视觉协同的违规驾驶行为分析方法
2021-11-27高尚兵黄子赫耿璇臧晨沈晓坤
高尚兵,黄子赫,耿璇,臧晨,沈晓坤
(1.淮阴工学院 计算机与软件工程学院,江苏 淮安 223001;2.淮阴工学院 江苏省物联网移动互联技术工程实验室,江苏 淮安 223001)
随着机动车数量的增多,频发的交通事故成为社会关注的难题,而司机的不规范驾驶行为(如抽烟、玩手机等)是造成事故发生的重要原因。通过约束驾驶员的行为可以在一定程度上减少此类交通事故的发生,众多研究者开始致力于研究如何快速有效地检测驾驶员的不规范驾驶行为。近年来,图像识别成为了检测驾驶员行为的趋势,深度学习在计算机视觉领域被广泛用于图像分类和目标检测,卷积神经网络(convolutional neural network,CNN)在图像识别和物体检测方面功不可没[1]。
目前基于CNN 的检测驾驶员行为的方法包括:Le 等[2]利用R-CNN 目标检测算法,对驾驶员头部、手部和方向盘进行检测,通过检测头部和手部的位置,判断驾驶员是否在打电话,检测手部和方向盘的位置,判断驾驶员的手是否脱离方向盘;李俊俊等[3]对经典卷积神经网络进行改进,提出了结合FCNN 与三级级联神经网络融合的模型,实验结果表明该模型能有效识别违规行为,但仍需提高训练的准确率和速度;巍泽发[4]构建了一种基于SSD[5]目标检测算法的出租车司机违规行为检测方法,他选用VGG16[6]作为SSD 算法的基础网络,结合自建数据集的特点,采用迁移学习的方法训练数据集,准确率高达94.22%,较原始SSD 算法提升了2.42%,同时能保证模型处理速度为33 f/s。Jin 等[7]采用了一种基于双流卷积神经对驾驶员使用手机这种行为进行实时检测,并在自建数据集上取得了95.7% 的准确率;Huang 等[8]建立了一个混合CNN 的框架,先采用一个联合的预训练的模型对驾驶员的行为特征进行提取,再将这些提取出来的特征送入到全连接层进行分类,实验结果表明,检测准确率达到96.74%。He 等[9]基于CornerNet-Lite[10]神经网络对驾驶员打电话这种行为进行检测,在取得86.2%的准确率的同时还有着30 f/s 的实时检测速度,并且即使在具有噪声干扰的环境下,仍然能够保持较为稳定的鲁棒性。Masood 等[11]在内安装一个摄像头,利用VGG16 对驾驶员的违规行为进行识别,实验结果表明,平均准确率达到了99%。
实时性和有效性是驾驶员行为检测的重要指标。将基于CNN 的目标检测方法如YOLOv4[12]、YOLOv3[13]、EfficientDet[14]、Faster-RCNN[15]、RetinaNet[16]、R-FCN[17]等算法进行对比,YOLOv4 算法更加高效且适合单次GPU 训练。另外,姿态检测算法Open Pose[18]能够实现多人姿态检测,优点是能在人物数量多的情况下,既能保持精度,又可以提升检测速度。
本文提出了一种新颖算法LW-Yolov4,通过去除网络模型中权重较低的模型通道数来简化Yolov4 网络模型大小,从而提高了检测速度。驾驶员违规行为的识别需要通过提出的LW-Yolov4网络和姿态检测算法OpenPose 对驾驶员的监控数据进行协同检测,将视频帧图像送入LW-Yolov4网络获取置信度较高的敏感物品检测框位置坐标,并同时进行人体姿态关键点的检测,获取手指部分关键点坐标。通过判断双手手指部分关键点与敏感物品识别区域是否有重叠,以检测行车过程中玩手机、抽烟、喝水等违规驾驶行为。
1 Yolov4 目标检测算法
Yolov4 目标检测算法平衡了精度与速度,相较于Yolov3,mAP 提升了10%,速度提升了12%。Yolov4 的主干网络采用了CSPDarknet53 网络,并将SPP (spatial pyramid pooling) 模 型[19]加 入到CSPDarknet53 中,使用PANet[20](path aggregation network)代替了Yolov3 的FPN[21]。用Focal Loss来解决数据不平衡的问题。回归框的损失则采用CIOU Loss[22]。基于CutMix[23]数据增强方法,Yolov4 提出了一种新的数据增强方法Mosaic,将4 张图片拼接成一张,能够丰富检测物体的背景,降低批处理数量,使得图片在单GPU 上训练更为轻松。Mosaic 拼接效果如图1 所示。

