基于图像级标签的弱监督图像语义分割综述
2021-11-25谢新林尹东旭续欣莹刘晓芳罗臣彦
谢新林,尹东旭,续欣莹,刘晓芳,罗臣彦,谢 刚,
(1.太原科技大学 电子信息工程学院,太原 030024;2.先进控制与装备智能化山西省重点实验室,太原 030024;3.太原理工大学 电气与动力工程学院,太原 030024)
图像语义分割旨在自动识别图像中每一个像素的类别标签,是计算机视觉领域的一个基础研究问题,具有非常重要的理论研究价值。相比于单一的图像处理任务,图像语义分割能够同时实现对目标的分割和识别,可以为后续的图像分析和理解等视觉任务提供细粒度和高层次的语义信息。作为近几年计算机视觉领域的热点研究问题之一,图像语义分割还具有广泛的应用前景和重大的社会意义,是自动驾驶、机器人感知、3D城市建模、无人机应用、智能交通、智能医疗和遥感影像分析等应用场景的核心技术[1-3]。
近年来,受益于像素级标签标注的训练数据和深度卷积神经网络(deep convolutional neural network,DCNN)模型的广泛应用,图像语义分割方法的识别精度获得了显著的提高[4-5]。然而,基于深度卷积神经网络的图像语义分割方法依赖于大规模精细到像素粒度的训练数据。这种费时费力和高代价的大规模像素级标签标注工作严重制约了图像语义分割性能的进一步提升和实际应用的可扩展性。为了解决上述不足和局限性,基于图像级标签的弱监督图像语义分割受到了众多研究人员的关注,并成为近几年计算机视觉领域的一个热点研究课题。
图像级标签标注仅需要给出场景图像中存在的具体目标类别信息,并不需要指出目标类别在图像中的位置信息。图像级标签标注与像素级标签标注的对比示意图如图1所示。相比于像素级标签,图像级标签可以被准确和高效标注,这极大地减少了数据标注的时间和代价。例如,高质量像素级标签的人工标注大约需要几分钟或者十几分钟的时间,而图像级标签的时间标注代价仅需要几秒或几十秒[6]。此外,大规模基于图像级标签的训练数据可以从在线的多媒体分享网站(Flickr,Picasa和Zooomr)中被快速和方便获取,这极大地缓解了训练数据规模不足的问题。例如,Flickr网站中存在大量带有用户提供标签的社交图像未被充分利用[7]。

图1 图像级标签标注与像素级标签标注对比示意图Fig.1 Annotation comparison of image-level labels and pixel-level labels
尽管基于图像级标签的弱监督图像语义分割在标注代价和训练数据获取方面具有优势,但是图像级标签相比于像素级标签或者其它形式的弱监督标注,其包含的有指导性和有监督的信息最少,面临的挑战和难度也最大。主要表现在:1) 图像级标签没有提供标签类别在图像中的位置信息和边界信息;2) 图像级标签无法提供适用于现有深度卷积神经网络模型所需的像素级标签标注数据。因此,如何从图像级标签推断出高质量和稠密的位置信息,进而基于推断的伪标签数据构建图像语义分割网络是当前基于图像级标签的弱监督图像语义分割面临的关键和难点。此外,实际场景图像往往包含多个目标类别和复杂背景,且各目标类别具有多样性的外观、姿态、视角、尺度和纹理等特征,进一步加剧了图像级标签位置推断的难度。
根据标签位置推断方式的不同,现有基于图像级标签的弱监督图像语义分割可以划分为基于超像素的方法和基于分类网络先验的方法,如图2所示。其中,基于超像素的方法主要是以超像素分割产生的超像素或者超像素合并产生的候选区域为处理单元进行图像级标签位置推断,然后基于推断的伪标签数据构建分类模型。其原理依赖于多个图像中具有相似视觉特征的超像素或者候选区域具有相同的类别标签。该类方法以超像素或者候选区域为处理单元,能够显著提高算法的计算效率,并有助于提高图像级标签位置推断的精度。但是,基于超像素的方法依赖于超像素分割和超像素合并产生的初始分割区域的精度,且易受噪声标签和背景复杂性的影响。

