基于特征工程的重要节点挖掘方法
2021-12-02尹春林陈端兵
潘 侃,尹春林,王 磊,陈端兵,3*
(1. 云南电网有限责任公司电力科学研究院 昆明 650217;2. 成都数之联科技有限公司 成都 610041;3. 电子科技大学大数据研究中心 成都 611731)
现实生活中的复杂系统(如交通运输系统、生物系统)可以很自然地用图表示,其中节点表示系统中的各个要素,边表示要素之间的关系[1]。复杂网络的研究逐渐从宏观层面深入微观层面[2]。节点作为系统中最小的元素,不同节点在系统中的地位是不同的。重要节点是指相比于网络中其他节点,能更大程度地影响网络功能的一些特殊节点。这种节点数量不多,但是其影响力却可以快速波及网络中大部分节点,如社交网络中权威账号的舆论引导,交通网路中重要路口堵塞导致交通系统瘫痪等。节点重要性排序[1]和相对重要节点的挖掘[3-4]对现实生活有着重要的指导意义。在网络分析中,节点的重要性通常用中心性[5]来度量,其主要目的是为基础网络的每个节点分配一个实值,用于度量该节点对其他节点的影响力。目前已有不少成熟的节点中心性计算方法,主要分为两类[3]:1) 基于网络结构特征的指标和方法;2) 基于随机游走的指标和方法。
基于结构特征的指标和方法主要根据其他节点与已知节点之间的网络结构特征设计相对重要指标。这些方法通过捕捉节点之间的局部连边信息或路径信息,衡量节点的重要性。度中心性(degree)是最简单的中心性度量方法,主要利用网络节点的连边信息刻画节点的重要性。度中心性认为一个节点邻居数目越多,该节点影响力就越大。但若节点在网络中属于核心位置,即使它本身度很小,也有较高的影响力。基于此,文献[6]提出了基于K-壳分解(K-shell decomposition)的K-shell 中心性,该中心性将外围的节点层层剥去,使处于内层的节点拥有较高的影响力。还有一些基于路径的中心性计算方法,如节点的接近中心性(closeness)[7]考虑将节点与其他节点的测地距离之和的倒数作为节点重要性。而介数中心性(betweenness)[8]认为经过一个节点的最短路径越多,这个节点就越重要。受到介数中心性启发,流介数中心性(flow betweenness)[9]、连通介数中心性(communicability betweenness)[10]、随机游走介数中心性(random walk betweenness)[11]和路由介数中心性(routing betweenness)[12]相继被提出。除此以外,H-index[13]作为评价学者学术成就的权威方法,也能很自然地延伸到复杂网络的重要节点挖掘任务中。
