基于多任务学习和多态语义特征的中文疾病名称归一化研究
2021-11-25张展鹏
韩 普,张展鹏,张 伟
(1.南京邮电大学管理学院,南京 210003;2.江苏省数据工程与知识服务重点实验室,南京 210023)
1 引言
近年来,随着互联网的飞速发展和公众信息素养的提升,微博、微信和在线健康社区等社会化媒体逐渐成为人们获取、传播和分享医疗健康知识的重要渠道,这些平台所产生的海量在线医疗健康数据已经成为医疗实体识别[1-2]、流行病预测[3-4]、情感分析[5-6]和药物不良反应[7-8]等多个研究的重要数据源。与电子病历中的专业化表述相比,在线医疗健康文本缺乏医疗术语规范,存在大量的疾病指称和口语化表达,这对在线医疗健康信息抽取和知识挖掘带来了极大的挑战。在这种背景下,将用户的非标准化表述映射到标准医学术语的疾病名称归一化任务[9-10],受到了医疗健康信息抽取、知识库和知识图谱构建以及领域知识挖掘的重点关注[11-12],目前已经成为自然语言处理和信息抽取中的一个重要研究领域。
疾病名称归一化任务的主要挑战表现是在线医疗健康文本中疾病指称与标准术语往往并没有字面上的关联,基于规则的方法难以从字符层面实现归一化;另外,在线医疗健康文本中的疾病指称与标准术语存在一对多或多对多等复杂关系,传统方法难以挖掘深层语义信息。与英文相比,中文文本表达方式和语法结构更为复杂,词汇间无分隔符号,一词多义和同形异义的现象较为普遍,导致语义分析的难度更大[13]。另外,中文疾病名称构词更为复杂,存在大量缩写和翻译词汇,也缺少类似于UMLS(unified medical language system)和SNOMED CT(the systematized nomenclature of human and vet‐erinary medicine clinical terms)的疾病名称知识库资源[14-15],使得中文疾病名称归一化面临着更大的挑战。与通常的术语相比,中文疾病名称专业性更强,尤其是在线医疗健康社区中不同用户的表述多种多样,并且有许多名称是从外文翻译而来,这些因素导致中文疾病名称归一化难度也远大于普通的术语标准化。
本研究基于多任务学习视角,将CNN(convo‐lutional neural networks)、GRU(gated recurrent unit)、LSTM(long short-term memory)、BiGRU(bidirectional gated recurrent unit)、BiLSTM(bi-di‐rectional long short-term memory)与BERT(bidirec‐tional encoder representations from transformers)相 结合,以捕获静态和动态语义信息;同时引入注意力权重词典作为辅助任务生成注意力矩阵以调节静态向量,并将疾病名称归一化转化为分类任务;最后在中文数据集上进行实验,以验证多任务学习对中文疾病名称归一化的效果。