图2 基于图像级标签的弱监督图像语义分割方法Fig.2 Weakly-supervised image semantic segmentation method based on image-level labels
基于分类网络先验的方法主要是借助类激活图(class activation maps,CAM)定位网络[8]或者其它目标识别领域预训练好的分类网络来产生具有判别性的初始种子区域,然后通过扩张非判别区域的类别标签来实现图像级标签位置推断,并基于扩张后的伪标签数据作为强监督信息训练图像语义分割网络。该类方法的关键在于引入类激活图定位网络或者其它预训练好的分类网络(全卷积网络、卷积神经网络、显著性检测或者注意力机制等)等先验信息来产生具有判别性的初始种子区域。然而,类激活图定位网络或者其它预训练好的分类网络仅能够识别图像中一些稀疏的高响应判别区域,且缺乏对目标区域所在边界的精确描述。
1 基于超像素的弱监督图像语义分割方法
基于超像素的弱监督图像语义分割方法可以划分为以超像素为处理单元的方法和以候选区域为处理单元的方法。基于超像素的弱监督图像语义分割方法的核心环节包括:1) 超像素或者候选区域的高精度分割;2) 以超像素或者候选区域为处理单元的图像级标签位置推断;3) 基于推断的伪标签数据进行分类模型的学习。相比于以像素为处理单元的推断方式,基于超像素的弱监督图像语义分割能够以数量较少的超像素或者候选区域为处理单元进行图像级标签位置推断,有助于提高算法的推断效率和精度,并能减少噪声像素对于图像级标签位置推断的干扰。
1.1 以超像素为处理单元的方法
以超像素为处理单元的方法通过超像素分割来产生具有高边缘贴合度的超像素,主要包括基于图模型的方法和基于聚类的方法。其中,基于图模型的方法主要是借助条件随机场(conditional random fields,CRF)或者马尔可夫随机场等图模型来构建分类模型。其中,在融合条件随机场的方法中,VEZHNEVETS et al[9-10]分别采用TURBOPIXELS[11]和FH[12]超像素分割算法来产生超像素,并分别基于主动学习和贝叶斯优化来提高算法的分割精度;XING et al[13]采用SLIC[14]超像素分割来产生不同尺度的超像素块,并利用超像素嵌入来构建条件随机场的势函数;韩铮等[15]利用朴素贝叶斯来估计超像素标签的概率,提出了一种基于纹元森林和显著性先验的弱监督图像语义分割方法;ZHANG et al[16]利用卷积神经网络(convolutional neural network,CNN)提取多尺度的超像素特征,并利用条件随机场来构建上下文信息。此外,SHI et al[17]面向基于目标和属性的弱监督标注,构建了基于马尔可夫随机场的超像素之间的关联性;VEZHNEVETS et al[18]基于超像素的外观相似性,通过构建多图模型来恢复训练图像的像素级标签;ZHANG et al[19]由图像级标签构建超像素集的空间结构分布提出了一种基于图割的方法;XU et al[20]利用图模型来编码类别的出现与缺失,并对超像素的语义标签进行分配。
基于聚类的方法主要是基于超像素之间的特征相似性将不同图像中具有相同视觉特征的超像素通过聚类的方式进行划分,进而实现超像素级的标签位置推断。例如,LIU et al[21]利用谱聚类对过分割的超像素集进行聚类,提出一种基于线性变换的判别特征提取方式;LIU et al[22]还提出一种多示例多标签学习用于划分超像素到不同的聚类分组;YING et al[23]通过谱聚类和判别聚类构建以超像素为处理单元的子集,提出一种基于词典学习的弱监督多元聚类方法;POURIAN et al[24]应用谱聚类的图划分方法分离出具有高相关性的超像素;ZHANG et al[25]利用稀疏重构来实现超像素集的划分,并采用迭代合并更新的方式获得分类模型的最佳参数。