上述方法能够很好地捕捉节点周围的局部结构信息。除此之外,很多学者采用基于路径和随机游走的方法,利用整个图的拓扑信息挖掘图中的重要节点。在不考虑时间开销的前提下,从初始节点出发将信息传播出去,当随机游走趋于稳定时,信息保留越多的节点越重要。特征向量中心性(eigenvector)传播时不仅考虑节点的邻居数目,也同时考虑每个邻居节点的重要性。另外,学者们还提出了HITs[14]、LeaderRank[15]、PageRank[16]、Vote Rank[17]等 其 他全局游走的方法。总体而言,这些基于全局游走的方法计算成本较高,不能有效地应用于超大规模网络。文献[18]考虑四阶邻居,提出了局部中心性方法LocalRank,在时间复杂度和准确率之间找到了一个较好的平衡点。
虽然复杂网络中检测节点重要性的方法很多,但它们都试图找到能反映节点重要性的某种因素。但节点重要性之所以不同,是因为不同节点周围的结构是异质的[19]。因此,本文利用机器学习方法挖掘节点结构特征与节点重要性之间的关系。首先基于二步可达子图的节点信息,采用特征工程中的特征提取、特征重构方法,提出能描述节点周围信息的特征集合。再利用简单的线性回归模型(linear regression model)[20],学习节点局部结构与节点重要性之间的关系。在13 个真实网络中,将训练所得模型与度中心性、介数中心性[8]、K-shell[6]、H-index[13]和DynamicRank[21]中心性进行了比较。实验结果表明,本方法能更准确、更有效地识别出复杂网络中对信息传播影响较大的重要节点。
1 基于特征工程的重要节点挖掘方法
重要节点挖掘是网络攻击和信息传播及控制等领域中的核心问题之一。网络中的少数节点具有非常高的影响力。而造成网络中节点重要性差异的根本原因是节点周围的结构差异[19]。闭塞的局部结构会阻碍节点影响力的传播,而好的局部结构会促进信息在网络中传播。
本文研究主要针对无向无权图G(V,E),其中V={v1,v2,···,vn}是 节点集合,E={e1,e2,···,em}是边集合,n和m分别是节点数量和边数量。为了提取和重构节点邻居信息得到节点的局部结构特征,首先拓展两个邻居的定义。
定义1 二阶邻居
若网络中节点u的一阶邻居定义为 Γ1(u),那么节点u的二阶邻居可定义为:

定义2 二阶外联邻居
二阶外联邻居属于二阶邻居的子集,区别在于二阶外联邻居是二阶邻居与一阶邻居的差集,定义如下:
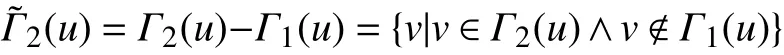
从局部角度考虑,节点的度以及节点邻居的度最能反映节点的局部结构特征。除此以外,现有的中心性算法中,H-index 和K-shell 也是能较好反映节点重要程度的中心性指标。然而这些中心性指标对节点周围复杂多样的局部结构还是很难刻画。
