基于Copula函数与等概率逆变换的风电出力场景生成方法
2021-12-01唐锦张书怡吴秋伟陈健李文博周前潘博
唐锦,张书怡,吴秋伟,陈健,李文博,周前,潘博
(1.国网江苏省电力有限公司电力科学研究院,江苏 南京 211103;2.山东大学电气工程学院,山东 济南 250061;3.丹麦科技大学电气工程系,丹麦 灵比 2800;4.嘉兴国电通新能源科技有限公司,浙江 嘉兴 314000)
0 引言
在能源危机与环境问题恶化的双重压力下,风电装机容量迅速增加,并网规模逐步扩大[1—3]。风电输出功率受风速、季节、区域等影响具有随机性、波动性和间歇性[4],因此输出功率的平稳性、可控性较差,给电网安全运行带来挑战[5—7],常规确定性优化问题已不再适用。通过场景法对风电不确定性进行研究建模,应用多个场景表征不确定性变量可得到确定化问题[8],具有广泛应用前景。
场景生成方面,文献[9]构建场景树描述风电功率的不确定性,但阶段数增加时会受到维数限制。文献[10]对风速的概率分布进行拉丁超立方采样,生成初始场景,但该采样为单周期采样技术,无法正确表征风电的时间相关性。文献[11—12]采用蒙特卡洛抽样法生成调度模型中的风电预测场景,但是由于风功率转换不准确,使用风速生成风电场景会出现显著误差。目前大多基于多元变量的联合分布函数或Copula函数研究风电出力相关性。文献[13—14]采用基于Copula函数的场景生成方法,模拟多风电场出力相关性。文献[15]通过多元正态分布函数对单一风电场的时间相关性进行研究。文献[16]结合实测风速对各风电场的联合Copula分布进行相关性研究。现阶段,仅考虑时间或空间相关性的研究较为广泛且容易实现,但是未能综合考虑时空相关性的场景在实际应用中会有偏差。为更好地解决含风电系统的优化运行问题,文献[8]在考虑时间相关性的场景中应用条件分布描述空间相关性,应用范围存在一定约束。文献[17]构建多风电场空间相关Copula模型后,重构场景使其与基准序列误差最小,此方法下相邻时刻风电出力情况最为相似,但与实际风电波动存在差异。少数场景难以覆盖风电的各种潜在可能,而大量场景间相似度大,计算冗余。文献[18]对风、光概率分布抽样后,采用后向削减法得到典型场景,文献[19]应用同步回代消除法,文献[15]采用K-means聚类方法,但上述方法均需人为确定最终场景数目,不能得到代表性场景。文献[20]应用聚类有效性指标平衡类间与类内距离,但未考虑聚类结果波动导致的最优聚类数目波动问题。