然而,以超像素为处理单元的方法依赖于超像素分割算法的分割精度,且易受超像素特征表示能力的影响。此外,以超像素为处理单元的图像表示和标签位置推断方式,依然存在大量具有相似特征的冗余超像素,这会干扰超像素标签的位置推断。相比于基于分类网络先验的方法,以超像素为处理单元的方法大都仅依赖图像级标签的弱监督指导信息,并未引入其它额外的先验信息。因此,以超像素为处理单元的弱监督图像语义分割方法的分割精度相对较低,且难于实现端到端的训练。以超像素为处理单元的弱监督图像语义分割方法的总结如表1所示。

表1 以超像素为处理单元的弱监督图像语义分割方法Table 1 Weakly-supervised image semantic segmentation method using superpixel as processing units
1.2 以候选区域为处理单元的方法
以候选区域为处理单元的方法主要是通过超像素合并的方式来实现候选区域的分割,并以数量较少的候选区域块为处理单元进行图像级标签位置推断和分类模型学习。例如,LIU et al[30-31]合并FH[12]超像素分割产生的小图像块到候选区域,并利用稀疏编码来推断图像级标签的区域语义信息;LI et al[32]利用条件随机场模型合并SLIC[14]超像素分割产生超像素,并基于候选区域库来构建分类模型;XU et al[33]和LU et al[7]采用局部搜索算法对MCG[26]产生的超像素进行合并,分别构建了面向图像级标签、边界框和部分标签等弱监督标注形式的分割模型和标签噪声约简模型。
以候选区域为处理单元的方法依赖超像素合并生成的候选区域的分割精度。相比于以超像素为处理单元的方法,以候选区域为处理单元的方法能够进一步减少标签位置推断过程中的冗余信息和计算代价。然而,如何自动地确定超像素合并过程中的终止条件,进而自适应地确定候选区域的分割数量是以候选区域为处理单元的方法面临的一个瓶颈问题。以候选区域为处理单元的弱监督图像语义分割方法的总结如表2所示。

表2 以候选区域为处理单元的弱监督图像语义分割方法Table 2 Weakly-supervised image semantic segmentation method using candidate region as processing units
2 基于分类网络先验的弱监督图像语义分割方法
基于分类网络先验的弱监督图像语义分割方法可以划分为基于类激活图(class activation maps,CAM)定位网络[8]的方法和基于其它分类网络的方法。基于分类网络先验的弱监督图像语义分割方法的核心环节在于:1) 基于类激活图定位网络或其他分类网络模型产生判别性稀疏种子区域;2) 判别种子区域到非判别种子区域的挖掘与扩张;3) 融合判别区域和非判别区域的伪标签数据构建分割网络模型。相比于基于超像素的弱监督图像语义分割方法,基于分类网络先验的方法由于额外先验信息的引入,能够显著提高当前基于图像级标签的弱监督图像语义分割方法的精度和性能。
2.1 基于类激活图定位网络的方法
基于类激活图定位网络[8]的方法依赖类激活图定位网络来产生具有判别性的稀疏种子区域,进而以判别性的稀疏种子区域作为先验信息指导图像级标签的定位,最后以种子区域扩张生成的伪标签数据构建语义分割网络模型。其中,ZHOU et al[8]提出的类激活图定位网络利用全局平均池化的方法来生成类激活映射图,并根据类激活映射图获取对分类具有判别性的区域,该方法意在定位出图像中具有判别力的深度特征区域。