2 相关研究概述
根据所采用的研究方法,疾病名称归一化可以分为无监督学习和有监督学习。在有监督学习方法中,多任务学习和BERT是学界近期的关注重点。
2.1 无监督学习
无监督学习方法主要是指采用字典查找或字符串匹配的方法进行归一化。Ristad等[16]利用编辑距离计算字符串间的相似度,将归一化任务转化为相似度排序问题。2010年,美国医学图书馆年发布了MetaMap工具[17],它首先通过词典遍历和浅层句法分析来识别名词短语,然后将生物医学文本与UMLS的CUIs建立映射关系。Tsuruoka等[18]利用逻辑回归计算字符串相似度以实现归一化,其效果优于传统的规则匹配方法。Yang[19]从UMLS和SNOMED CT中提取了疾病相关特征,并改进了基于规则的归一化方法。基于MetaMap工具,Khare等[20]建立了疾病和药物的映射关系,并将药物描述中的疾病作为候选名称,结果表明该方法在疾病名称归一化上可达到较好的效果。基于UMLS中的疾病变体规则,Kate[21]提出了自动学习临床术语变体的模型,从而对未包含在知识库中的术语进行归一化。Jonnagaddala等[22]提出了基于词典查找的方法进行疾病名称归一化,并引入同义词增强词典以进一步提升实验效果。通过上述分析可知,一方面,传统的无监督学习方法依赖权威的医学词典或知识库,难以应对未收录疾病和疾病指称的情况;另一方面,该方法主要利用语言形态信息进行处理,难以结合深层语义信息进行疾病名称归一化。
2.2 有监督学习
有监督学习方法主要是指利用机器学习或深度学习模型进行任务分类的方法,该方法往往将疾病描述文本与疾病名称匹配视为文本分类任务,通过模型学习疾病描述特征表示以预测疾病分类,从而实现疾病名称归一化。基于成对学习思想,Leaman利用机器学习模型,构建了英文疾病名称归一化系统DNorm(disease name normalization)[10]。该系统利用计算相似度矩阵预测疾病描述文本与候选疾病名称的关系,其F值在NCBI(National Center for Biotechnology Information)疾病数据集实验中较MetaMap提升了25%。Shi等[23]利用字符级感知神经网络学习书面诊断描述和ICD(international cassifi‐cation of diseases)编码的隐藏表示,并引入注意力机制,实现了书面诊断与ICD编码的归一化映射。Liu等[24]利用word2vec和TreeLSTM生成了分布式特征表示并提取候选疾病名称,通过计算疾病描述和候选疾病名称间相似度进行分类,在英文数据集上取得了较好的实验结果和较高的鲁棒性。