基于VGG16 网络的超参数调整策略的研究*
2021-12-04张铠臻李艳武刘博李杰谢辉张忠义
张铠臻,李艳武,刘博,李杰,谢辉,张忠义
(重庆三峡学院电子与信息工程学院,重庆 404100)
神经网络的优化与学习率的调整有着很大的关系,如果学习率的策略调整合适,模型的泛化性能会有明显的提升。通常神经网络中使用的学习率衰减为指数衰减、余弦衰减。除此之外,SMITH[1]提出了一种循环学习率调整策略,他提出了三角形循环学习率,阐述了如何寻找循环学习率的上界和下界的方法。针对需要手动调整学习率的策略,DUCHI[2]等人提出了一种Adagrad 自适应调整学习率的算法,有效减少了人工经验给模型带来的影响。但是Adagrad 自适应调整学习率算法随时间的增加,对历史梯度的累加使得学习率越来越小,在训练后期会使得模型的收敛速度很慢,针对这一问题,TIELEMAN[3]提出了RMSProp 算法,这种算法在对梯度进行指数加权平均上引入了平方根,有效缓解了Adagrad 算法在训练后期学习率极小导致模型收敛缓慢的缺点。针对RMSProp 算法和Adagrad 算法的优点,KINGMA[4]等人提出了Adam 算法,这种算法不仅引入指数加权平均计算,而且引入了误差修正。对于随机梯度下降算法(Stochastic Gradient Descent,SGD)的损失函数容易出现振荡,且梯度下降较慢的问题,NESTEROV[5]等人提出了Nesterov 加速方法并进行了理论证明,SUTSKEVER[6]等人提出了Momentum 算法以及说明了经典动量与Nesterov 加速梯度的联系,明显加快了梯度下降,文中还说明了可以以更大的曲率点缓慢梯度下降,不易振荡,Nesterov 加速梯度比动量算法更加稳定。文献[7]对梯度下降算法进行了详细介绍。
基于以上出现的优秀的学习率调整方法,很多学者对其研究与应用比较广泛。为了解决由于网络训练次数较多且收敛性较差的弊端,储珺[8]等人提出了网络可自适应调整学习率和样本训练方式的算法,主要根据训练误差来调整学习率同时根据输出结果改变训练样本,倾向于训练分类不准确的图像。贺昱曜[9]等人提出了一种AdaMix 组合型学习策略,这种策略考虑到神经网络传播时的权重和偏置,分别设置不同的学习率策略,有效提高了模型的收敛速度同时减少了训练时间。除了只考虑学习率的变化问题,仝卫国[10]等人还综合考虑了网络训练优化、网络结构选择以及权重初始化的因素。文献[11]讲述了训练神经网络分为前期、中期、后期三个阶段,通过实验验证了前期模型还是欠拟合状态,需要适当大小的学习率去拟合模型,在中期和后期,模型基本有着较好的拟合能力但没有达到最佳拟合能力,因此还要减小学习率,使得模型向着最佳拟合方向优化。文献[12]提出了一种k-Decay 方法,它是一种对任意可导的衰减函数都适用的学习率衰减函数的调整方法,通过引入控制学习率的衰减程度。除此之外,IOFFE[13]等人也提出了一种批量归一化的方法来优化神经网络,主要是通过将网络每层的输入分布保持一致来消除内部协变量偏移最终使得模型性能更好。刘建伟[14]等人也对批量归一化及相关算法的研究进行了综述并对批量归一化在神经网络领域的应用进行了总结。因此学习率衰减和批量归一化策略对模型的性能影响显著。
