卷积神经网络的FPGA并行加速设计与实现
2021-11-30郭子豪曲志坚
满 涛,郭子豪,曲志坚
(山东理工大学 计算机科学与技术学院,山东 淄博 255049)
0 引 言
随着计算机视觉和深度学习的迅速发展和广泛应用,对于卷积神经网络(Convolutional Neural Network,CNN)的关注度越来越高。但是,随着CNN的网络深度和规模越来越大,由此带来的功耗较大和计算效率低等问题又使得人们关注于使用不同架构的硬件来加速CNN的计算[1-3]。对于CNN,现场可编程门阵列(Field Programmable Gate Array,FPGA)使用软硬件协作来执行CNN网络,可重构配置以便在速度、功耗和灵活性之间权衡,可以大大提高计算效率并降低功耗。
目前的研究主要针对CNN模型的压缩和终端推理计算的设计与优化。在模型压缩方面,Choi等[4]分别对目标权重和激活分别量化并形成一个整体量化神经网络(Quantized Neural Network,QNN)的新技术;Ding等[5]提出使用2的幂的有限组合替代权重,从而用移位操作代替乘累加操作,实现了更高的准确性和更快的速度。在FPGA的设计与优化方面,Zhang等[6]设计了一种对特征图分块展开的加速方法并提出Roofline模型优化资源利用率,Li等[7]设计了一种单指令多数据(Single Instruction Multiple Data,SIMD)的卷积与流水线结构进行CNN加速,Stylianos等[8]提出一种以同步数据流(Synchronous Dataflow,SDF)计算模型为基础的加速器框架,Yang等[9]使用移位操作和1×1卷积优化网络设计了新的加速器架构和CNN模型。
本文针对使用浮点数进行卷积计算导致的计算复杂度高、模型占用空间大和运算速度慢的问题,设计了一种基于FPGA的卷积神经网络加速器。首先,通过设计动态定点量化方法,实现了将浮点CNN模型各层的权值和特征图参数动态量化为定点模型;其次,通过输入即输出方式的流水线架构提高数据吞吐率,并对卷积运算单元进行并行优化以提升计算效率;最后,采用MNIST手写数字字符库和CIFAR-10数据集进行方案和功能验证。
1 卷积神经网络
CNN是由大量具有可学习功能参数(也称为“权重”)执行点积的神经元构建的,并且需要反向传播进行训练并向前传播进行测试。CNN与传统识别算法不同,其输入数据可以使用图像,并且不再需要特征提取和数据重建。在此条件下,CNN的前向传播等效于二维卷积,这意味着CNN具有很强的确定性和并行性便于对其加速。经典的CNN模型由许多不同的层组成,特征图依次在这些层上进行运算,下一层都从上一层的输出中读取输入特征,然后执行和输出。常用的CNN层包括卷积层、池化层、全连接层和分类层。
LeNet-5是一个非常成功且典型的卷积神经网络模型[10],其网络结构如图1所示。
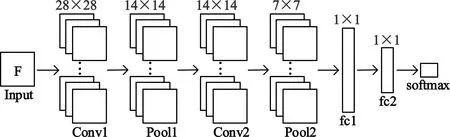
图1 LeNet-5网络结构图
对于MNIST数据集,LeNet-5网络的输入为28×28×1大小像素的图片,对于CIFAR-10数据集,该网络的输入为32×32×3大小像素的图片。输入图像按照网络结构的顺序依次通过conv1-pool1-conv2-pool2-fc1-fc2层后输出10个特征值,然后在softmax层中进行归一化求出最大概率值,进而得出分类结果。两个数据集的网络参数设置如表1所示。
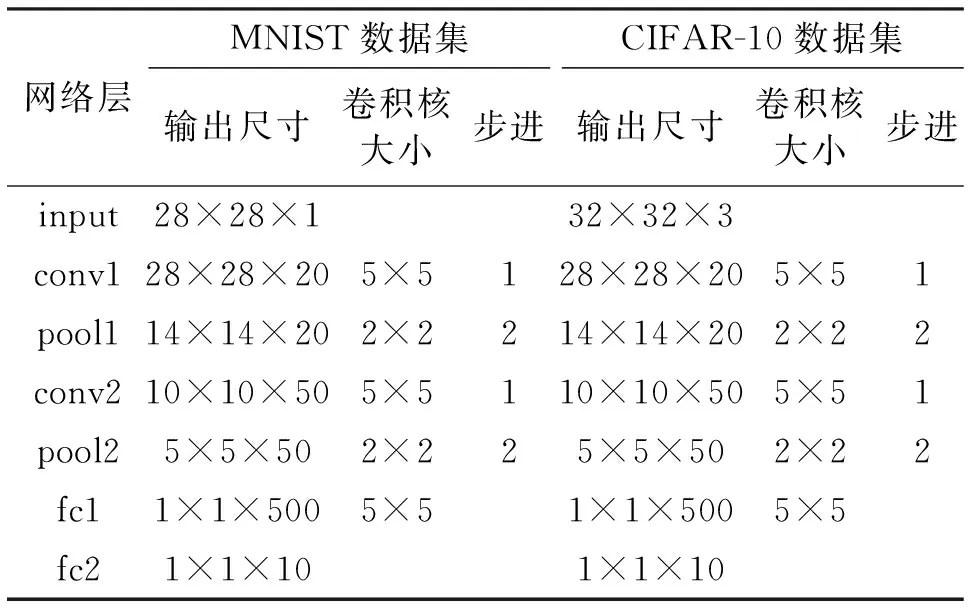
表1 网络参数表
2 FPGA加速器设计方案
2.1 总体框架
采用ARM+FPGA的整体架构设计卷积神经网络的前向推断加速,包括ARM处理器部分(Processing System,PS)和FPGA逻辑资源部分(Programmable Logic,PL)。因为卷积神经网络的计算密集层主要为卷积层和全连接层,所以进行软硬件划分时,在FPGA上实现的主要是网络的运算,而ARM处理器主要负责对输入数据和参数进行预加载和分配,并执行对FPGA初始阶段的控制。
系统的结构框架如图2所示。左上方为ARM处理器PS部分,灰色区域为可编程逻辑PL部分。PS部分主要包括ARM双核处理器及其控制的数据输入端口、分类结果输出端口、DDR(Double Data Rate)存储模块和IP(Internet Protocol)网络接口,PL部分主要由AXI_DMA控制模块、片上存储器和由不同层的IP核构成的CNN硬件加速器组成。

