基于改进Faster RCNN的目标检测算法
2021-11-26鹿晓威吴晓翎
赵 俊,鹿晓威,赵 骥,吴晓翎
(1.中钢科技发展有限公司 运营管理部,北京100080;2.辽宁科技大学 计算机科学与工程学院,辽宁 鞍山114051)
目标检测就是从背景信息中检测、提取、分割出目标,对输入图像中的目标进行快速准确表达和精确定位,为目标信息的读取与理解奠定基础,为目标识别提供有力的数据资源支持[1]。在传统的目标检测方法中,通常采用Histogram of Oriented Gradient(HOG)特征[2]或是Haar特征[3]、Scaleinvariant feature transform(SIFT)特征[4]进行特征提取。这些方法在检测时采用比例不一的滑动窗口对整个图像加以遍历,再使用Support Vector Machine(SVM)分类器[2]、AdaBoost分类器[5]对每一个窗口内的目标分类,这种穷举的方式将会耗费大量的时间。多尺度形变部件模型Deformable Part Model(DPM)[6]在保留HOG+SVM优点的基础上进行扩展,在人脸检测、行人检测上取得一些成就,但是DPM相对复杂,检测效率低,很快被基于深度学习的目标检测方法取代[7-8]。2014年,Facebook人工智能实验室FAIR的Girshick Ross,首次将深度学习引入目标检测算法中,提出区域卷积神经网络(Regions with CNN features,RCNN)[9]。RCNN虽然可以较好地完成目标检测任务,但是缺点也是很明显的。第一,RCNN的训练是分多个阶段进行的:首先需要训练一个用于提取图像特征的CNN,然后训练若干用于物体检测的SVM,最后进行边框回归;其二,RCNN开销非常大,对于每一个推荐区域都要提取一次特征,而推荐区域间有大量的重叠,致使检测的时间漫长。鉴于此,Girshick于2015年提出了改进的目标检测方法Fast RCNN[10],Fast RCNN不再是对每个推荐区域(Region of interest,RoI)逐一提取特征,只需要对整张图片进行一次特征提取,同时不需要对SVM分类器以及边框回归进行单独训练,训练效率有所提高。Fast RCNN虽然在RCNN的基础上性能提升了不少,但二者均依赖选择性搜索(Selective search,SS)[11]的区域推荐算法来寻找推荐区域,目标检测也因此被分成两个串行的阶段,影响检测效率。基于此,2015年Ren等又提出了新的检测方法Faster RCNN[12],Faster RCNN在借 鉴Fast RCNN特点的基础上,采用区域建议网络(Region proposal network,RPN)直接预测出候选框产生推荐区域,同时RPN绝大部分对候选框的预测工作在GPU中完成,目标检测的速度也因此得到了大幅度的提升。
除了以上提到的基于候选区域的深度学习检测方法之外,还有无需区域建议的深度学习方法。Redmon等于2015年提出的YOLO(You only look once)目标检测方法[13],针对给定的图像划分网格,并在图像上的每个网格中设定包围框,设定阈值保留可能性较高的框并加以分类识别,速度明显提高,但是准确率却不太理想。2016年,Liu等又提出了SSD(Single shot multibox detector)算法[14],参考Faster RCNN的Anchor机制,引入多尺度的概念,由于其固定了默认框的形状以及网格大小,导致SSD算法检测小目标物体的效果不够理想。
本文首先将Faster RCNN中用于提取图像特征的VGG16网络替换为具有更强表达能力且层次更深的残差变换聚合深度网络(Aggregated residual transformations for deep neural networks,ResNeXt),能够更完整地学习目标特征;其次,采用具有101层的ResNeXt网络对图像特征进行提取;然后,改变残差单元结构,将常规的“后激活”方式更改为“预激活”方式,使得网络在前向以及反向传播过程中更为畅通;最后,引入自动可变形卷积,卷积核的大小和位置会根据当前需要识别的图像内容进行动态调整,从而能更好的适应物体形状、大小等发生几何形变的目标检测任务。
1 深度残差网络模型
深度残差网络(Residual neural network,ResNet)[15]在标准的前馈神经网络上加一个“跳跃”引入恒等映射,解决了退化问题,同时也解决了梯度弥散的问题,整个网络性能大大提升。
1.1 残差单元
残差单元是ResNet的基本构成单元,结构如图1所示。残差单元的数据通过两条路线进行传输,其中一条与一般网络类似,经过两个卷积层再进行传递输出,另一条则是实现单位映射的直线连接。残差单元的两个主要设计:快捷连接和恒等映射,二者结合完美解决了随着网络的加深准确率下降的问题。