针对以上问题,文中以多元变量协方差矩阵与Copula函数为依据构建时空相关性模型,通过对累积分布函数(cumulative distribution function,CDF)的非参数模型进行非线性变换与等概率逆变换,完成时空相关性场景生成。应用基于手肘法与聚类有效性指标确定最优聚类数目的改进K-means法确定最终场景集。通过质量评价指标检验所生成场景的有效性。算例分析表明,文中方法能真实反映风电波动情况以及时空相关性,具备有效性与可行性。
1 时空相关性场景生成
1.1 时间相关性分析
由风速表现出的间歇性和波动性可知,风电出力具有的时间相关性表现为相近时刻风电出力相关性大,而相差较远时刻较小。对于风电场景不同时间断面间的相关性研究,构造协方差矩阵Σ:
(1)
式中:NT为风电场景长度。σt1,t2可有效反映任意两时刻风电出力的相关性,用指数函数法构建如下:
(2)
式中:参数ε用来控制t1和t2时刻随机数的相关性强度,且1≤t1,t2≤NT。为研究风电时间相关性与波动情况,得到最优相关性参数ε,计算风电历史数据相邻时刻爬坡情况,具体如图1所示。由图可知,t-位置分布拟合效果最好[21]。
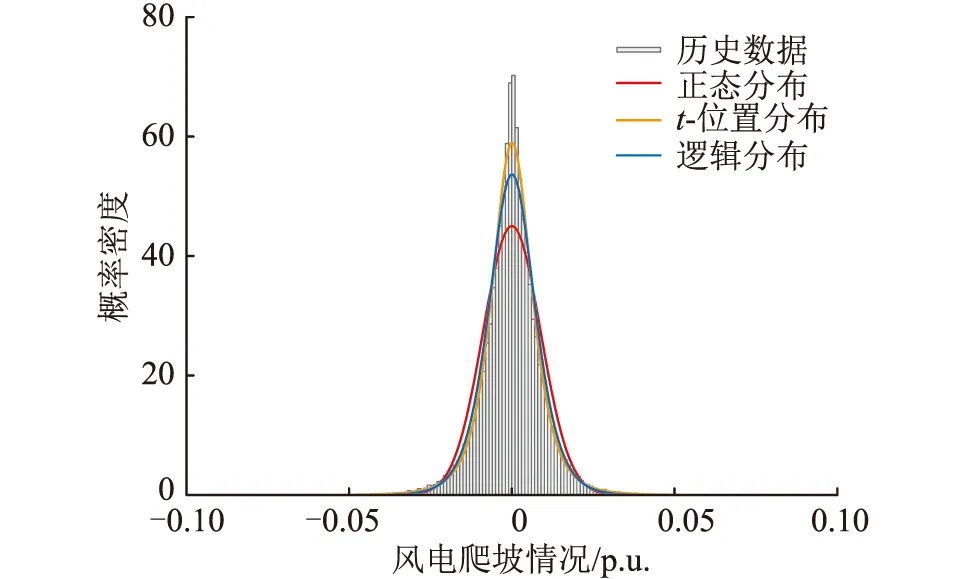
图1 风电爬坡情况拟合曲线Fig.1 Fitting curve of wind power climbing condition
对于不同ε,生成大量场景后,根据拟合t-位置分布函数计算生成场景与历史数据之间的坡度差,如式(3)所示。
(3)
式中:S为采样数目;Ppdf,m(s),Ppdf,ε(s)分别为历史数据和不同ε下所生成场景爬坡情况的t-位置分布概率密度函数值。Iε越小,则可认为生成场景和历史数据的波动情况越接近,ε取值越合理。
1.2 空间相关性分析
由于风速不可突变,一定空间范围内的风电场出力之间必然显现相似性,体现时空相关性。风电场的概率分布不符合常见分布,因此利用非参数估计的方法确定两风电场CDF分别为U,V[22]。由图2可知,核分布能够较好地拟合该CDF,可用于后续参数估计。
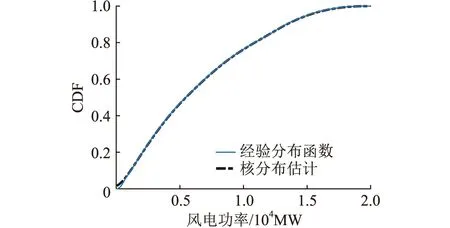
图2 风电场1经验分布函数和核分布估计Fig.2 ECDF and nuclear distribution estimation of wind farm 1
Copula函数可以刻画随机变量间的相关性,将多元随机变量的联合分布函数与其各自的分布函数连接起来[23]。可根据二元频率分布直方图的形状特征,如图3所示,选取恰当的Copula函数结构。