1 优化神经网络的方法
1.1 梯度下降法与动量法
梯度就是函数在某一点的方向导数上升最快的方向。而梯度的反方向就是在这个点下降最快的方向,在神经网络中,通过梯度下降走到最低点使得损失函数最小来让模型更有泛化能力。
设一个样本点为x,初始迭代为x0,第t次迭代为xt,其目标函数为f(x),则梯度下降法的公式如下:
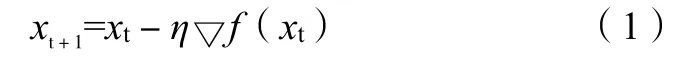
式(1)中:xt+1为样本点的第t+1 次迭代;xt为样本点的第t次迭代;η为学习率。
一种常用的梯度下降法是随机梯度下降法,它是每次仅随机选择一个样本进行梯度计算以更新权重,直到损失函数值不再下降或者下降到一个可接受的阈值以下才停止更新。因此,随机梯度下降算法更适用于神经网络的优化器。
动量法的核心思想是在一定次数迭代时,参数的更新方向通过计算其负梯度的加权移动平均得到。
1.2 学习率方法
常用的学习率调整策略分为非自适应调整学习率和自适应调整学习率。非自适应调整学习率有指数衰减、余弦变化、带热重启的学习率调整;自适应调整学习率有Adagrad算法、RMSProp 算法、Adam 算法。自适应调整学习率算法可以解决随机梯度下降法不能自动调节学习率的缺点。
指数衰减指一个初始的学习率η0,学习率随着迭代次数以指数形式衰减。
水权制度 水权指按照水法行使的对水的管辖权力,也指经过水行政主管部门批准给予用水户的对水资源处理和利用的权力。水权制度就是通过明晰水权,建立对水资源所有、使用、收益和处置的权利,形成一种与市场经济体制相适应的水资源权属管理制度。
余弦变化就是学习率随着迭代次数以余弦的形式周期性变化。文献[15]提出了一种带热重启的学习率调整方法,其思想就是如果梯度下降过程中重启n次,第n-1 次重启后迭代Tcur 次再进行第n次重启,在第n次重启之前利用余弦衰减降低学习率。
Adagrad 算法[2]是对随机梯度下降法手动调整学习率的一个改进,算法的思想是使用历史梯度平方一直累加后开方调整学习率,分子为初始学习率,这样就可以随着时间或迭代次数改变学习率了。
RMSProp 算法[3]是对Adagrad 的一个改进,主要思想是摒弃直接使用小批量随机梯度按元素平方和,而是将小批量随机梯度平方和做指数加权平均,这样就解决了由于随时间的变化学习率急剧减小的问题。
Adam 算法[4]计算了梯度平方和的指数移动平均值,主要使用两个参数来控制指数移动平均的衰减,通过一阶矩和二阶矩计算动量和速度,然后通过偏差校正来更新参数。
1.3 批量归一化
批量归一化的概念首先是IOFFE[13]提出的,由于在训练神经网络时,网络前一层参数的变化会引起后一层输入数据的分布发生变化,因此会导致饱和非线性的模型训练困难。批量归一化就是将每一层的输入数据进行预处理操作,处理后使得网络每层的输入数据的分布基本保持一致,它可以很好地处理反向传播的梯度消失和爆炸的行为。
因此,优化神经网络的方法可以从以上几个角度出发,除此之外还可以考虑权重初始化等优化方法让模型的泛化能力更强。
2 实验环境与测试方案
2.1 实验环境
