基于公交运行规律的乘客下车点推算方法
2021-12-03王妮满
王妮满,余 洋*,余 静,陈 昆,杨 航,秦 昆
(1.武汉大学 遥感信息工程学院,湖北 武汉 430079;2.重庆市地理信息和遥感应用中心,重庆 401120)
近年来,随着低碳健康生活、人本城市建设等居民新生活理念的提出,作为城市交通的重要组成部分,公交车的运行线路优化、车辆合理配置等问题得到广泛关注。车载GPS技术和AFC系统的迅猛发展,为采集乘客出行时空特征提供了一种积极有效的方式[1]。将GPS数据与AFC数据相结合,可使地理位置与乘客出行时间信息相匹配,有助于挖掘公交客流的时空分布规律,实现对公交运行的评价分析和居民出行行为的特征分析,为公交线路规划、公交站点选址以及辅助决策等提供良好的数据支持[2-5]。
上下车时间与站点信息是分析居民公交车出行规律的基础。目前,我国大部分地区公交采用一票制收费模式,系统中仅记录了上车刷卡时间,难以得知乘客的下车站点与时间,因此围绕推算上下车点这一问题,国内外众多学者已开展了大量研究,如Trépanier M[6]等通过分析不同乘客的出行特征,利用多次转乘距离最短来推算下车地点,但没有考虑规律性不强的出行轨迹;Munizaga M[7]等结合假定的转乘相邻站点的时间和距离,根据个人出行链确定乘客的下车点;Jung J[8]等基于AFC数据和土地利用数据,利用监督深度学习框架得到较准确的下车点推算结果,但需输入大量人工收集的样本;胡继华[9]等利用乘客出行链和站点客流量信息分析了乘客个体出行特征对站点吸引权重的影响,建立了基于出行链的下车点推算模型;贾奕宁[10]根据出行链判断乘客的下车与换乘行为,并基于“乘客的公交出行总量一定”原则计算公交OD矩阵;马晓磊[11]等针对有无GPS数据两种情况,分别提出了上车点推算方法,若有GPS数据,则采用GPS与IC卡数据相融合的方法进行推算,若无GPS数据,则采用基于移动步距的贝叶斯决策树算法推算上车点。目前国内外对于公交乘客下车点的研究,多针对具有明显出行链规律的乘客进行推算,缺乏有效的验证方法。
由于乘客的出行类型多,单一采用某种算法推算上下车点难以适应具备不同出行规律乘客的刷卡特征,因此本文设计了一种适应于多类型刷卡时间特征的上下车点推算框架。该框架在利用GPS数据提取公交车辆停靠站点的基础上,通过分析乘客AFC记录,提出了根据层次聚类推算乘客上车点时间与位置的方法;并以此为基础,对乘客类型进行了分类,研究了不同类型乘客适用的下车时间与位置推算方法;最后利用深圳公交车GPS和AFC数据验证了该框架的可 行性。
1 计算流程
利用GPS和AFC数据推算乘客上下车位置和时间的整体计算流程如图1所示,主要包括4个步骤:

图1 基于GPS和AFC数据判断上下车点的算法流程图
1)数据预处理。对GPS数据进行道路匹配、误差点过滤等处理,对AFC数据进行刷卡时序重建、无效时间过滤等处理,以保证参与计算的数据均为有效数据。
2)计算公交车的停靠时间和位置。本文利用停滞点提取、折返点提取和空间聚类等方法从公交车GPS数据中提取到站停靠点数据。
3)提取乘客上车位置。对AFC数据进行凝聚层次聚类,再与公交车停靠数据进行匹配,从而确定乘客的上车点。
4)推算乘客下车位置。对乘客刷卡数据进行统计分析,将乘客分为单日多次刷卡(M1)、多日多次刷卡(M2)和多日单次刷卡(M3)3种类型。针对不同类型的乘客,分别采用基于出行链的方法、基于历史数据的方法和基于站点吸引的方法推测其下车位置。
2 基于车辆运行规律的公交车站点提取
公交车站点提取是公交出行行为特征、公交运行规划等研究的基础。在实际运营中,由于GPS记录一般是按固定频率上传的,在车辆到站停靠时是否存在记录具有不确定性,需要利用GPS数据推算公交车的停靠位置和停靠时间。本文总结了公交车运行的基本规律:①在到达和驶离停靠点的过程中,公交车由减速至加速;②在公交线路的起始站点和终止站点上,公交车的停留时间相对其他站点更长;③在一条线路中,起始站点和终止站点间的行程距离是最长的。根据上述规律,本文设计了一种公交车停靠点提取方法,主要包括停滞点提取、往返点提取、停滞点聚类3个步骤,如图2所示。