图3 两风电场二元频率分布直方图Fig.3 Binary frequency distribution histogram of two wind farms
可采用同样具有尾部对称性质的二元正态copula或t-Copula进行拟合,其概率密度函数如图4所示。
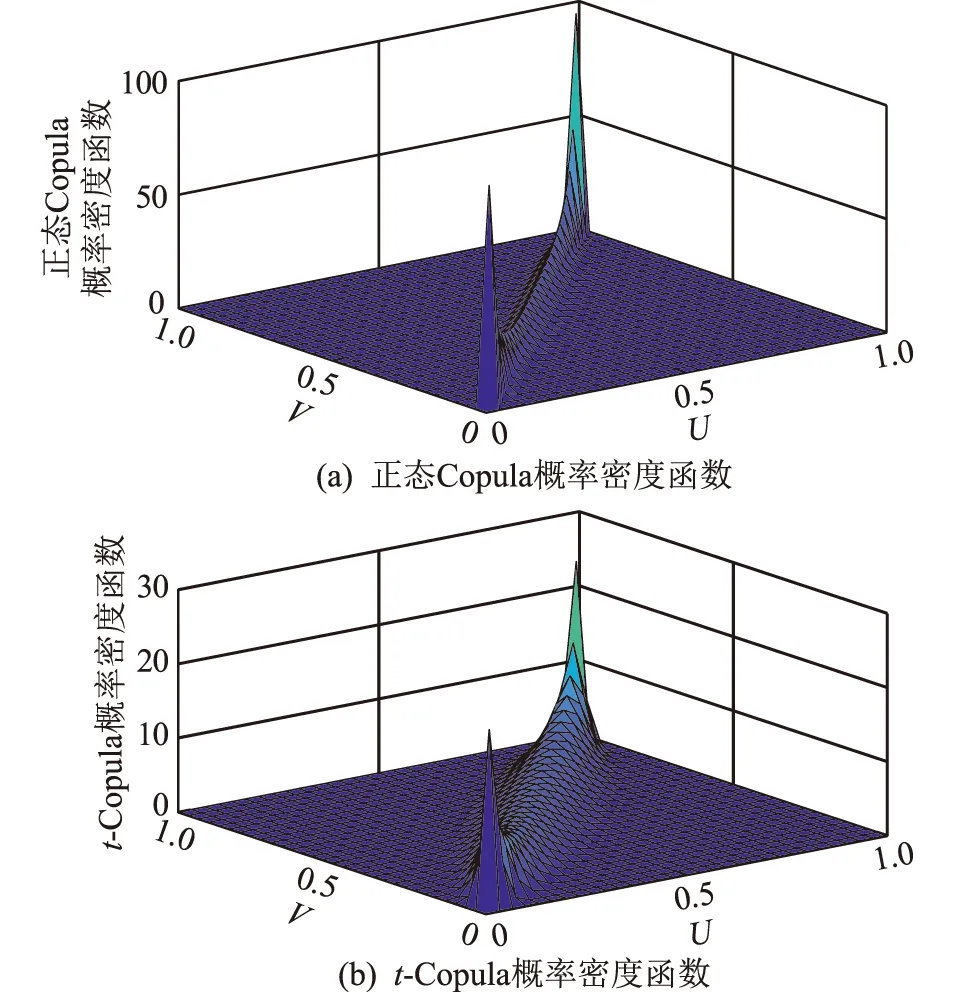
图4 正态Copula与t-Copula概率密度函数Fig.4 Density function diagram of the normal Copula and t-Copula
分别对两Copula函数进行参数估计,得到两模型下的线性相关参数和自由度参数。为评价所选模型,引入经验Copula函数。通过计算两模型与经验函数间的欧式平方距离、比较秩相关系数来选择拟合效果更好的模型。
1.3 场景生成
文中提出了基于数据箱的时空相关性场景生成方法。其核心内容为数据箱划分、各数据箱内CDF的构建、Copula相关性建模和CDF的非线性变换与等概率逆变换。具体步骤如下:
(1)对风电场1构建基于大量历史数据的[实测值,预测值]数据对,进行归一化处理。以0.02为间隔等距划分为50个数据箱。根据预测值大小将数据对划分到数据箱内,并生成各箱内基于实测值的CDF,以应对预测值不准确带来的误差,完成后续基于某日预测值的场景生成。
(2)根据风电场1某日预测风电确定各时刻对应数据箱,以便在预测点附近根据大量历史数据找到更合理的实际出力。风电场2进行同样处理。
(3)利用指数函数法构建风电场1的协方差矩阵。生成大量服从多元标准正态分布的随机变量Z~N(μ,Σ),其中μ为NT维零向量。Σ与最优相关性控制参数ε的确定方法如1.1节所述。在各时刻分别生成随机数的CDF。
(4)根据1.2节选择Copula模型,进行参数估计后生成符合该自由度与线性相关关系的Copula随机数,对应两风电场空间非线性相关关系。
(5)Copula函数可看作符合[0,1]均匀分布的联合累积概率分布函数,因此风电场1正态分布随机数的CDF根据确定的相关性进行非线性变换得到风电场2各时刻随机数的相应CDF。
(6)等概率逆变换,其基本思想为通过历史数据与随机数的CDF将随机数转换为相应出力场景,过程如图5所示。
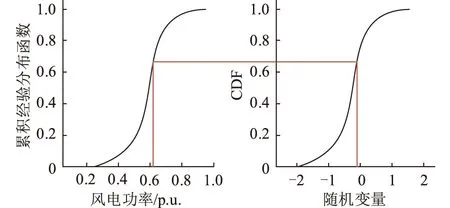
图5 等概率逆变换过程示意Fig.5 Schematic diagram of equal probability inverse transformation