图1 残差单元Fig.1 Residual unit
恒等映射即曲线x,快捷连接即残差部分为F(x)。其中,x代表某段神经网络的输入,H(x)表示期望输出,通过梯度下降方法直接求H(x),会面临网络退化问题。当假设F(x)=0,输入x将直接传到输出作为下一阶段的初始输入,网络则变成了恒等映射,相当于在一个准确率达到饱和的浅层网络的基础上继续叠加y=x的恒等映射层,该举措达到了随着深度加深网络性能不发生退化,训练误差不会增加的目的。
1.2 ResNeXt网络
本文以ResNeXt为前置网络的深度学习模型,用于目标检测中目标特征的提取,使得目标的特征学习更加完全。
ResNeXt网络架构采用一种平行堆叠且具有相同拓扑结构的block,同时引入“基数”(独立路径的数量)的超参数。图2展示了ResNet和ResNext构建块的基本结构。
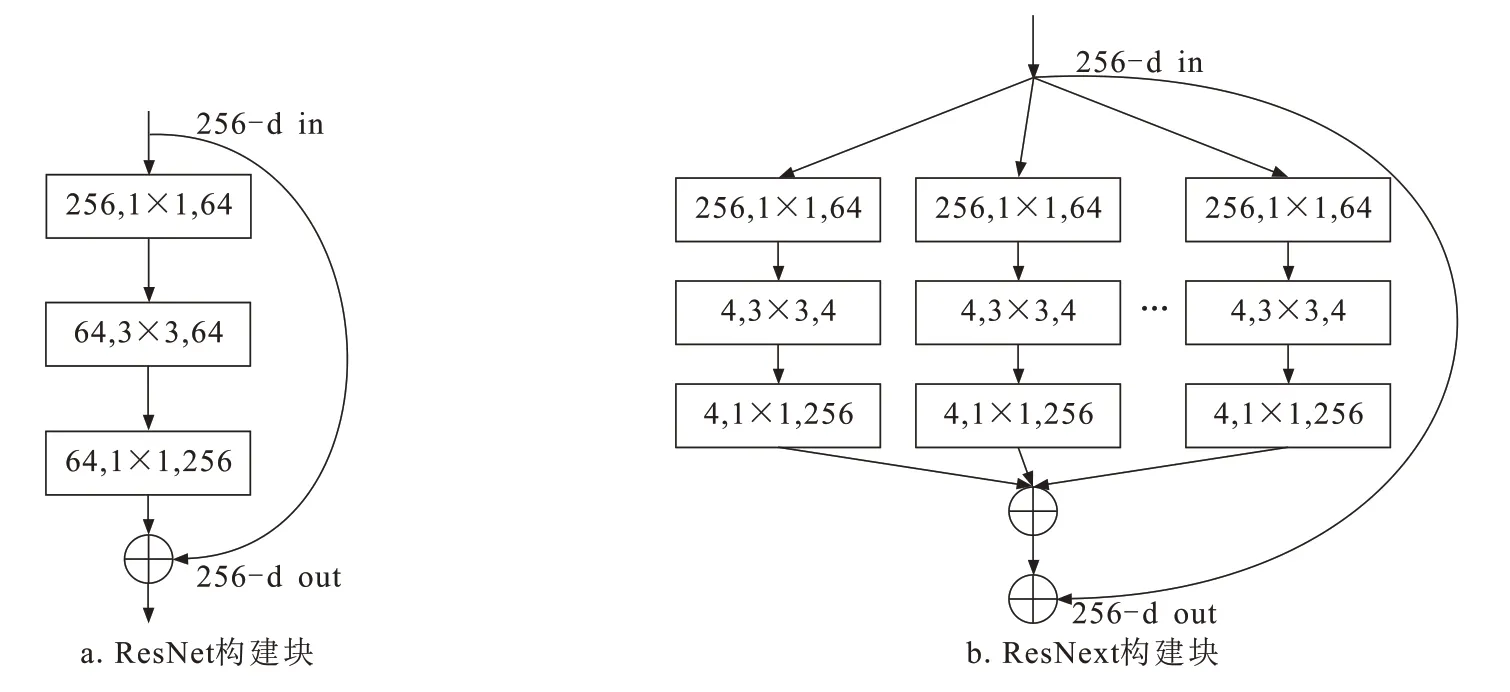
图2 ResNet与ResNext构建块Fig.2 Building blocks of ResNet and ResNext
ResNeXt网络结构保留了ResNet网络的基本堆叠方式的同时,将ResNet的单个路径拆分为32条独立路径,这32条路径同时对输入图像进行卷积操作,最后将来自不同路径的输出累计求和作为最终的结果。这一操作使网络的分工更明确、局部适应性更强。由于每条路径共用相同的拓扑结构、卷积参数,设计方式一致,因此网络参数并不会增加,便于模型移植。
2 模型设计与实现
2.1 网络层数的选取
为了使网络的性能更优,本文分别对不同深度的ResNeXt网络,在测试集和验证集进行了相关错误率的检验。随着网络深度的不断加深,网络出现的错误率呈现稳步下降趋势,101层和152层的ResNeXt网络在训练错误率上相差无几,但是152层的网络参数却比101层的网络增多近一倍。综合权衡网络的正确率和训练耗费时间,本文最终采用101层的ResNeXt网络作为提取目标特征的前置网络。
2.2 残差单元结构
为了对残差单元有更深入的了解,本文对残差单元的内部结构进行剖析。图3是残差单元的内部构造。常规的残差单元结构有两个特点,BN层、ReLU层和Conv层的顺序是Conv-BN-ReLU;第二个ReLU层要在addition之后。