图1 Mosaic 拼接效果Fig.1 Mosaic effect
1.1 Yolov4 基础网络结构
Yolov4 采用的CSPDarknet53 网络包含了29 个卷积层,感知野大小为725×725。Darknet53结构如图2 所示,由5 个残差块组成。

图2 Darknet53 网络结构Fig.2 Darknet53 network structure
CSPDarknet53 为Darknet 改进而来,在Darknet基础上添加了CSPNet[24](cross stage partial network),能在轻量化的同时保持准确性,降低计算的成本。CSPDark 网络是在每一个残差块上加上CSP,图3 为残差块1 的CSPDarknet53 模型图,其中,层[0,1,5,6,7] 与Darknet53 的原网络一致,而层[2,4,8,9,10]为新添加的CSPNet。

图3 残差块1 的CSPDarknet53Fig.3 CSPDarknet53 of residual block 1
1.2 LW-Yolov4 算法
Yolov4 算法计算精度高,检测速度快,通过加入CSP(cross stage partial)、SPP(spatial pyramid pooling)模块和PANet(path aggregation network)进行多尺度融合的同时利用路径聚合网络将底层特征信息与高层特征进行融合,从而有效增强模型的表达能力,仅牺牲少量训练速度的代价来换得精度的提升。由于车载系统属于低功耗场景,实时检测需要模型的计算量和大小尽可能的小,为了让驾驶员行为检测平台对数据能够实时地处理反馈,针对驾驶员协同检测算法中的目标检测网络模型结构,本文提出了一种Yolov4 的网络模型简化算法−LW-Yolov4,LW(light weight)代表了轻量化,即轻量化的Yolov4 网络模型。
LW-Yolov4 算法简化了神经网络模型,通过去除卷积层中不重要的要素通道,达到提升检测速度的目的。首先通过L1正则化[12]产生稀疏权值矩阵[25],得到的梯度添加到BN (batch normalization)层的梯度中。L1正则化表示为
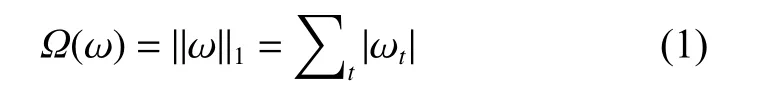
式中:ωt为模型权重系数;Ω(ω) 为惩罚项。使用BN 层中的缩放因子γ评估参数,根据每个神经元的L1绝对值的权重参数γ从小到大进行排序。设立合适γ的阈值,该阈值决定了网络模型最终的大小。本实验将γ阈值设置为0.8,即优化后的神经网络为原网络的模型的0.2 倍。将γ低于阈值0.8 的权重参数置0。然后将由BN 层得到的卷积计算结果与合并后的权值参数β(偏置量)进行计算。通过去除这些不重要的像素通道,网络模型在进行模型推理的时候,可以跳过这些通道,仅仅去加载那些权重大的通道,从而减少模型的计算量,提高模型的检测速度。LW-Yolov4 算法流程如图4 所示。

图4 LW-Yolov4 算法流程Fig.4 Flow chart of LW-Yolov4 algorithm
模型通道数量的改进前后对比效果见表1。通过对比改进前后的模型通道数可知Yolov4 网络模型得到了简化。