度中心性可以广泛地概括简单图中重要节点的规律,一般来说,节点的邻居越多,影响力越大。现实网络中节点的局部结构非常复杂,单独用某一种复杂网络指标无法准确地刻画节点周围的结构信息。如图1a~1d 中,节点A、B、C、D具有不同的局部结构,相应的中心节点的影响力也有差异,使用传统的中心性方法无法准确区分这4 个节点的真实重要性。如采用度中心计算时,A、B、C、D属于同一类型节点(dA=dB=dC=dD=2)。而Hindex 无法判断节点A、C、D(hA=hC=hD=2)。另外K-shell 中心性也无法判断A、B和C、D(kA=kB=1,kC=kD=2)。可以看出,传统方法在节点重要性分析中还属于粗粒度方法,对于不同的微观局部结构有时很难区分。
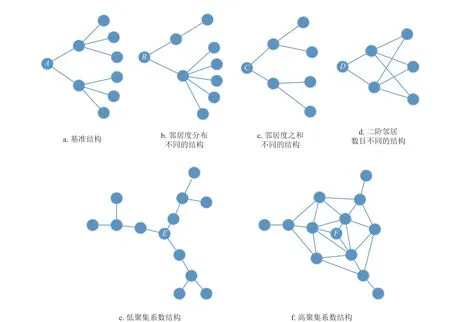
图1 复杂网络中节点的局部结构示例
1.1 特征提取
由于传统的基于中心性的方法不能很好地刻画节点的局部结构,特别是对于二阶邻居结构信息的刻画过于粗糙。因此本文主要以节点的邻居信息为基础,提取和重组能刻画节点局部结构的特征。
课堂中的所有元素都应该相互协同合作的,教师和学生作为课堂中的两个参与者,师生之间的互动交流是不可缺少的。纵观当前的高中英语课堂,教学氛围比较压抑,师生之间的交流不多,一般总是教师单方面的滔滔不绝的讲述,学生没有参与其中,只是被动的接受知识灌输,实际上只有在师生之间友好交流的过程中,才能带动学生参与学习,达到高效教学的效果,同时也增进了师生感情。因此,教师应该注重搭建师生互动平台,在教学中要设计更多师生之间交流反馈的机会,比如可以开展小组合作学习,让学生自主讨论出一篇课文中比较难以理解的词汇释义或者句型语法,然后教师再引导他们进行解决,这有助于锻炼学生的感知力和表达能力,真正实现师生协调发展。
1.1.1 一阶邻居特征
从一阶邻居开始,一般而言,度越大,信息越有可能传播出去,因此,节点的度是刻画信息传播能力的一个重要特征。除此以外,一阶邻居度的分布一定程度上反映了节点二阶邻居的结构信息。如图1 中,虽然节点A、B、C、D的度都为2,但是它们的一阶邻居度分布相差却很大。特别地,A的一阶邻居度分布为[4,4],而B的分布是[2,6]。显然,A的一阶邻居度的分布更加均衡,而B的邻居度分配不均衡。由于这两个一阶邻居度的分布对应的局部结构不同,导致节点的影响力也不同。在低感染率下,邻居度分布越均匀,信息往外传播能力越强。若度分布极度不均衡,在图1b 中,若度为6的节点没有被感染,B节点的传播能力会大打折扣。