实验在配有七彩虹RTX2080Ti 显卡和Inter 的i7-8700cpu 的Windows10 系统环境中进行的,基于Python 语言的Pytorch 深度学习框架,使用Cifar10 数据集对VGG16网络模型训练并测试。Cifar10 数据集包含60 000 张32×32的RGB 彩色图片,图像内容有“飞机”“猫”和“狗”等10 个类别。数据集的每个类别包括6 000 张图片,其中5 000张用于训练,剩下的1 000 张用于测试。因此,Cifar10 的训练集有50 000 张图片,测试集有10 000 张图片。
2.2 测试方案
本文通过研究指数衰减、余弦变化和1.2 节描述的自适应调整学习率算法对模型进行优化。使用了典型的VGG16网络在Cifar10 数据集上进行了训练与测试,实验中所有使用了批量归一化的模型的批量大小均为128 并且模型训练50 轮。
首先针对是否使用批量归一化方法对模型进行对比分析,分别使用两种VGG16 网络进行训练:①未使用批量归一化的VGG16 模型;②使用了批量归一化的VGG16 模型,批量大小为128。两种模型的优化器均为随机梯度下降法,经过大量调整学习率和权重衰减,设置初始学习率为0.01并在训练中保持不变,权重衰减为0.001。
其次针对不同学习率策略对模型的影响进行了对比分析,对于非自适应调整学习率方法,均使用随机梯度下降优化器,权重衰减为0.001。对每一种学习率策略设置多个学习率初始值进行测试,各种策略的调整方案为:①以0.01为初始学习率,动量为0.9,采用指数衰减方法,每轮学习率降为原来的95%;②初始学习率为0.01,动量为0.9,利用余弦变化策略,最小学习率为0,余弦变化周期为20 轮;③初始学习率为0.01,使用Adagrad 算法;④初始学习率为0.001,衰减因子为0.9,利用RMSProp 算法;⑤初始学习率为0.001,矩估计的衰减速率分别设置为0.9 和0.999,利用了Adam 算法。
为让实验数据更具有准确性,测试损失、测试精度、训练时间、训练时间都是经过5 次训练取平均值所得出的。
3 结果分析
首先对于学习率固定而训练的VGG16 网络,采用了两种不同的VGG16 模型,分别为不使用归一化策略与使用归一化策略的模型,两种模型均使用了随机梯度下降优化器,对应的收敛曲线和测试精度曲线分别如图1 和图2 所示。
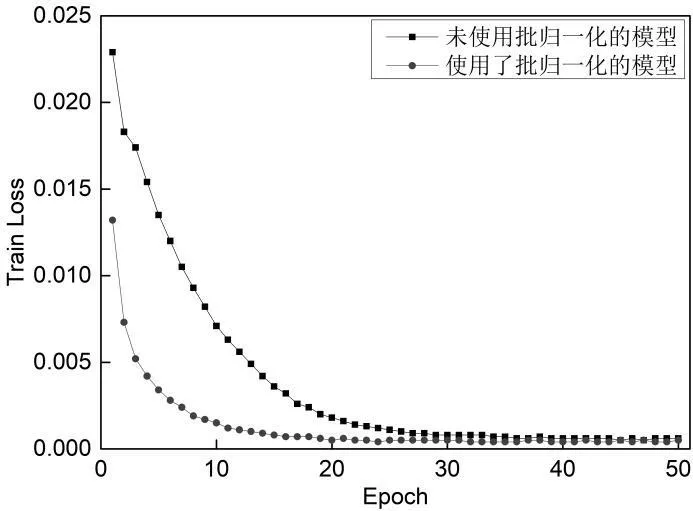
图1 两种模型的收敛曲线
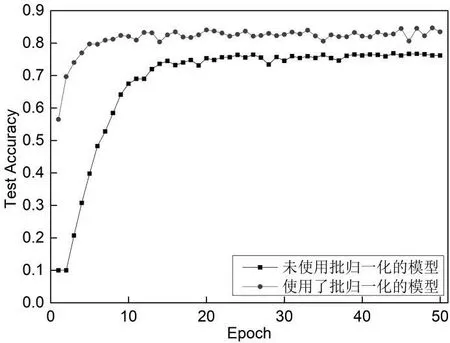
图2 两种模型的测试精度曲线
由图1 和图2 分析可知:从收敛的角度考虑,未使用归一化的模型比使用了归一化的模型的收敛速度慢,最终的训练损失更高,使用了归一化的模型好于未使用归一化的模型;从测试精度的角度考虑,未使用归一化的模型比使用了归一化的模型测试精度要低约6.5%,从两种模型的稳定性角度考虑,二者的稳定性相差不大,这可能是由于模型和数据集不足够大而出现的情况。
针对批量归一化策略,文献[13]对于这种情况有了很好的解释,他们认为,批量归一化策略就是将每一层的输入分布基本保持一致,这不仅可以使得输入的数据内部协变量偏移更小,还可以很好地处理反向传播的梯度消失和爆炸的行为,利用它可以使用相对较大的学习率在更深的网络中实现较大的性能;他们还认为模型和数据集越大,批量归一化的效果会更明显。
