基于Gensim的LDA主题模型分析在商品评价中的应用
2021-11-28肖自乾陈经优符天
肖自乾 陈经优 符天


摘要:目前在网上购物已成为大多数人的首选,避免购物途中的劳累并且也节约时间。文章基于LDA主题模型对电商平台商品的评论数据进行分析,得出用户正面评价和负面评价分别主要集中在哪些方面,并提出针对性的改进建议,从而提高商品的质量和用户体验。
关键词:Gemsim;LDA;文本分析;主题模型;评价
中图分类号:G642 文献标识码:A
文章编号:1009-3044(2021)30-0017-03
开放科学(资源服务)标识码(OSID):
1引言
随着信息技术的不断发展革新,线下物流业的蓬勃发展,人们在电商平台购物已成为生活的一部分。2020年中国网上零售额达11.76万亿元,同比增长10.9%,实物商品网上零售额达9.76万亿元,同比增长14.8%[1]。面对如此庞大用户群体、如此庞大的交易额,商家如何高效准确地获取客户反馈对提高销售量、提升客户满意度及提高服务质量显得尤为重要。因此课题从电商平台着手,获取海量用户对某一产品的评价,如好评、差评等,接着进行文本主题分析,得到该产品有哪些方面的优点和缺点,进而提供相关的改进建议。
2 LDA主题模型
2.1 文本分析
文本分析是指对文本的表示及其特征项的选取,它把从文本中抽取出的特征词进行量化来表示文本信息。课题用数学的方法进行选取,找出最具分类信息的特征,这是一种比较精确的方法,尤其适合于文本自动分类挖掘系统的应用[2]。
2.2 LDA的概念和方法
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为三层贝叶斯概率模型,包含词、主题和文档三层结构。LDA是一种非监督机器学习技术,可以用来识别大规模文档集或语料库中潜藏的主题信息,它采用了词袋的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息[3]。课题主要应用Gensim库中的LDA模型。Gensim是一款开源的第三方Python工具包,用于从原始的非结构化的文本中,无监督地学习到文本隐藏层的主题向量表达。它支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法,支持流式训练,并提供了诸如相似度计算,信息检索等一些常用任务的API接口。
3抓取笔记本电脑用户评论
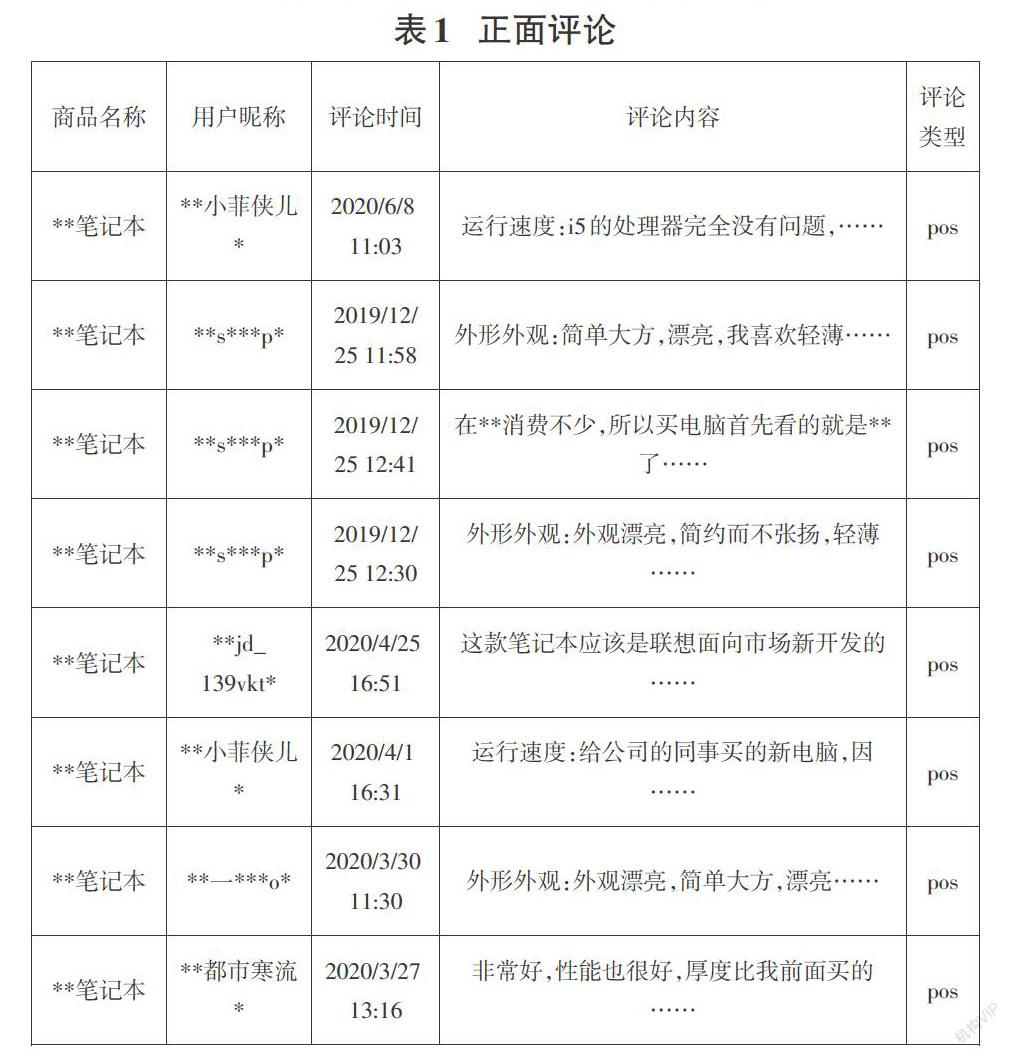
我们选取电商平台上一款销售量较高的笔记本电脑产品,查看“商品评论”可以看到分为好评、中评以及差评。在评论数据包含用户ID、商品名称、评论内容以及评论时间等。在数据抓取中我们可以使用“requests”库或者“Scrapy”爬虫框架来实现。