图2 系统结构框图
系统的具体工作流程如下:ARM Cortex-A9处理器通过IP网络接口从上位机获取MNIST数据集或CIFAR-10数据集的特征图和权值参数数据并存入到DDR存储模块中,然后驱动AXI_DMA模块,从直接存储寄存器(Direct Memory Access,DMA)中将特征图和权值参数传输到片上存储器(Random Access Memory,RAM)。ARM会控制CNN硬件加速器模块从片上存储器中读取所需的特征图和权重参数数据进行计算,在CNN加速模块计算完之后将计算结果存储在片上存储器中。整个运算过程完毕之后,ARM会驱动AXI_DMA模块,将运算结果从片上存储器传输到DMA再传输到DDR存储器中,ARM通过IP网络接口将结果传输给上位机。
CNN硬件加速器模块的实现是通过将卷积神经网络的各个层设计成IP核,然后将各层IP核按照网络的结构连接到一起,通过AXI4-Streaming总线来传输数据流,各层之间采用输入即输出的计算模式。该计算模式实现了流水线操作,数据流可以由每个层独立地驱动,上一层计算好的数据可以立即传出,既节省了整个网络的内存占用又提高了系统鲁棒性。
2.2 数据量化
为了减少FPGA在计算时的资源耗费,在网络模型识别准确率保持不变或者略微下降的前提下,一般采用数据量化来降低网络模型计算时的数据位宽[11]。文献[12]从优化CNN运行内存带宽角度出发,统计了CNN分别采用浮点数与定点数计算时MNIST手写数字数据集的识别错误率,其测试结果显示数据在使用定点16位和定点32位时错误率基本没有变化。
在FPGA上进行卷积计算时大部分使用乘法器和加法器进行设计。乘法器和加法器的资源消耗与数据精度息息相关。根据实验得出,乘法器和加法器主要耗费数字信号处理器(Digital Signal Processing,DSP)和查找表(Look-up Table,LUT)资源。不同精度下,乘法器和加法器的资源耗费如表2所示。
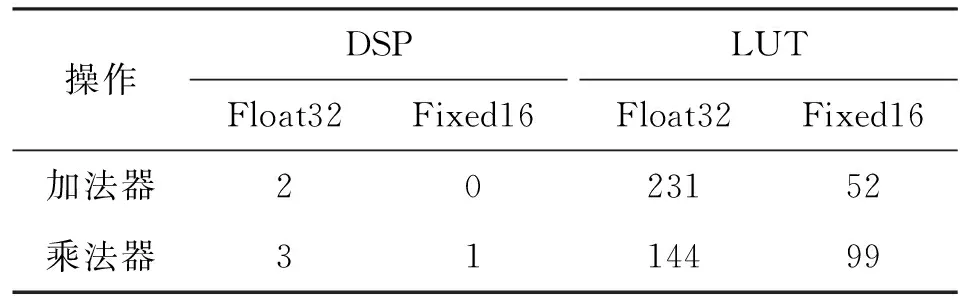
表2 资源耗费比较
表2表明,选择浮点32位精度设计单个乘法器和加法器时,DSP和LUT消耗都比较大。然而,定点数16位精度的加法器不消耗DSP,只消耗较少的LUT;乘法器的资源消耗也大大减少。因此,在确保数据精度不变或较少变化的前提下,定点计算具有很大的优势。
文献[13-14]介绍了对于网络模型参数和输入输出特征图的采用动态定点数量化的方法。本文借鉴了相关的量化思路,设计并采用16位动态定点数对卷积神经网络中的参数和特征图进行量化,如图3所示。在对每一层的输入输出特征图和权重参数进行量化时,采用阶码来表示每一层参数和特征图分配给小数部分的位数,每一层的阶码是固定的,层与层之间的阶码是根据数据分布范围动态调整的。