进行等概率逆变换时,分别调用各时刻随机数的CDF与该时刻对应数据箱内的CDF。此方法可保证各时刻均在预测点附近进行采样,逆变换结果降低了预测值不准确导致的场景生成误差。
(7)将逆变换所得出力场景乘以风电最大值,得到两风电场实际出力场景。
2 基于改进K-means聚类的场景缩减
K-means聚类过程按照距离准则将数据集划分到不同类内,使得同一类内元素相似性大,而不同类中元素差异性大,从而将原数据集聚类为少数代表性数据集。由于原始K-means聚类算法具有人为选取聚类数目且初始聚类中心随机的缺点,容易导致算法质量差、陷入局部最优解。因此提出对以上2点进行改进的K-means方法。
2.1 聚类过程
(1)确定K个初始聚类中心。传统方法中随机选择会导致聚类结果波动,无法找到最优聚类数目。改进为下述方法:
①K=1时,以所有场景平均值作为聚类中心即最具代表性,无需后续计算;
②K>1时,首先选择具有最远欧氏距离的2个场景作为初始聚类中心集。对于所有剩余场景,计算与中心集间的欧式距离,选择与集合内场景平均值间距离最远的场景加入到集合中。重复上一步骤,直到初始聚类中心集中有K个场景。以此得到满足不同类别间具有较大差异性要求的初始聚类中心。
(2)为度量两场景间的相似度与差异度,引入距离函数。计算各场景与各聚类中心间的距离,根据距离准则将每个场景归类至与其距离最近的类内。
(4)
式中:dij为场景i与场景j间的欧式距离;λi,t,λj,t分别为t时刻场景i,j的元素。
(3)计算类内场景的平均值,得到新的聚类中心后重新归类,重复上步直到满足收敛条件。
2.2 聚类有效性指标
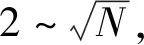
手肘法的核心指标簇内误差平方和(sum of squared error,SSE)为所有样本的聚类误差,定义为:
(5)
式中:xn,k,t为第k类中场景n在t时刻的数值;ck,t为t时刻第k类聚类中心的值;K为聚类数目;Nk为第k类中场景的个数。
其基本思想是样本划分随聚类数目的增多而更精细,因此各类内聚合程度增强,SSE值逐步减小。当聚类数目较小时,增加聚类数目会大幅提升各类内聚合程度,导致SSE值大幅下降。当K接近最优聚类数目时,SSE值下降幅度骤减,随K值的增大而趋于平缓,此拐点即为最优聚类数目。但是普遍采用的目测法难以准确确定拐点,因此引入聚类有效性指标Calinski-Harabasz(CH),其计算如下:
(6)
