基于CNN-BLSTM 的化妆品违法违规行为分类模型
2021-11-27胡康何思宇左敏葛伟
胡康,何思宇,左敏,葛伟
(1.中国食品药品检定研究院 信息中心,北京 102629;2.北京工商大学 农产品质量安全追溯技术及应用国家工程实验室,北京 100048)
为了规范化妆品生产经营活动,加强对化妆品市场的监督管理工作,使得化妆品质量和消费者健康都能得到有效保障,促进化妆品产业的健康蓬勃发展,化妆品安全监管部门在日常工作中会采取预防、保护、监管等一系列保障措施,防止化妆品相关安全事故发生,保障人民群众的安全与权益。根据近几年国家化妆品监督抽检结果发现,染发类化妆品不合格率偏高,这为化妆品安全监管带来了新的难题和挑战。为进一步保障公众用妆安全,加强化妆品安全风险评估,化妆品安全监管亟需对违法违规行为进行自动识别及分类。因此,研究利用智能化手段辅助相关监管部门监督管理化妆品市场,以确保化妆品安全得到有效监管具有重大意义。本研究建立了针对化妆品安全领域的文本语义分类模型,能够有效提高监管部门监管效率及质量。
文本分类是自然语言处理(natural language processing,NLP)的一个重要且实用的研究方向。在深度学习兴起之前,传统机器学习方法被应用在文本分类领域,如朴素贝叶斯模型[1]与SVM(support vector machines) 模型[2]。然而传统机器学习模型依赖人工语料标注,不仅耗费大量人力物力,而且文本特征提取结果也不尽如人意。
近年来随着深度学习、云计算、人工智能等技术的发展,深度神经网络在各个领域实现应用并取得了较好的成果[3-5]。在NLP 领域,基于大规模语料的情况下,多层次的网络模型实现了自动挖掘文本特征信息,深度神经网络成为了NLP 领域的关键技术之一,其在文本语义分类任务中也取得了良好的效果。
针对文本语义分类问题,目前深度神经网络表现出更好的分类性能[6],因此本文采用基于深度神经网络的方法构建分类模型。
1 相关工作
深度学习方法通过数据来自动学习文本特征,替代了传统人工选取特征的过程,将特征选取转化为通用的学习过程,避免了传统人工选取特征存在的主观性和偶然性。Kim[7]提出将卷积神经网络应用于文本分类任务,降低了文本特征提取的难度,提升了分类精度,但 CNN 仅能学习文本的局部特征,无法考虑词的上下文含义。Mikolov 等[8]将文本分类应用于循环神经网络(recurrent neural network,RNN),其实验证明了RNN 网络能够在文本分类中取得良好的分类效果,并且表现出充分学习文本上下文信息的能力;Socher等[9-10]分别在2012 年和2013 年发表了他们在RNN 方面开展的相关工作,从词开始通过树形结构逐步合成各短语,乃至整句语义,该方法被证实在构建句子级语义时较为有效。但随着输入的增多,RNN 存在梯度消失和梯度爆炸问题。Hochreiter 等[11]利用门机制克服传统RNN 模型缺点,建立长短时记忆网络(long short-term memory,LSTM)模型;Liu 等[12]将LSTM 应用到文本分类中;Alkhodair 等[13]训练了一个LSTM 模型,对谣言文本进行分类。
