一种基于注意力机制的细粒度图像分类方法
2021-12-02郑承宇邓亚萍尹甜甜
王 婷,王 新,郑承宇,邓亚萍,尹甜甜
(云南民族大学 数学与计算机科学学院,云南 昆明 650500)
细粒度图像分类(FGVC)作为当前研究的热点,与常规的粗粒度图像分类相比,为人们提供了更加详细的图像信息,并可以区分图像中的各基本级别的类别.例如,鸟类和车辆之间存在细微的视觉差异[1-2],在区分图像中鸟和车的同时,还能分别出鸟类和车辆的特定种类和类别.由于传统的图像分类方法无法产生良好的分类效果,研究人员开始将深度学习技术引入到图像分类、识别任务中[3].
目前关于细粒度图像分类的研究已取得一些成果.例如,Huang等[4]提出1种基于多视角融合的分类方法,其主要包括使用特征图从图像中挖掘出细粒度特征和分析图像的全局特征的2个分支,最后合并2个分支;Wei等[5]提出在对物体进行检测时引入深度卷积特征的方法,应用到细粒度图像中,通过图像的注释定位目标和图像中其他可识别的地方;Lin等[6]提出了一种包含2个VGG网络的B-CNN网络,将其分别用于检测图像的目标区域和提取目标区域的特征,最后将获取的特征进行双线性融合.不同而又细微的细节特征在细粒度图像分类中起着重要作用,因此,学会区分细节的注意力机制逐渐成为最受欢迎和最有前途的研究方向,研究者们提出了各种注意力机制.例如,文献[7]中提出了一种动态反复视觉注意计算时间的DT-RAM模型,该模型能够参与动态测量中最具有区别的部分.Fu等[8]提出一种使用注意力网络在不同尺度的图像上生成区域性注意力的RA-CNN网络,此模型主要使用多尺度网络逐步找到主要目标,利用分类损失优化网络,从而找出准确的区域.Heliang Zheng等[9]提出了MA-CNN模型,此模型能够产生多个设计通道模块,并且能够实现单尺度一致的注意映射.Heliang Zheng等[10]提出了TASN模型,该模型以一种高分辨率的师生方式从数百个建议中学习图像的细粒度特征,最后表现出来的分类性能优于上述模型.
上述的分类模型在细粒度图像的分类的任务中虽已取得较好的分类效果,但是在实验过程中缺少对模型的鲁棒性和泛化能力的验证.为了解决此问题,本文针对TASN模型进行研究,对此模型注入dropout,随机深度2种噪声,并在输入实验数据之前,利用Rand Augment的数据增强对实验数据进行加噪,并把增强后的图像反馈回加噪后的模型,从而来验证模型的泛化能力和鲁棒性.
1 基于注意力机制的细粒度图像分类
1.1 注意力机制
因人类认知过程中,大脑会有选择的关注所得信息更有价值部分,忽略低价值的信息,这样会给识别的结果产生干扰.当计算机无法模拟人类的注意力状态时,可能会对低价值的信息进行处理从而扰乱最终结果,也正因此,我们需要通过训练,使计算机学会注意力机制.在经过训练后,注意力模块通过不同的神经网络结构以预测主体的位置,即从输入图像中剪裁更精细的图像,让模型对精细化图像的进行更精准的分类,从而达到提升分类的性能目的.具体的测试流程图如图1所示.
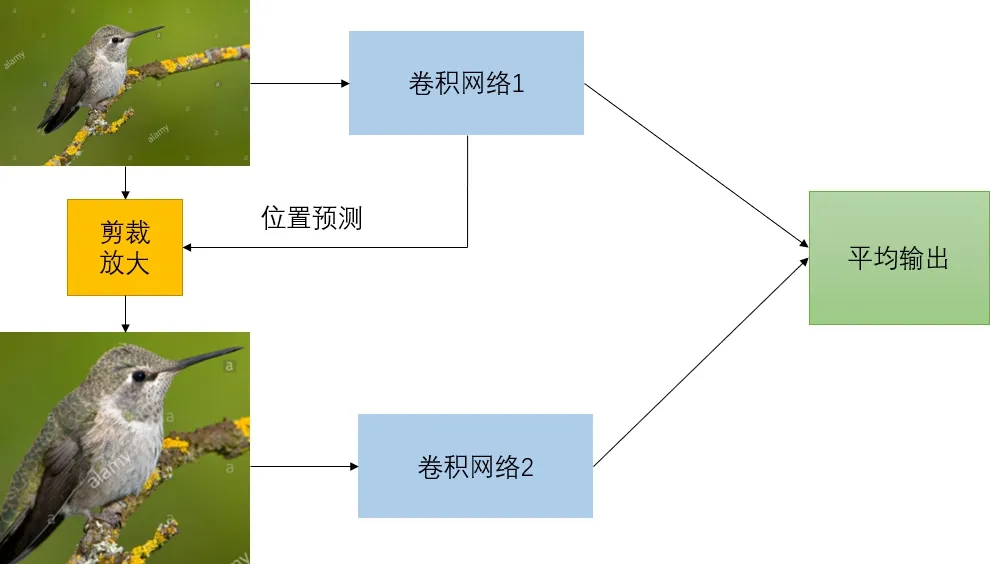
图1 注意力机制测试流程图
1.2 三线性注意力抽样网络
三线性注意力抽样网络(TASN)是以注意力机制为基础,基准网络为Resnet-18的抽样网络,其主要功能是以一种高效的方式,从多个注释的特征中学习图像细粒度特征.网络的具体结构如图2所示.
