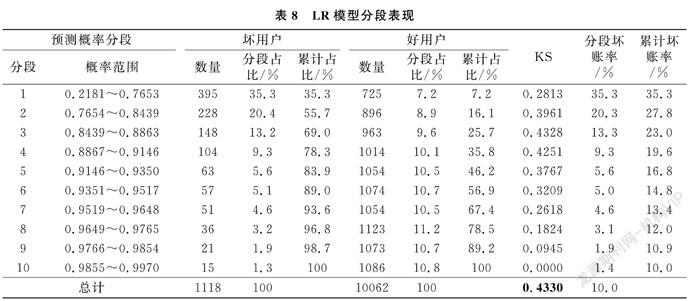
模型在使用中需要确定切分分数线,即该分数线以下的用户需要被排除。所以,在模型评估中需要比较不同分数段坏账率及累计坏账率。将生产实际中运用最为广泛的LR模型、效果最优的XGBoost复合模型进行比较,对比的数据集为训练集+测试集。对预测概率进行从小到大排序,切分为10等分,每一等分用户数量大致相同。为便于比较,均使用预测概率表明分段范围。两模型结果如表8、表9所示。
从分段坏账率来看,XGBoost复合模型比LR模型第一分段高4.2%,如果切分分数线划在第一段,则XGBoost有明显优势;从累计坏账率来看,假设坏账率差异小于1%就认为模型效果无明显差别,则模型切分点设在第三段时两模型“抓坏人”能力相同,LR模型、XGBoost模型对应切分概率分别为0.886和0.903。
三、 模型选择及部署实施探索
(一) 风险评估
评分模型在风控策略中有两个重要作用:一个是确立拒绝分数线,即小于某一预测概率(评分)的用户拒绝授信;另一个是根据预测概率(评分)划分风险等级、确定授信额度。评分模型设立的目的是为了让坏账率在可控范围内,那如何利用评分模型预测进件用户的坏账率便成了关键。电商平台消费贷产品通常是分期的,根据消费贷产品设计,若用户在某一期还款截止日10天内未还清账款,账户自动冻结。账款催收方面,逾期90天以内的账款由平台内部催收部门催收,逾期超过90天(进入M4)的账户因账款难以回收,故采用外包形式,催回金额与外包公司按比例分成。所以这里我们把进入M4(逾期天数>90天)的用户记为坏账用户,未还清金额(包括已出账、未出账)记为坏账余额,表现时长取1年。由于使用余额、坏账余额是一个动态平衡的过程,这里选取时点数据来定义,以账户成功授信之日起1年为时间节点,坏账率定义为坏账余额与使用余额之比。
在作风险评估方面,需要用到2个群体:已授信群体和即将进件群体。已授信群体定义为成功授信且表现期满1年的用户;即将进件群体定义为近一个月内申请授信的用户。
将LR模型、XGBoost复合模型分别运用到2个群体上得到每个用户的预测概率。根据模型坏账率划分风险等级,并将风险等级、用户授信额度等级绘制成交叉表,如表10所示。单元格内bij、uij、qij分别是已授信群体的坏账余额、使用余额以及用户数量,其中脚标i代表授信额度等级,j代表风险等级。
将模型运用于进件用户群体,进件用户群体的用户数量记为Qij,这里i、j分别为额度等级、风险等级,等级划分方式如表10所示。风险等级1为最低,风险等级5为最高。坏账率记为BRm,有:
假设坏账率最高不超过某一值,记为BRrate,计算BRm≤BRrate的最大m值,大于m的风险等级用户即为需要拒绝的用户。以此确定模型拒绝用户的切分点,记为Preject。
(二) 通过率评估
通过率评估是将评分模型应用到当前进件用户模拟进件用户通过率的方式。通常业务部门与风控部门为通过率博弈,业务部门要求更高的通过率,风控部门则通过模型优化在保证风险的前提下提高通过率,但模型评价指标越好并不意味着使用该模型就一定有更高的通过率。本文采用传统LR单模型、XGBoost复合模型进件通过率的模拟验证以上观点。
设计思路为上述两模型应用于102 787名即将进件用户群体,并计算其预测概率。分别对两模型预测概率进行从小到大排序,每一个预测概率对应与风控模型中累计坏用户数对应,而预测概率在该进件用户群体的分位数即为拒绝率,进而计算得到进件群体的通过率。本文通过作图的方法比较LR模型与XGBoost复合模型相同风控效果对应的通过率。以累计坏用户数作为横轴,进件用户通过率(1-拒绝率)作为纵轴,分别对两模型作散点图,结果如图4所示。从图4中可以看出两模型头尾几乎是重合的,只在中间段看出差异。通过计算得到在“抓坏人”能力相同条件下,两模型通过率最大差异为7.9%,对应的LR模型和XGBoost复合模型通过率分别为44.8%和52.74%;若业务部门要求75%以上的通过率(假设容差为2%),且风险在可以接受范围内,两模型则在风险能力控制和通过率上几乎没有差别。如表11所示。
(三) 模型部署实施评估与建议
对于传统LR模型部署一般是线上实施审批,采用风控决策引擎部署。主流的风控决策引擎包括FICO公司的Blaze和Experian公司的SMG3。风控决策引擎负责入参、出参的配置,以及结果调用。风控决策引擎使操作简单易学,门槛低,上手快,例如LR模型10~15个变量的配置,1个小时就能完成。然而,对于复杂的机器学习算法,上百个模型变量,上千次的学习迭代,以及复杂的预测概率计算,