图3 常规的残差单元结构Fig.3 Traditional residual unit structure
常规的残差单元的输出为

式中:yl为第l个残差单元的输出;h(Xl)为恒等映射;F(Xl,wl)为残差;f为ReLU激活函数;Xl是第l个残差单元的输入;Xl+1是第l+1个残差单元的输入;wl是第l层的参数。
对式(1)和式(2)整合得到

前向传播以及反向传播的信号都能直接从一个单元传播到另一个单元,但是在进行相加操作的后面还存在ReLU激活函数。该激活函数的存在会影响残差单元的两个分支,导致前向以及反向传播的信号只能在两个残差单元之间直接传播。针对这一缺点,将残差网络基本单元结构进行了重新设计,将ReLU激活函数移到残差函数分支上,把BN和ReLU都移到权值层之前构造恒等映射f(y)=y,形成一种“预激活”的方式[16],而不再是常规的“后激活”方式,因此快捷连接分支将不会受到影响。改进后的残差单元结构如图4所示。
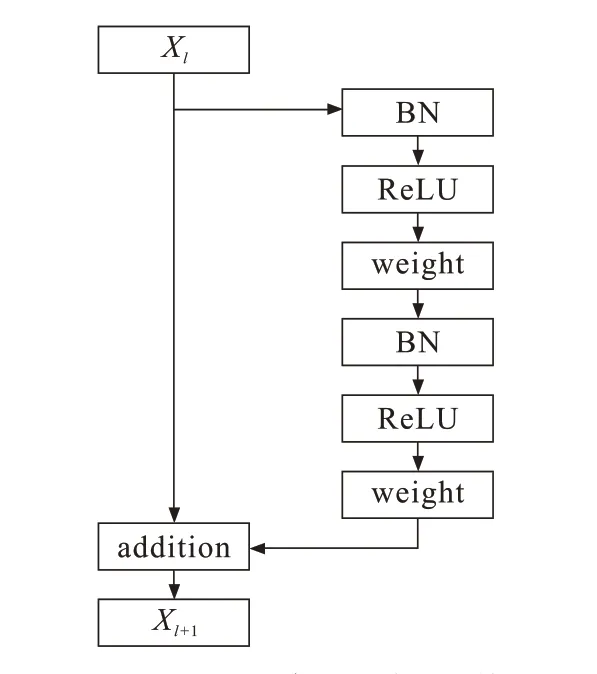
图4 改进后的残差单元结构Fig.4 Improved residual unit structure
结构改进后,残差单元的输出为