图2 公交车站点提取流程图
2.1 停滞点提取
停滞点表示车辆在某一区域内停滞时间超过一定时间范围的点[12]。由于公交车GPS数据是沿途采样的,若直接对其进行聚类提取,数据量偏大且误差较大,而公交车在进站与出站之间会有一个短暂的时间停留,因此聚类前需先提取停滞点,这些停滞点具有更加丰富的语义信息[13]。
设一辆公交车GPS记录中第i个点pi的坐标为 (xi,yi),加速度为ai,速度为vi,Δt为GPS点的时间差,一般为固定值,Ps为停滞点集合,dist(pi,pi-1)为点pi和pi-1的距离。


根据规律①,设pi为停滞点,则Ps可记为:若有连续的GPS点序列满足加速度一直为负,则连续点序列中最后一个加速度为负的点为停滞点。
2.2 折返点提取
公交线路中同一站名的两个方向车站位置往往会错开一定距离,因此为了能准确提取公交车的停靠位置,需对GPS轨迹中的往返线路进行区分。设pj为一辆公交车的起止点,pj∈Ps;Pz为备选起止点集合;tj为该起止点对应的GPS时间;dist(pj,pj-1)为两个备选折返点pj和pj-1的行程距离。根据规律②,设T为线路每个站点停留时间的阈值,若两个相邻停滞点间的时间间隔超过T,则这两个点是备选折返点;同时考虑到车辆存在GPS信号丢失等情况,设S为距离阈值,若两个相邻停滞点间的距离小于S,则认为它们属于同一折返点。因此,备选折返点应满足条件:

根据规律③,设折返点为po和pd,公交车的折返点为行程距离最大值对应的两个点,应满足条件:

2.3 基于密度聚类的公交站点提取
设Ps中除折返点po和pd以外的停滞点为公交沿途停靠点,对于同一公交线路的所有公交车,依次按照§2.1和§2.2的方法进行处理,可得到该线路中公交车站位置的集合。本文利用DBSCAN[14]算法对提取的停滞点进行聚类。 DBSCAN算法需要指定E和MinPts 两个参数,其中E为搜索半径,MinPts为站点附近最少的停滞点数目。由于不同线路各站点附近的停滞点实际上存在数量不均匀的情况,因此利用停滞点进行站点聚类时,采用相同MinPts阈值易影响公交站点的提取精度。本文设计了一个权值,对每条线路进行停滞点聚类时,MinPts为该线路总停滞点数目N的加权结果,即

在此基础上,本文利用DBSCAN算法可将同一线路上的各公交站点逐一提取出来。
3 基于刷卡规律的上下车点推算
3.1 基于凝聚层次聚类的上车点提取
由于在同一站点上车的乘客刷卡记录在时间上具有集中性,同站上车的刷卡时间差小于在不同站上车的刷卡时间差,因此本文采用凝聚层次聚类法[15]对同一站上车的刷卡数据进行聚类,并以最短时间距离判断记录之间相似度。具体聚类步骤为:
1)按AFC数据的时间记录顺序,对属于相同车辆的刷卡记录进行排序,假定初始刷卡记录总数为n,将每一条记录作为待聚类对象。
2) 对记录进行两两比较,以相邻记录Ci和Cj之间的邻近度作为两条最近对象之间的时间差,并对最邻近的两个记录进行合并。记录Ci和Cj之间的邻近度可记为:
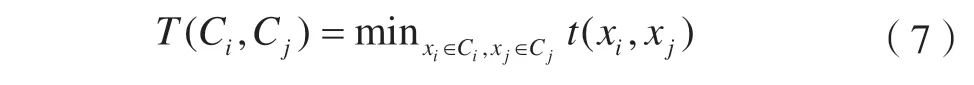
式中,t(xi,xj)为记录之间的时间差。
3) 设相邻两站之间的运行时间阈值为Tmin,可根据公交车的平均速度和相邻公交站间的距离来推算Tmin。
4)当T(Ci,Cj)<Tmin时,将记录Ci和记录Cj合并为新的聚类簇,值为两条记录时间相加的平均值,重复步骤2)。
5)当T(Ci,Cj)≥Tmin时,输出记录Ci和记录Cj内点的GPS平均坐标,作为这两条记录对应的上车点。
3.2 基于乘客刷卡模式的下车点推算
为了推算乘客的下车点,根据刷卡次数,本文将公交车乘客分为3种类型:单日多次乘客(M1)、多日多次乘客(M2)和多日单次乘客(M3)。利用上车点的提取结果,结合不同类型乘客出行规律和刷卡历史数据,可对乘客出行的下车点进行推算。
1)基于出行链的下车点推算。对于M1型乘客,其每天出行的起止点在空间上呈相互衔接的环状结构,可基于出行链来推算下车点。若城市居民一天内多次出行均采用公交作为出行方式,则其公交出行会构成一个闭合环,即出行链,如图3所示。
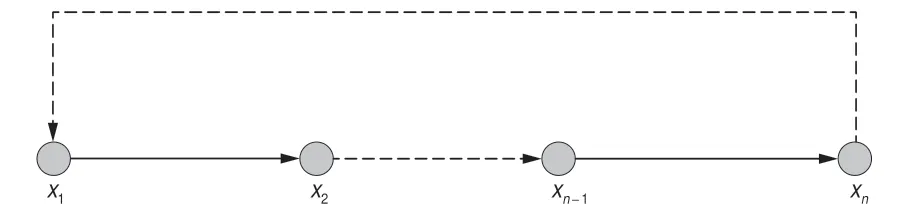
图3 闭合公交出行链
对于符合出行链特征的乘客,其上下车点推算方法基于两个假设:①前一次乘车的终点是下一次乘车的起点;②同一天内首次乘车的起点是最后一次乘车的终点。根据上述假设,设xn为某乘客一天内第n个上车点,N为该乘客一天内的上车点总数,x′n为其对应的下车点,则有:

2)基于历史数据的下车点推算。对于M2型乘客,其出行可能采用多种交通方式,因此一天内的公交出行链可能是不闭合的。由于城市居民出行具有一定的规律性,大部分出行记录都发生在居住地和工作地(或学校)之间,因此可根据历史记录来推算乘客的下车点。以图4中乘客的上车点为例,其第一天数据中存在闭合环,即前一时刻的下车位置为下一时刻的上车位置;但在其他日期不存在,第三天的起点数据与第一天在时间和空间上相似,则推断其下车点与第一天的下车点相同。

图4 基于历史数据的下车点推算
3)基于站点吸引的下车点推算。刷卡数据中还存在多日刷卡次数较少的乘客,其出行既不能构成出行链,历史数据也难以直接用于推算。对于这种情况,本文采用站点吸引法推算其下车点。
研究表明,居民在5~10 km范围内出行搭乘公交的概率较大,小于5 km或大于10 km则会采用其他出行方式[16]。在只考虑站间距离时,乘客在某点的下车概率随途经站点数量服从泊松分布[17],则有:

式中,Fij为在公交站点i上车的乘客在站点j下车的概率;λ为途径站点数量。
乘客下车点的选择也易受站点周围设施的影响,处在交通枢纽、购物休闲娱乐场所以及教育、医疗等设施处的站点吸引力较大,辐射半径也较大[16],乘客在这些站点下车的概率较高。从整体来看,某个站点对乘客自此上车和自此下车的吸引力是相等的,因此可利用站点上车人数计算站点吸引强度。公交线路各站点的吸引权重Wi可表示为[17]:
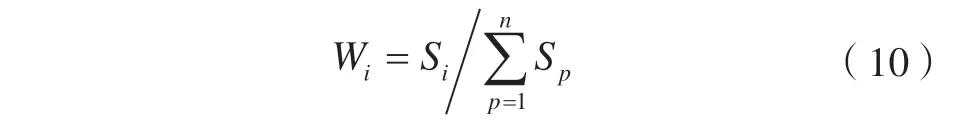
式中,Si为在第i个站点上车的人数;n为该条线路站点的总数。
此外,由于M1型和M2 型乘客的数据记录,推算结果较准确,本文尝试利用这些乘客的下车点推算结果修正站点吸引力权值的影响。修正系数Qi的计算公式为:

式中,Ri为M1型和M2型乘客推算后,在第i个站点下车的人数。
根据上述计算结果,乘客下车概率的计算公式为:

取所有站点中概率最大的点为M3型乘客的下车点。
4 实验分析与评价
4.1 数据来源
本文采用的数据是2014-09-01-09-09的深圳市公交车GPS轨迹数据和IC卡刷卡数据,涵盖深圳市500条公交线路,共8 471辆公交车。公交车GPS轨迹数据和AFC数据的基本格式如表1、2所示。