为了描述邻居度的分布均衡性,本文引入国际通用的,用以衡量一个国家或地区居民收入差距的常用指标:基尼系数(Gini coefficient),基尼系数最大为1,最小等于0。系数越大说明该分布越不均匀,系数越接近0 表明收入分配越是趋向平等。对给定的序列x=[x1,x2,···,xn],该序列数据平均值为 µ,可采用下式直接计算序列的基尼系数:
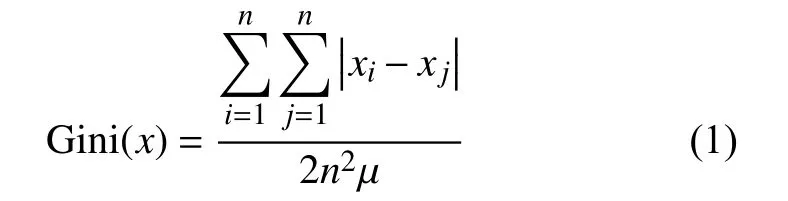
如图1 所示,B的一阶邻居度的差距很大,而A的一阶邻居相对平衡。给定节点u,其一阶邻居为 Γ1(u), 一阶邻居度的集合为D1(u)={dv|v∈Γ1(u)}。为了刻画节点u的一阶邻居度分布的平衡度,定义节点u的一阶邻居度的基尼系数:

然而,只有基尼系数还不能完全反映节点一阶邻居局部结构。如图1 中A和C,一阶邻居的基尼系数都为0 且中心节点的度都为2,仅靠这两个特征还不能很好区分相同度节点重要性的差异,有时小度节点甚至比大度节点具有更高的传播影响力。为了体现这种差异性,引入特征2 区分这种情况,特征2 为一阶邻居度之和,定义如下:
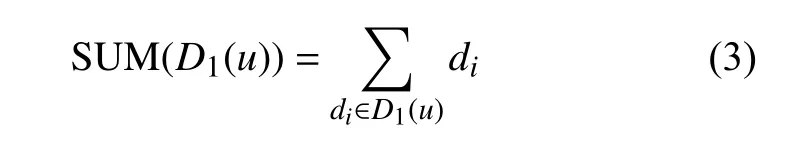
1.1.2 二阶邻居特征
有时仅用一阶邻居的特征还不能很好地刻画节点周围的局部特征,如图1 中的节点A和D,Gini(D1(A))=Gini(D1(D))=0 且 SUM(D1(A))= SUM(D1(D))=0,仅从这两个角度还是无法区别A、D两种局部结构。针对上述情况,本文将二阶邻居数目作为特征,记为 Len(Γ2(u)), 其中 Len(Γ2(A))=6,Len(Γ2(D))=3。
在对一阶邻居的规模和分布进行分析后,将基尼系数和规模作为二阶邻居的特征。但与一阶邻居不同的是,一阶邻居与二阶邻居会出现重叠邻居的情况。如图1f 中的F节点,其周围很多一阶邻居之间存在连接。在获取二阶邻居时,很多一阶邻居还会被判定为二阶邻居。重叠的邻居越多,节点聚集系数越大,节点的影响力在局部区域内能充分地传播,但这种结构会导致信息很难再往外传播[22]。如图1 所示,在邻居节点数目一致的情况下,E节点往外传播的能力大于F节点。因此中心节点的二阶外联邻居Γ ˜2(u)度的分布和规模反映了信息从中心节点向外传播的能力。基于此,本文提取二阶外联邻居度的基尼系数和SUM 值作为节点的局部结构特征。

表1 节点局部结构特征度量
至此,本文从局部结构的规模和平衡性两个角度,针对一阶、二阶邻居,提取了共8 个特征,具体计算方法和描述总结在表1 中。除上述特征外,还有其他类型的特征对排序结果也有影响,如邻居度的最大值、平均值、方差等。这些特征都会对节点重要性判断带来影响,本文仅作为一种算法思路,通过重构二阶邻居内的度信息,得到刻画节点邻居结构最主要的8 个特征用于节点重要性排序。