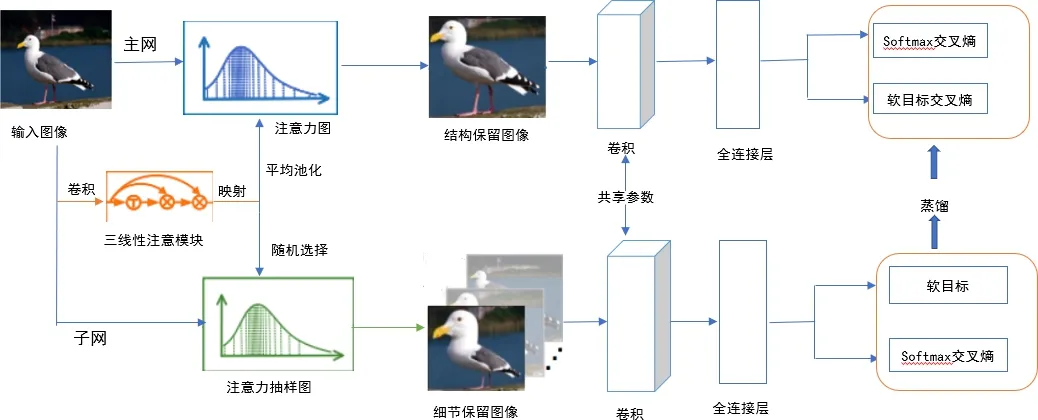
图2 三线性注意力抽样网络结构
该网络主要有3大模块,即注意力模块、注意力采样器模块及蒸馏器模块.其中三线性注意力模块主要以特征映射作为输入.为了提取图像中更多的细节特征,三线性注意力模块通过三线性积生成注意力映射,使特征通道与其关系矩阵相结合,然后将每个通道的特征图转化成一个注意力.注意力采样器以注意力图作为输入图像,最后将从保留细节的图像中学习到的细粒度特征利用蒸馏器提取到主网中.主网只要以结构保留图像作为输入,通过部分网的指导细化图像特定的部分.三线性注意模块首先将c×h×w维的特征图转化为c×hw维的矩阵.三线性函数如下公式(1)所示:
Mb(X):=(XXT)X.
(1)
其中:X∈Rc×hw,XXT是一个双线性的特征,表示的是通道之间的空间关系.为提高三线性注意力的有效性,对输入的图像做归一化处理,归一化的公式可表示为
M(X):=N(N(X)XT)X.
(2)
其中:N(.)表示对矩阵的第二阶进行softmax函数归一化,N(X)表示空间归一化,N(N(X)XT)X表示关系归一化,它在每一个关系向量上进行.注意力采样器在对图像进行细粒度提取的过程中,对不同的注意力图统一抽样处理,统一抽样公式为:
IS=S(I,A(M)),Id=S(I,R(M)).
(3)
其中:M为注意力图,S(.)表示非均匀采样函数,A(.)表示平均池化通道,R(.)表示从输入中随机选择通道.最后将结构保留图像和细节保留图像送到相同CNN中,以此获得全连接的输出.将全连接输入记为Zs和Zd,采用softmax函数将其转换为概率向量qs和qd,如下所示:
(4)
其中T为参数,在知识蒸馏中,T的值通常会设置比较大.主网软目标交叉熵为:
(5)
最后三线性注意力抽样网络的损失函数如下所示:
L(IS)=Lcls(qs,y)+λLsoft(qs,qd) .
(6)
1.3 Resnet网络
Resnet最初由何凯明团队提出,开启了人们学习残差网络的热潮,解决了在浅层次的网络结构中建立深层网络不仅不能取得较高的准确率,反而引起了网络性能下降的问题.作为基于注意力机制的三线性注意力抽样网络的基准网络,其原理是在输入和输出之间增加了一种短链接,迫使网络适应残差映射.于之前的网络结构相比,此方法更加容易训练.设所有的映射为H(X),残差连接让堆叠的非线性层来拟合另一个映射:
F(X)=H(X)-X.
(7)
原来的映射为:
H(X)=F(X)+X.
