基于K均值聚类挖掘的跟车测试场景研究
2021-12-05黄昆
黄昆
(天津经纬恒润科技有限公司,天津 300385)
主题词:跟车测试场景 聚类挖掘 K均值聚类 自动驾驶技术
1 引言
随着智能驾驶技术的不断发展,特斯拉、蔚来等主机厂已经开发了许多较为完善的先进自动驾驶辅助系统[1-2],例如高速自动辅助驾驶(Highway Pilot,HP)、拥堵自动辅助驾驶[3](Traffic Jam Pilot,TJP)等,然而目前智能驾驶汽车仍无法实现L4及以上的智能驾驶,其技术发展仍需要多种自然驾驶场景支持,因此,十分有必要开展各类驾驶场景挖掘研究。
场景聚类挖掘[4-5]是获取智能驾驶测试场景的主要方法之一。徐向阳[6]等基于国家车辆事故深度调查体系中的499 例事故场景数据,对我国自动紧急制动(Autonomous Emergency Braking, AEB)场景进行聚类挖掘。郭景华[7]等基于我国自然驾驶数据中的危险工况片段,使用层次聚类法对驾驶行程中的危险场景进行聚类挖掘。夏澜[8]等通过对43例自然驾驶场景进行分析,挖掘到6 类目标切入的危险跟车场景。Adam[9]等人以交通目标之间的位置关系作为判别量,基于此提出了一种距离聚类的场景挖掘方法。Jin[10]等人使用考虑时间与空间的马氏距离对跟车进行聚类,提出了一种交通异常事件的场景挖掘方法。Birant[11]等人提出了一种用于处理大规模数据集异常问题的时空异常场景挖掘算法。
场景聚类挖掘是智能驾驶场景研发和验证的基石,对我国智能驾驶技术的发展具有十分重要的意义。本文基于K均值聚类算法,对自然驾驶过程中的跟车场景进行场景解构和场景聚类挖掘研究,依据场景主体要素挖掘到3类典型的跟车工况,并结合场景交通环境及车辆类型等要素,构建了大量的类跟车测试场景,这对我国自动驾驶辅助系统的研发和测试具有十分重要的意义。
2 道路试验及跟车场景数据提取
2.1 道路试验
道路试验从2020 年4 月10 日开始到2020 年5 月21 日结束,测试有效时间为56 d,道路测试总里程为10 120 km,测试地点涵盖河北、山西、河南及周边地区。道路类型包括高速、国道、市区,测试天气有晴天、阴天、雨天、雾天,场景数据包括直道、弯道、十字路口、红绿灯和人行横道场景。共选取10名男性驾驶员进行试验,平均年龄为35岁,试验车中采集数据的传感器主要包括Mobileye 摄像头、激光雷达和ESR毫米波雷达,其实物如图1所示。由于本次试验主要开展驾驶员跟车特性的研究,故将3种传感器都安装在试验车的前部,其安装位置如图2所示,其中浅色圈部分代表传感器的具体安装部位。

图1 试验所用传感器

图2 传感器安装位置示意
2.2 跟车场景数据提取
基于数据库,首先选取399例城市道路、387例高速公路、413例乡村道路的跟车场景,并对其加减速度曲线进行提取。共提取1 199例跟车场景,排除121例曲率半径较大的弯道跟车速度曲线,剔除68例涉及非机动车场景或其它特殊车辆的跟车场景,最终获得1 010 例跟车场景(均为跟随同一目标,不存在跟车目标转换)。