1.2 节点重要性学习建模
节点的重要性与节点周围的局部结构有着紧密的关系。本文根据表1 列出的特征,采用线性回归(linear regression)模型对节点局部特征与节点重要性关系进行建模。定义一个线性回归函数f:x→s,将节点的结构特征映射为节点的相对重要性,具体可表示为:

式中,w为特征向量的权重向量;x是特征向量;b是误差项。

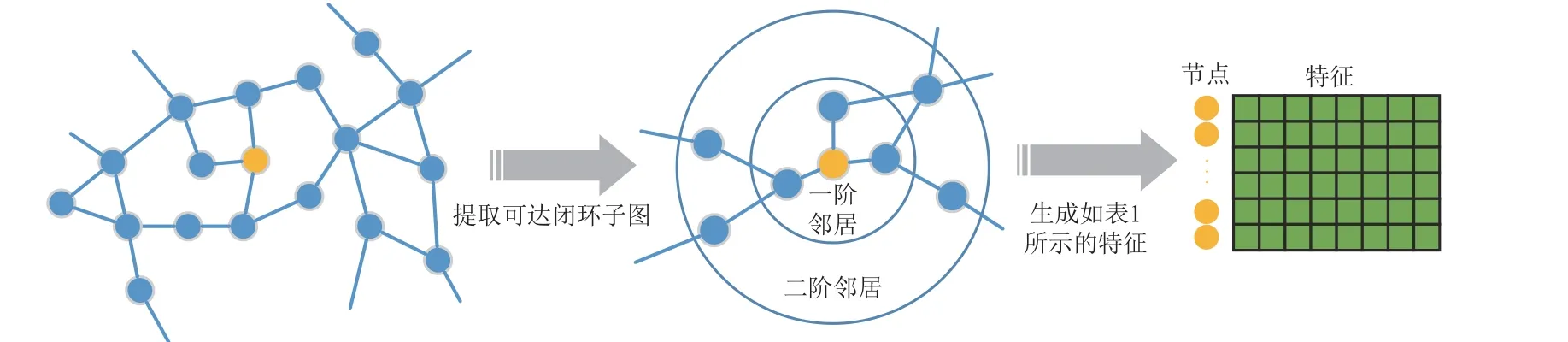
图2 节点局部特征生成示例
至此,在获得了节点v的归一化结构特征xv和真实重要性sv后,采用线性回归模型,选取均方误差(mean squared error, MSE)建立目标函数以学习节点局部结构特征与真实重要性之间的关系:

为了获得模型最优的回归系数,本文采用Adam 优化器[27]优化目标函数。
1.3 模型训练
本文用LastFM[28]作为训练网络对节点重要性挖掘模型进行训练学习。LastFM 是一个2020 年3 月从公共API 收集的社交网络,节点代表亚洲的用户账号,边代表它们之间相互关注的关系,其节点规模为7 624,边数量为27 806,最大度为216。首先从LastFM网络中提取节点的特征向量;同时,以LastFM 网络中每个节点为初始感染节点,进行1 000 次独立的SIR 传播仿真,将1 000次的平均sv作为每个节点的标签;最后,将标签和特征向量作为训练集输入线性回归模型,训练得到节点重要性度量模型,用于预测其他网络中每个节点的重要性。
2 实验与讨论
本文用13 个不同类型的真实网络对本文提出的方法进行测试,并和度中心性、介数中心性、Kshell 中心性、H-index 中心性和DynamicRank 中心性进行对比。
2.1 评估指标


2.2 数据集

表2 13 个真实网络的基本特征数据
本文采用的13 个真实网络中,包括了规模较小的网络(如Jazz),也有规模较大的网络(如Cond-Mat, CM),其平均度的范围为2~35。其中,1) Jazz 是爵士乐手之间的协作网络,每条边表示两个乐手在一个乐队中一起演奏;2) NetScience(NS)是发表关于复杂网络主题论文的科学家之间的合作者网络;3) Email 是Rovirai Virgili 大学成员之间的电子邮件交换网络;4) Sex 是研究男女性伙伴的网络;5) Polblog 是2004 年美国大选中博客之间的超链接形成的网络;6) USAir 是2010 年美国机场之间的航空网络;7) Router 是由Rocketfuel 项目收集的互联网路由器拓扑网络;8) Cond-Mat(CM)是1995 年-1999 年arXiv 出版物的科学家合作网络;9) Grid 是美国西部的某电力网络;10) Figeys、Stelzl 和Vidal是3 个蛋白质-蛋白质相互作用网络;11) Hamster是一个包含网站用户之间的友谊和家庭关系的网络。