值得注意的是,近年来注意力机制在NLP 领域取得了广泛的应用。Bahdanau 等[14]做出了最早的尝试,将attention 机制与RNN 结合应用于机器翻译任务;Yin 等[15]介绍了CNN 和attention 的3 种结合方式;Zhou 等[16]将attention 机制与双向长短时记忆网络(bidirectional long short-term memory,BLSTM)结合应用在文本分类中,以获取句子中最重要的语义信息,然而对于内部位置语义等重要信息仍然没有进行很好的学习和处理。
此外,在文本语义分类中,关于字符级和词语级两种嵌入粒度是否对分类效果有影响,不少研究者对此进行了研究。目前,常见的词语级别文本表示方法有布尔模型(Boolean model)、向量空间模型(vector space model,VSM)[17]、嵌入向量模型。嵌入向量模型的目的是将高维词向量嵌入到低维空间,降低文本特征的稀疏性,减少训练资源浪费,并且能够考虑词的上下文信息来进行计算。常用的嵌入向量模型主要有Word2vec 模型[18]和Glove 模型[19]。Kim 等[20]提出了一种通过字符级CNN 提取文本语义信息的模型,刘龙飞等[21]证明了字符级特征表示在中文文本处理中的优越性。
本文针对化妆品安全监管领域,建立了一种基于融合位置感知注意力机制的BLSTM 网络与CNN 网络的字词双维度语义分类模型,使用中文字向量和词向量分别作为双路模型的输入,采用CNN 模型训练字向量,在引入位置注意力机制的BLSTM 网络模型中训练词向量,最后结合双路网络的特征提取结果对文本进行分类。该模型充分利用BLSTM 的特性,从词向量级别挖掘化妆品抽样检查建议(下文称检查建议)文本的语义特征,并结合使用位置注意力机制进行Attention Value的计算,使化妆品安全领域的领域词汇在整个检查建议的语义表达中能够起到决定性作用。同时,CNN 网络能够从字向量级别对文本语义进行进一步挖掘,避免了由于文本语义特征提取不全面而损失文本分类精度的情况发生,有效提高了文本语义分类效果。
2 字词双维度识别模型
为进一步提高文本语义分类准确性,本文提出一种字词双维度模型,能够从字、词级别提取检查建议中提到的违法违规行为语义特征,进一步丰富文本重要语义特征输入,结合两种级别的特征向量,得到最终的分类结果。CNN-BLSTM模型结构如图1 所示。
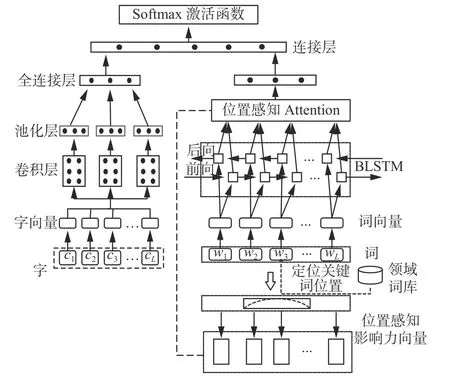
图1 CNN-BLSTM 模型结构Fig.1 CNN-BLSTM model structure
模型在化妆品安全检查建议语料的字和词维度上使用字嵌入和词嵌入,分别生成字向量和词向量,其中字向量作为CNN 网络输入,词向量作为BLSTM 网络输入。