式中:tr(SW),tr(SB)分别为类内和类间散布矩阵的迹,分别度量类内紧密度和类间分离度[24]。K值增大,tr(SB)上升,tr(SW)下降,CH值在某个K处达到最优,CH值最大时对应最佳聚类结果。
综上,确定最优聚类数目的步骤为:计算搜索范围内各聚类数目下SSE指标与CH指标;在SSE折线图趋于平缓的拐点附近找到具有最大聚类有效性指标CH的聚类数目,即为最优K。
3 场景质量检验方法
若将生成场景应用到日前调度中表征风电不确定性,需验证生成场景是否能反映风电波动特性和相关性特征[25],以及文中方法的有效性。考察方面包括:(1)生成场景是否符合风电的波动性和时间相关性;(2)生成场景是否能够覆盖预测日的实际风电出力情况;(3)生成场景与实际风电是否具有一致的爬坡情况;(4)是否能够正确体现两风电场的空间相关性。检验指标具体表述如下。
(1)生成场景与历史数据在任意时刻间相关性的近似程度PA。
PA=|chis,t,t+n-cs,t,t+n|
(7)
式中:chis,t,t+n,cs,t,t+n分别为历史数据和生成场景s在任意两时刻间的相关系数。PA越小,生成场景越能有效反映波动性和时间相关性。
(2)生成场景对风电实测值的覆盖情况PB。
(8)
Bt为二元变量,预测日当天的风电实测值处于生成场景的最大值与最小值之间时取1,反之为0,即生成场景覆盖了当天的实测值,生成场景有效时为1。PB数值范围为[0,1],计算结果越大,生成场景越能有效考虑到其不确定性。
(3)生成场景的爬坡情况与实际爬坡情况的相似度PC。
(9)
式中:Δactual,t,t+1,Δs,n,t,t+1分别为实际爬坡情况与生成场景s的爬坡情况。PC越小,生成场景的爬坡情况与真实情况越接近、越合理。
(4)生成两风电场场景空间相关性与实际相关性的近似度PD。
PD=|chis,X,Y-cs,X,Y|
(10)
式中:chis,X,Y,cs,X,Y分别为两风电场历史数据与生成场景s的相关性矩阵。差值越小,生成场景与实际情况越相符。
4 场景生成和缩减及质量检验算例分析
文中对某地区两相邻风电场进行场景生成、缩减和场景质量检验,验证所提方法的有效性。以2017年—2019年两风电场出力的实测值与预测值为基础生成CDF,以2017年8月8日数据作为某预测日进行分析计算。
4.1 考虑时空相关性的场景生成结果分析
4.1.1 时间相关性参数分析
为使生成场景具有合理的波动情况,首先确定相关性参数ε。通常认为1≤ε≤300时,可以满足大多数场景对波动性的要求,但最优取值随预测日选取不同而变化[26]。