未使用批量归一化的模型的训练损失、测试精度、训练时间分别为0.000 5、78.192%、1 843.402 s,使用了批量归一化的模型的训练损失、测试精度、训练时间分别为0.000 4、84.712%、1 376.647 s。因此,使用了归一化的模型相对于没使用归一化的模型训练时间大幅度缩减并且测试精度显著提高,训练时间减少了约8 min,测试精度提高了约6.5%。由于批量归一化模型收敛时间、训练时间更短并且测试精度更高,因此,本文后面的实验是基于使用了批量归一化的VGG16 网络进行的学习率调整,批量大小设置为128。
图3 和图4 分别是2.2 节所描述的5 种学习率策略和不使用任何学习率策略应用到带有批量归一化的VGG16 网路中的收敛曲线和测试精度曲线。
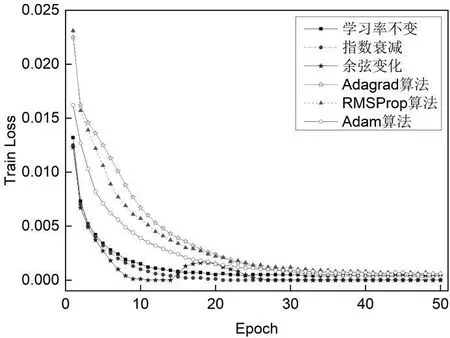
图3 不同学习率策略下模型的收敛曲线
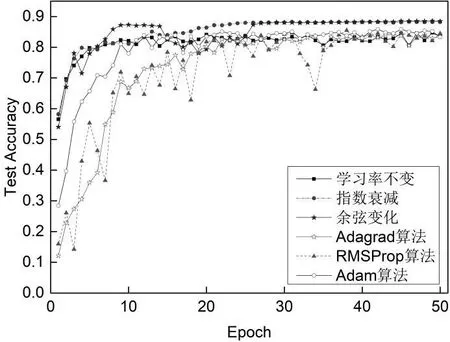
图4 不同学习率策略下模型的测试精度曲线
由图3 和图4 得出:从收敛速度方面,余弦变化先达到收敛,但由于余弦衰减中有学习率变大的情况,因此会导致收敛后又出现了训练损失上升,随后下降到收敛值;指数衰减方法略慢于余弦变化;接下来是学习率不变策略;利用Adam 优化器的收敛速度略慢于学习率不变策略。利用Adagrad 算法和RMSProp 算法要比Adam 算法的收敛速度略逊。从测试精度方面,余弦变化的测试精度最高;指数衰减的测试精度相对于余弦变化略低,而且指数衰减比余弦变化在收敛前更稳定;Adam 算法的测试精度略差于指数衰减;随后是RMSProp算法、学习率不变方法的测试精度;Adagrad算法的测试精度最低。RMSProp 算法最不稳定。
表1 展现出使用了上述各种学习率方法的模型的训练损失、测试精度和训练时间。从表1 中可知:指数衰减、余弦变化的训练损失最小;余弦变化的测试精度最高,达到了88.33%;Adagrad 算法的训练时间最短。前5 种学习率策略的模型的训练时间相差不大,比Adam 算法显著快。因此综合考虑,使用余弦变化策略的模型性能更好。
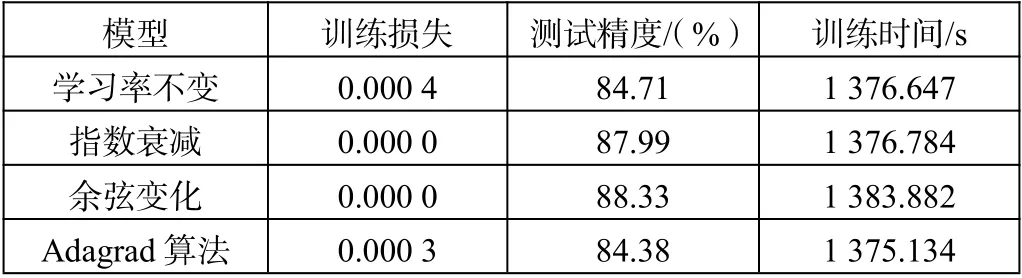
表1 使用6 种学习率策略的模型性能对比

表1(续)
4 总结
通过对模型使用批量归一化与不使用批量归一化进行了对比,经过实验验证,使用了批量归一化的模型在收敛速度、测试精度、训练时间以及模型稳定性方面都有了明显的提升。通过对学习率的衰减策略调整发现,虽然自适应学习率算法相对于非自适应学习率算法可以减少手动调节学习率,但性能不一定比非自适应学习率算法好。即随机梯度下降算法性能不一定要逊于Adam 算法,与相关的参数大小设置及网络模型的选择也有关。通过实验对比非自适应学习率算法和自适应算法的性能,证明了在VGG 网络中使用余弦变化方法使得模型的性能更好。优化神经网络除了使用不同的算法,调整学习率初始值与衰减方式、权重衰减值以及训练轮数都是重要的因素。本文主要研究了学习率策略,基于本文的研究基础上,将来的研究方向是:将权重初始化和学习率策略结合优化模型,探索可以加快网络训练并提高网络模型泛化性的优化方法。