在图1 中,其左半部分为CNN 网络模型。字向量通过输入层输入,经由CNN 网络的卷积层、池化层和全连接层计算,最后得到字符级别文本特征表示。在图1 的右半部分网络模型中,首先模型通过结合领域词库判断领域关键词语义角色和位置,生成基于位置感知的注意力。经过词嵌入生成词向量输入BLSTM 模型,将词向量参与中间隐藏层的计算,之后模型输出隐藏层向量并在注意力机制的影响下得到文本语义特征。在得到字词双维度文本特征输出后,将两路输出通过连接层进行连接,最后通过SoftMax 层进行分类,得到最终分类结果。
2.1 文本向量化
1)语料存在问题
化妆品违法违规行为检查建议语料存在因人为填写而不可避免地产生口语化及表达差异化问题,属于非结构化、非标准化语料。且检查建议中包括化妆品安全领域专业词汇、化妆品安全相关法律法规名称等,具有较强的领域性。语料结构性弱、领域性强,因此向量化难度较大。
2)语料处理思路
针对语料结构性弱问题,本文采用两种不同的向量作为输入,其中一个输入通过获取文本字符级别向量,能够有效避免因为非结构化、非标准化带来的文本语料特征提取困难。再结合词向量级别特征提取,避免重要文本语义特征丢失,丰富文本语义特征表示。在生成字向量前,需要将数据集中所有字符进行提取,构成字符库,并按照字符出现频率进行排序,以便下一步字向量的生成。
针对语料领域性强问题,本文首先进了语料扩充,即在一个公共语料库的基础上,增加化妆品领域相关的百度百科语料,并网络爬虫得到领域词汇、新闻等语料,训练词向量模型。在每隔一段时间积累了一定的检察建议语料时,利用增量训练的方式更新词向量模型,使其能适应最新语料的语义关系,及时更新词汇的向量表示,得到更好的文本向量,提高文本向量化水平,为算法的性能提升打下基础。
3)语料向量化
将检查建议文本分别按词语级别和字符级别进行分词处理后,需要进一步将其向量化表示以作为神经网络输入,用于后续训练分类模型。本研究使用word2vec 进行文本向量化,提取文本语义特征。
2.2 CNN-PA-BLSTM 模型阐述
2.2.1 CNN 网络
卷积神经网络作为一个多层前馈神经网络,通常在全连接层前面包含卷积层和池化层,卷积层和池化层的个数可能是一个或多个。每个卷积层由一组神经元组成,每个神经元都可学习权重和偏差,卷积运算旨在提取输入的不同特征,多层的网络能够从大量样本中通过提取、迭代特征,自动学习获得复杂、高维、非线性映射的文本特征。
1)输入层
在文本分类任务中,将文本进行向量化,作为CNN 模型的输入。
2)卷积层
卷积层是由一系列卷积单元(也称卷积核,filter)组成,通过反向传播算法训练得到每个卷积单元的参数。卷积层能够提取输入的不同局部特征,原因是每个神经元的输入并非与前一层全连接,而是与其局部接收域相连,因此提取到的是该局部的特征。针对化妆品检查建议数据集特点,本文共设置了几种不同尺寸的卷积核,并且确定了适合的滑动步长(stride),以保证提取出的语义特征更全面。另外,为避免特征矩阵中间区域与边缘区域提取次数不同的问题,本研究采取在边缘区域填充空值的操作来避免边缘区域特征提取少,还能够使得卷积输出与输入维度一致,提高程序可维护性和泛化性。