针对文中预测日,在不同ε取值下拟合误差Iε的变化曲线如图6所示。
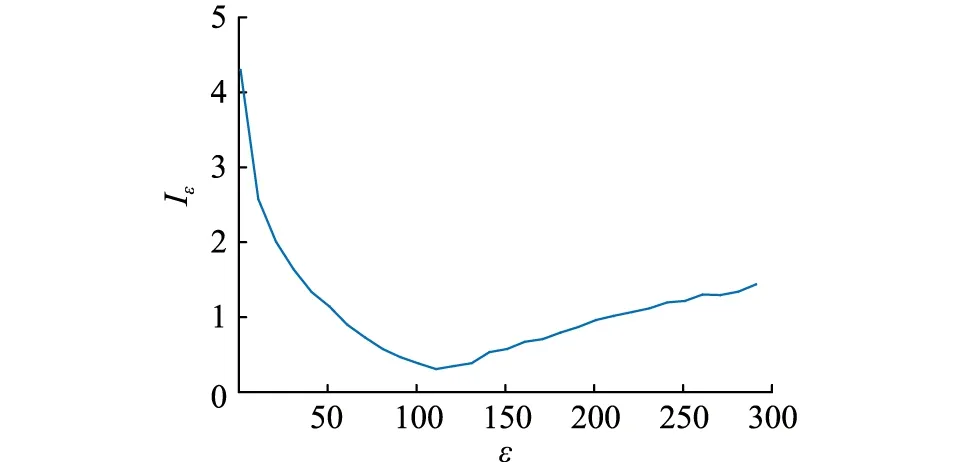
图6 拟合误差随ε变化曲线Fig.6 Curve of fitting error changing with ε
由图可知,当ε=110时,Iε最小,生成场景的波动性与时间相关性最合理。因此相关性控制参数设置为ε=110。
4.1.2 空间相关性参数分析
根据两风电场二元频率直方图,选择同样具有尾部对称性质的正态Copula和t-Copula进行参数拟合,结果如表1所示。
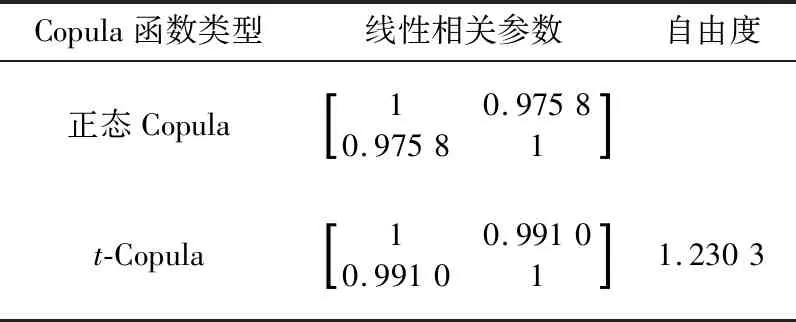
表1 Copula函数参数估计结果Table 1 Parameter estimation results of Copula function
通过计算两模型与经验函数间的欧式平方距离比较正态Copula和t-Copula与原始数据的拟合程度,通过对比Kendall与Spearman相关系数[27]矩阵对比拟合效果,结果如表2所示。
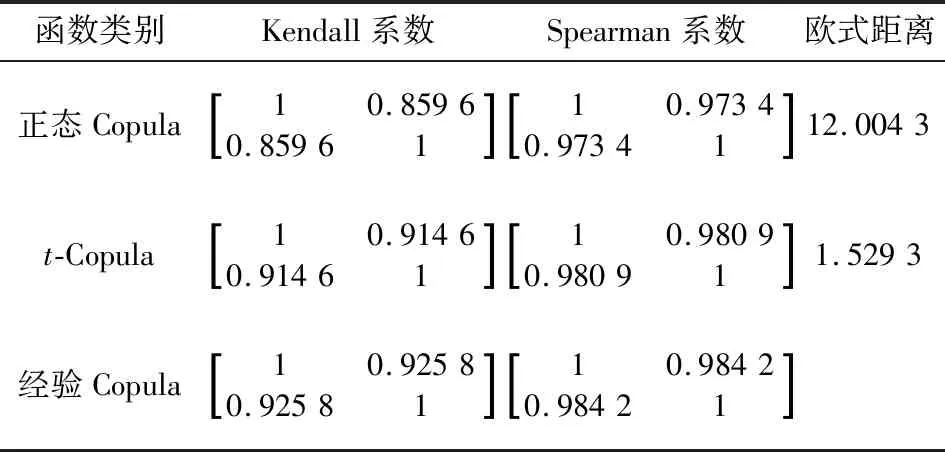
表2 相关性系数及欧氏距离计算结果对比Table 2 Correlation coefficient and calculation results of Euclidean distance comparison
t-Copula的2类相关系数矩阵均与经验Copula更接近,且欧氏距离更小,具有更好的拟合效果。因此选择线性相关参数为0.991 0,自由度为1.230 3的t-Copula函数拟合两风电场的空间相关性。
4.1.3 场景生成结果
应用文中所提考虑时空相关性的场景生成方法生成两风电场场景如图7所示。
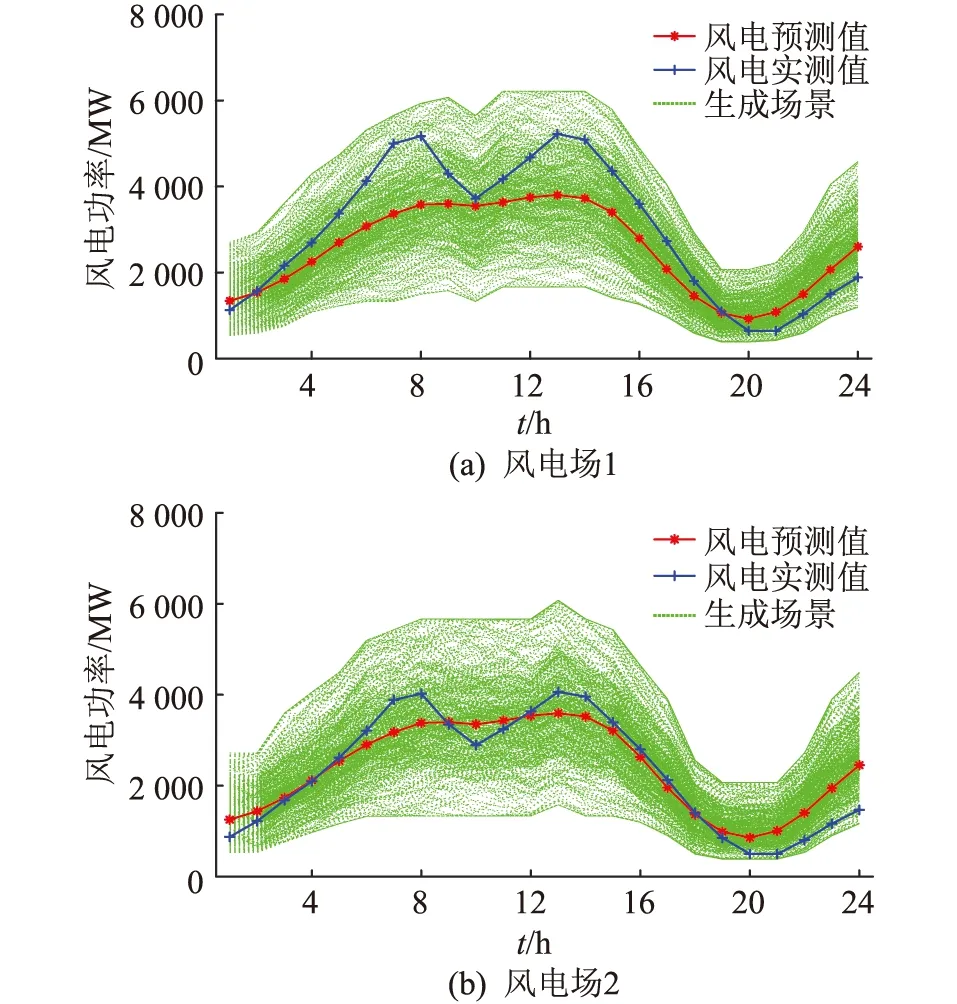
图7 两风电场时空相关性场景Fig.7 Spatial and temporal correlation scenes of the two wind farms
两风电场生成场景均与当日预测值具有比较一致的波动情况。这是由于控制参数ε是根据预测日波动情况并使得误差最小确定的,而且在场景生成过程中,是按照当日预测值大小选择不同数据箱进行非线性变换与等概率逆变换的。
4.2 基于改进K-means聚类的场景缩减结果分析
聚类目标期望在类内的元素具有较大的相似性,不同类中的元素具有差异性。应用手肘法与聚类有效性指标相结合的方法,寻找最优聚类数目。SSE值随聚类数目变化情况如图8所示。