图3 动态定点量化
动态定点量化定点数xfixed由以下公式表示:
(1)
式中:s表示符号位,f表示阶码,B表示量化的位宽长度,xi表示尾数部分。定点数xfixed最高位为符号位。
动态定点数量化包含以下三个部分:
(1)参数量化
在进行量化之前,需要先找到每层权重参数的最优阶码fw:
fw=argmin|Xfloat-Xfw|。
(2)
式中:Xfloat表示在CNN训练中某层权重参数的原始浮点值,Xfw表示在给定阶码fw的情况下对Xfloat定点化后再转换回浮点数的值。在CNN原始的浮点数权重和定点量化后的权重差的值最小的情况下得出的fw为该层的最优阶码。
(2)中间特征图量化
其次,需要按照网络的结构对网络中每层的输入输出特征图进行量化,使得每层特征图具有共同的阶码fo,其满足
fo=argmin|Pfloat-Pfo|。
(3)
式中:Pfloat表示CNN前向推断中的输出特征图的原始浮点数值,Pfo表示给定阶码fo的情况下对原始数据定点化后再转回浮点数的值。其余过程与参数量化类似。
(3) 中间参数量化
在对权重参数和中间特征图进行定点量化之后,还需要对中间的计算结果进行量化。采用乘加和移位的方式对CNN中间计算产生的定点数进行操作,保证卷积神经网络在FPGA上的数据计算和传输都采用定点数来进行。中间参数量化的阶码fm的计算公式如下:
fm=argmin|Mfloat-Mfm|。
(4)
由以上的量化计算公式可得LeNet-5模型的阶码如表3所示。CNN模型进行计算时采用量化后的参数进行运算,对定点数进行乘累加运算,将运算结果按照每层的阶码再进行量化操作,量化后的特征图再作为下一层的输入参与到下一层的计算,直到完成CNN模型所有的计算。

表3 CNN各层阶码
2.3 数据存储模块
ARM端的一个任务是负责从DDR内存到FPGA片上存储器的数据传输,通过AXI_DMA模块实现。通过AXI4-Lite总线对AXI_DMA模块进行配置,对DDR存储模块的指定区间执行读写任务,DMA通过AXI4总线读取DDR内的特征图数据,并通过AXI4-Streaming总线将读取到的数据输入片上缓存模块,进而给到CNN加速IP,并将最后的结果通过总线接收后传输至ZYNQ处理系统,完成数据的传输。
进行数据传输的总线使用了握手协议更为简单的AXI4-Streaming总线。AXI4-Streaming总线协议去除了地址概念,不再是一种地址映射协议,而是数据流通信协议,可以始终不断地对一个地址读写,因此该协议主要面向高速的、大数据量的数据流传输,这提高了数据传输的效率。存储器直接访问DMA是一种高速的数据传输操作,在存取数据的过程中,数据的传输由FPGA上的独立控制器控制和调度,这样CPU和其他功能模块可以负责其他任务。通过使用AXI4-Streaming协议和直接存储寄存器DMA可以为系统提供更高的数据传输吞吐量。
为了减少存储器传输延迟,本设计将所有的特征图数据和权重参数都存储在片上存储器中,在运行时可以重新加载。
2.4 卷积与池化模块设计
本文设计了如图4所示的卷积计算单元,将卷积计算单元设计为多个部分,包括存储模块、移位寄存器、乘法器阵列、加法树和累加器,一方面通过将数据存储在多个存储模块中来同时获取多个数据;另一方面是将复杂的卷积运算转换成乘加法运算,需要使用较多的DSP资源来提升并行性。