在依赖类激活图定位网络[8]获得种子区域的基础上,依据种子区域生长方式的不同,基于类激活图定位网络的方法主要包括基于扩张网络的方法和基于显著性的方法。基于扩张网络的方法主要是通过构建种子区域扩张网络来高精度和稠密地扩张目标区域。例如,KOLESNIKOV et al[34]在种子、扩张和约束原则下提出了新的损失函数,并采用全局加权池化的方法来扩张种子区域,构建了基于全连接条件随机场的边界约束模型;ARASLANOV et al[35]同样构建了归一化全局加权池化来产生稠密的语义区域;SHEN et al[6]融合目标域和网络域的指导信息来逐步地挖掘细粒度的区域语义信息;SALEH et al[36]采用高水平卷积层网络来激活前景和背景标签;FAN et al[37]利用类内判别器来区分前景和背景信息;CAROLINA et al[38]构建了两个类激活图模型来恢复覆盖整个对象范围的激活掩码;WEI et al[39]通过设置不同的空洞卷积率转移判别信息到非判别目标区域;LI et al[40]通过设置背景类中不同比例的背景信息和堆叠来实现目标区域的定位,并采用期望最大化的方法来优化分割网络参数;ZHOU et al[41]构建了针对噪声标签的选择损失函数和注意力损失函数来定位图像级标签位置和改正分类错误;CHANG et al[42]通过引入子类别信息来增强分类网络的区域定位能力;WANG et al[43]利用成对的空间传播网络来细调单元势网络产生的每一个像素的类别标签;AHN et al[44]提出一种基于深度神经网络和随机场的亲和力网络来扩张目标区域;LEE et al[45]利用FickleNet来同时识别目标的判别区域和非判别区域;ZHANG et al[46]构建了解耦空间神经注意网络来同时识别目标区域和定位判别区域;LIU et al[47]构建了级联语义擦除网络来扩张种子区域到整个目标。基于显著性的方法主要是通过引入显著性机制来指导种子区域的扩张。例如,OH et al[48]利用显著性作为先验信息来指导种子区域的扩张;WANG et al[49]利用贝叶斯框架下的显著性图来细调目标区域,进而实现非判别区域的增补;SUN et al[50]利用自注意显著性和种子区域增长法来扩展像素级标签的范围。在其它基于类激活图定位网络的方法中,HUANG et al[51]使用区域增长法来扩张种子区域并将其整合到深度分割网络当中;WEI et al[52]提出一种对抗擦除的方法来逐步挖掘稠密和完备的目标区域;HONG et al[53]和LEE et al[54]利用网络上抓取的视频流信息来产生标签的定位图和伪标签数据。
基于类激活图定位网络的方法能够显著提高图像级标签的定位能力,但是基于类激活图的定位网络起初并非应用于语义分割任务。因此,基于类激活图定位网络的方法仅能够识别出图像中一些稀疏和不完备的判别性区域,即只能获得图像中显著目标的部分区域,这不能满足图像级标签位置的稠密推断和语义分割网络构建所需的大规模标注数据。此外,基于类激活图定位网络的方法易于产生不精确的边界和形状描述,因此还需要引入后续的精炼或者平滑模块来细调最终的分割结果。基于类激活图定位网络的弱监督图像语义分割方法的总结如表3所示。

表3 基于类激活图定位网络的弱监督图像语义分割方法Table 3 Weakly-supervised image semantic segmentation method based on localization network of class activation maps
2.2 基于其它分类网络的方法