通过学习文本内在语义关系,Limsopatham等[25]发现CNN在疾病名称归一化上的效果优于RNN(recurrent neu‐ral network),其实验准确率较DNorm高出13.79%。基于形态和语义信息,Li等[26]通过CNN计算疾病指称和候选疾病名称的语义相似度实现了生物医学概念归一化,实验结果明显优于基于规则的方法,验证了引入语义特征可提高疾病名称归一化效果。Tutubalina等[27]提出了基于注意机制的双向LSTM及GRU,并引入UMLS的TF-IDF(term frequencyinverse document frequency)特征和语义相似性特征,进一步验证了语义特征对疾病名称归一化的影响。Huang等[28]基于RNN和CNN实现了MIMIC-III(medical information mark for intensive care)数据集到ICD编码的映射,研究结果验证了RNN和CNN较传统的逻辑回归和随机森林等模型的疾病名称归一化效果均有明显提升。
与无监督学习相比,有监督学习不但弥补了无监督学习中无法处理未收录疾病名称的不足,而且通过大规模训练数据学习疾病特征,可充分利用文本语义信息进行疾病名称归一化。
2.3 多任务学习
多任务学习可联合训练多个子任务,通过共享参数提高模型的学习效率和泛化能力,近期在自然语言处理领域受到了学界的重点关注。Collobert等[29]在词性标注、命名实体识别和语义角色标注等任务中,提出了基于多任务学习的CNN模型,验证了多任务学习在自然语言处理上的优异表现。Liu等[30]基于LSTM设计了三种信息共享机制,使用特定任务的共享层对文本进行建模,研究发现子任务可以提升主分类任务效果;另外,Liu等[31]还在文本分类中提出对抗性的多任务学习框架,避免了共享和私有两种特征的相互干扰,实验结果表明所学习的共享知识可被迁移到新任务中。Yang等[32]以ELMo(embeddings from language models)作为向量嵌入提出了基于注意力的多任务BiLSTM-CRF模型,在电子病历数据集上进一步提升了医疗实体识别和归一化效果。Niu等[33]基于多任务学习思路提出了字符级CNN模型进行疾病名称归一化,较好地解决了未登录词的问题,并引入注意力机制优化模型效果,实验结果在AskApatient数据集上达到了84.65%的准确率。由上文可知,在自然语言处理任务的不同应用场景中,多任务学习得到了广泛的应用。本文将多任务学习思想引入中文疾病名称归一化研究中,利用多任务学习能够共享多个子任务间参数以共同提升主任务的优势,进一步推动中文疾病名称归一化研究进展。
2.4 BERT