表1 模型通道数对比Table 1 Model channel number comparison
1.3 基于LW-Yolov4 的敏感物品检测
本文通过LW-Yolov4 算法进行车内敏感物品的检测,训练前需对数据集图像进行归一化[26]处理,归一化采用了z-score 标准化方法,基于原始数据的均值和标准差,经过处理的数据符合标准正态分布,转换函数为

式中:µ 为所有样本数据的均值;x∗为样本数据的标准差。
训练函数采用了CIOU Loss,CIOU Loss 加入了一个影响因子,这个因子把预测框长宽比、拟合目标框的长宽比考虑进去,公式为

式中:CIOU为交并比;v为权重函数,用来度量长宽比;b、bgt分别代表了预测框和真实框的中心点;c代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离;α 为正权衡参数。

式中:w、wgt分别代表了预测框宽和真实框宽;h、hgt分别代表了预测框高和真实框高。损失函数公式为

2 视觉协同检测算法融合
将敏感物品的识别与人体的姿态进行协同融合检测,从而达到驾驶员违规驾驶行为的识别的目的。
1)人体姿态算法OpenPose
OpenPose 人体姿态识别算法[10]由美国卡耐基梅隆大学提出,可以实现人体动作、面部表情、手指运动等姿态估计。OpenPose 使用的是联合的多branch 分支,一个分支负责关键点的检测,另一个分支负责将关键点连接成骨架,再通过二分图匹配匈牙利算法。
2)算法融合策略
将待检测视频的同一帧同时送入LW-Yolov4网络模型和OpenPose 模型,LW-Yolov4 算法检测后得到敏感物品的位置信息以及置信度,Open-Pose 检测后得到人体关键点信息及手部的位置坐标。设定一个阈值,若连续1 s 内检测到驾驶员的手指位置与敏感物品重合则判定驾驶员出现了违规驾驶行为,保留视频节点并进行语音提醒。算法融合流程如下:
1)将采集到的动作图片序列输入检测系统,对图片进行裁剪、缩放、中值滤波等图像预处理操作,获得416 像素×416 像素的图片,作为模型的输入;
2)将图片输入到LW-Yolov4 模型中进行敏感检测,并得到敏感物的坐标;
3)将图片输入到OpenPose 中获得手部关键点的坐标;
4)进行图片渲染,整合到一张图片上;
5)判断敏感物坐标是否与手部坐标重叠,若重叠则进行相应的预警。
3 实验分析
本文的驾驶员行为识别分析系统是通过对比车内敏感物品的检测框位置与驾驶员手部位置坐标是否出现重合来判定驾驶员是否出现了违规驾驶行为的。因此,实验分为3 个部分,分别为车内敏感物品的检测、人体关键点的检测以及视频融合与行为判定。
3.1 实验平台及数据
实验数据来自淮安公共交运平台的驾驶员行车过程中的驾驶员视角的监控视频,视频数据大小为430 GB。视频像素大小为1280×720,包含了同一场景下的红外摄像头拍摄的灰度图像以及高清摄像头拍摄的日间行车图像。使用标注工具Labellmg 对视频中截取的敏感物品进行标注,主体标注对象为手机、水杯和香烟3 个类别。将标注完成的图片制作成VOC 格式的数据集。数据集包含了15 000 张训练集以及6000 张验证集,实验平台的环境配置如表2 所示。

表2 实验环境配置Table 2 Experimental environment configuration
3.2 协同检测算法融合训练过程
将制作完成的VOC 格式的数据集图片采用Mosaic 数据增强方法进行裁剪、旋转以及缩放操作。LW-Yolov4 训练参数的初始学习率设置为0.001,采用阶跃衰减学习率[27]调度策略,预测分类类别数设置为3(检测手机、水杯、香烟这三类敏感物品),经过2 000 次的迭代训练。读取待检测视频的每一帧图像,通过训练好的网络模型进行敏感物品的检测。图5 为日间行车敏感物品检测效果图,图6 为灰度图像敏感物品检测效果图。