以上数据集可从网站(http://konect.cc/networks/)获得,这13 个真实网络的详细特征如表2 所示,其中,n是节点数目,m是边数目,表示所有节点的平均度,kmax代表节点的最大度,所有节点的平均聚集系数为。
2.3 实验及分析
为了检测模型预测的准确性,本文首先对测试网络中每个节点作1 000 次SIR 传播仿真,将1 000次的平均sv作为测试网络节点的真实影响力。再根据节点影响力的预测值和真实值的Kendall Tau 系数评价模型的预测效果。本文方法和其他基准方法的对比结果如表3 所示。
从表3 可以看出,本文提出的方法在大部分网络中表现非常好,13 个网络中有10 个网络都好于对比方法,尤其在NS 网络中,相比于表现第二好的DynamicRank 中心性方法,相关系数提升了0.2456。在平均度比较高(平均度大于20)的网络中,由于训练集中缺少类似的大度点的局部结构,无法学习到大度节点的重要性,极大影响了模型的判断,如在Polblog 网络中,最大度为467,远高于训练网络的最大度216。另一方面,平均度反映网络中常见的局部结构。如训练网络LastFM 的平均度为7.294,虽然也存在度为20 的局部结构,但这种结构在训练网络中并不常见,转换得到的训练集会极不平衡。模型对度为20 的局部结构无法充分学习,因此模型在度大于20 的网络表现也就较差。
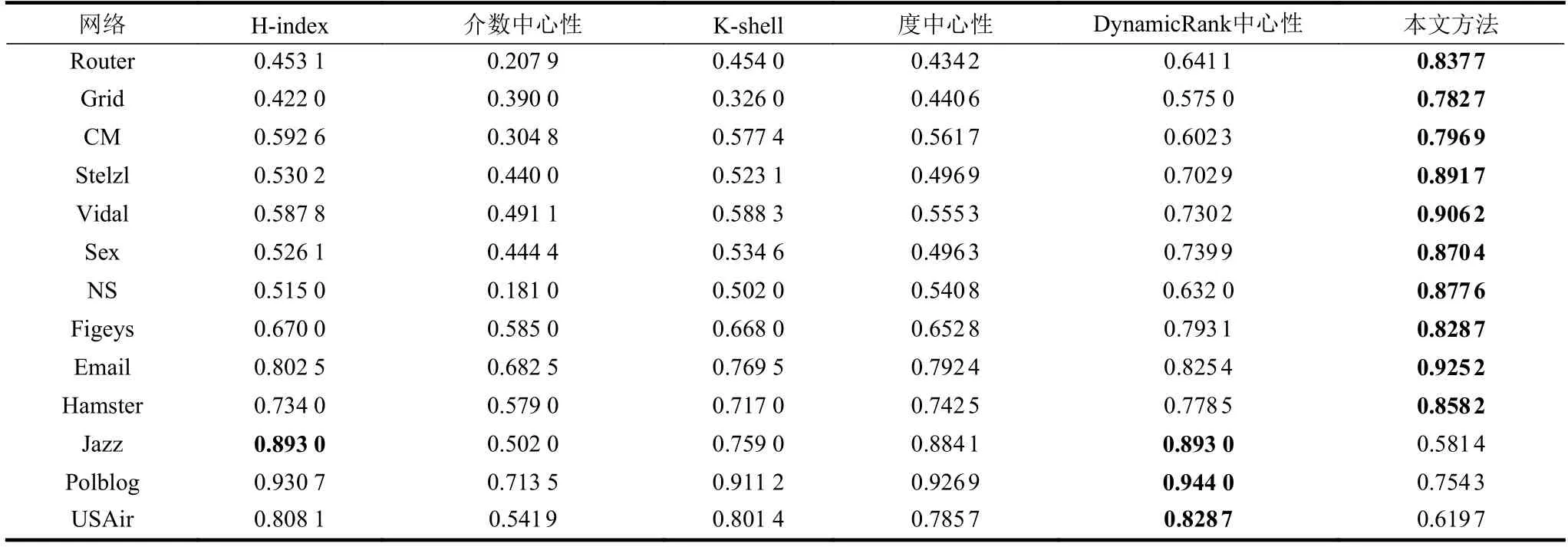
表3 不同方法与SIR 模型仿真结果的Kendall Tau 相关性系数
为了验证本文学习模型的鲁棒性,本文在不同感染概率下对模型效果进行了分析。设置 β=cβc,选取不同c值用于分析选取不同传染概率对重要节点挖掘的影响。
如图3 所示,在不同感染概率β=βc、1.5βc、2βc、2.5βc下,本文利用特征工程的方法提出的特征能够很好地描述节点在网络中的重要性。在不同的感染概率下,本文方法依旧能在低平均度的网络中取得最好的效果。图3 的结果表明,虽然基于特征工程的方法在训练时依赖于感染概率,但训练得到的重要性评估模型对感染概率并不敏感,适用于对不同感染概率下,节点重要性的挖掘。
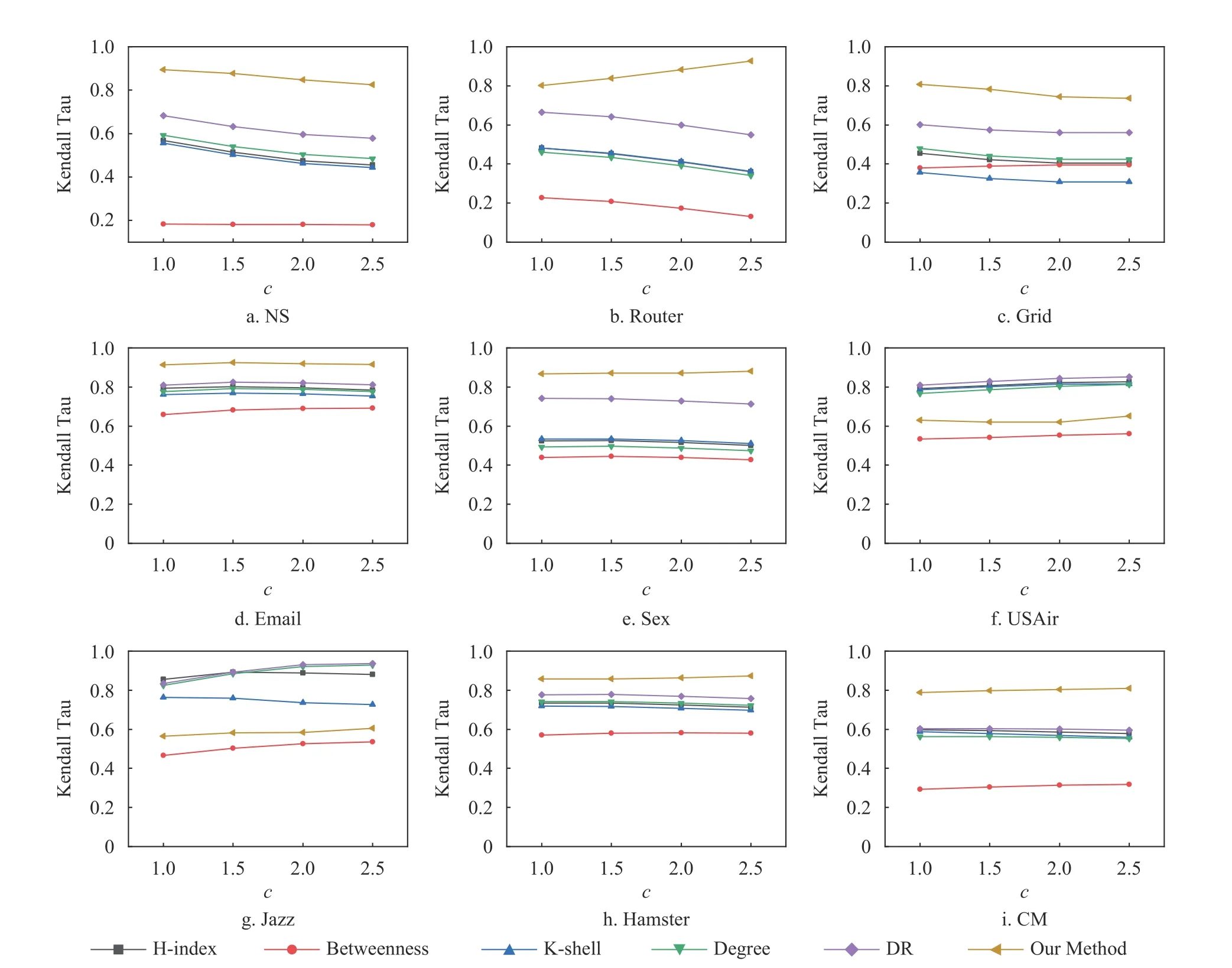