BERT[34]是一种基于转换器的双向编码表征模型,在多个自然语言处理任务中表现优异[35-36]。Li等[37]对大规模标注的电子健康档案进行了BioBERT微调,进一步训练了EhrBERT、BioBERT和BERT,研究结果发现,这些模型在疾病名称归一化上的效果均优于DNorm。Xu等[38]基于BERT设计了列表分类器并利用正则化UMLS语义类型对候选概念进行排序,在疾病名称归一化上达到了较高的准确率。Ji等[39]基于微调预训练的BERT、BioBERT和Clini‐calBERT进行疾病名称归一化,在ShARe/CLEF、NCBI和TAC2017ADR三种不同类型数据集上的实验均表明微调模型明显优于基线方法。此外,Kalyan等[40]提出了一种基于BERT和Highway的医学概念标准化系统,研究发现在CADEC和PsyTAR数据集上的效果优于传统方法。本文基于多任务视角,结合当前主流的BERT模型,综合利用文本形态信息和深层语义信息进行中文疾病名称归一化实验,并引入多态语义特征以改进模型效果。
3 模型设计
本文设计的MTAD-BERT-GCNN模型结构如图1所示。首先,根据好大夫、求医问药、好问康、THUOCL(THU Open Chinese Lexicon)、CCKS2017(China Conference on Knowledge Graph and Semantic Computing-2017)和ICD-10(International Classifica‐tion of Diseases-10)分别构建实验数据集、特征训练语料和注意力权重词典;其次,利用word2vec和Glove在特征训练语料上生成字词向量;接着分别将疾病描述文本转化为向量输入到子任务;然后利用GCNN(graph convolutional neural network)和BERT同时对输入向量进行特征训练和提取,并引入注意力权重词典以调节向量表示质量;最后,根据Softmax函数实现疾病名称归一化。其中,BERT输入的是动态语义向量,GCNN输入的是静态语义向量。因此,MTAD-BERT-GCNN模型可以通过多任务学习捕获特征向量的静态和动态语义信息,并利用共享权重参数优化多个子任务深度挖掘语义信息,从而提升实验效果。
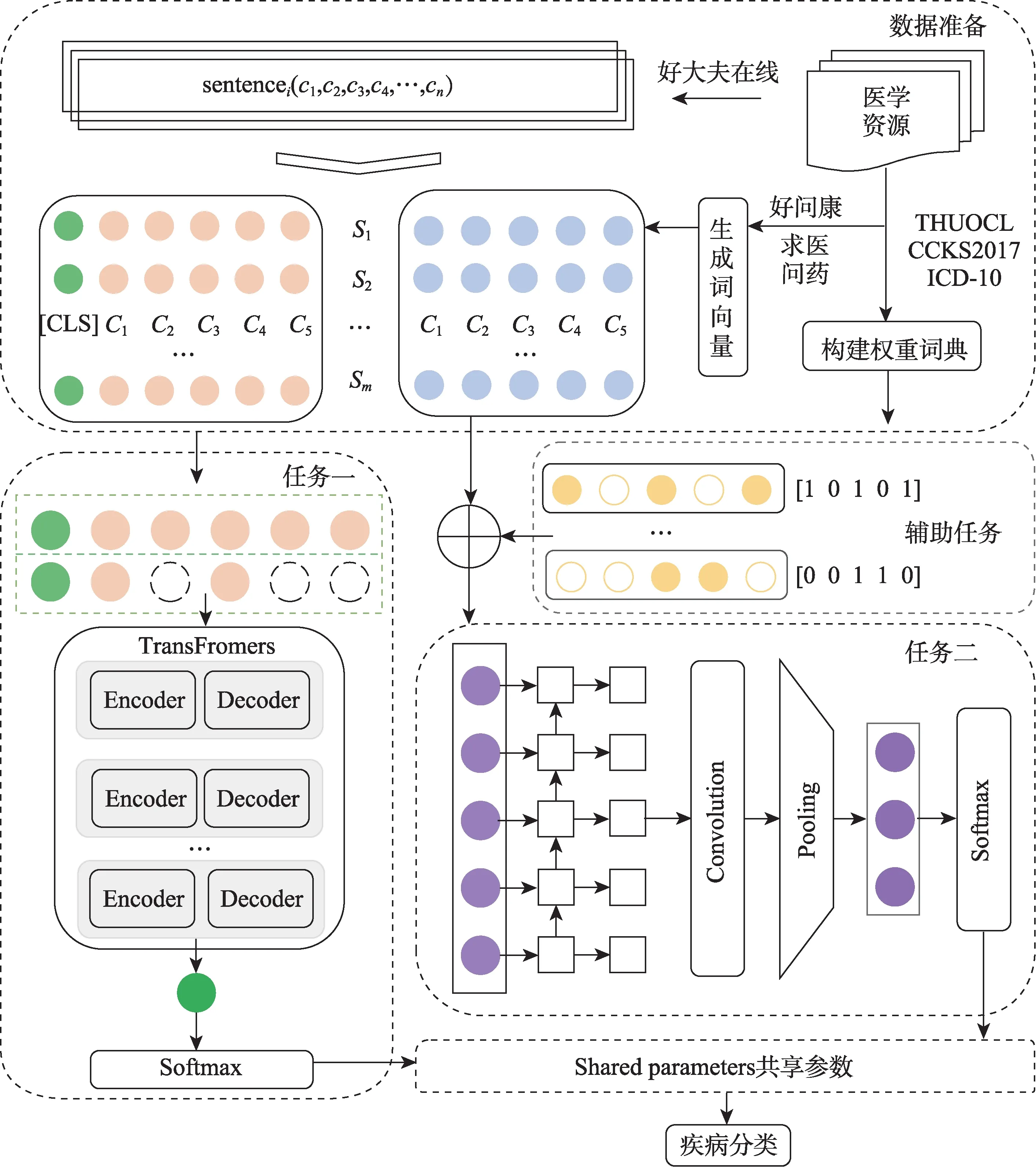
图1 MTAD-BERT-GCNN模型结构图
3.1 数据准备
1)构建实验数据集
由于国内缺少公开的疾病名称归一化数据集,本文参照英文疾病名称归一化评测任务,构建了中文疾病名称归一化数据集(Chinese Disease Normal‐ization Data,ChDND)。具体过程包含两部分。一是数据获取及处理。从好大夫在线网站爬取了46140条疾病描述和537个疾病名称,参照已有研究[27,41],去除出现频次少于10的疾病名称及其对应描述,并分别生成词级和字级疾病描述;二是建立映射关系。基于网站的类别信息,将疾病描述与对应疾病名称建立多对一的映射关系。最后,本文构建的数据集ChDND包含了407个疾病名称和42891个疾病描述,平均每个疾病名称对应105个疾病描述。数据集ChDND的示例如表1所示。