基于其它分类网络的方法主要是通过引入全卷积网络[4](fully convolutional network,FCN)、卷积神经网络、显著性检测或者注意力机制等预训练好的分类模型来指导种子区域的产生和扩张,然后基于扩张后的伪标签数据进行分割网络的学习。在基于全卷积网络的方法中,PATHAK et al[55]利用全卷积网络来预测输入图像的标签类别信息,提出了一种基于约束卷积神经网络的弱监督分割模型;QI et al[56]利用全卷积网络来产生目标类的激活图,并融合目标定位网络和MCG[26]来产生像素水平的伪标签数据;TOKMAKOV et al[57]从视频水平的弱标注中学习运动信息来识别和扩张目标的区域及其边界。在基于卷积神经网络的方法中,PINHEIRO et al[58]利用预训练好的卷积神经网络来产生特征信息,并在训练的过程中分配对于分类图像具有重要作用的像素点更高的权重;ROY et al[59]利用卷积神经网络来预测图像级标签的类别信息,并以条件随机场为递归网络来产生平滑的分割。在基于显著性检测(salient detection,SD)的方法中,WEI et al[60]利用显著性目标检测技术从简单图像中挖掘显著性图,并利用增强深度卷积神经网络挖掘复杂图像当中的像素级标签;ZENG et al[61]构建了显著性聚合模块来聚合每个预测类别的分割掩码,并提出一种融合显著性检测和分割网络的联合学习模型。在基于注意力机制的方法中,FAN et al[62]使用示例水平的显著性目标检测技术来自动产生候选区域,并采用图划分的方式来构建用于分割网络的伪标签数据;LI et al[2,63]融合具有类别信息的注意力图和逐次擦除生成的显著图来生成用于训练分割网络的伪像素标签;WANG et al[1]提出自监督等变注意力机制来产生稠密的类激活图信息;XU et al[64]提出上下文传播嵌入网络来产生初始的视觉信息,该嵌入网络聚焦于相邻区域之间的语义关系学习。此外,WEI et al[65]利用Hypothesis-CNN-Pooling来预测目标类别的分类得分,并结合图像之间的上下文细调来产生目标定位图;JIN et al[66]利用网络图像中的上下文和先验信息,构建了浅层神经网络(shallow neural network,SNN)来获得每一个类别的分割掩膜。
基于其它分类网络先验的方法大都用于解决初始种子区域面积小和稀疏的问题,进而通过引入全卷积网络、卷积神经网络、显著性检测或者注意力机制等先验信息来挖掘更多具有判别性的目标区域。因此,该类方法能够提高初始种子区域的定位和扩张精度,进而能够获得比较好的分割性能。但是,基于其它分类网络先验的方法依然依赖于预训练好的分类网络模型的泛化性和可扩展性,同样需要增加后续的边缘处理模块来优化分割边界。基于其它分类网络的弱监督图像语义分割方法的总结如表4所示。
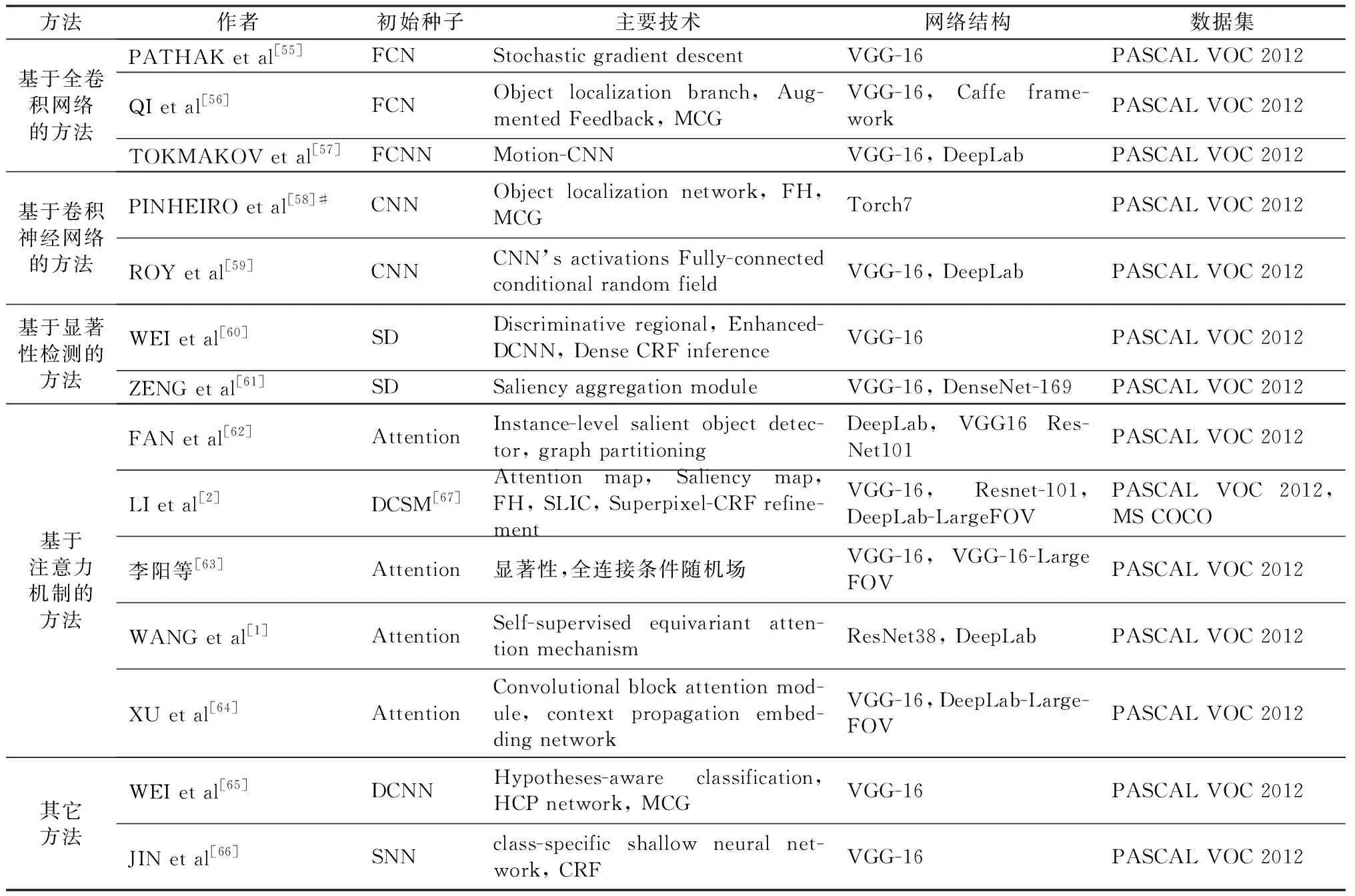
表4 基于其它分类网络的弱监督图像语义分割方法Table 4 Weakly-supervised image semantic segmentation method based on other classification networks
3 常用数据集与评价指标
3.1 常用数据集
3.1.1MSRC(microsoft research cambridge)数据集
MSRC[68]是由微软剑桥研究院建立的用于图像场景理解和物体分割的自然场景图像数据集,是最早被应用于验证弱监督图像语义分割方法性能的常用数据集之一。MSRC由591张320×213或者213×320像素的图像组成,共包含21个目标类,图像示例如图3(a)所示。MSRC数据集中平均每张图像包含3.5个目标类,且均对应有像素级标签标注的真值数据。在具体的验证过程中,通常将MSRC数据集划分为由276张图像组成的训练集和256张图像组成的测试集。此外,MSRC图像中的目标类面积较大,易于构建不同目标类之间的共生和关联关系。但是,MSRC数据集中的真值数据存在比较粗糙的边缘标注。
3.1.2PASCAL VOC 2012数据集