图3 从CANape 17.0中提取的参数曲线
如图4 所示,基于CANape 17.0 进行(滤波)提取的跟车场景参数包括速度、目标车头时距(THW)、横/纵向相对距离、相对速度。图5为加速度、减速度曲线样本频次分布统计。
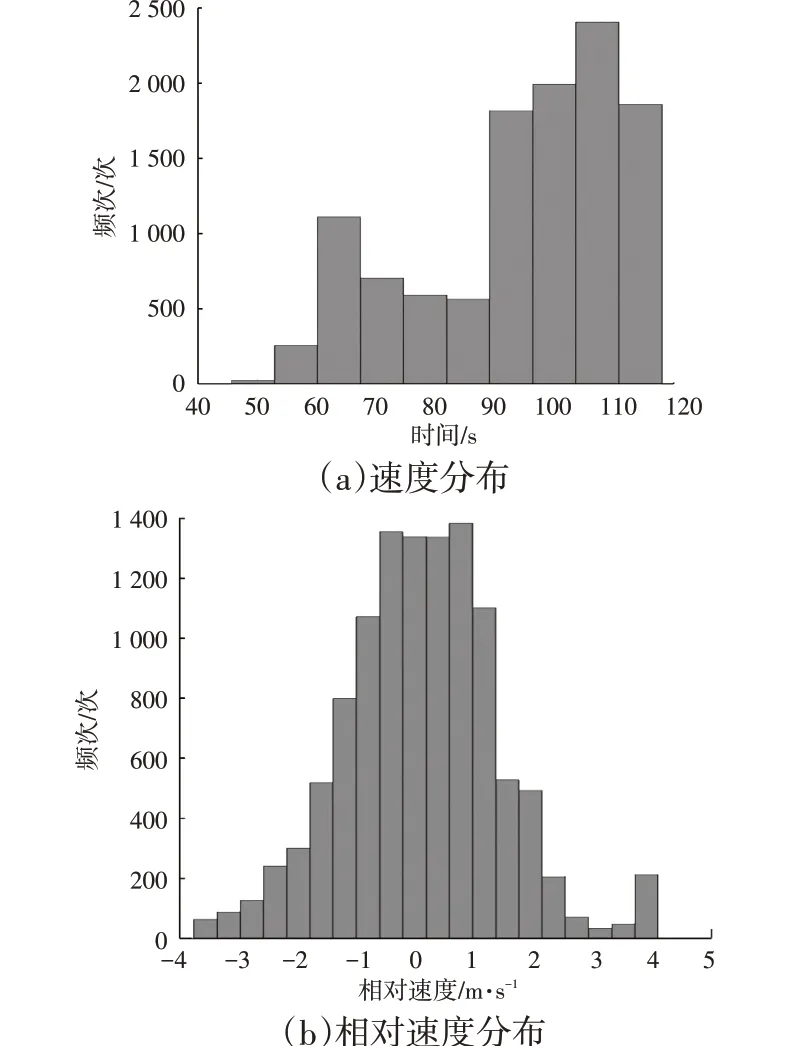

图4 跟车场景参数频次分布统计
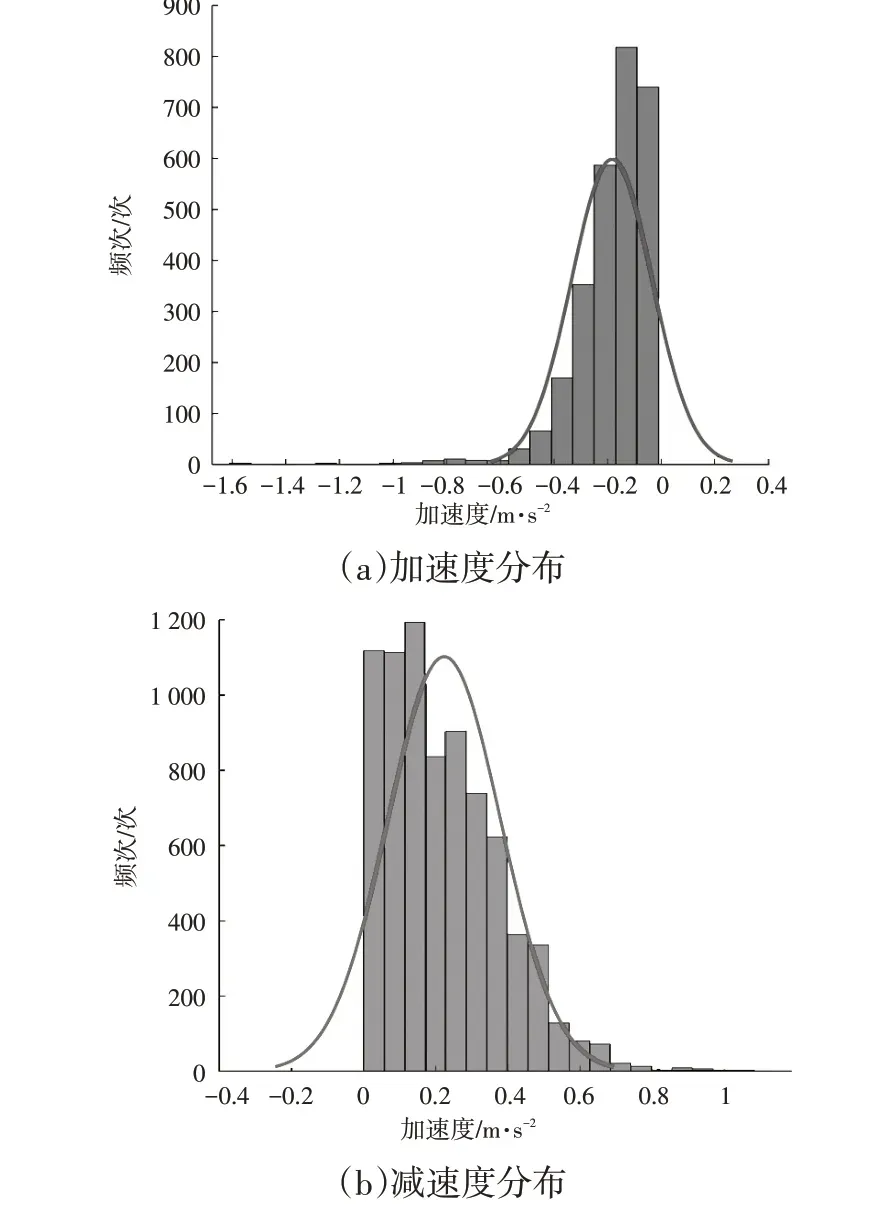
图5 加速度、减速度频次分布统计
可以看出,跟车状态下样本车的加速度、减速基本维持在-1~1 m/s2之间,这表明所提取的一些超过正常加速度、减速度范围的数值反应了安全性较差的跟车情况。
3 跟车场景特征要素的提取
3.1 跟车场景要素提取
场景要素是跟车场景聚类分析的依据,是主成分提取的数据来源。跟车场景要素的分类如图6所示,包括交通环境要素和场景主体要素2大类以及天气、光照等10个小类。其中,交通环境要素包括跟车场景中的天气类型、光照条件、道路类型、交通密度等,场景主体要素包括自车和目标车的车辆类型、车辆位置及运动状态等要素。

