基于加权深度支持向量数据描述的工业过程故障检测
2021-11-26王晓慧王延江邓晓刚张政
王晓慧,王延江,邓晓刚,张政
(中国石油大学(华东)控制科学与工程学院,山东青岛266580)
引 言
随着现代工业过程的规模扩大和复杂性增加,安全性和连续性成为人们高度关注的焦点。作为保障工业过程安全连续生产的关键,实时故障检测技术的地位日趋重要[1-3]。近年来,随着先进的数据采集和计算机控制系统的广泛应用,工业大数据平台日益完善,数据驱动的故障检测方法成为一个研究热点[4-6]。本质上讲,数据驱动故障检测也可视为一个单分类异常检测任务。单分类异常检测方法通过统计分析、机器学习等技术描述正常数据分布区域,该区域之外的样本被认为是异常数据。作为一种经典的单分类异常检测方法,支持向量数据描述(support vector data description,SVDD)在诸多异常检测领域得到了广泛的应用[7-8]。SVDD 属于一种无监督学习算法,它只需要正常样本进行模型训练即可。在工业生产过程中,大部分采集到的操作样本是正常的,而故障数据很少。即使存在一些故障数据,它们往往是未标记的。因此,SVDD 的无监督学习特性特别适用于数据驱动的故障检测问题[9-10]。
目前,已经有一些学者将SVDD 算法应用到工业过程监控和故障检测中。王建林等[11]针对高维空间中超球体的不规则性,设计了基于核相似度的SVDD 监控模型。赵小强等[12]考虑到测量变量之间存在的相关性,设计了一种基于变量分块的改进SVDD 方法,并通过青霉素发酵过程进行了仿真验证。为同时处理工业过程数据的动态、非线性和非高斯性,Zhang 等[13]设计了一种两步式SVDD 模型。针对SVDD 建模过程中异常点导致检测性能下降的问题,Yuan 等[14]开发了一种剪枝SVDD 模型,以提高故障检测系统鲁棒性。针对滚动轴承故障检测问题,Liu 等[15]提出了一种半监督SVDD 方法,克服了样本标注的局限性。为了监控时变动态特性的批处理过程,Lv 等[16]提出了一种结合实时学习策略的改进SVDD算法。
虽然目前的研究已经说明了SVDD 在故障检测中的可行性,但仍有一些问题值得深入研究。其中一个问题就在于SVDD 模型本质上是一种浅层学习结构,难以对复杂的工业过程数据进行准确描述。即使采用基于核函数的特征提取方法,SVDD 也仅涉及一个特征提取层,其数据描述能力有限。近年来,深度学习理论在机器学习和数据挖掘领域蓬勃发展。深度神经网络通过多个特征提取层自动学习数据的抽象表示,并在数字识别、人脸识别和药物发现等方面取得了巨大成功[17-19]。如何将深度学习思想与SVDD 相结合提高故障检测效果是一个值得深入探讨的问题。
综合以上分析,本文提出一种基于加权深度支持向量数据描述(WDSVDD)的复杂过程故障检测方法。该方法的主要工作体现在两个方面。一方面,将深度SVDD 引入工业过程故障检测领域,构建相应的统计模型和监控指标;另一方面,考虑到深度特征对不同故障的响应差异,从故障敏感性的角度构建特征加权层,并设计静态和动态权重因子,以增强故障检测的灵敏程度。最后,通过一个典型的基准化工过程系统来测试算法的有效性。
1 SVDD原理分析
SVDD 是一种重要的单分类算法[20-22],该方法将复杂的非线性训练数据映射到高维特征空间中,寻找尽可能小的超球体包围所有的训练样本,超出超球体边界的样本被视为异常样本。给定训练数据集X=[x1,x2,...,xn]T∈Rn×m,其中n和m分别为样本和变量数目,SVDD 引入非线性映射函数φ(·),将所有的样本xi映射到特征空间φ(xi)中,并在特征空间中寻找最小超球体实现对数据的包围,对应的优化目标函数如下[20]:

其中,R为超球体半径;o为超球体中心;σi为松弛变量;C为平衡超球体积与边界外样本的惩罚因子。
基于上述优化问题可构造如下拉格朗日函数:

其中,αi>0和βi>0是拉格朗日乘数。进一步分析可以得到原优化问题的对偶描述:

其中,K(xi,xj)=φ(xi)Tφ(xj)为核函数运算,即特征空间中两个向量的内容可以用原始空间中的核函数计算,常用的核函数为高斯核函数。
式(3)描述了一个标准的二次优化问题,求解该问题可以得到超球体中心:

而半径R可以通过计算支持向量到中心的距离得到:

其中,x*表示对应αi>0的任意支持向量xi。
对于t时刻的测试样本xt,定义其到超球体中心距离的平方Dt作为监控指标,其表达式如下[21-22]:

通过将Dt与R2进行比较,可以判断过程数据的情况。如果为Dt≤R2,则将相应的向量xt归类为正常样本。否则,将其视为异常样本。
SVDD 模型的基本框架包含了两个主要步骤,即单层非线性映射、超球体建模,如图1所示。在该模型结构中,非线性映射是一个空间变换,起到了特征提取的作用,实际计算过程中借助于核函数完成。由于基本的SVDD 仅涉及一个特征提取层,往往难以有效处理复杂的非线性数据关系。近年来,深度学习在很多领域取得了巨大的成功,其展示的深层次特征提取技术为进一步改进SVDD 模型提供了借鉴,后续内容讨论如何将深度学习思想与SVDD建模相融合。

图1 SVDD模型结构解析Fig.1 Structure analytic diagram of SVDD model
2 加权深度SVDD监控方法
2.1 方法框架
基于对传统SVDD 模型结构的局限性分析,提出一种加权深度SVDD 模型用于故障监控,其整体结构如图2所示。该方法将基于多层神经网络的深度特征提取技术引入SVDD 模型中,代替传统的隐式非线性变换,提高模型对数据内在特征的挖掘和表达能力。同时,针对深度特征在故障信息表达上的差异性问题,进一步设计特征加权单元,根据特征的故障敏感程度计算权值,增强对复杂故障的监控能力。所提方法的关键在于两点:深度SVDD 模型构建、特征加权策略设计,下文分别进行阐述。
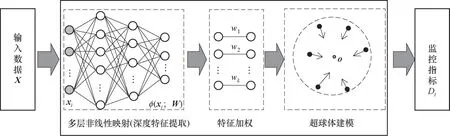
图2 WDSVDD模型结构Fig.2 Structure diagram of WDSVDD model
2.2 深度SVDD建模原理
深度SVDD(deep SVDD)是在S VDD 基础上发展起来的一种新方法[23-24],其基本思想是通过深度学习网络进行特征提取,然后在深度特征基础上构建一个端到端的异常检测网络模型。其与传统SVDD 方法最大区别在于,利用多个特征提取层代替简单的单层核映射来获得数据特征表示。
对于训练样本集{xi∈Rm,i= 1,2,…,n},多层特征提取过程可以描述为函数关系
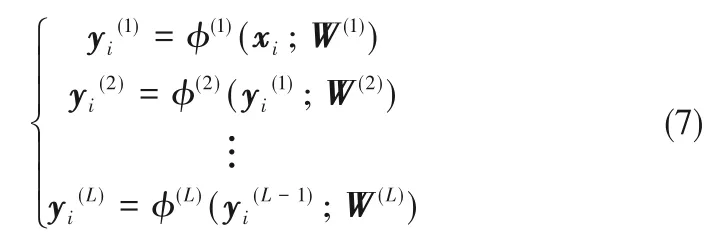
其中,φ(l)(1 ≤l≤L)表示深层网络中的逐层非线性映射函数关系;W(l)(1 ≤l≤L)表示第l层网络权值参数。最终所提取的特征如下:

其中,W={W(1),W(2),...,W(L)}表示深度网络整体参数集合。
由于深度特征提取技术的应用,传统的SVDD优化目标函数不再适用。深度SVDD 模型的优化目标是通过训练调试参数集W使得输出的深度特征y(L)i尽可能密集分布在半径为R,中心为o的超球体内,对应的优化目标函数为[23-24]:

其中,ν是调节超球体外异常数据点影响的平衡参数;λ是对网络权重大小的惩罚系数;o是先验指定的球体中心。在单分类任务中,一般假设训练数据集均为正常样本,此时可以将目标函数进一步简化为
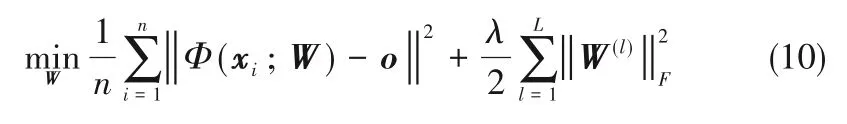
通过深度网络优化算法(如Adam 优化算法)对权值参数W进行优化,训练样本能够在深度特征空间中聚集到超球中心o附近,从而形成一个描述正常训练数据的超球体,训练得到的网络权重参数为W*。
对于测试样本xt,其异常程度监控指标定义为该点的深度特征y(L)t=Φ(xt;W*)到超球面中心o的距离平方,即:与式(6)中的SVDD 监控指标不同,式(1)描述的深度SVDD 监控指标可以直接计算,无须利用复杂的核函数映射。

上述模型作为基本SVDD 模型的深度化扩展,有助于提高故障监控性能。但是,需要注意的是,该深度模型训练过程有一些基本限制,如网络隐层不可设置偏差项、必须采用无界激活函数等,具体参见文献[23-24]。
2.3 基于KDE的监控阈值计算
深度SVDD 模型中没有定义超球体半径,必须寻找另一种方法来设置检测阈值。本文采用核密度估计来获得监控指标Dt的概率分布,进而计算其控制限作为监控阈值。当测试样本对应的监控指标Dt超过其该阈值时,即被认为是故障数据点。
核密度估计(KDE)是一种非参数概率密度估计技术[25],可以根据给定的训练数据估计随机变量的概率密度函数。对于深度SVDD 建模过程中的训练数据样本{x1,x2,…,xn},计算得到相应的监控指标D1,D2,…,Dn。基于训练数据集构建Dt的概率密度函数f(Dt),其表达式如下[25]:

其中,g(·)表示KDE 采用的核函数;a表示核函数的宽度参数。
在给定置信度δ的前提下,可以通过概率密度函数的积分公式求解相应的控制限Dlim,即
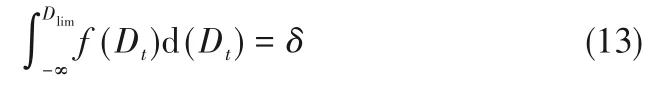
在本文中,置信度δ设置为95%,其概率意义在于,正常样本对应的监控指标数值有95%的概率不超过Dlim。与传统SVDD 方法依赖于优化半径R不同,KDE 给出了监控阈值的明确概率意义。本文中对所有测试方法均采用KDE技术计算监控阈值。
2.4 面向故障敏感特征的静态与动态加权策略
对式(11)中DSVDD监控指标公式进行分析,可以看出Dt本质描述了深度特征空间中的欧氏距离。列出深度特征和超球体中心的具体表达式y(L)t=o=[o1o2…ok],则 式(11)可以重新表达为:

从式(14)可以看出,监控指标平等对待于每个深度特征。实际应用过程中,某些故障可能只影响少数特征(可称为故障敏感特征),大部分特征仍然处于正常状态。此时,微量的故障信息可能会被正常的噪声信息淹没,从而使得故障难以得到有效检测。本质上,这是一个不同特征的故障敏感性差异导致的现象。针对该问题,本文提出采用加权策略来突出故障敏感特征的影响,从而提高对复杂故障检测的灵敏性。
为方便起见,定义第i个深度特征在监控指标中的子成分为:
如果特征为故障敏感特征,则相应的监控指标成分Dt,i必然发生显著变化。为度量深度特征对故障的敏感程度,进一步定义深度特征的故障概率为:
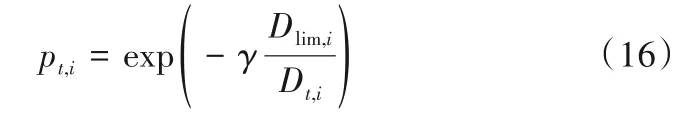
其中,Dlim,i为Dt,i对应的95%控制限,可以根据核密度估计法算出。对于正常数据变化,故障概率pt,i趋近于0。反之,故障敏感样本对应的概率趋近于1。γ为调节因子,通过改变其数值,可以影响概率曲线的分布情况,本文设置为2。基于上述分析,构造每个深度特征的静态权重因子如下:

式(17)的意义在于,满足Dt,i>Dlim,i条件的特征被定义为故障敏感特征,其相应的权值大于1,具体权值大小取决于故障概率。否则,非敏感特征的权值设为1,即保持原先的影响程度。基于此权重因子,重新构造加权后的监控指标SDt如下:
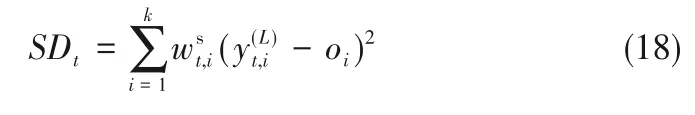
上述加权方法仅仅考虑了单个样本点的变化,是一种静态数据处理方法。实际工业过程中,系统本身固有的惯性导致故障影响是逐渐出现的,是一个动态过程。此时,仅仅考虑单个样本点就不能及时发现系统的变化。针对该问题,进一步设计动态加权方案,综合考虑历史样本的影响来确定故障程度。对于t时刻的测试样本xt,采用滑动窗方式建立一个长度为d的历史窗口{Dt-d+1,i,Dt-d+2,i,…,Dt,i},根据该窗口的动态数据对当前的监控指标进行估计


3 仿真验证
本节使用标准测试工业过程Tennessee Eastman(TE)系统对所提出的方法进行性能验证。TE 系统源自一个真实的化学工业过程[26],主要包含五个操作单元:反应器、冷凝器、循环压缩机、分离器和汽提塔(图3)。反应物A、B、C、D 和E 进入到反应器内发生不可逆的放热反应,出口产物通过冷凝器进行冷却,然后进入分离器。分离得到轻组分物料经过压缩机返回到反应器,分离器的重组分液体流入汽提器,最后得到产物G、H 以及副产品F。目前该系统已经成为一个测试控制和诊断方法的基准系统,在许多研究中得到广泛应用[27-30]。
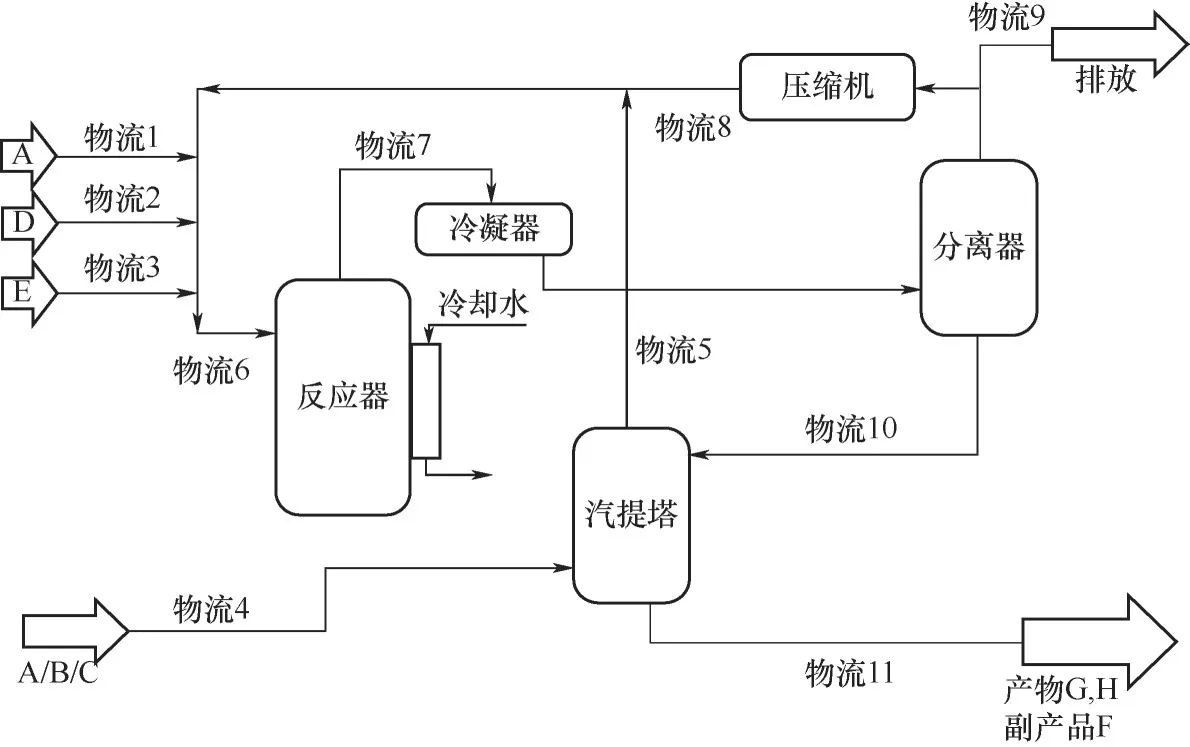
图3 TE过程流程图Fig.3 Flowchart of TE process
TE 过程仿真过程中采集了52 个变量,包括41个测量变量和11个操作变量。除正常工况外,还设计了21 种故障操作模式。本文选择9 种故障模式用于算法测试,如表1 所示。所有的数据集均包含960个样本,其中故障数据集在第160个样本之后引入故障。