表1 中文疾病数据集实例
2)生成特征向量
基于求医问药和好问康在线医疗社区问答语料,利用word2vec和Glove两种词向量训练模型,生成具有局部和全局语义特征的多特征融合向量,并作为本实验静态语义向量的输入。BERT预训练向量是谷歌提供的中文预训练模型BERT-Base-Chinese。
3)构建注意力权重词典
引入医学词典构建注意力权重词典以提高领域关键词的权重,降低非专业化表述的影响,进而提升关键特征的提取效果。本实验所采用的医学词汇,一方面,来源于ICD-10和THUOCL中的专业医学词汇;另一方面,抽取了CCKS2017电子病历数据集中的所有医疗实体。其中,ICD-10是国际疾病分类,包含1587个疾病类别,本实验提取了5634个疾病特征词汇;THUOCL是清华大学NLP组构建的中文词库,词表来自主流网站的社会标签、搜索热词和输入法词库,本实验提取了18749个专业医学词汇;CCKS2017是2017年全国知识图谱与语义计算大会中文电子病历命名实体识别竞赛数据,包含2505条电子病历,本实验提取了13802个高频实体词汇。此外,ICD-10是标准的医学术语,THUOCL中的医学词汇符合医学术语规范;相比而言,经CCKS2017提取的词汇主要来自电子病历中医生表述,其规范性略低于医学词典。
3.2 关键技术
1)LSTM
长短时记忆网络[42](LSTM)是RNN的变体,它可解决文本序列中的长期依赖问题,该模型由忘记门、输入门和输出门组成。其中,忘记门决定细胞状态丢弃的信息;输入门添加细胞状态中的新信息;输出门则判断细胞的状态特征,联合输入层中的细胞状态计算得到最终输出。
2)GRU
GRU[43]是LSTM的变体,它将三门结构替换为更新门和重置门两门结构,优化了网络结构,在联动表达式将前一节点和当前节点相结合以更新单元记忆。
3)BiLSTM、BiGRU
LSTM和GRU均采用正向传播算法,仅能获取文本序列正向的上文语义信息,而忽略了后向序列的语义影响。BiLSTM和BiGRU可以通过正反传播获取上下文全局语义特征。
4)CNN
卷积神经网络[44](CNN)是一种前馈神经网络,它通过多个卷积核提取文本信息。该模型包含输入层、卷积层、池化层、连接层和输出层。其中,输入层将向量转换成张量矩阵;卷积层提取输入向量的局部特征和位置编码信息,利用卷积核进行首次特征提取;池化层对文本向量进行二次特征提取,通过降维保留关键信息;全连接层用于拼接和拟合池化后的特征向量以降低模型损失值;输出层根据任务目标选择不同函数并输出相应结果。