图6 跟车场景要素提取结果
(1)交通环境要素的提取
跟车场景的交通环境要素包括天气类型、光照条件、道路类型、交通密度等,天气类型包括4类:晴天、阴天、雨天、雪天,光照条件主要分为3类:白天、傍晚、夜间,道路类型主要包括5类:城市、高速、国道/省道、乡村道路,交通密度主要包括3类:畅通、正常、拥堵,其提取结果如表1所示。
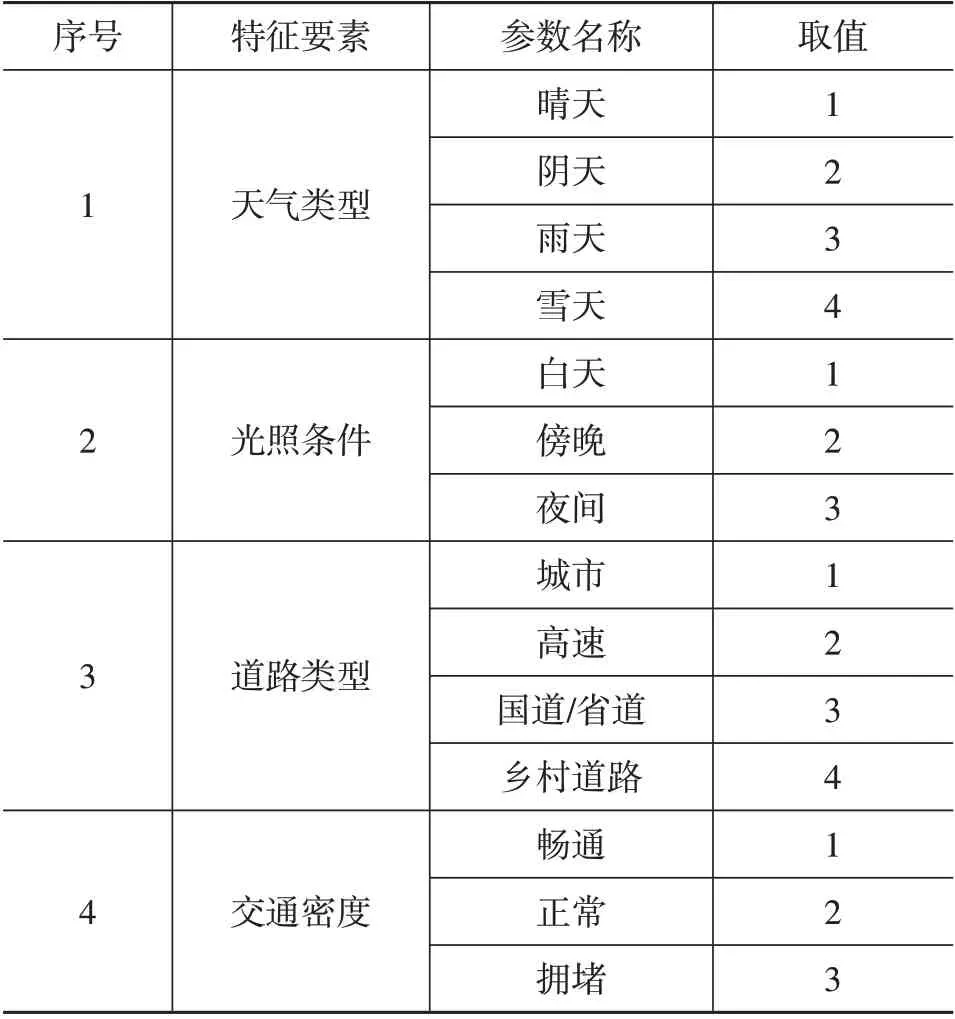
表1 交通环境要素提取结果
目前,受自动驾驶领域内感知技术发展的限制,交通环境要素还无法实现自动提取,需进行人工筛选。
(2)场景主体要素提取
场景主体要素如表2 所示,包括自车和目标车的车辆类型、车辆位置、运动状态等。其中,车辆类型包括轿车、大型货车/客车等;车辆位置及运动状态包括自车位置、自车距车道线位置、目标位置、自车速度、自车加速度、目标纵向距离、目标横向距离、相对速度等参数。

