面向复杂来源的大数据分析架构研究
2021-12-02熊燕
摘要:大数据时代数据的大不仅仅在于数据量的多少,更为复杂的是数据结构的多样性。本文首先介绍了研究背景和研究目的。然后分析了大数据可能的来源,从这些来源初步可以判断出数据形式的复杂。紧接着对不同类型数据进行了特征分析,重点在于地理数据及人类反馈信息。基于对复杂数据的特征分析,随后给出深度数据分析的工作流程,提出基于聚类算法模块的全局架构设计方案。
关键词:聚类分析,GIS,人类,时空,维度
前言
对于一个社会来说,信息获取由三大部分组成,一个是物理,一个是人类本身,一个是信息。当今大数据趋势呈不断上升趋势,除了物理传感以外,时空数据的感知渠道新增了许多。首先是互联网,像Facebook、微博、微信等有大量的信息每天都在网上,这些信息大量反映社会发展的现状,也包括人文的一些理解和信息,以及包括人的相关观点模型。
数据很“大”不仅仅是数据很“多”。事实是,大数据的类别、数据间关联的复杂才是真正的“大”。处理海量的复杂的数据,首先要弄清楚这些数据的来源。来源不同的数据造成了数据的积累、数据结构复杂度的提升。
1.大数据来源分析
1.1现实社会大数据的产生
首先当今许多行业的日常工作几乎都是在互联网上进行,关键词搜索、各官网平台数据交互、数据通信等。
第二是智能手机,智能手机更多地反应了个人在社会经济中的行为,如在线申报、及时通信、各种APP等。
第三是导航设备,包括实时的交通、路况各种信息,都是由导航设备得到的。
第四是视频监控,城市、企事业单位里现在有大量的视频,每个城市都有几十万、上百万甚至更多,这些视频从原理上说既是感知物理世界的视频,同时也是感知人类社会的视频。对人流量感知,对突发事件的感知,都会有大量信息获取。
最后,现在很多人戴的手环、电子表,这些可穿戴设备本身提供很多的信息,包括个人、群体的信息等。
1.2量化与感知数据
针对这些来源,一些可由物理感知获取较量化的数据,较复杂的是社会感知产生的数据。那么,现在对于一个应用,越来越多地需要同时获取来自物理感知和社会感知的多方数据,并能为这个应用同时服务。
首先,我们就需要识别有哪些数据来源,并分析这些不同来源数据的特征。其次,这些来源经常会涉及不同领域、不同物理设备以及人类自身,因此必然造成从这些复杂来源获取数据的复杂多样化。这些数据有些本身在结构性、动态化等方面就已经非常复杂,如何统一收集、管理、分析这些数据的任务复杂度则是呈级数增加。如何融合复杂来源的大数据高效地为同一应用所服务,我们需要分析来自复杂来源大数据的个性及共性特征。进而,清理出不必要的冗余,找出不同来源数据的关联性。
在《面向复杂来源的大数据分析架构及算法模型研究》项目实施中,发现用户在网络和数字地图上的活动数据具有GIS数据的时空特性,还具有人类本身感知反馈产生的数据。这些数据造成了多种应用系统大数据处理的复杂度。
2.多种数据特征分析
2.1GIS数据特征分析
如今,社会上许多行业和部门都在使用GIS(Geographic Information System)。在研究项目中,某职能部门的预警系统时时刻刻都在收集地理数据。
地理数据是与空间相关的。它可以被分配坐标或任何空间引用。数据在地球表面,包括位置和组织。地理数据的规模可以从一般到具体,从简单到复杂。一颗卫星每天可以产生几百万兆的数据。地理数据是动态的,包括空间动态(空间变化)和时间动态(时间变化)。地理数据既具有空间特征,又具有属性特征,并随时间变化。因此,数据量非常大。