若在决策引擎上部署就变得难以实施。当下,对于复杂机器学习模型部署方式还在探索中。目前,一般采用预测模型标准语言(PMML),该语言可以在不同数据挖掘工具和不同应用系统之间交换挖掘模型,实现模型的部署。虽然,在机器学习模型应用方面,PMML的应用实施还在发展中,除了不同的数据挖掘厂商支持的模型类型有限外,PMML在执行过程中还出现数据厂商生成的PMML与标准定义的Schema有偏差导致最终结果的偏差等问题。然而,纵有这么多问题,模型效果的优势是不容置疑的,而且机器学习的发展已成为趋势。
综上所述,在模型应用选择方面,无论是应用最为广泛的LR模型还是上面提到的类似XGBoost复合模型的机器学习模型都是有利有弊的。前者部署门槛低,部署高效,模型本身有较好的解释性,但模型应用效果不及后者;后者模型效果整体优于前者,但对于部署人员来说门槛较高,且部署过程中产生的各种问题还在不断尝试解决中。然而,模型的应用、部署实施上线并不是一个二选一的问题。本文建议模型选取要结合具体业务指标、风控指标、模型效果还有具体商业模式来确定。在线实施审批的风控模型一定要上生产线,但机器学习的模型应用不一定要上生产线,可以采用离线方式部署,其对应的商业模式为预授信。预授信模式是从待选的用户池中筛选出优质用户为其打上授信标签,包括是否授信及授信额度。再将授信信息用弹窗、链接、短信等方式推送给可以授信的用户,鼓励用户申请。
本文LR模型和XGBoost机器学习模型选择及应用层面,要综合考虑模型效果指标、坏账率指标、通过率需求,及模型部署实施方面的问题,如图5所示。红、蓝两条曲线分别代表LR单模型和XGBoost复合模型。横坐标(上)为模型预测概率,横坐标(下)为模型“抓坏人”数量,模型纵坐标为进件用户通过率。两条纵向的黄色虚线分别表示两模型风控能力相同条件下,进件模拟通过率差异小于2%的临界值。左黄线通过率为75%,右黄线为20%,对应拒绝概率如灰色标注所示。结合上述叙述,模型应用方案如表12所示。
四、 结 语
本文通过真实数据从多个维度非常详实地分析了从模型构建到模型应用实施全过程。模型特征工程方面,相比陈秋华[11]提出的自变量交互对模型指标效果的提升,本文进一步提出用相关系数法寻找交互变量的方法;在特征變量构建上,创新采用对原变量进行woe转换的方式创建衍生变量。经验证,该方法对于模型效果指标的提升是有效的。对于XGBoost模型,此方式相当于将分类变量转换为可以计算的定距变量,解决了XGBoost模型矩阵不能处理字符型变量的问题,也避免了分类变量转化为虚拟变量的麻烦。
在复合模型变量构建方面,跳出通过原变量加减乘除的方式进行变量衍生的圈子,将LR单模型的woe变量连同决策树、XGBoost单模型的输出结果(概率&评分)作为输入变量,并使用XGBoost进行拟合,经验证,复合模型评价指标优于各单模型。
本文创新之处在于不只对模型评价指标进行比较,更从模型应用实施角度提出了模型拒绝分数线(切分点)的确定方法[21]。该方法首先采用模型各分段坏账率对模型进行风险等级划分,并通过风险等级与授信额度交叉的方法模拟各单元格内坏账率分布构成,并将模型运用于新进件的用户,预测进件用户预期坏账率,以此确定拒绝用户切分点。不仅如此,本文用模型表现与通过率之间的关系阐述了模型选用标准。以LR单模型、XGBoost复合模型为例,用数据验证了在“抓坏人”能力相同的条件下两模型通过率的大小及差异。并从通过率差异、业务部门通过率最低要求、模型部署实施难度及商城现有的业务模式进行综合分析,给出模型选用建议[22]。在建议实施方面,对于选用难以部署的复合模型,建议采用预授信的模式。将模型应用在新进件用户群体上,筛选出通过用户,并用弹框或短信等方式通知,让用户选择是否开通。与现有的申请-授信模式相比,此种方式在确保风险的同时,扩大了人群覆盖面,提升了总体进件人数,绕开了模型部署实施难的障碍。
[参考文献]
[1]何飞,张兵.互联网金融的发展:大数据驱动与模式衍变[J].财经科学,2016,23(6):12-22.
[2]涂艳,王翔宇.基于机器学习的P2P网络借贷违约风险预警研究:来自“拍拍贷”的借贷交易证据[J].统计与信息论坛,2018,33(6):69-76.