我们编写程序抓取“好评”评论,对每条记录标记为“pos”,抓取“差评”,对每条记录标记为“neg”。抓取评论页数设置为50页。最终获取正面评论500条,负面评论360条。
4 数据处理分析及LDA模型构建
4.1 语料处理
第一步是进行数据去重和删除笔记本电脑名称等无关词组。抓取到的数据是比较完整的,里面存在诸如商品名、商品型号等重复数据,我们需要对这些数据进行删除,保留能反映商品优缺点的评论内容。
第二步是进行分词、删除标点符号和停用词。中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块,在进行中文自然语言处理时,通常需要先进行分词。在项目中我们引入jieba库,jieba分词算法使用了基于前綴词典实现高效的词图扫描,生成句子中汉字所有可能生成词情况所构成的有向无环图(DAG),再采用了动态规划查找最大概率路径,找出基于词频的最大切分组合。对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。下一步是去除停用词(Stop Words)。停用词被译为“电脑检索中的虚字、非检索用字”。在SEO 搜索引擎中,为节省存储空间和提高搜索效率,搜索引擎在索引页面或处理搜索请求时会自动忽略某些词,这些字或词即被称为停用词。停用词一定程度上相当于过滤词(Filter Words),区别是过滤词的范围更大一些,包含敏感信息的关键词都会被视作过滤词加以处理,停用词本身则没有这个限制。通常意义上,停用词大致可分为如下两类:一类是使用十分广泛,甚至是过于频繁的一些单词。另一类是文本中出现频率很高,但实际意义又不大的词。主要包括了语气助词、副词、介词、连词等,通常自身并无明确意义,只有将其放入一个完整的句子中才有一定作用的词语。经过分词后,评论由一个字符串的形式变为多个由文字或词语组成的字符串的形式,可判断评论中词语是否为停用词。根据上述停用词的定义整理出停用词库,对评论数据进行处理。
最后一步是合并评论ID、评论中词的ID、词、词性以及评论类型成一张表,提取含有名词类的评论,最后将语料处理结果写入数据文件。
4.2 文本情感分析
情感倾向也称为情感极性。在商品评论中,情感倾向可以理解为用户对该商品表达自身观点所持的态度是支持、反对还是中立,即通常所指的正面情感、负面情感、中性情感。由于课题主要是对产品的优缺点进行分析,所以只要确定用户评论信息中的情感倾向方向分析即可,不需要分析每一评论的情感程度。
首先我们建立负面评价词语、负面情感词语、正面评价词语以及正面情感词语四个文本库,用于我们进行目标文本分析的时候用于计算情感值。即正面评价词和正面情感词分值为1,负面评价词和负面情感词分值为-1;然后是根据否定词或双重否定对情感值进行修正;最后是去掉情感值为0的评论,并分别得到正面和负面的评论信息关键词。通过实验表明,在使用原始的正面负面文本库的情况下,假设不存在“好评”中给差评,和“差评”中给好评的情况,根据文本情感分析的正确率为0.8763326226012793,此时交叉矩阵如表3所示。