常规单元结构网络在起始阶段误差下降很慢,是因为当ReLU激活函数信号为负时传播会被截断,使模型无法很好地逼近期望函数;改进后的结构中,信息不仅能在相邻的两个残差单元间“直接”传播,而且在整个网络中信息都可以“直接”传播,网络也因此更容易训练。同时,Batch normalization(BN)层对卷积层的输出做批量归一化处理,进一步防止由于网络过深而引发的梯度弥散问题。
更改后的残差单元结构中的XL可以看作是Xl和残差ε的累计,实现了真正意义上的残差,改进后单元结构的残差计算式
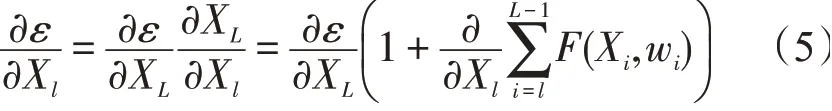
网络在执行反向传播操作时,∂Xl/∂XL梯度可以完全回传,并且信息传递更畅通。
2.3 自动可变形卷积
目标在图像中通常呈现出不同的大小、不同的姿态甚至不同的角度。在检测此类目标时,传统的网络完全依赖于训练数据集本身所具有的多样性,而不是网络模型内部所具有的应对机制。
在每个卷积核的采样点上添加一个偏移变量Δpn[17],给予卷积核形变的特性。加上该偏移的变量后,网络会根据反向传播的误差学习偏移量,自动地对卷积核的形状进行调整。因此,可变形卷积核的大小和采样点的位置,可以依照图像内容进行动态调整,而不再局限于之前的规则格点,进而网络模型可以凭借自身的内部机制增强空间几何形变的适应能力。
图5 以一个3×3卷积核为例,其中空心点表示大小为3×3的卷积核的9个采样点,箭头表示可变形卷积中增大的偏移量,实心点表示变形后采样的位置。网络会根据原采样点的位置,学习一个偏移量Δpn,得到新的卷积核。

图5 常规卷积和可变形卷积目标的检测Fig.5 Traditional and deformable convolution target detections
首先需要从输入图像或者特征图X上采样9个位置,传统卷积神经网络中这9个采样点的位置是固定不变的,集合R定义了感受野的大小,用于在输入特征图X上采样。

式中:(-1,-1)代表X(p0)左上方的采样点;(1,1)代表X(p0)右下方的采样点。
对于输出特征映射y上的每个像素p0而言,得到
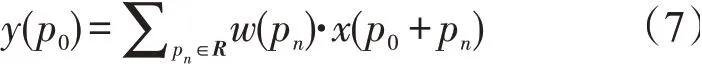
式中:pn枚举了R中的位置;y(p0)输出特征映射y上的每个位置p0;w是权值;x(p0+pn)是p0+pn位置的输入特征映射。
对于自动可变形卷积而言,需要在输入图像以及特征图X上采样9个点,在每一个pn上增加一个偏移量Δpn,集合R中元素通过偏移量{Δpn|n=1,…,N}变化(其中,式(7)变为