图3 本文方法与其他基准方法在各网络中不同感染概率下的Kendall Tau 相关性系数对比
进一步,为了验证这8 个特征的有效性,本文在不同网络上选取不同特征组合进行实验分析。
1) 在Figeys 网络中去除特征1 后,算法排序结果和实际仿真排序结果的Kendall Tau 相关性系数从0.83 下降到0.77。
2) 在NS 网络中去除特征1 后,Kendall Tau 相关性系数从0.879 下降至0.872,若去除特征2,Kendall Tau 相关性系数下降更为明显,降至0.861。
3) 若在Grid 网络中去除特征2,Kendall Tau相关性系数从0.775 下降至0.728。若再进一步去除特征7,Kendall Tau 相关性系数大幅降低至0.688。
4) 在Stelzl 网络中,若同时去除特征3 和7 时,Kendall Tau 相关性系数从0.89 大幅下降至0.79。
从上面的分析可以看出,8 个特征在不同网络的重要节点排序上相互补充和促进,去掉某个或某组特征,对节点重要性研判将带来直接影响。而完整的8 个特征,模型更稳定,也能更准确地判断网络中节点的重要性。
同时,根据信息传播理论,节点对三阶邻居以外的影响已经很小,更高阶的邻居信息趋于同质化[30]。为了验证更高阶邻居对模型的影响,根据特征4-8,拓展三阶邻居的特征9-13(三阶邻居的度之和、三阶邻居数目、三阶邻居度的基尼系数、三阶外联邻居度之和、三阶外联邻居度的基尼系数)。选取email 作为测试网络,发现8 个特征训练所得模型的排序结果与仿真结果的Kendall Tau 相关性系数为0.925,而13 个特征的相关系数为0.927,提升并不明显。实验表明,选取二阶邻居以内的信息已足够。
3 结 束 语
本文利用特征工程方法对节点的邻居信息进行提取和重构,提取更能反映节点局部结构的特征向量。根据节点的局部结构特征信息,建立了用于挖掘网络中重要节点的机器学习模型。用13 个实际网络对本文所提方法的有效性进行了测试,并和典型的基准方法进行了对比。实验结果表明,本文提出的机器学习模型能有效地挖掘网络中的重要节点,13 个网络中有10 个网络的效果显著地优于已有方法。由于本文方法一定程度上依赖于训练网络的局部结构,对于训练数据中出现较少的局部结构,由于训练不充分,在测试时表现出的效果整体欠佳。在未来的研究中,一方面是构建更加丰富多样的训练集,另一方面,需提取更为丰富的局部特征,提升模型的预测能力。近年来,随着深度学习的发展,尤其是图神经网络的研究深入,如何利用图神经网络训练泛化性能更好的复杂网络局部结构特征的表达模型[31],从而提高重要节点识别的准确率也是一个重要的研究方向。