图4 卷积计算单元
为了减少缓冲区的使用和提高计算的吞吐量,采用了不改变滑窗计算过程并且使用较少DSP资源的乘加树计算方法。该卷积层输入多张特征图及其对应权重,分别经过乘累加运算后得到一组卷积结果。对该组结果进行相加后,得到一个卷积计算的输出,然后对结果进行缓存。设计的卷积计算单元能够将多个特征图计算并行,从结构的层面对卷积神经网络并行加速。
由于块随机存取存储器(Block Random Access Memory,BRAM)的限制,无法把所有数据都存入到BRAM上进行计算,若通过DDR读取传入数据再进行计算,则速度会受到影响。在设计时提出将输入特征图存储于基于LUT的存储模块中,权重存储于基于BRAM的存储模块中,通过添加约束指令来实现对于存储模块的分割,以便于并行获取多个输入数据。
如图4所示,有4个存储模块输入特征图1~4负责存储输入特征图,4个存储模块权重参数1~4负责存储权重。对于包含填充操作的卷积神经网络,需在输入特征图的边缘位置填充0。根据当前卷积操作所在的时钟周期,负责执行点积的数据被存入移位寄存器Ai和Bi中,然后使用4个乘法器阵列对权值和特征图进行乘法运算,将计算值共享给加法树进行累加计算,最后的累加器负责将上一层的输出的值求和,结果再经过之后的非线性函数ReLU送到下一层。在计算的过程中不用等待当前计算完成再获取下一组数据,而是在下一个时钟周期继续获取数据,构成一个数据处理流水线。因此,整个卷积计算模块具有高吞吐量,从而整体的数据处理速度也得到提高。
本文设计的池化模块如图5所示,通过5个for循环遍历输入通道、输入特征图长宽和卷积核大小,并可根据模型选择三种池化方式。

图5 池化运算单元
平均值池化一般由输入数据和一个系数恒定的系数乘加实现,最大值和最小值池化由比较器实现。池化的步长为2,窗口尺寸为2×2,以类似滑动窗口的方式来进行池化操作。
3 实验结果
3.1 实验环境
本文进行硬件设计使用的开发板是Xilinx公司的PYNQ-Z2,该开发板使用的是ZYNQ-7000 xc7z020clg400-1的FPGA芯片。实验中的硬件开发环境为Vivado 2019.1和Vivado HLS 2019.1。在通用的CPU平台上用软件实现了与FPGA完全一致的CNN模型,CPU采用的是Inter Core i5-8300H处理器,主频为2.3 GHz,卷积神经网络的训练和执行采用基于Python的Tensorflow 1.15框架。实验的测试数据集是MNIST数据集和CIFAR-10数据集。
3.2 测试流程
通过PYNQ开源框架,用户可以可直接在PYNQ-Z2上进行开发和测试。本设计所采用的基于PYNQ的测试流程如下:
Step1 在Vivado开发环境中对设计的方案进行综合、布局布线、生成bit和tcl文件,给FPGA上电并启动。
Step2 给DDR存储模块加载网络参数和数据集。
Step3 通过PYNQ进行SoC编程,Overlay比特流,配置FPGA。
Step4 对测试集中的图片进行识别,识别完成后FPGA输出识别结果,ARM处理器从PL端读回测试结果,并通过IP网络接口传至上位机。
Step5 如果当前批次中的图片未处理完,则重复操作Step 4;如果测试完成,记录识别时间并传至上位机。
3.3 识别精度
在文献[15-16]中,使用16位定点数量化进行模型压缩导致的识别准确率的下降范围为0.02%~2.88%。不同批次下,本文采用数据量化的方法进行模型压缩后的准确率如表4所示,在MNIST数据集下由数据量化引入的精度损失不超过0.6%,在CIFAR-10数据集下由数据量化引入的精度损失范围是0.5%~1.4%。

表4 不同批次下准确率对比
在批次为500的情况下,本文将数据量化后的参数代替原有的参数在软件平台进行测试后发现,对于MNIST数据集卷积神经网络的识别准确率从98.6%降低到98.4%,对于CIFAR-10数据集卷积神经网络的识别准确率由75.3%降低至74.2%,可见是由数据量化的使用导致了准确率的下降。经过FPGA实现后,两个数据集的识别率仍为98.4%和74.2%,说明硬件实现并未导致新的识别精度的下降。
3.4 资源使用
本次设计经过综合、布局布线后,Vivado 2019.1给出的资源使用情况如图6所示,图中列出了LeNet-5模型在MNIST数据集和CIFAR-10数据集下FPGA的资源使用情况。