假设卷积层输入维度Win=lin×din,其中lin为输入的长度,din为输入的宽度。那么,输出维度的计算如下:

由式(1)~(3)可知,Wout=Win。
3)池化层
卷积层输出的特征维度通常较高,会造成较大运算压力,解决这一问题的方法是通过池化层对卷积层输出进行特征压缩。本文选择使用最大池化作为池化方式,最大池化即在过滤器滑动到一个区域时,选择使用区域内最大值作为该区域表示。过滤器大小为2×2,滑动步长设置为2。原特征矩阵经过最大池化处理后被压缩为原来大小的四分之一,因此池化操作能够在尽可能保持最显著特征的前提下有效提高计算效率。
4)全连接层
全连接层接收经过卷积和池化操作后得到的一系列局部特征,将其通过权值矩阵重新整合成为完整的特征信息。
2.2.2 BLSTM 网络
LSTM 使用输入门、遗忘门和输出门机制,解决了传统RNN 模型在输入序列信息过长时产生的梯度消失和梯度爆炸问题,图2 给出了LSTM的一个神经元结构。

图2 LSTM 神经单元结构Fig.2 LSTM neural unit structure
忽略其内部细节,每个神经元都有3 个输入与3 个输出,Xt是该时刻新加入的信息,at−1与Ct−1是上文信息的表示。对于经过一个LSTM 神经单元处理后,Ct携带的信息经过输出门限会含有更多当前时刻的信息,因此得到的at相对于Ct可以说是具有短期记忆的,而相对来说Ct则是具有长期记忆的,将它们统称为长短时记忆网络。式(4)~(9)为LSTM 的计算过程:
式中:i表示输入门;f表示遗忘门;o表示输出门;
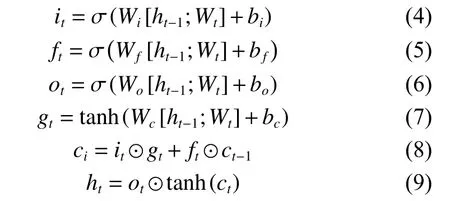
前向传播隐藏层计算公式为
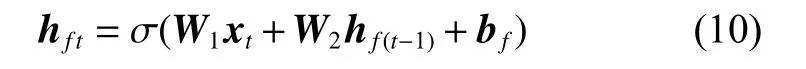
后向传播隐藏层计算公式为
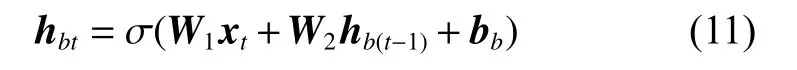
两层输出合并得到输出,可表示为
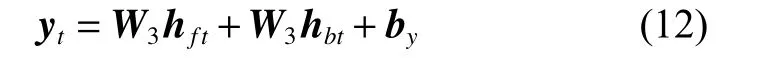
式中:W1、W2、W3分别表示输入层到隐藏层、隐藏层神经元间和隐藏层到输出层的权重矩阵;bf、bb、by分别表示各层计算时的偏差向量。
为了突出领域关键词在句中的作用,本文将位置注意力机制引入BLSTM 网络中,对其输出进行微调。
2.2.3 attention 机制
注意力机制最早应用在视觉图像领域,用来模拟人类视觉聚焦,在重要信息点加注更多注意力,而相对忽略不重要信息的机制。随着深度学习的发展,自然语言处理领域也越来越多地进行W表示对应权重;b表示相应偏置。
BLSTM 本质上是由前向LSTM 与后向LSTM组合而成,通过两层相反方向的数据流对数据进行处理,从而对文本历史信息和未来信息进行兼顾。BLSTM 结构如图3 所示。它的两个并行神经元分别从前向和后向两个方向处理输入序列信息,最终将两层输出进行拼接,作为BLSTM 隐藏层的输出。了基于注意力机制的网络模型应用实现。