(8)
参差网的基本结构图如图3所示;
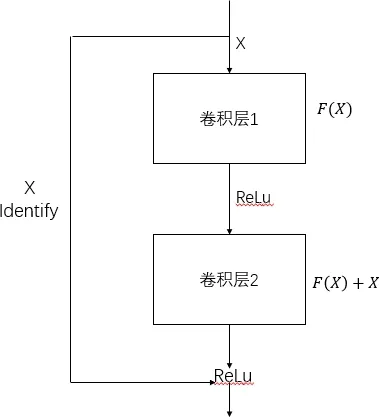
图3 残差模块的基本结构
残差网结构具体形式如图4所示:
xl+1=xl+F(xl,Wl).
(9)
通过递归,可以得到任意深层单元L特征的表示:
(10)
2 基于改进的注意力机制的细粒度图像分类方法
2.1 模型框架
三线性注意力抽样网络在细粒度图像分类中已取得较好的分类效果,但模型的鲁棒性和泛化能力在训练的过程没有得到很好的体现.为了进一步提高三线性注意力抽样网络模型的鲁棒性及泛化能力,提出一种改进的三线性注意力抽样网络.该模型在原始三线性注意力抽样网络基础上引入一种新颖的图像增强方法,并引入随机深度和Dropout层添加噪声,进而完成细粒度图像分类.改进的模型框架如图4所示.
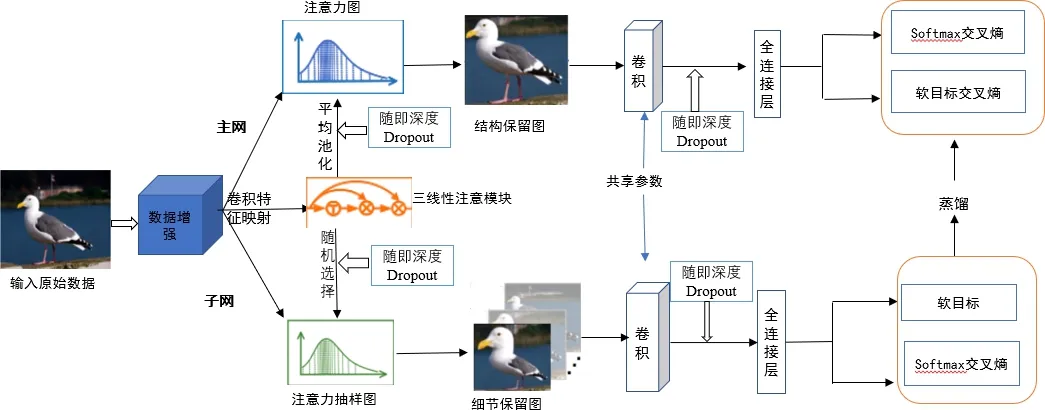
图4 基于注意力的三线性注意力抽样网络
基于改进的注意力机制的细粒度图像分类方法的主要步骤为:
1) 在原始输入图像中进行数据增强处理(数据增强的方式主要有旋转、翻转、变形、缩放以及扩充等);
2) 以三线性注意力模块作为输入的特征映射,将增强后的图像转化为注意力图,此步骤会提取出图像中的成百上千个细节特征,在平均池化的过程中,对其注入随机深度和Dropout;
3) 采样器将注意力图作为输入,并随机选择图像生成细节保留的图像和结构保留的图像;
4) 将部分网中学习到的细粒度特征通过蒸馏器提取到主网中,蒸馏器是通过权重共享和特征保留来实现其操作,在主网和部分网中的卷积到全连接层也注入了随机深度和Dropout.通过以上4个步骤以完成细粒度图像分类任务;
2.2 图像增强(AUG)
本文提出一种改进的三线性注意力抽样网络,为增加网络的泛化能力,在将原始图像输入网络之前,对输入图像进行归一化操作,其计算公式如式(11)所示.
(11)
原始数据标准化处理后得到注意力图像Ak,再对图像进行图像增强操作,进一步提高网络的泛化能力,数据增强的主要过程如图5所示.
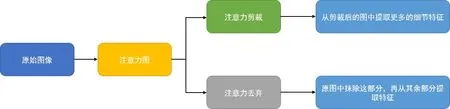
图5 图像增强过程
其中图像中局部区域Ck和Dk的计算公式分别如式(12)、式(13)所示.
(12)
其中,θc∈[0,1].
(13)
其中,θd∈[0,1]
2.3 随机深度网络(SD)
为了提升收敛性,将随机深度网络引入到三线注意力机制网络.随机深度网络主要是指在Restnet训练时优化算法的速度和性能,原始Resnet结构和具有随机深度的Resnet结构分别如式(14)和(15)所示:
Hl=ReLU(fl(Hl-1)+id(Hl-1)).