图6 FPGA资源消耗
通过对FPGA资源使用情况分析可以发现,BRAM、LUT和DSP48乘法器是本设计占用率比较大的资源。由于本文使用的方法是将权值参数全部放在片上BRAM中,特征图的值存储在基于LUT的存储模块上,所以对于BRAM和LUT的资源使用率非常高。对于乘法部分运算逻辑全部使用的DSP资源。可以看出,本设计对资源的利用率很高。
3.5 性能分析
由于文献[17-20]并未给出功耗及性能指标,对于功耗方面,本文按照对比文献中的时钟频率和资源使用率,使用Xilinx Power Estimator(XPE)得出其FPGA的运行功耗;对于性能方面,本文按照文献[21]中的关于计算量的公式对其进行了计算以方便对比,CNN中的计算量指的是输入一张图像,CNN网络模型进行一次完整的前向传播所发生的浮点运算次数,也即模型的时间复杂度,单位为FLOPs。而GFLOPS是指每秒十亿次浮点运算的次数,表示计算的速度,与GOPS近似相等,是一种衡量硬件性能的指标,所以本文使用GFLOPS来进行性能分析。单个卷积层的计算如公式(5)所示:
FLOPs=2×Ho×Wo×K2×Cin×Cout。
(5)
式中:Ho、Wo表示每个卷积核输出特征图的高度和宽度;K表示每个卷积核的边长;Cin表示每个卷积核的通道数,也即输入通道数;Cout表示本卷积层拥有的卷积核数,也即输出通道数。
对于全连接层,浮点运算次数计算公式如下:
FLOPs=2×I×O。
(6)
式中:I表示全连接层输入维度,O表示输出维度。
根据表5列出的实验结果,本文的硬件工作平台FPGA的工作频率为100 MHz,识别每张图片的时间为MNIST数据集2.067 ms和CIFAR-10数据集4.98 ms,且功耗仅为1.6 W左右。识别时间在Jupyter notebook中可视化的时间损耗为计算时间,包括网络部署时间、Python脚本解释器初始化时间、内存传输以及前向传播的时间。

表5 相关工作比较
此外,通过本次设计的板级测试,得到系统的性能等数据与其他文献的对比,如表5所示。文献[17-20]与本文设计比较类似,均研究了在FPGA上实现小型网络的加速方案,文献[17-18]使用的是MNIST数据集,文献[19-20]使用的是CIFAR-10数据集。通过比较,文献[17]使用的数据精度更低,但本文在单帧时间、功耗及性能方面更优。文献[18]在单帧时间及性能方面均优于本文设计,但其使用了1 180个DSP,使用的DSP数量约是本文设计的9.2倍,但在性能方面仅为本设计的1.9倍,本文在单位DSP的性能贡献方面优于该文献。文献[19]虽然在功耗方面与本文相近,但是本文在性能方面为其15.7倍,能效比方面为其15.5倍。文献[20]使用了32位浮点数,其单帧时间、性能和能效比方面都不如本设计。综上所述,本文设计的FPGA加速方案具有更好的综合性能。
表6为本文设计所使用的开发平台与同等网络结构下CPU和GPU性能对比。由表6可知,本设计实现的FPGA加速器功耗仅为文献[22]中CPU和GPU的5.8%和6.6%,性能方面相比也有较大的提升。

表6 与CPU、GPU的比较
4 结束语
为了解决目前硬件设备上实现卷积神经网络资源有限和功耗过大问题,本文提出了一种基于流水线架构的卷积神经网络加速器架构。该架构针对CNN网络的结构设计卷积计算策略,并在FPGA平台上量化了网络参数,解决了卷积神经网络需要大量FPGA资源进行计算的问题。为了优化内存,本文提出了一种CNN各层输入即输出的工作方式,各层IP按照流水线的方式工作,大大提高了数据交互效率。本设计在xc7z020上实现了LeNet-5,实验结果表明,与LeNet-5在CPU、GPU和其他FPGA平台中的实现相比,本文提出的方法保持了准确率,节省了资源,降低了功耗,对资源和功耗有限的平台实现卷积神经网络的加速具有重要意义。
为了进一步提高FPGA加速器的性能,后续的研究方向主要集中在探索模型压缩的算法并设计更大更复杂的加速器,提升FPGA硬件架构的通用性。