表2 跟车场景主体要素
定义场景主体要素提取矩阵Pmn,用以表征场景主体要素序号1~16 的提取结果(车辆类型单独考虑)。依据本文提取的1 010例跟车场景,获取的跟车场景主体要素矩阵如公式(1)所示。

式中,m为场景主体要素序号(m为1~16,要素序号对照详见表2),n表示提取的跟车场景片段个数。
至此,跟车场景特征要素提取已经完成,其提取过程有3个特点:
(1)考虑了跟车场景中的交通环境要素和场景主体要素,并对交通环境要素进行参数化,便于场景类型划分。
(2)场景主体要素基于主机厂的道路试验数据,提取的场景数据源于真实驾驶数据,且具有十分的典型性。
(3)从宏观角度出发,考虑自车和目标车的车辆类型对场景类型的影响。
3.2 主成分分析
由3.1节的场景主体要素矩阵Pmn可知,场景主体要素包含的参数维度较高。为简化计算,需要降低参数与参数之间的相关性,以达到可以便于聚类分析的要求。此外,由于自车与目标的车辆类型对跟车过程影响较大,需要单独考虑,对其类型进行划分。
(1)车辆类型
自车与目标的车辆类型包括轿车和大型货车/客车两类。依据车辆类型不同,可以将跟车场景划分为4种类型的跟车场景,如表3所示。