PASCAL VOC 2012[69]是当前基于图像级标签的弱监督图像语义分割领域使用最为广泛的自然场景图像数据集,该数据集极大地推动了图像语义分割领域的发展。PASCAL VOC 2012数据集包含20个目标类和1个背景类,由训练集(1 464张图像)、验证集(1 449张图像)和测试集(1 456张图像)三个图像子集构成,对应的图像示例如图3(b)所示。目前,主要以HARIHARAN et al[70]扩增后的训练集(10 582张图像)进行分类或分割网络的训练。PASCAL VOC 2012数据集主要涉及日常生活中的常见物体目标,图像中物体的尺度变化较大、背景复杂、图像大小不固定,且同一图片内的不同物体之间往往存在遮挡现象。
3.1.3MS COCO(microsoft common objects in context)数据集
MS COCO[71]数据集是当前弱监督图像语义分割和目标检测领域非常具有挑战性的自然场景图像数据集。其包含80个目标类和1个背景类,有123 287张用于测试和训练的图像(包含80 k训练集和40 k验证集),图像示例如图3(c)所示。MS COCO数据集主要是从复杂的日常场景中获取,且图像中的物体均具有精确的位置标注。
3.1.4Sift Flow数据集
Sift Flow[72]数据集是最早被应用于基于图像级标签的弱监督图像语义分割的数据集之一,其是LabelMe数据集[73]中的一个子集。该数据集包含33个目标类和3个地理类别,共由2 688张256×256像素的图像组成,图像示例如图3(d)所示。Sift Flow数据集共包含8种户外场景,如街道、海滩、城市、山脉、建筑等,且每张图像均有像素级标签的真值标注。与MSRC数据集类似,Sift Flow数据集图像中的目标类别具有比较大的面积,且易于构建不同目标类之间的共生和关联。
3.1.5Cityspaces数据集
Cityspaces[74]数据集由50个不同背景和季节的欧洲城市街道场景图像组成,是当前应用于交通场景图像语义分割的重要数据集。该数据集含有不包括背景在内的30个目标类,共由24 998张城市街道场景图像组成,图像示例如图3(e)所示。Cityspaces数据集约有5 000张精细标注的图像、20 000张粗粒度标注的图像,且每一张图像均包含数量众多的目标类和复杂的背景,并存在大量远视角的小目标。
各数据集的特点对比如表5所示。

表5 不同数据集的特点对比Table 5 Comparison of characteristics of different datasets

图3 常用数据集的图像示例Fig.3 Image examples of commonly used datasets
3.2 评价指标
在基于图像级标签的弱监督图像语义分割方法中,最为常用的评价指标为交并比IoU(intersection over union),即正确分割的正样本与错误分割的正样本、错误分割的负样本、正确分割的正样本之和的比值。评价指标IoU反映了算法正确分割的结果与图像真值区域的重合程度。为了评价算法对所有目标类的整体分割精度,通常采用所有目标类的平均交并比MIoU来进行表示。其中,MIoU被定义为:
(1)
式中:N指图像中的目标类别数;nii表示实际类别为i,预测类别为i的像素数量;ti表示类别i中包含的像素总数;nji表示实际类别为i,预测类别为j的像素数量。
其次,像素准确率PA(pixel accuracy)及平均像素准确率MPA也是弱监督图像语义分割领域常用的评价指标。其中,PA指图像中正确分割的像素数占总像素数的比例,MPA指所有目标类别像素准确率的平均值,被定义为:
(2)
式中:N指图像中的目标类别数;nii表示实际类别为i,预测类别为i的像素数量;ti表示类别i中包含的像素总数。
4 基于图像级标签的弱监督图像语义分割方法性能对比
为了对现有基于图像级标签的弱监督图像语义分割方法进行全面和客观的对比与分析,本文依据常用数据集的不同对各方法的性能进行了对比。其中,四个应用最广泛的数据集被选择,包括:MSRC、PASCAL VOC 2012、MS COCO和Sift Flow.