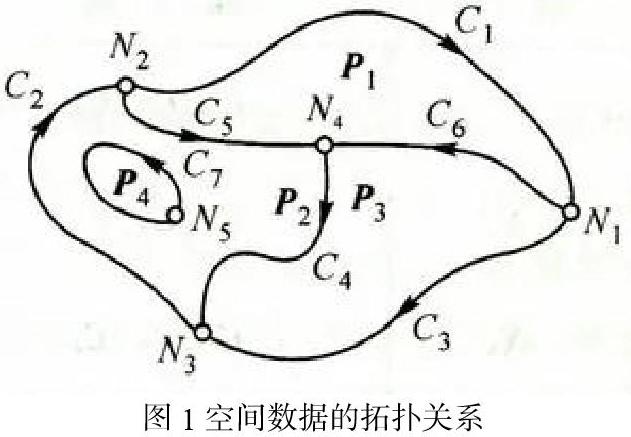
空间数据是指用来表示空间实体的位置、形状、大小和分布的数据。它可以用来描述现实世界的目标。它具有区位性、质量性、时间性和空间性的特点。空间物体在已知坐标系中具有独特的空间位置。质量是指空间目标的性质,伴随着目标的地理位置。空间目标会随时间改变。空间关系通常用拓扑关系来表示,如图1所示。空间数据是人类赖以生存的自然世界的数据。空间数据由基本的空间数据结构(如点、线、面和实体)表示。
2.2人类反馈数据特征分析
在研究项目中,某职能部门的预警系统不仅定时收集固定時刻的地理数据。同时,在有临时事件触发预警系统时,可能会收集触发系统的民众信息。这些信息包括:民众的地理位置、反馈时间、反馈事件、预警等级、民众个人信息、意见等。
相对较量化的地理数据而言,人类反馈信息的准确性、清晰度都是不定的。也就是说相对而言,数据“噪音”较多。那么在大数据分析架构中需要考虑“噪音”的处理。
首先,原始数据不准确性是产生不确定性数据最直接的因素。物理仪器所采集数据的准确度受仪器的精度制约;在网络传输过程(特别是无线网络传输)中,数据的准确性受到带宽、传输延时、能量等因素影响;在传感器网络应用与RFID应用中,周围环境也会影响原始数据的准确度。
第二,从粗粒度数据集合转换到细粒度数据集合的过程会引入不确定性。例如,假设预警系统以行政区为单位统计预警人数,而需要精确到街道时,则预警人数存在不确定性。
第三,缺失值产生。装备故障、无法获取信息、与其他字段不一致、历史原因等都可能产生缺失值。无论是用插值还是删除的方法,都有可能变动原始数据的分布特征。
第四,不同数据源的数据信息可能存在不一致,在数据集成过程中就会引入不确定性。例如,应用前端中含很多信息,但是由于页面更新等因素,许多页面的内容并不一致。
还有一点,也是较常出现的问题。人类在移动过程中产生的地理数据很容易出现不确定性。LBS(Location-Based Service)是移动计算领域的核心问题,在军事、通信、交通、服务业等领域有着广泛的应用。LBS应用获取各移动对象的位置,为用户提供定制服务,该过程存在若干不确定性。首先,受技术手段(例如GPS技术)限制,移动对象的位置信息存在一定误差。其次,移动对象可能暂时不在服务区,导致LBS应用采集的数据存在缺失值情况。
3.深度数据分析的工作流程
首先,必须确定系统需要哪些数据。数据资源可以通过访问公众、收集地理信息等方式获得。可以先把所有的数据进行分类、去噪、初步筛选。其次,只有遵循正确的程序,我们才能有效地应用深度数据分析挖掘技术。
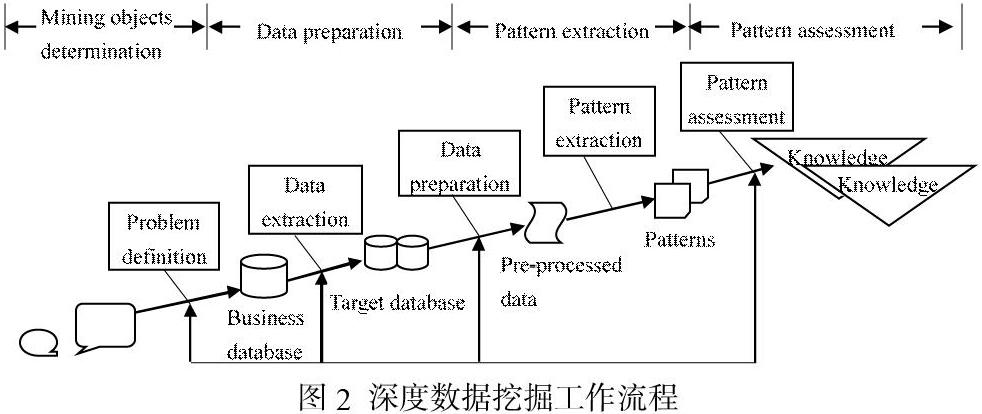
图2给出了深度数据分析的工作流程。从这个流程中,可以直接确定每个阶段的任务。工作流包括四个阶段: 挖掘对象确定(Miningobjects determination)、数据准备(Data preparation)、模式提取(Pattern extraction)、模式评价(Pattern assessment)。
在此工作流程中,从问题域直接获取的业务数据库,依据应用需求经过数据“清洗”提取获得目标数据库。然后针对目标数据库,对数据进行预处理,当然是基于模式提取需求的。模式提取使用一些科学的计算方法,得到可用模式集。最后根据用户意愿评价模式,用户意愿可以使用一些评估值或阈值设定提取范围,评价出的模式用以辅助用户决策。