5)BERT
BERT是一种基于转换器的双向编码表征模型,具有强大的特征提取功能。Transformer[45]是BERT的主要框架,它基于自注意力机制能够更全面地捕捉语句间的双向关系;BERT基于掩藏语言模型(mask language model,MLM)突破了单项语言模型的限制,利用MASK随机替换输入特征以提高模型对特征的辨识度。在具体分类任务中,BERT在每条数据前插入[cls]标记,并将Transformer输出结果汇总到该标记,从而实现整个输入序列的信息汇总,从句向量角度实现分类任务。
3.3 多任务
1)任务一
任务一基于动态语义向量进行BERT微调和疾病描述映射。首先,文本Si经过数据准备阶段转化为向量矩阵Ci=([cls],c1,c2,c3,…,ci,…,cn)并输入到该任务,ci可与BERT预训练嵌入层建立唯一映射关系;其次,BERT将输入向量转化为字向量特征Wi、位置特征Posi和分割嵌入Segi三种嵌入特征,并将三特征求和作为新的输入向量矩阵,其中Segi在单句文本分类时记为0;接着,BERT经多层Transformer生成微调后的动态语义向量,输入到下游任务计算分类向量CLSi=(cls1,cls2,cls3,…,clsi,…,clsn);然后,利用Softmax函数结合训练的最佳权重和偏置(W1i和b1i)将CLSi转换为概率向量Pi=(p1,p2,p3,…,pl),其中,pi为疾病描述文本映射到候选疾病名称的概率;最后,利用交叉熵函数计算该任务损失,具体公式为

2)任务二
任务二基于静态语义向量进行特征挖掘和疾病描述映射。首先,文本Si经过数据准备阶段转化为字符向量矩阵Ci=(c1,c2,c3,…,ci,…,cn)输入到该任务,ci可与多特征融合嵌入层建立唯一映射关系;其次,利用GRU训练向量矩阵,增强输入文本序列间语义关系,计算得到向量矩阵Hi;接着,利用CNN提取该向量矩阵中的重要信息,保留输入文本的关键语义特征,经过卷积池化后得到向量矩阵Fi;然后,利用Softmax函数结合训练得到的最佳权重和偏置(W2i和b2i)将Fi转换为概率向量Pi=(p1,p2,p3,…,pl),其中pi为疾病描述文本映射到候选疾病名称的概率;最后,利用交叉熵函数计算该任务损失,具体公式为

3)辅助任务
辅助任务可提取任务二中输入文本的关键词注意力权重。首先,将任意输入文本Ti=(t1,t2,t3,…,ti,…,tn)与注意力权重词典建立映射;其次,当输入文本的词汇在注意力权重词典出现时,将该位置标记为1,否则标记为0,得到一个注意力矩阵ATi=(at1,at2,at3,…,ati,…,atn),其中ati=0,1;再次,将该矩阵ATi与任务二中的Ci矩阵相乘计算得到C_ATi,该向量经任务二特征提取得到向量矩阵F_ATi;最后,计算融入注意力权重后的概率向量P2i,具体公式为