4.1 MSRC数据集上的性能对比
为了全面分析MSRC[68]数据集上各对比方法的性能,本文对基于图像级标签的弱监督图像语义分割方法的性能进行了总结与对比,具体的性能指标如表6所示。
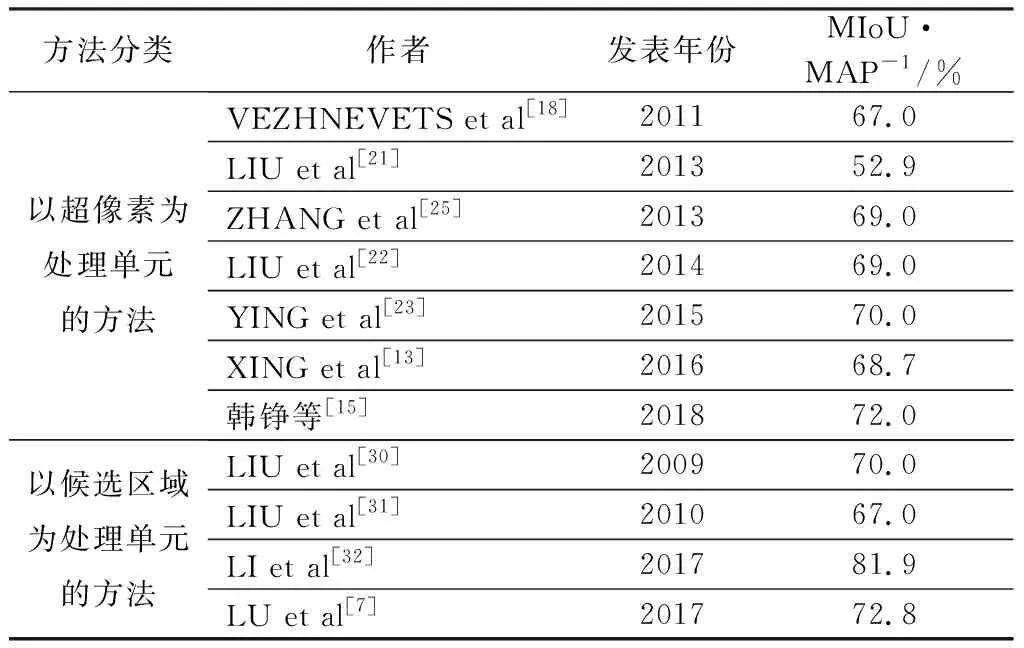
表6 MSRC数据集上的性能对比Table 6 Performance comparison on MSRC datasets
由表6可知,MSRC数据集被较早应用于基于图像级标签的弱监督图像语义分割,所提方法主要以基于超像素的弱监督图像语义分割方法为主,具体包括以超像素为处理单元的方法和以候选区域为处理单元的方法。相比于基于分类网络先验的弱监督图像语义分割方法,基于超像素的方法更适用于具有干净背景和显著目标区域的MSRC自然场景图像数据集。基于分类网络先验的弱监督图像语义分割方法很少在MSRC数据集上进行验证,原因在于MSRC数据集包含的数据量较小,很难利用这些少量的数据来训练基于深度卷积神经网络的复杂分割模型。此外,随着时间的增长以及越来越多先进技术的引入,基于MSRC数据集的弱监督图像语义分割精度呈现逐渐升高的趋势,但是基于MSRC数据集验证的弱监督图像语义分割方法呈现减少的趋势。主要原因在于MSRC数据集中的目标相对单一,仍然存在一些需要先验信息指导才能高精度识别的目标区域,这限制了MSRC数据集上基于图像级标签的弱监督图像语义分割方法性能的进一步提升。
4.2 PASCAL VOC 2012数据集上的性能对比
PASCAL VOC 2012[69]数据集作为当前基于图像级标签的弱监督图像语义分割领域最为主流的图像数据集,被广泛应用于验证所提方法的有效性。为此,本文在PASCAL VOC 2012测试集上来评估各对比方法的性能,具体的对比结果如表7所示。

表7 PASCAL VOC 2012测试集上的性能对比Table 7 Performance comparison on PASCAL VOC 2012 test sets
由表7可知,PASCAL VOC 2012数据集上的验证主要以基于分类网络先验的方法为主。该类方法基于预训练好的分类网络来指导图像级标签位置推断,能够显著提高所提方法的分割性能。相比于基于超像素的方法被较早提出,基于分类网络先验的方法从2015年开始才被显著关注,并成为近5年基于图像级标签的弱监督图像语义分割的主流方法。鉴于PASCAL VOC 2012数据集包含的目标类别较多且图像中包含众多复杂的小目标区域,基于分类网络先验的弱监督图像语义分割方法更依赖于选择PASCAL VOC 2012自然场景图像数据集进行验证。随着时间的增长,面向PASCAL VOC 2012数据集验证的弱监督图像语义分割方法的性能也获得了显著的提升。原因在于更多有效的判别种子区域产生方式被提出以及更多有效的种子区域扩张方式和分割网络被构建。在基于分类网络先验的方法中,基于类激活图定位网络的方法要比基于其它分类网络的方法更受关注,但是基于类激活图定位网络的方法仅能识别出图像中一些稀疏性的判别区域,这也成为该类方法精度进一步显著提高的障碍。
4.3 MS COCO数据集上的性能对比
MS COCO[71]数据集作为当前基于图像级标签的弱监督图像语义分割领域最为复杂的自然场景图像数据集之一,近几年也常被用于验证所提方法的有效性。相比于PASCAL VOC 2012数据集,MS COCO被应用于验证算法性能的文献较少,具体的性能对比如表8所示。
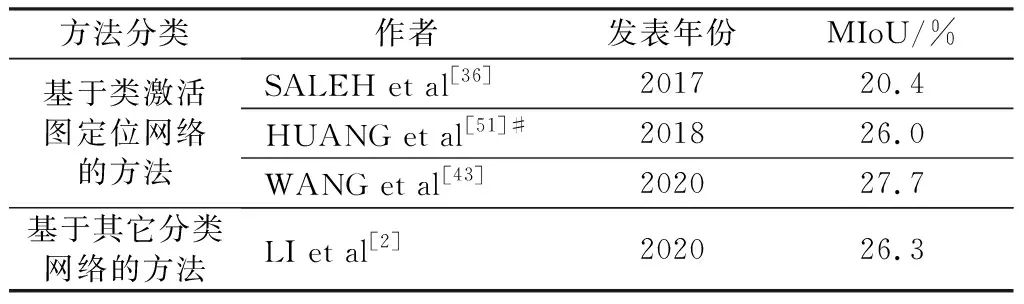
表8 MS COCO数据集上的性能对比Table 8 Performance comparison on MS COCO datasets