[3]Baesens B,Van Gestel T,Viaene S,Stepanova M.Benchmarking state-of-the-art classification algorithms for credit scoring[J].Journal of the Operational Research Society,2003,54(6):627-635.
[4]晏艳阳,蒋恒波.信用评分模型应用比较研究:基于个体工商户数据的检验[J].统计与信息论坛,2010,25(5):30-35.
[5]石庆炎,勒云汇.多种个人信用评分模型在中国度用的比较研究[J].统计研究,2004,21(6):43-47.
[6]陈为民,马超群,冯广波.基于KMOD核函数的SVM方法在信用评分中的应用[J].经济数学,2008(1):24-27.
[7]杨力,汪克亮,王建民.信用评分主要模型方法比较研究[J].经济管理,2008 (6):37-42.
[8]萧超武,蔡文学,黄晓字,陈康.基于随机森林的个人信用评估模型研究及实证分析[J].管理现代化,2014,34(6):111-113.
[9]Bequé A,Lessmann S.Extreme Learning Machines for Credit Scoring:An Empirical Evaluation[J].Expert Systems with Applications,2017,86:42-53.
[10]Luo Cuicui,Wu Desheng,Wu Dexiang.A Deep Learning Approach for Credit Scoring Using Credit Default Swaps[J].Engineering Applications of Artificial Intelligence,2017,65:465-470.
[11]陈秋华,杨慧荣,崔恒建.变量筛选后的个人信贷评分模型与统计学习[J/OL].数理统计与管理,(2020-02-23)[2021-04-10].https://doi.org/10.13860/j.cnki.sltj.20200223-002.
[12]黄志刚,刘志惠,朱建林.多源数据信用评级普适模型栈框架的构建与应用[J].数量经济技术经济研究,2019,36(4):155-168.
[13]Sohn S Y,Dong H K,Jin H Y.Technology credit scoring model with fuzzy logistic regression[J].Applied Soft Computing,2016,43:150-158.
[14]宋捷.商业银行信用卡数字化转型的路径分析[J].金融科技时代,2020,29(6):41-44.
[15]Bradley A P.The use of the area under the ROC curve in the evaluation of machine learning algorithms[J].Pattern Recognition,1997,30(7):1145-1159.
[16]周毓萍.基于机器学习方法的个人信用评价研究[J].金融理论与实践,2019(12):1-8.
[17]Rokach,L.and Maimon,O.Data Mining with Decision Trees:Theory and Applications,volume 69 of Series in Machine Perception and Artificial Intelligence[C].London:World Scientific,2008.
[18]Soman,K.P.,Diwakar,S.,and Ajay,V.Insight into Data Mining:Theory and Practice[C]. New Delhi:PHI Learning,2010.
[19]Chen T,Guestrin C.XGBoost:A scalable tree boosting system[C]//Proc of ACM SIGKDD international Conference on Knowledge Discovery and Data Mining.San Francisco:KDD,2016.
[20]Friedman J H.Greedy function approximation:A gradient boosting machine[J].Annals of Statistics,2001,29(5):1189-1232.
[21]陳战勇.珠联璧合:基于机器学习的网络借贷信用评分卡模型研究[J].武汉金融,2020(3):42-50.
[22]邓大松.我国商业银行小微企业申请评分卡构建及验证研究[J].投资研究,2017(5):149-159.
(责任编辑 文 格)
Construction and Application of Risk Control Model for Consumer
Loan Products on Large E-commerce Platforms
WANG Xiao-xi1, MA Ying2
(1.School of Management,Wuxi Institute of Technology,Wuxi 214121,Jiangsu,China;
2.School of Management,Wuhan University of Technology,Wuhan 430070,Hubei,China)
Abstract:The construction and application of the credit scoring model is an important subject of continuous research and innovation in academia and industry.Starting from the construction of the machine learning model,this article explains the model application strategy from the perspectives of modeling indicators,model construction,and expected online model performance.In terms of modeling indicators processing,the original variable woe transformation is used as the input variable of XGBoost and other models,and it is verified the improvement of the model effect; in the model construction,a variety of algorithms were compared.Among those,XGBoost algorithm was used to fit the output results of each single model,which was proved that the effect of the composite model was significantly improved.The biggest innovation is that it proposes a method to determine the cut-off point of the model,and predicts the bad debt rate of the incoming group from the three dimensions of credit line,risk level and group distribution.In this paper,model selection and deployment are innovatively combined with model performance and business models to give implementation suggestions: for complex models that are difficult to deploy,the pre-credit model can be used; LR scorecard model deployment can be used to the application-credit model.
Key words:credit score; risk control model; XGBoost; machine learning; model application strategy
收稿日期:2021-03-08
作者简介:汪晓曦(1989-),女,湖北武汉人,无锡职业技术学院管理学院助教,通信与信息系统/市场营销双硕士,主要从事互联网金融、数字金融等研究。
通讯作者:马 颖(1975-),女,山东烟台人,武汉理工大学管理学院教授,博士生导师,博士,主要从事营销管理、风险管理研究。
基金项目: 2021年度无锡职业技术学院校级社科类课题(SK202102) ;2020年无锡职业技术学院“青蓝蓝工程”青年教师培养项目