表1 用于算法测试的故障Table 1 Faults for algorithm testing
本节分别使用了SVDD、DSVDD、SWDSVDD、DWDSVDD 四种方法来监控系统故障,SDSVDD、DDSVDD 分别表示静态和动态加权后的DSVDD 模型。SVDD 模型中的惩罚因子C设为0.05,DSVDD模型采用52-36-18 三层结构,网络惩罚系数λ设为0.0001,DDSVDD 中的滑动窗长度设为30。不同方法的监控性能主要通过故障检测率和误报率来评价,其中检测率定义为超出阈值的故障样本占所有故障样本的百分比,误报率定义为超出阈值的正常样本占所有正常样本的百分比。一个良好的监控方法应该具有高检出率与低误报率。需要注意的是,深度模型的结构设计在目前仍然是一个开放性问题,对于如何确定模型深度并没有统一结论。实际应用中,模型的深度应该与建模数据量相匹配,并非越复杂越好。
以故障IDV10 为例,该故障为C 进料温度的随机波动故障。当该故障发生时,四种方法的监控效果如图4所示,其中实线为监控指标,虚线为监控阈值。图4(a)中,SVDD 方法的故障检测率为59.38%,有约40%的故障样本被漏报。进一步结合深度学习技术,DSVDD 方法将故障检测率提高到78.63%,如图4(b)所示。然而,DSVDD 方法的误报率也有所提升,相比于SVDD 的1.88%,DSVDD 的误报率达到了5.63%。考虑到本文采用95%控制限,5%的误报率仍然符合统计假设。通过应用静态加权技术,图4(c)中SWDSVDD 方法将故障检出率提高到83.13%,但是误报率也增加到了10%。虽然总体上故障检测效果得到了提升,但是误报率的升高是不符合期望要求的。出现误报率升高的原因在于,静态加权方式仅仅考虑当前时刻的数据波动,易于放大过程噪声的影响。本文提出的动态加权方法DWDSVDD 能够有效克服这个问题,DWDSVDD 通过综合考虑滑动窗口内的历史信息设计权值,能够更为客观反映故障灵敏程度。图4(d)显示,DWDSVDD 将故障检出率提高到95.25%,且该方法的故障误报率仅为5.63%。

图4 不同方法对故障IDV10的监控效果Fig.4 Monitoring charts for fault IDV10 based on different methods
以故障IDV19 为例,该故障为一个未知类型故障(由于技术原因开发人员未公布其具体信息,仅仅提供故障数据)。对故障IDV19 的监控结果如图5 所示,从图中可以看出DSVDD 方法能够比基本的SVDD 更为显著地检测到故障,两者对应的故障检测率分别为62.5%、16.5%,检测率提升了46%。静态加权和动态加权方法均能进一步增强DSVDD 的监控效果,其中SWDSVDD的检测率达到了70.75%,动态模型的检出率达到了95.63%。这个故障监控效果进一步说明了本文所设计方法的有效性。

图5 不同方法对故障IDV19的监控效果Fig.5 Monitoring charts for fault IDV19 based on different methods
为进一步分析特征加权策略可以改进监控性能的原因,将第1 个和第7 个深度特征对应的监控成分Dt,1、Dt,7绘制于图6中。前160个样本为正常样本,后800 个样本为故障样本。从图6(a)可以看出,故障7 发生后,Dt,1未受到显著的影响,但是Dt,7却发生了显著变化,对应着故障敏感特征。在图6(b)中应用静态加权策略时,SDt,1总体没有显著变化,但是对个别样本点进行了加权处理,SDt,7相比于Dt,7则幅值显著改变,这是静态权重因子对故障敏感特征的影响所致。图6(c)中非敏感DDt,1与Dt,1的曲线几乎完全相同,但是敏感特征DDt,7则能比SDt,7更好地反映故障信息,这说明动态加权策略能够更好地区分敏感和非敏感特征,从而提高故障敏感程度。