表1 公交车GPS轨迹数据描述

表2 AFC数据描述
4.2 提取结果
利用本文提出的方法提取的部分停靠点与百度地图叠加的结果如图5所示,红色五角星表示聚类提取的公交停靠点,与实际百度地图结果几乎一致。

图5 公交站点提取结果
2014-09-01早上8点的上车点、下车点提取结果如图6、7所示,不同大小的点表示该站上、下车人数,可以看出,提取的上车点位置与实际公交站点位置基本吻合。

图6 上车点提取结果
4.3 结果验证
乘客下车点提取结果的验证原理为:由于M1型、M2型乘客的出行记录呈现较明显的出行链特征,推算结果较准确,因此以基于出行链下车点推算方法推算的M1型乘客下车点、基于历史数据下车点推算方法推算的M2型乘客下车点的结果为真值,并删除部分M1型、M2型乘客上车点记录,使其尽量变成M3型乘客刷卡记录;然后利用基于站点吸引下车点推算方法推算M1型、M2型乘客下车点,并对推算的下车位置进行评分。以M1型乘客为例,设M1型乘客数量为n,基于出行链方法推算的下车点位置为PMi(i=1,2,…,n),基于站点吸引方法推算的下车点位置为P′Mi,di为PMi与P′Mi之间的欧氏距离。基于站点吸引的下车点推算方法准确率的定义为:
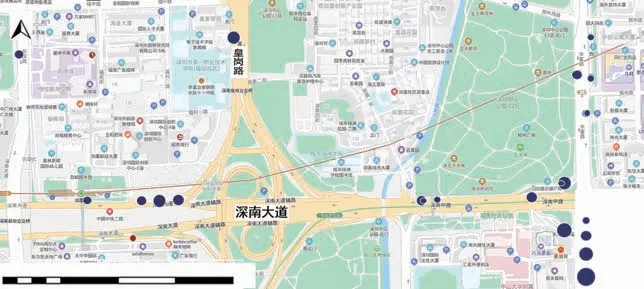
图7 下车点提取结果
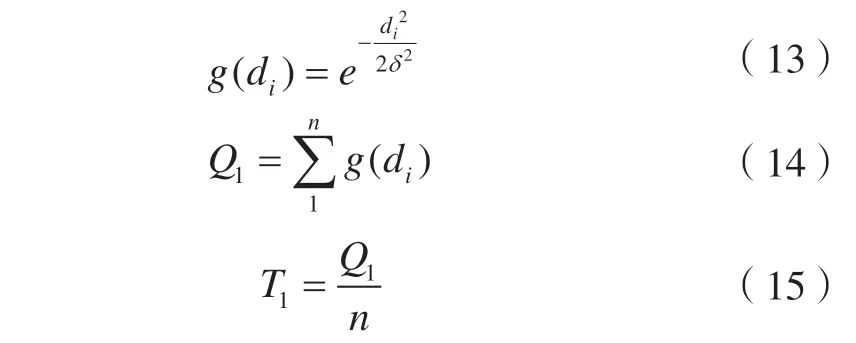
式中,g(di)为基于站点吸引的下车点到实际站点的距离得分,范围为0~1,数值越大代表得分越高,该下车点预测的准确率越高;Q1为所有M1型乘客下车预测点的评分总和。
同理,可利用该方法验证M2型乘客通过基于站点吸引的下车点推算结果的准确率Q2,最后将Q1、Q2取平均,即为总的乘客下车点的匹配成功率。通过上述方法计算得到乘客下车点的匹配成功率为65%,表明本文的下车点提取能大致预测乘客的下车位置,为研究乘客的出行特征提供基础。
5 结 语
本文提出了一种基于公交运行规律的乘客下车点计算方法,利用公交车GPS和IC卡数据推算了乘客的上下车点,并验证了该流程的可行性。通过分析公交车运行规律,本文提出了公交车停滞点和折返点的提取方法,并结合密度聚类法完成了公交站点的提取。在此基础上,通过分析乘客上车刷卡时间特征,利用凝聚层次聚类法提取了乘客上车点的位置与时间;针对3种类型的乘客,分别利用基于出行链、基于历史数据和基于站点吸引3种方法完成下车点的推算,并对结果进行了分析评价。
实验结果表明,本文提出的方法在缺少样本数据的情况下,能较好地提取公交站点的位置,对于乘客下车点的提取也具有采用价值。未来加入更多实验数据和样本数据后,可对参数做进一步优化,下车点推算的精度将有进一步提高的空间。