(14)
Hl=ReLU(blfl(Hl-1)+id(Hl-1)).
(15)
其中:f代表残差部分,id代表恒等映射.然后将两部分进行求和,再经过激活最后输出.随机深度网络就是在训练时加入一个随机变量b,然后将f乘以b.
2.4 Dropout层
Dropout层是指在训练深度学习网络的过程中根据一定的概率对神经网络单元进行丢弃,但是在网络训练时,总会遇到诸如过拟合和费时等问题,Dropout的功能主要是减少实验过程中过拟合的发生,整个Dropout过程相当于平均许多不同的神经网络取.一些互为“反向”的拟合会相互抵消,以减少整体过拟合,并且在一定程度上降低神经元之间复杂的共适应关系和正则化的影响.采用Dropout网络计算公式如下(16)至(19)所示:
(16)
(17)
(18)
(19)
其中:Bernoulli函数是生成概率向量r,即随机生成0、1向量;*是元素级乘法,对任意层l,r(l)是独立Bernoulli随机变量,每个变量的概率p为1.此操作等效于对大型网络的子网络进行采样,并且在反向传播的情况下,它是当前子网络的反向传播.
3 实验数据与结果分析
3.1 实验数据
选取了3个公开的细粒度图像分类数据库,分别是CUB-200-2011数据库[11]、Stanford cars数据库[12]以及iNaturalist-217数据库[13]进行实验.其中CUB-200-2011由加州理工学院创建,具有200种鸟类,共拍摄了 11 788 张图片,其中训练集中有共 5 799 张图片,测试集中有 5 999 张图片.Stanford cars数据库由斯坦福大学团队创建的有关汽车模型的细粒度图像数据集,它总共包含196种常见的车型,共有 16 185 张图片,训练集中有 8 144 张图片,测试集中 8 041 张图片.iNaturalist-2017数据库共有 675 170 张图,其中训练集有 579 184 张,测试集有 675 170 张图像.数据集的统计信息如表1所示.

表1 数据集信息统计表
3.2 实验平台及实验参数
本实验采用的实验平台与配置如表2所示,实验具体参数如表3所示.

表2 实验平台与环境

表3 实验参数
3.3 实验结果分析
将本文方法与当前的细粒度图像分类模型进行比较,对比结果于表4~表6所示.在文中,将公式(20)定义的精度作为评估指标,Pi代表正确分类为类别i的物种的数量,numi代表第i类图像的数量,N代表所有图像类别的数量.

表4 数据集CUB-200-2011的细粒度分类结果对比

表5 数据集stanford cars的细粒度分类结果对比

表6 数据集iNaturalist-2017的细粒度分类结果对比
(20)
为进一步增强结果的可靠性,实验过程未采用额外的数据集,也未进行人工标注以及层次标签.由表4可见,对于数据集CUB-200-2011,文中方法相较于RA-CNN准确率提高了2.7%,相较于MA-CNN准确率提高了2%,相较于三线注意力抽样网络的准确率提高了0.1%.
由表6可见,对于数据集iNaturalist-2017,本文方法的准确率比RA-CNN提高了2.9%,比MA-CNN提高了2.5%,比三线注意力抽样网络提高了0.5%.
由此可见,通过数据增强增加噪声以及提高模型鲁棒性的方式,可有效提高细粒度分类准确度.
3.4 消融实验
讨论各种噪声的作用情况,研究噪声在具有同一数量的数据和不同状态下的模型的分类准确度.分别采用TASN、TASN+Aug、TASN+SD、TASN+Dropout及TASN+Aug+SD+Dropout等不同模型训练图像数据,实验使用的数据集均为CUB-200-2011.实验结果如表7所示.
由表7可见,噪声如随机深度、dropout和数据增强等在训练模型TASN网络的过程中发挥了重要作用.其中,分别在TASN中增加数据增强、随机深度及Dropout,其准确率相较于TASN模型增加0.04%~0.05%,但三者之间的准确率相差不大,分别为87.93%、87.94%、87.93%;在同时对TASN模型加入数据增强、随机深度、Dropout后,其准确率相较于TASN增加0.13%,相较于只增加数据增强、随机深度或Dropout,准确率提高了0.08%~0.09%.由此可见,采取多种方式增加噪声,可明显增加结果的准确度.
4 结语
随着对计算机视觉中应用的不断研究,细粒度图像分类被越来越的人关注.文中基于注意力机制条件,对三线性注意力抽样网络提出改进,使网络具有更加显著的鲁棒性和泛化能力,从而减少了外界环境改变对分类结果的影响.具体方法是通过在网络中注入随机深度、Dropout两个噪声,且在实验之前,采用数据增强对原始图像进行预处理.本文所提出的改进网络表现出较强的容错率,减少了外界环境的改变对分类结果造成的影响,提高分类准确度的效果.