如此一来,采样将发生在具有偏移量的不规则的位置上。
可变形卷积单元有以下几点优势:首先,可变形卷积是卷积的一般化,它不仅可以定义所有传统的卷积,可以自由地改变卷积的形状,这为形成CNN结构提供了更大的自由度;其次,卷积核的形状是不需要手动调整而是在反向传播中学到的;最后,可变形卷积对图像的适应性比常规的卷积操作更强。
3 实验结果与分析
为了体现本文算法的优越性,分别与传统的目标检测算法DPM、Faster RCNN、SSD进行比较。为了验证改进网络模型的有效性以及鲁棒性,本文将分别对呈现不同旋转角度的图像和存在严重遮挡、检测目标不完整的图像进行检测。
3.1 数据集
在检测工作开始前,需要在ImageNet的物体分类数据集上做预训练,将预训练模型的参数作为目标检测模型的初始化参数,使用Pascal_VOC(Pattern Analysis Statistical Modelling and Computational Learning,Visual Object Classes)数据集[18]对预训练模型进行微调。该数据集包含了人、交通工具、动物、室内物品四大类共20个细分类的图像数据,训练集和测试集总计包括17 125张图像。
3.2 不同旋转角度
将待检测图像进行旋转,使得图像中的目标呈现出不同的角度,以此作为目标发生几何形变的代表。检测结果如图6所示。DPM算法对发生形变的目标适应性不强,只检测出目标的局部;SSD算法在检测紧凑的多目标时,没有将独立的目标分别检测出,而是框取了整张图作为最终的检测结果,且标签概率值很低;Faster RCNN对不同旋转角度的目标存在大量漏检、检测不完整等诸多糟糕的情况。由于本文算法引入了可变形卷积,可以根据当前需要识别的图像内容进行动态调整,因此对发生角度旋转变化的图片仍保持着较强的适应性。

图6 旋转角度的目标检测结果Fig.6 Detection results of rotated targets
从检测结果中可以看到,每个算法对“猫”的检测效果都很好,这是因训练集中“猫”的图像多样性。验证了传统网络对不同姿态的目标的应变能力完全来源于训练数据集本身的多样性这一说法。
3.3 目标遮挡
为了检验本文算法对检测被遮挡的目标的适应能力,人为的用方框将图中的目标进行不同程度的遮盖,其中最大遮挡率达到50%。四种算法的检测结果如图7所示。

图7 存在遮挡的目标检测结果Fig.7 Detection results of partially blocked targets
DPM算法的检测结果仅标注出了目标的局部;SSD算法对遮挡面积小的目标表现良好,但对遮挡面积较大的目标却无法准确检出;Faster RCNN算法只能确定目标的大体位置,但目标检测不完整,甚至出现误检为两个目标的情况;相比而言,本文的检测效果相对理想,这是因为本文算法不但能够很好地学习目标细小的特征,而且对目标整体的特征也能保证良好的学习效果。
4 检测结果评价
本文依据评价标准,客观地评价各种算法在检测目标时的准确性。
目标检测不但要识别出候选框里面的物体,还需要定位出物体候选框的精确位置,二者共同决定了目标检测的准确性,通常用平均精度均值(Mean average precision,MAP)表示,MAP值实质上是指P-R曲线与坐标轴所构成的面积,该面积越大,则说明算法性能越优。
P-R曲线图通常是以召回率R为横轴,准确率P为纵轴进行绘制,二者的关系呈现出负相关。准确率P计算式

召回率R计算式

式中:TP代表被正确检测出的数目;FP代表被错误检测的数目;FN代表漏检的数目。
图8 为四种目标检测算法的P-R对比图。随着R值增大,四种算法的P值都下降。当R小于0.4时,本文算法的P值稍低于Faster RCNN算法;当R大于0.4时,本文算法的P值明显高于其他三种算法,MAP值最高,达到75.6%,表明本文算法的性能更具有优越性。
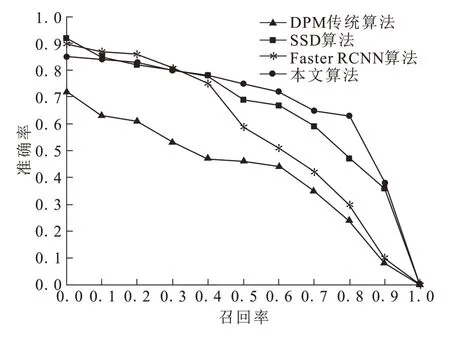
图8 准确率-召回率曲线图Fig.8 Curves of precision rates and recall rates obtained by different algorithms
5 结论
本文参考当前最新型的网络以及各领域的先进理论技术,结合深度学习知识在FasterRCNN算法的基础之上进行改进。改进算法对小目标、发生形变的目标以及重叠度大的目标检测有很好的检测效果。通过实验验证了改进模型在检测有遮挡和分辨率低以及不同旋转角度等目标时具有更强的鲁棒性。对测试图像进行了准确性对比分析,本文算法的平均精度达到75.6%,优于其它模型,有较大的实用性。