图6 加权前后的深度特征对比分析Fig.6 Deep features comparison before and after weighting
表2 和表3 中列出了本文中4 类方法对所有9种测试故障的故障检测率和误报率结果。总体上看,DSVDD 比SVDD 平均检测率提高了约20%,静态方法SWDSVDD 则进一步提升平均检测率4%左右,而动态方法DWDSVDD 比静态方法的平均故障检测率高出约10%。在误报率方面,SVDD、DSVDD、DWDSVDD 有相似的平均故障误报率,均在5% 附近,符合95% 的统计学意义。但是SWDSVDD 的平均误报率为10.14%,远远超出了5%,这是该方法仅仅考虑静态变化的加权策略放大噪声的原因。动态加权方法DWSVDD利用了滑动窗内的历史动态信息判定故障敏感特征成分,能够降低过程噪声的影响,从而保证较低的故障误报率。

表2 故障检测率比较Table 2 Comparison of fault detection rates

表3 故障误报率比较Table 3 Comparison of false fault alarming rates
本文中涉及两个重要参数:式(16)中的调节因子γ、式(19)中的窗口宽度d,下面依次分析其对监控效果的影响。调节因子γ主要用于平衡故障检测率(FDR)和故障误报率(FAR)两类性能指标的性能。分别设置调节因子为0.5、1、2、4、8、16,将平均监控结果列于表4 中。可以看出,当γ为0.5 时,SWDSVDD 方法具有最高检测率86.68%,但是此时误报率也很高,FAR 为14.93%。增加调节因子γ数值,可以有效减少误报,γ=16时,FAR降为5.21%,但此时的故障检测结果也较差,FDR 降至79.97%。在DWDSVDD 方法中,由于动态权值计算对原始的概率数值进行了规范化处理,使得调节因子的影响反转。当γ设为0.5 时误报率最小,FAR 为5.28%,同时检测率FDR 也较小,为93.21%。当增加调节因子数值时,故障检测率略有上升,同时也伴随误报率上升。需要注意的是,DWDSVDD 方法对该系数的敏感性明显降低,FDR 和FAR 的波动很小,这也说明了动态加权方法的有效性。综上,改变调节因子γ改善一方面性能的同时,必然会以降低另一方面性能为代价。所以,在实际中应进行综合多方面影响进行权衡。

表4 不同调节因子情形下的平均监控效果Table 4 Average monitoring results under different tuning factors
为了验证滑动窗口宽度d对检测效果影响,分别设置其参数值为5~50,计算对9 种故障的平均监控效果。从图7 中可以看出,随着窗宽d的逐渐增加,误报率FAR 逐渐降低,同时检测率FDR 逐渐升高。因此,动态数据窗的引入有助于提升监控效果。但是当窗宽d大于30 以后,FAR 和FDR 逐渐趋于稳定数值,不再显著提升,所以无需引入过多的历史数据增加在线计算量。综合而言,窗宽d设为30是一个相对合理的选择。

图7 窗宽对DWDSVDD监控效果的影响Fig.7 Influence of window width on the DWDSVDD monitoring results
4 结 论
针对复杂工业过程故障监控问题,提出了一种基于深度学习框架的深度加权SVDD 故障检测方法。相比于传统的SVDD 方法,该方法从模型结构、优化目标、检测阈值等多个方面进行了改进,并针对深度特征的故障敏感性差异这一现象,进一步设计了特征加权层,提出了静态和动态加权因子突出敏感特征在监控指标中影响力。在TE 过程的测试结果表明,深度学习策略能够有效改进传统SVDD的监控效果,动态加权策略能够在确保合理的故障误报率的前提下较好地提升故障检测率。虽然本文提出的方法表现出较好的性能,但是仍然存在一些值得深入研究的问题,如深度网络结构的设计、针对微弱故障的检测策略改进等。