表3 场景分类
(2)车辆位置和运动状态
由3.1 节可知,跟车过程中的车辆位置和运动状态信息可由场景主体要素矩阵Pmn表征,由于矩阵维度较高,且变量之间的相关性较强,为了简化计算,需要对主体要素矩阵进行相关性分析和降维处理。
PCA (Principal Component Analysis)[12-14]是一种常用的数据分析方法。PCA 通过线性变换将原始数据变换为一组各维度线性无关表示,可用于提取数据的主要特征分量,常用于高维数据的降维。因此,本文使用PCA 算法对跟车场景中的主体要素进行相关性分析和降维处理。
PCA算法的过程如下:
(1)主体要素矩阵的标准化处理
在主体要素矩阵Pmn进行降维之前,首先采用公式(2)对矩阵中的参数进行标准化,消除量纲对参数的影响。
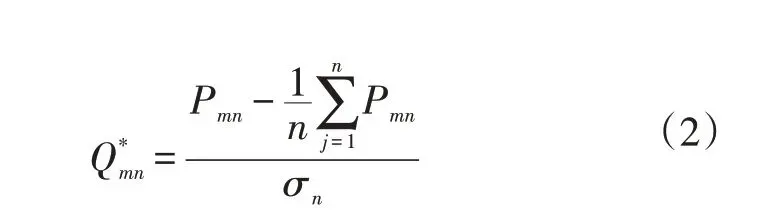
式中,Q*mn为标准化矩阵;Pmn为主体要素矩阵;σn为第n个跟车场景片段的特征参数标准差。
经过公式(2)对矩阵中的每一个参数进行标准化后,最终获得的主体要素标准化矩阵如公式(3)所示。
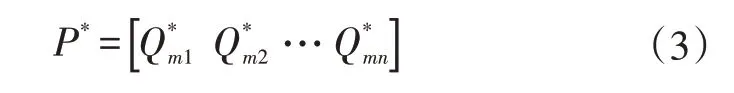
式中,Q*mn为标准化矩阵中第m行n列的值;P为主体要素的标准化矩阵。
(2)利用PCA算法对标准化后主体要素矩阵进行降维
主体要素矩阵经过标准化处理后,已经消除了量纲对矩阵中参数的影响,可以利用PCA算法对标准化后的矩阵进行降维处理,得到标准化后的矩阵参数线性组合R*。

式中,Q*mn为标准化矩阵中第m行n列的值;Pomn为相关系数矩阵。
在PCA算法的主成分分析过程中,任务主成分累计贡献率达到85%以上,即可认为主成分可以代表原始信息。进行标准化后的场景主体要素矩阵主成分分析结果如图7 所示,前3 个主成分的累计贡献率已经达到91.16%,完全可以表征跟车场景主体要素信息。依据主成分分析结果,将主体要素矩阵降为3维矩阵。