4)共享参数
多任务学习中,多个关联任务间通过损失函数相互调节以共享信息,并优化参数,分别反馈到每个子任务以提高模型效果。其中,共享损失函数为
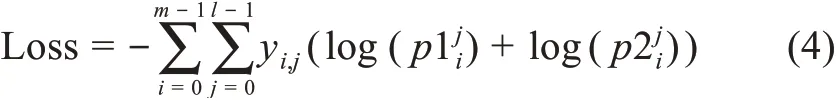
具体共享参数流程如图2所示。
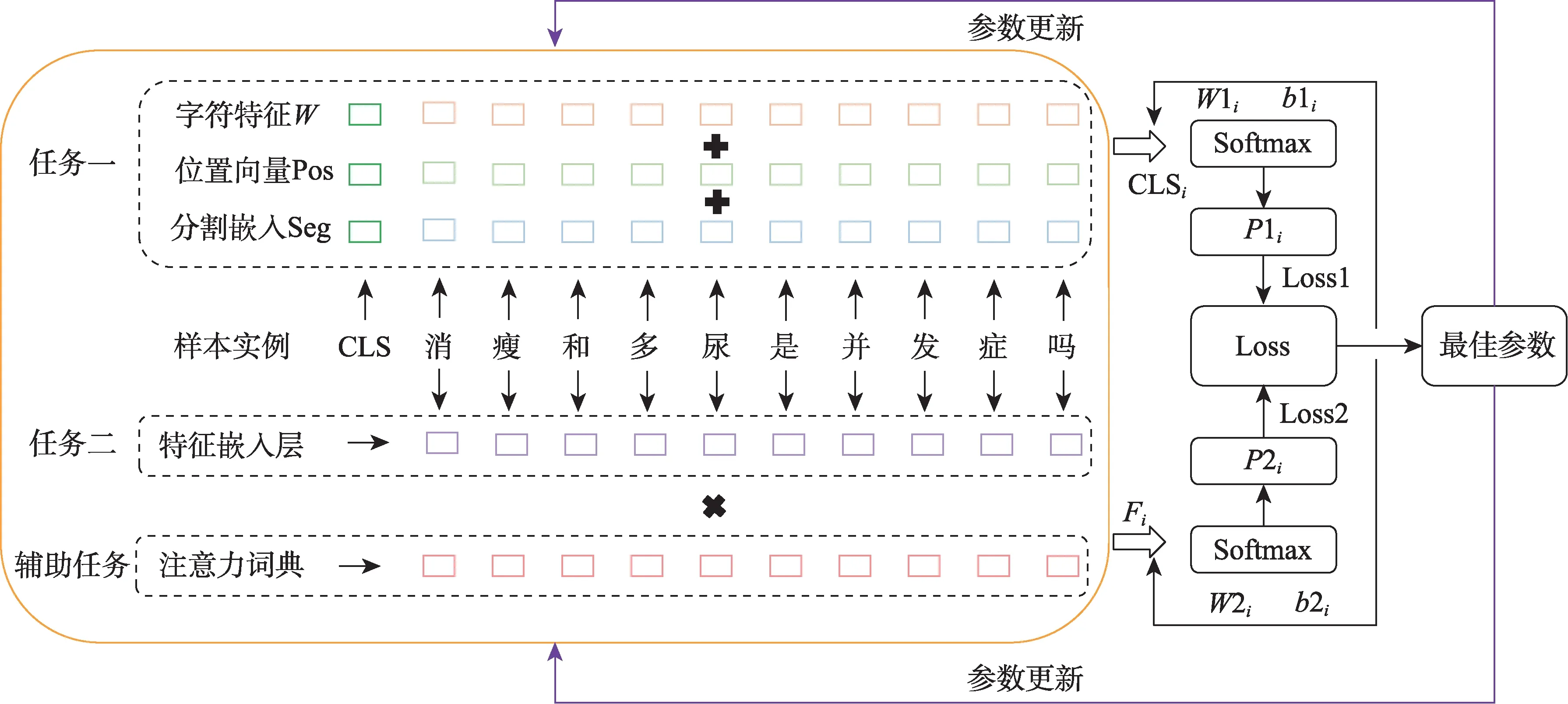
图2 多任务共享参数流程
4 实验分析
4.1 实验设计
本文实验目的如下。
(1)验证基准模型在中文疾病名称归一化任务上的效果。
(2)验证引入语义关系对中文疾病名称归一化实验的影响。
(3)验证引入多任务学习对中文疾病名称归一化实验的影响。
基于上述实验目的,本文共设计了三组对照实验。每组实验均采用五折交叉验证,按7∶2∶1划分为训练集、验证集和测试集,具体设计如下。
实验一:对比分析CNN-WRv(CNN中嵌入词级随机向量)、CNN-CRv(CNN中嵌入字级随机向量)、CNN-WGv(CNN中嵌入外部语义特征)以及BERT-Base(基于预训练BERT进行微调)的实验效果。
实验二:在实验一中实验效果最佳CNN的基础上,分别引入GRU、LSTM、BiGRU和BiLSTM训练语义关系,分析语义训练后不同特征向量对中文疾病名称归一化的影响。
实验三:基于多任务学习,将实验一和实验二中表现最优的模型相结合,验证多任务学习对中文疾病名称归一化的效果,并在此基础上引入计算注意力权重的辅助任务,分析调节向量权重后模型对实验的影响。
具体实验思路如图3所示。
4.2 实验环境
本实验环境是一台内存20 GB、CPU型号为In‐tel(R)Core i5-7600K CPU、频率3.80 GHz、GPU为型号Nvidia GeForce RTX 2080 Ti、显存11 GB、操作系统为Windows 10的服务器。此外,实验中还使用了jieba分词库、哈工大LTP语言云、word2vec和Glove词向量训练工具、BERT和Tensorflow框架。开 发 环 境 为python 3.6、Tensorflow 1.13、keras 2.2.4、cuda10.0、cudnn 7.3.1。
4.3 实验参数
本实验中的具体参数设置如表2所示。
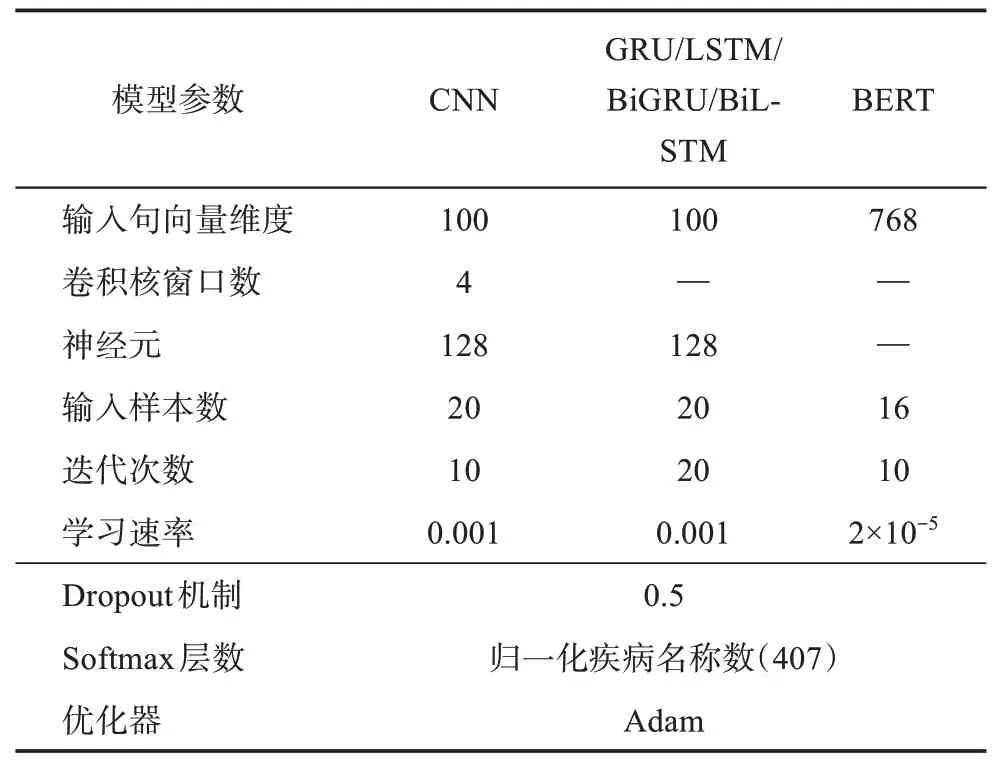
表2 模型参数设置
4.4 评价指标
参照已有研究[14,46-47],本实验采用准确率(Ac‐curacy)指标进行归一化评价,利用Accuracy@k评估疾病名称归一化效果,Accuracy@k表示前k个预测疾病中正确结果的占比。分别取排名前1、5和10个疾病作为预测疾病,计算Accuracy@1、Accura‐cy@5和Accuracy@10。由于多分类任务中难以计算负样本对结果的影响,本实验的归一化评价指标为