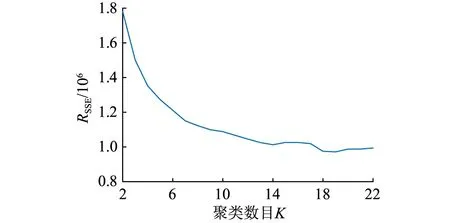
图8 两风电场SSE值随聚类数目变化示意Fig.8 Schematic diagram of SSE changes with the number of clusters in the two wind farms
由图8可知,在聚类数目为2~7时SSE值急剧下降,还未达到最优聚类数目。当聚类数目达到7~9、9~10与10~12时,SSE值变化相对平缓,在14~18时出现波动,目测法难以准确定位拐点。
CH值随聚类数目变化情况如图9所示。

图9 两风电场CH值随聚类数目变化示意 Fig.9 Schematic diagram of CH changes with the number of clusters in the two wind farms
由图9可知,在K=7和K=9时CH值较大,具有较高的聚类有效性,且K=12~14与K=19时,有效性也较高。K-means聚类是一个反复迭代的过程,重复选取聚类中心与按照距离准则划分样本直到满足误差要求,得到稳定的聚类结果。K=9时的迭代次数相较于K=7时并未显著增加。将2类评判指标相结合得到最优聚类数目。拐点确定在K=9时CH指标最高,类内场景紧密程度与类间场景离散程度最优,为最佳聚类数目,可有效代表大量场景的变化特征。进行聚类缩减后,得到的两风电场场景如图10所示。

图10 K-means聚类所得两风电场场景Fig.10 Scenarios of two wind farm obtained by K-means clustering
由图10可知,两风电场缩减后的场景均与生成的大规模场景具有一致的变化规律。
4.3 场景质量检验结果分析
最后需对文中方法生成场景的波动性、时间相关性等特征进行检验。蒙特卡洛与拉丁超立方均为从概率分布中抽样的技术,应用广泛。以风电场1为例,文中分别采用基于历史数据统计特性的简单蒙特卡洛抽样法和采用分层抽样的拉丁超立方抽样与文中方法进行对比,生成场景见图11。
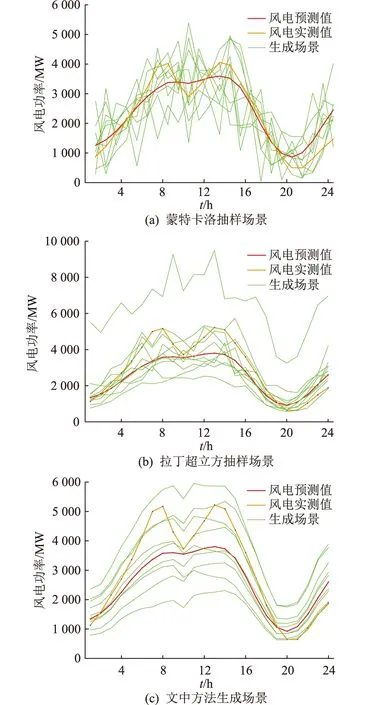
图11 抽样方法与文中方法生成场景对比Fig.11 Comparison of scenarios generated by sampling methods and method proposed