图7 主成分分析结果
跟车主体要素矩阵经过降维后,保留累计贡献率排名前3的主成分,其参数详见表4。
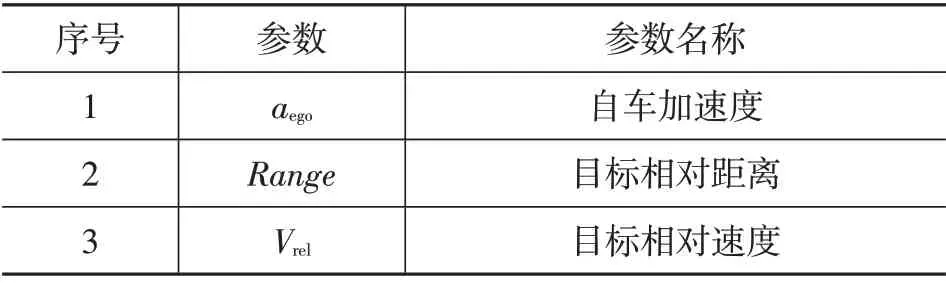
表4 累计贡献率排名前3的主成分
经过标准化后的主体要素矩阵使用PCA 算法降维后仅保留排名前3的主成分,降维后的矩阵如公式(5)所示。
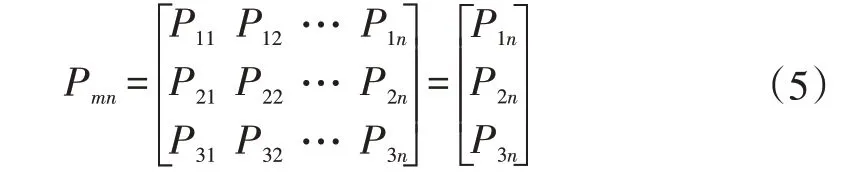
式中,P为降维后的主体要素矩阵;P1n,P2n,P3n依次代表自车加速度,目标相对距离,目标相对速度。
4 跟车场景聚类分析
4.1 K均值聚类算法
K 均 值 聚 类 算 法(K-Means Clustering Algo⁃rithm)[15-17]是一种迭代求解的聚类分析算法,在数据分析、信号处理以及机器学习等领域得到了广泛的应用。本文采用K 均值聚类算法对降维后的跟车特征参数矩阵进行聚类,聚类过程如下:
(1)定义初始聚类中心
在K均值聚类的计算过程中,首先需要定义初始聚类中心矩阵以及聚类中心个数k。
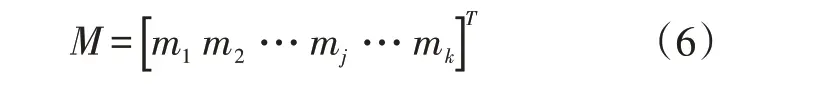
式中,M为初始聚类中心矩阵,mj为第j个聚类中心(j∈1,2,…,k),其值为随机数。此处聚类中心个数k取值为3。
(2)样本分配
在K均值聚类的计算过程中,每一轮迭代更新开始后,需要计算每个样本分别到每个聚类中心的欧氏距离[18],其计算过程如公式(7)所示。
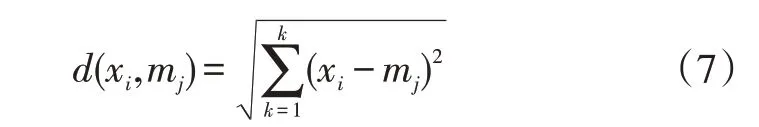
式中,xi为样本数据中的第i(i∈1,2,…,n)个样本,d(xi, mj)为第i(i∈1,2,…,n)个样本xi到第j(j∈1,2,…,k)个聚类中心mj之间的距离。
计算各个样本到各个聚类中心的距离之后,依据距离最小原则,将样本分配到与距离中心距离最近的类中,如公式(8)所示。
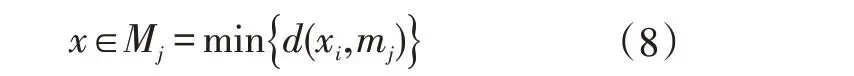
式中,x为样本数据,Mj为样本数据聚成的类。
(3)更新聚类中心
由第(2)步将样本数据聚为k类后,需要对聚类中心进行迭代更新,计算每一类样本数据的均值,使用每一类中所有样本数据的样本均值作为新的聚类中心,实现对聚类中心的更新,其更新过程如公司(9)所示。
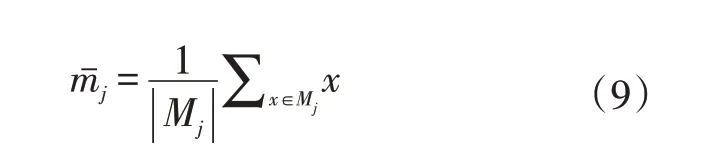
式中,mˉj为更新后的聚类中心;x为Mj(j∈1,2,…,k)类中的样本数据。
(4)准则函数的计算
在K均值聚类的过程中,当完成一轮样本分配和聚类中心的更新后,需要对聚类结果的准则函数进行计算,如公式(10)所示。若准则函数结果变化较大,重复第(2)和第(3)步,继续进行迭代更新。若准则函数的结果不变,则停止迭代,结束聚类。
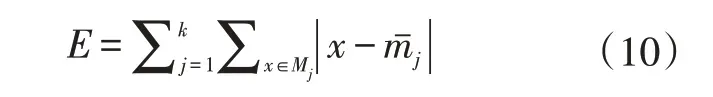
式中,E为准则函数;mˉj为更新后的聚类中心;x为Mj(j∈1,2,…,k)类中的样本数据。
通过以上步骤计算得到每个样本对所有聚类中心的准则函数进行计算,然后依据距离中心不变原则和误差平方和局部最小原则,终止样本聚类的更新迭代。
4.2 跟车场景聚类结果分析
利用MATLAB对样本进行聚类,除了K均值聚类外,还以车头间距、目标的相对速度、自车加速度进行模糊C 均值聚类,并作为对比(表5)。结果表明,K 均值聚类的相对距离和相对速度较低,且自车加速度较低,但结果都将样本聚类为3簇,因此将跟车场景分为3类。

表5 K均值聚类和模糊C均值聚类对比
依据场景主体要素的聚类分析结果,将跟车场景划分为Cluster 1~3类,聚类结果的样例如图8~10所示,结合场景的天气类型、光照条件等交通环境要素,共获得1 728类测试场景,其结果如表6所示。

表6 聚类分析结果 类
(1)场景聚类结果为Cluster 1样例
限于篇幅原因,选择1 例聚类结果为Cluster 1 的场景作为样例,示例1场景数据如图8所示,跟车的车头间距围绕一个值在小范围内上下浮动,将Cluster 1划分为稳定跟车。