经过查看文本数据,发现较多正面评价词语被归到负面,或者一些情感词没有被归类到相应的类别,因此需要进行修正,即添加正面或负面评价词语到相应的文本库中,再次运行并得到正确率提高到0.955,此时交叉矩阵如表4所示。
4.3 主题数寻优
在这里我们引入Gensim库,使用doc2bow方法分别将每个正面评论或负面评论生成一个n维向量即语料库。应用基于相似度的自适应最优LDA 模型选择方法,确定主题数并进行主题分析。具体步骤如下:
(1)选择初始主题数k 值,得到初始模型,计算各主题之间的相似度(平均余弦距离)。
(2)增加或减少k 值,重新训练模型,再次计算各主题之间的相似度。
(3)重复步骤2 直到得到最优k 值。
利用各主题间的余弦相似度来度量主题间的相似程度。从词频入手,计算它们的相似度,用词越相似,则内容越相近。
对正面评论和负面评论分别执行划分2~10个主题并计算计算主题平均余弦相似度,生成折线图如图1、2所示,从而确定最佳的主题数。
从以图1和图2我们可以看出,对于正面、负面评论主题数我们分别选1个和2个较为合适。
4.4 LDA主题模型分析结论
根据主题数寻优结果,进行基于LDA的主题分析,打印前10个词组,正面评论生成1个主题,结果见表5,负面评论生成2个主题,结果见表6。
通过主题分析我们可以看出,对于正面评论,相对是比较集中在运行速度快、外观等方面;负面评论有两个方面,首先是对产品总体评价差、开机慢、卡顿等,其次是客服、售后服务质量差,也存在散热等问题。
5 结语
课题通过对电商平台上一款笔记本电脑的正面评论和负面评论进行主题分析,得出相应的结论,具体指出用户正面评价、负面评价主要体现哪些方面,从而为产品制造商、电商平台服务等提出针对性的建议,从而提高产品的质量和平台的服务质量。
参考文献:
[1] 2020年全年网络零售市场发展情况[EB/OL].http://www.mofcom.gov.cn/article/i/jyjl/j/202101/20210103033716.shtml.
[2] 曾祥坤,张俊辉,石拓,邵可佳. 基于主题提取模型的交通违法行为文本数据的挖掘[J].电子技术应用,2019(6):47-51.
[3] 程元堃,蒋言,程光. 基于word2vec的网站主题分类研究[J]. 计算机与数字工程,2019(1):174-178.
[4]张厚栋,徐爱民.基于LDA模型的电商用户评价分析[J].浙江万里学院学报,2020,33(6):91-96.
[5] 张心悦. 生鲜农产品在线评论文本内容对消费者满意度的影响研究[D].哈尔滨工业大学,2020.
[6] 陈俊宇. 基于文本挖掘的在線评论应用研究[D].湖北工业大学,2020.
【通联编辑:王力】