图5 日间行车检测效果Fig.5 Renderings of daytime driving detection

图6 灰度图像检测效果Fig.6 Grayscale image detection renderings
将送入LW-Yolov4 网络模型的视频帧同时送入OpenPose 进行人体关键点检测,得到人体关键点信息。结合敏感物品的检测窗口及姿态检测的信息对原视频每一帧进行渲染,并进行文本可视化,根据检测到的敏感物品以及手部信息在左上角给出文本进行提示,渲染后的效果图如图7、图8 所示。

图7 日间行车融合效果Fig.7 Renderings of daytime driving fusion

图8 灰度图像融合效果Fig.8 Gray-scale image fusion effect
3.3 实验结果
本文选取了3 段驾驶员行车过程监控视频(10 800 f)进行检测,检测对象喝水、打电话、玩手机等违规驾驶行为。通过统计含有违规驾驶行为的帧数与检出违规驾驶行为的帧数计算检出率,检测结果如表3 所示。

表3 检测结果Table 3 Test results
通过表3 的数据可以看出,驾驶员的违规驾驶行为具有较高的检出率,3 个视频的违规行为总体检出率为94.76%,其中喝水的平均检出率达到了95.90%,玩手机的平均检出率为94.65%,抽烟检出率为93.40%。整体来看,喝水的检出率略高于玩手机及抽烟的检出率。检测过程的FPS 为21.36,能够满足驾驶员违规行为检测的准确性和实时性要求。
为了进一步验证LW-Yolov4 算法的性能,本文对面前应用的主流算法进行训练,对比实验结果。评价指标为平均精度召回率mAP、精确率Priecision 以及召回率Recall。实验结果如表4 所示。

表4 LW-Yolov4 算法性能测试结果Table 4 Test results of LW-Yolov4 algorithm
通过表4 中的数据可以看出,LW-Yolov4 算法的运行速度比Yolov4 高出了9.1 个百分点,比Yolov3 高出了6.7 个百分点。但是在精度上,LW-Yolov4 下降的原因在于去除了部分权重较低的网络通道。与SSD、Faster-RCNN 和R-FCN 相比,本文提出的LW-Yolov4 在速度和精度上均有了较大幅度的提升。根据实验结果可知,LWYolov4 的算法优势在于,精度小幅下降的情况下,大幅提升了检测速度,能够满足实时检测的要求。为了进一步验证融合算法对于危险驾驶行为的检测效果,本文进行了协同检测算法的性能和精度对比。实验对比结果如表5 所示。

表5 各目标检测算法性能测试结果Table 5 Test results of the accuracy of each target detection algorithm
在3 类违规驾驶行为的综合检出率中,协同检测算法相较于Yolov4,检测精度提升了5.3%,检测速度提升了10%。相较于其他主流算法,融合检测算法的检测速度和精度也都具有明显的检测优势,检测精度提升5%以上,检测速度提升了10%以上。
由对比实验可以看出,本文提出的协同检测算法在检测精度、检测速度方面均有优势。
4 结束语
本文提出的LW-Yolov4 算法是在Yolov4 的基础上通过精简网络模型改进得到的。通过LWYolov4 算法与人体姿态算法进行融合从而达到检测驾驶员行车过程中违规行为的目的。目前众多深度学习算法模型在精度上表现都较为优越,但很多行业对数据的实时性处理要求较高,在检测速度上还未能完全得到满足。本文提出的LWYolov4 算法在精度能够达到实际应用的同时大幅提高了检测的速度,能够满足基础的应用,但距离工业化的检测速度要求还有一定的差距。在未来目标检测的前进方向上,目标检测速度算法的提升仍会成为重点的研究方向。