由图11可知,2种方法均能模拟风电的不确定性,且在大多数情况下生成场景均能覆盖当天的实测风电出力情况。可直观看到文中方法所生成场景与预测情况具有一致的变化趋势,且相邻时刻具有较大的相关性,而抽样方法有时可能会产生离群值或具有较大波动。对生成场景进行质量检验,结果对比如表3所示。
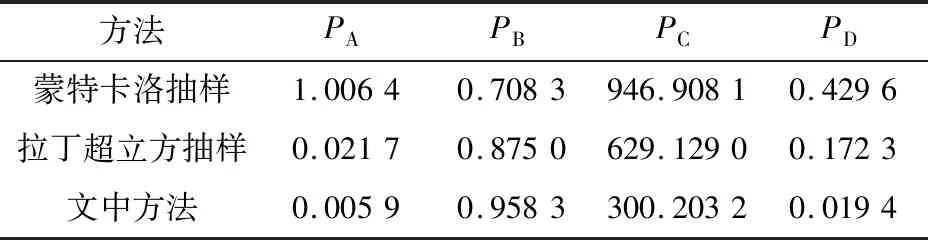
表3 抽样方法与文中方法生成场景质量评价对比Table 3 Compasion of quality assessment of thegenerated scenarios between sampling methods and method proposed in paper
对比上述4个指标,文中方法PA值更低,说明生成场景具有与历史数据更为一致的时间相关性,从而验证应用指数函数法构建协方差矩阵的有效性。文中方法PB值更接近1,生成场景对实测值的覆盖率更高,生成场景更能考虑到潜在不确定性。该方法生成的大规模场景完整覆盖当天风电随机性与波动性,改进的K-means聚类算法在忽略掉离群值基础上,以少数有代表性的场景反映风电变化特征,在减少计算量的同时并未降低场景对实际值的覆盖能力。文中方法PC更小,生成场景更能捕捉到风电的波动特性,爬坡情况与实测值更接近。由于蒙特卡洛与拉丁超立方抽样生成场景的过程中并未考虑到两风电场的空间相关性,因此文中方法PD更小,生成的两风电场场景间相关性与历史数据更为近似。在大规模风电接入的背景下,充分考虑多风电出力的相关关系具有重要意义。经检验,文中方法生成的场景具有更高的有效性与可靠性。
5 结论
针对多风电场出力具有的时空相关性特征,应用指数函数法构建体现风电时间相关性的协方差矩阵,通过构建Copula函数模型对两风电场之间的空间相关特征进行分析建模,采用构建数据箱并对累积概率分布函数进行非线性变换与等概率逆变换的方法完成场景生成。针对大规模场景应用改进的K-means聚类方法进行缩减,得到代表性聚类场景,克服了难以确定最优聚类数目及聚类情况波动的缺点。最后应用评价指标定量检验所生成场景的有效性。以某地区两风电场历史风电数据为例验证文中方法的有效性,主要结论如下:
(1)考虑风电时空相关性生成的场景,不仅能更好地拟合风电的波动性,与风电实测值具有更一致的爬坡情况与相关性大小,同时可以使得风功率场景包含更多空间相关特征,与多风电场间的实际出力情况更相符。
(2)通过改进K-means聚类方法确定了最优聚类数目,平衡了类间、类内的相似性与差异性,得到具有代表性的多风电场景。
(3)所得时空相关性风电出力典型场景可应用于综合能源系统日前调度中。