由表8可知,MS COCO数据集上所提方法的数量较少,且所提方法的分割精度相对较低。主要的原因在于MS COCO数据集建立的时间较晚,其包含80个目标类和1个背景类,而所有方法均采用MIoU指标来验证分割精度,更增加了MS COCO数据集上分割性能显著提高的难度。相比于基于超像素的弱监督图像语义分割方法,基于分类网络先验的方法更适合选择大规模的MS COCO自然场景数据集来验证方法的分割性能。因此,如何构建面向大规模复杂场景的弱监督图像语义分割算法仍然是一个非常具有挑战性的研究问题。
4.4 Sift Flow数据集上的性能对比
Sift Flow[72]数据集也是早期用于验证基于图像级标签的弱监督图像语义分割方法的常用数据集,各对比方法的性能指标如表9所示。
如表9所示,基于Sift Flow数据集的弱监督图像语义分割方法主要包括以超像素为处理单元的方法和以候选区域为处理单元的方法。和MSRC数据集一样,基于超像素的弱监督图像语义分割方法同样适用于包含干净背景和显著目标的Sift Flow数据集。该类方法主要集中在2013-2017年之间被广泛提出,且分割精度随着时间的增长成上升趋势。相比于基于分类网络先验的方法,Sift Flow数据集上主要以未引入先验信息的基于超像素的方法为主。因此,该类方法的分割精度相对较低,依然有比较大的提升空间。

表9 Sift Flow数据集上的性能对比Table 9 Performance comparison on Sift Flow datasets
5 总结与展望
基于图像级标签的弱监督图像语义分割研究是近几年计算机视觉领域的热点研究问题,具有重要的理论研究价值和广泛的应用前景。依据图像级标签位置推断方式的不同,本文将基于图像级标签的弱监督图像语义分割方法划分为基于超像素的方法和基于分类网络先验的方法,并对各类方法的原理、优缺点、关键环节、主要技术、特征、超像素/候选区域分割方式、种子区域产生方式、网络结构和数据集等进行了详细的分析和总结。此外,本文对基于图像级标签的弱监督图像语义分割方法常用的数据集和评价指标同样进行了归纳和总结,并定量地对比了各方法的性能。最后,针对现有方法存在的挑战和局限性,本文对基于图像级标签的弱监督图像语义分割下一步的研究方向进行了展望与预测。
1) 面向大规模多媒体分享网站大数据的弱监督图像语义分割。多媒体分享网站提供了大量带有社会标签的图像/视频数据,如何基于这些用户贡献的图像/视频数据挖掘弱监督标签信息,进而搜集和构建大规模图像级标签标注的图像数据集,并用于图像级标签位置推断和分割网络训练是一个重要的研究方向。但是,基于多媒体分享网站构建的训练数据往往包含比较严重的噪声标签。因此,如何减少噪声标签的影响也是该研究方向面临的一个难题。
2) 特定应用场景下的弱监督图像语义分割。图像语义分割近几年被广泛关注的一个重要原因在于其不仅具有重要的理论研究意义,还可以为各种应用场景提供核心的技术支撑。例如,自动驾驶、智能监控、3D城市建模、遥感图像分析、辅助医疗等应用场景均需要高精度的图像语义分割。因此,如何基于弱监督标签的标注,聚焦于交通、遥感、医学等具体应用场景的关键技术和语义分割算法研究是一个重要的研究方向。
3) 高质量和稠密的图像级标签位置推断策略。图像级到像素级的标签位置推断依然是当前基于图像级标签的弱监督图像语义分割面临的最大挑战。虽然现有的方法可以通过引入超像素或者额外的先验信息来指导图像级标签的位置推断,但是,当前基于图像级标签的弱监督图像语义分割与基于像素级标签的全监督图像语义分割还存在比较大的差距。因此,如何构建更加有效的图像级标签位置推断策略,进而高质量和稠密地定位图像级标签在图像中的位置信息是一个重要的研究方向。