图8 示例1的场景数据
(2)场景聚类结果为Cluster 2样例
限于篇幅原因,选择1 例聚类结果为Cluster 2 的场景作为样例,示例2场景数据如图9所示,跟车的车头间距不断缩小,相对速度恒为负值,将Cluster 2 划分为加速跟车。

图9 示例2的场景数据
(3)场景聚类结果为Cluster 3样例
限于篇幅原因,选择1 例聚类结果为Cluster 3 的场景作为样例,示例3 场景数据如图10 所示,跟车的车头间距不断增大,相对速度恒为正值,将Cluster 3划分为减速跟车。
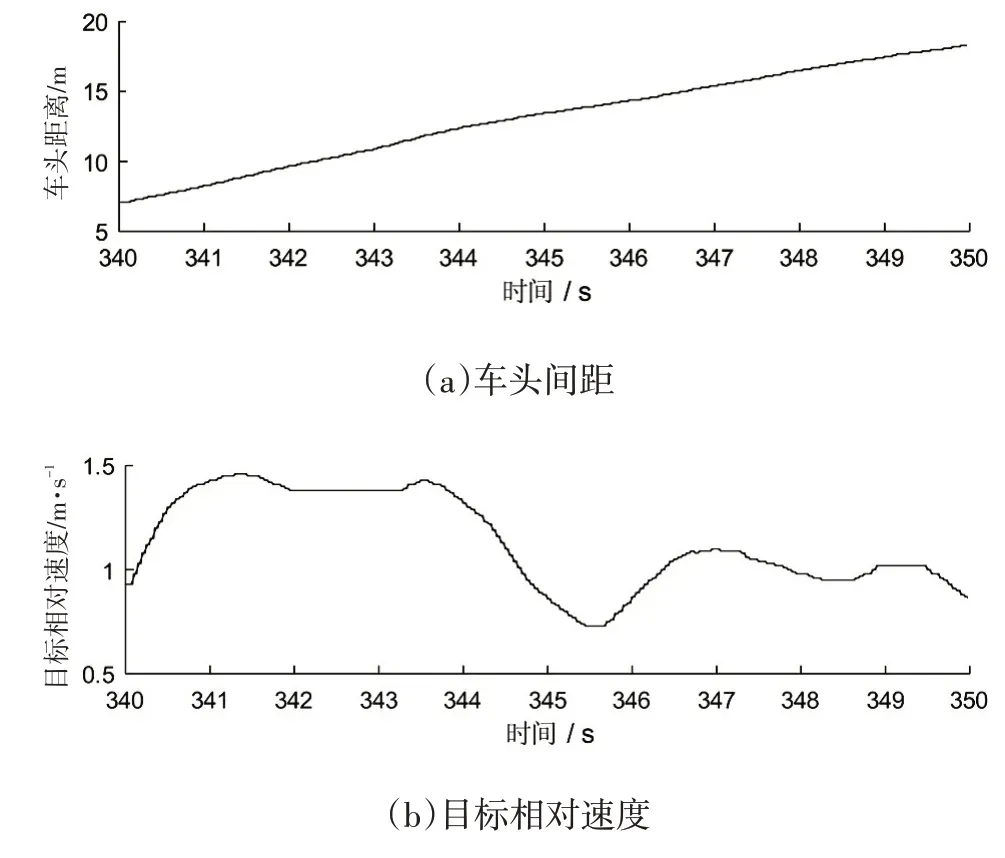
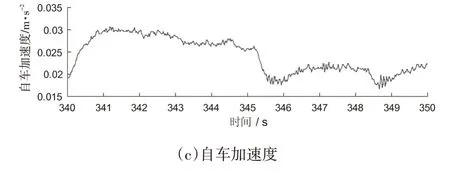
图10 示例3的场景数据
5 结束语
本文基于道路试验数据提取了跟车场景特征要素,运用K 均值聚类算法进行场景挖掘,挖掘获得大量具有实际价值的跟车场景,并以此为基础,构造了大量的跟车测试场景。场景数据源于真实道路试验,构建的场景更具有真实性、可靠性,对智能驾驶汽车的跟车仿真模型的建设具有重要意义。
未来的研究内容,将会依托提取的跟车测试场景,围绕高速领航功能、弯道跟车辅助功能、自动环道功能测试的仿真模型搭建展开。