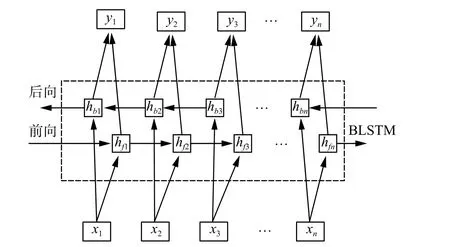
图3 BLSTM 结构Fig.3 BLSTM structure
在文本分类任务中,最终分类结果会受到文本中的每个词所带来的不同影响,而对关键词加大关注力度能够在文本语义表示上更充分发挥关键词作用。同时,上下文信息能够在一定程度上增强字词的语义表示。因此,针对本文中化妆品抽样检查建议的语义分类问题,应考虑到化妆品安全领域关键词及其临近词对于文本语义表示有着不可忽视的作用。因此本文根据领域词库定位关键词位置,让模型学习到更多的位置信息,在模型中引入基于位置的注意力机制,具体结构图4。
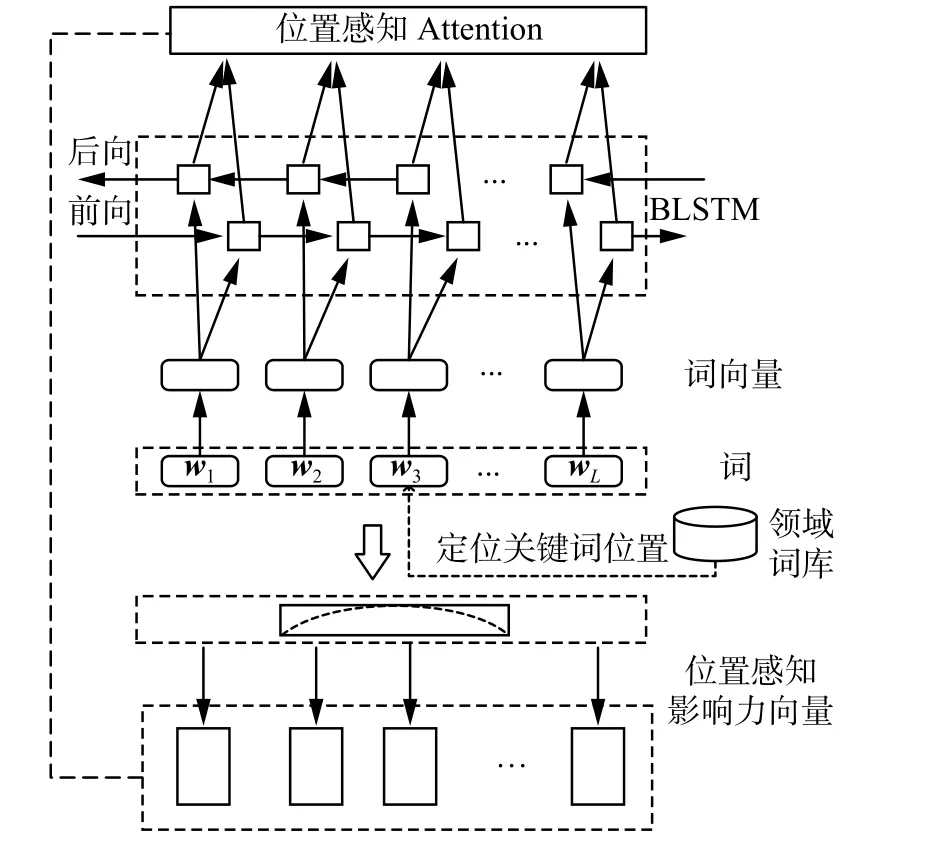
图4 位置注意力机制Fig.4 Positional attention mechanism
本文假设领域关键词的影响力在隐层维度特定距离上是遵循高斯分布的。首先,定义影响的基础矩阵为K,其每一列表示与特定距离对应的影响基础矢量。K的定义为
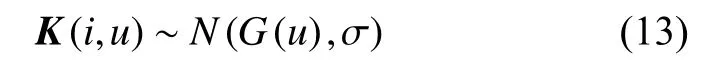
式中:K(i,u)代表第i维中关键词距离为u的相应影响;N代表符合G(u)值的期望和标准差 σ的正态分布。G(u)是高斯核函数,用来模拟基于位置感知的影响传播,其定义为
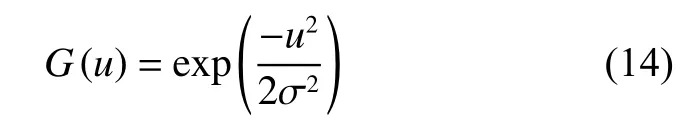
当u=0时,即表示当前词是一个化妆品领域关键词,此时其得到的传播影响力为最大,并且随着距离的增加,传播影响力会逐渐减小。
计算某位置上的词语的位置感知影响力向量,需要结合所有关键词的累积影响,并利用影响力基础矩阵K,得到特定位置下关键词的影响力向量:

式中:pj代表了词语在j位置上的累积影响力向量;cj代表一个距离计数向量,具体可表述为对于在j位置词语,距离为u的所有关键词计数。cj(u)的计算公式为
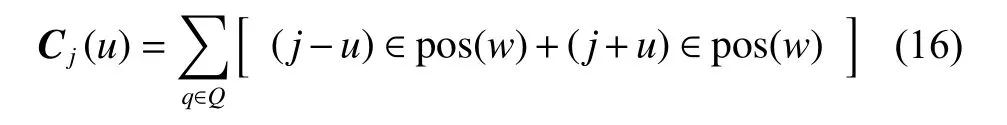
式中:Q为一条化妆品抽样检测文本中所包含的全部关键词集合,q∈Q;pos(w)为关键词w在句中位置的集合;[·]是指标功能,当满足条件时取值为1,不满足时则取值为0。
对于化妆品在检查建议中词语处于j位置时的注意力计算方法为
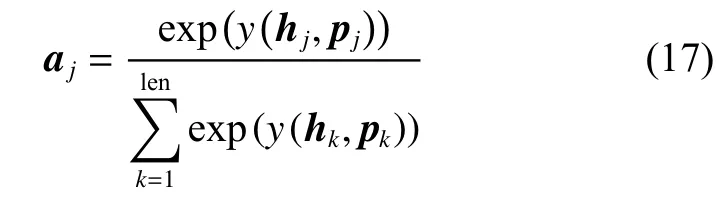
式中:hj是j位置词语的隐层向量;pj是累积的位置感知影响力向量;a(·)用于在基于隐层向量和位置感知影响力向量的影响下测量词的重要性。a(·)的具体形式为
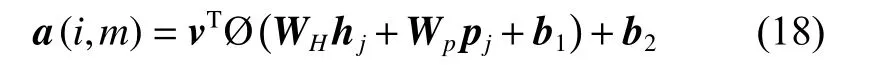
式中:m为一句化妆品检查建议中词向量个数;WH、Wp代表hj、pj的权重矩阵;b1代表第一层参数的偏置向量;Ø(·)=max(0,x)为ReLU 函数;v是全局向量;b2代表第二层参数的偏置向量。最终的Attention Value 根据各位置词语的权重,加权计算句中所有隐层向量所得,其中len为句子长度:

2.2.4 连接输出层
语料经CNN 与BLSTM 双路神经网络处理输出后,在连接层合并文本特征信息,然后输入分类器进行分类。本文选择使用SoftMax 作为损失函数,输出分类结果。此外,本文设置一定概率的Dropout 来避免过拟合问题的发生,即在模型训练过程中对隐含层的部分权重或输出进行随机归零操作,从而使得各节点间的相互依赖程度降低,提高模型泛化性。
3 实验结果及分析
3.1 实验准备
本文数据集来自化妆品监管部门针对化妆品安全相关违法违规行为的抽样数据集,为监管部门每次对化妆品售卖商家实行监管检查后,根据检查结果所填写的违法违规行为及改正建议。抽样检测数据集共包含10 000 条数据,主要分为无问题、功效问题、与产品描述不一致、不良反应、味道不好、不是正品、包装问题、物流问题、价格问题、容量不合理十大类检查建议,结果由5 折交叉验证得到。
将数据集按照8∶2 的比例划分为训练集和测试集用于模型的训练及验证。对于实验使用的相关指标部分,本文采用了准确率、召回率和F1值作为实验结果的评判标准。
准确率计算公式为

召回率的计算公式为

式中:TP代表一个模型在实际预测中将正类预测为正类的数量;FP代表其在实际预测中将正类预测为负类的数量。
因为准确率和召回率往往在其中一个取得较高值时,另一个就会相对较低,即当P高时R往往相对较低,当R高时P往往相对较低。所以为了更均衡地对模型的综合性能进行评价,一般使用F1-Score(F1分数)作为评价标准:

在实验的参数设置方面,CNN 使用的是12 层768 维的隐藏层,BLSTM 模型使用128 维的隐层维度。
3.2 实验结果分析
表1 的实验结果显示,在化妆品安全抽样检测语料中,常规的CNN 网络模型的精确度表现良好,但是在召回率上表现稍次,因此本文在CNN的基础上,对CNN 模型引入了注意力机制,其精确度、召回率和F1都得到了一定的提升。由第3 个模型和第1 个模型实验结果对比可以看出,对于句子整体的语义而言,CNN 模型对比BLSTM模型来说学习机制依然有所欠缺。并且在BLSTM中加入注意力机制后,其精确度、召回率和F1值都得到了较大程度的提升。在一系列的实验中,本文提出的CNN-BLSTM 模型在精确度、召回率和F1值都取得了最优表现,且与前几种常用模型相比,实验结果提升非常明显。
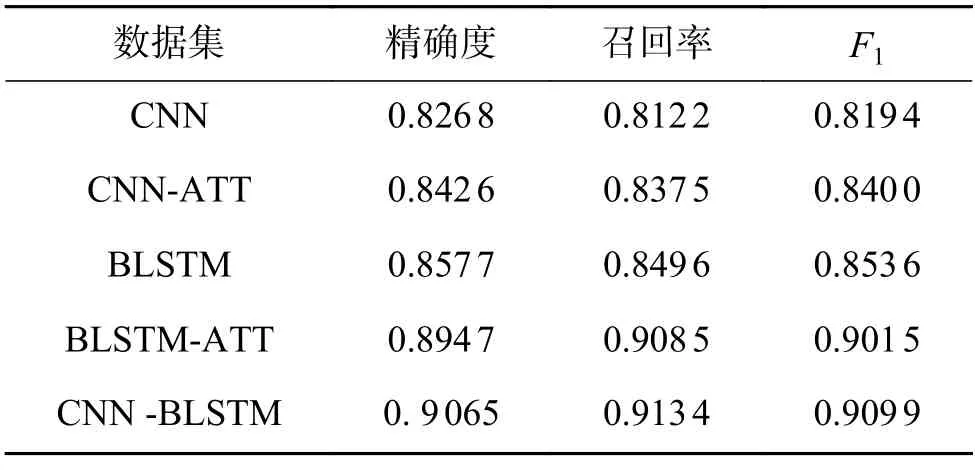
表1 实验结果对比Table 1 Comparison of the experimental results
4 结束语
本文根据化妆品安全监管部门的现实需要,提出了面向化妆品安全的字词双维度违法违规行为语义分类模型。模型使用字、词两个嵌入级别的特征表示,并结合位置感知注意力机制,以实现自动判别抽样检测数据中的违法违规行为。实验表明,本文模型表现出了良好的特征提取和分类性能,相较于实验中几种常用的神经网络模型取得了更好的结果。
未来的工作将继续优化网络结构、寻找更优的参数设置和提升模型训练效率,以期实现对现有模型的进一步优化与改进。