4.基于聚类算法模块的全局架构设计
在确定了数据来源之后,应用科学的流程对不同类型特征的复杂来源数据进行预处理后,即可构建数据挖掘的算法架构。
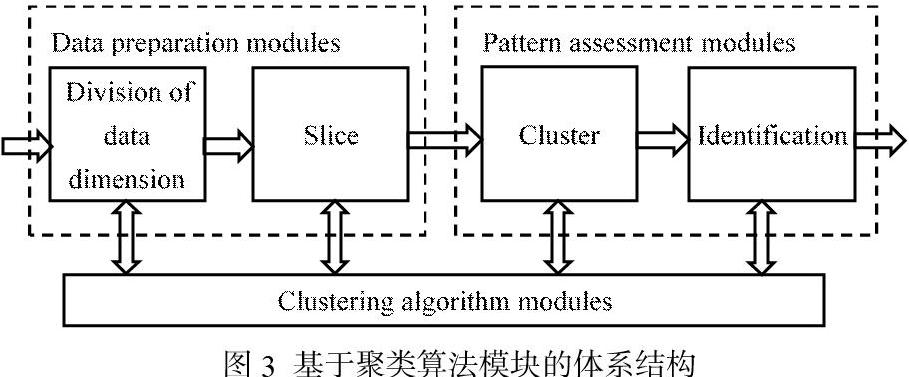
如图3所示,基于聚类算法的体系架构由四个部分组成: 数据维的划分、切片、聚类、识别。
聚类(Cluster)分析是由若干模式(Pattern)组成的,通常,模式是一个度量(Measurement)的向量,或者是多维空间中的一个点。
广泛获取不同来源的大数据后,首先设别出不同类型的数据,对这些数据进行分类,有些数据存在多种维度。在Data preparation modules阶段,对数据的维度进行划分,根据应用需求切片。本阶段,可根据应用需求的变化,重新设定维度划分的大小、切片的标准。以此尽量获得应用需求所需粒度的维度数据。一个数据库或者数据仓库可能包含若干维或者属性。人类的眼睛在最多三维的情况下能够很好地判断聚类的质量。在高维空间中聚类数据对象是非常有挑战性的,特别是考虑到这样的数据可能分布非常稀疏,而且高度偏斜。
在Pattern assessment modules阶段,应用合适的聚类算法,计算出相关模式,然后根据人类自定义的阈值选取结论,产生数据深度挖掘后的结论。很难对聚类方法提出一个简洁的分类,因为这些类别可能重叠,从而使得一种方法具有几类的特征。本研究主要用到的聚类分析计算方法有:划分法、层次法、基于密度的方法等。
大部分划分方法是基于距离的。给定要构建的分区数k,划分方法首先创建一個初始化划分。然后,它采用一种迭代的重定位技术,通过把对象从一个组移动到另一个组来进行划分。一个好的划分一般准备是:同一个簇中的对象尽可能相互接近或相关,而不同簇中的对象尽可能远离或不同。
系统关注的是地理数据的维度,这些数据被信息需求分割。然后高密度区域被划分为集群。在对数字地图进行聚类之后,用户可以进一步识别地图上的深度信息。
结语:空间数据已广泛应用于社会各行业、各部门,如公安系统、城市规划、交通、银行、航空航天等。随着科学和社会的发展,人们已经越来越认识到空间数据对于社会经济的发展、人们生活水平提高的重要性,这也加快了人们获取和应用空间数据的步伐。空间数据及人类反馈的不确定性数据的综合分析处理,对各种应用系统产生决策信息的有效性起着至关重要的作用。
参考文献:
[1]Arabameri Alireza, Pal Subodh Chandra, Rezaie Fatemeh et al. Modeling groundwater potential using novel GIS-based machine-learning ensemble techniques[J]. Journal of Hydrology: Regional Studies. 2021, 36
[2]张晓东.基于复杂系统理论的平行城市模型架构与计算方法[J].指挥与控制学报. 2021,7(01)
[3]Venkat Rayala. Big Data Clustering Using Improvised Fuzzy C-Means Clustering[J].Revue d’Intelligence Artificielle. 2020,34
项目来源:面向复杂来源的大数据分析架构及算法模型研究,湖北省教育厅2019年度科研计划项目,项目编号B2019285
作者简介:熊燕,女,副教授,湖北省武汉市武昌理工学院,人工智能学院