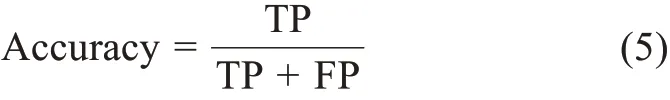
其中,TP为判断为正确的疾病指称;FP为判断为错误的疾病指称。
4.5 实验结果与分析
4.5.1 基准模型实验
为验证基准模型在中文疾病名称归一化任务上的效果,分别利用CNN和BERT-Base进行实验,结果如表3所示。
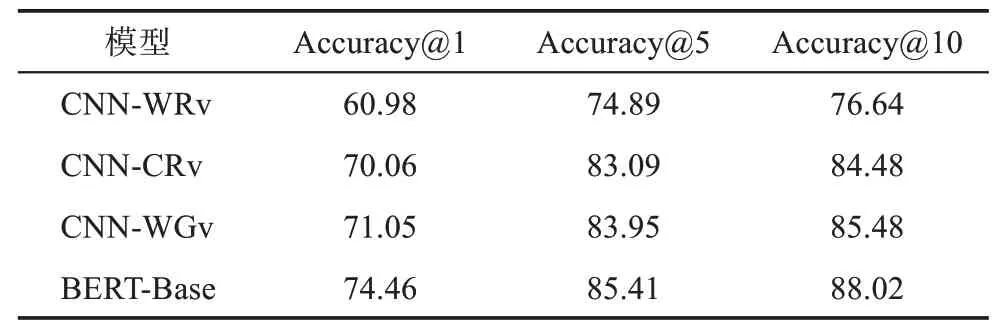
表3 基准模型实验结果 %
由表3可知,在中文疾病名称归一化中,字级CNN效果优于词级CNN;引入外部语义特征对模型效果的提升并不明显;BERT微调后的效果较好,较CNN有明显提升。
(1)字级CNN效果优于词级CNN。CNN-CRv在Accuracy@1、Accuracy@5和Accuracy@10上 较CNN-WRv分别提升了9.08%、8.20%和7.84%,提升幅度较为明显。通过分析可知,这是由于在线医疗健康文本中医学词汇和口语化表述经常混杂出现,导致分词质量难以保证,从而影响到词级向量;而通过分字生成的字级向量可独立表示字符语义,因此在实验中表现出更好的效果。
(2)引入外部语义特征对实验的影响并不明显。CNN-WGv在Accuracy@1、Accuracy@5和Ac‐curacy@10上较CNN-CRv分别提升了0.99%、0.86%和1.00%,提升幅度较小,表明词向量嵌入层中语义特征对CNN的影响较小,这是由于随机向量和外部语义特征均为唯一表示,不影响特征分布,但引入外部语义特征能够丰富特征语义,对模型效果有小幅提升。
(3)BERT预训练模型微调后的效果较好。BERT-Base在Accuracy@1、Accuracy@5和Accura‐cy@10上较最优的基线模型CNN-WGv分别提升了3.41%、1.46%和2.54%,提升效果较为明显。这验证了BERT能够进一步提升疾病名称归一化效果,且显著优于其他基线模型,表明BERT能够更充分地捕获文本深层特征。
4.5.2 引入语义关系的CNN实验
通过实验一可知,字级向量在CNN上有较高的准确率,在此基础上,实验二分别引入GRU、LSTM、BiGRU和BiLSTM验证语义关系训练对实验结果的影响,具体如表4所示。

表4 基于语义关系的CNN实验结果 %
由表4可知,在CNN上引入GRU、LSTM、Bi‐GRU和BiLSTM捕获文本间语义关系后的模型效果较表3中CNN-WGv有较大提升。其中,GRU-CNN效果最优,在Accuracy@1、Accuracy@5和Accura‐cy@10上较引入外部语义特征的CNN分别提升了2.95%、1.36%和1.12%。该结果表明,通过引入文本向量间语义关系可提高向量质量,在CNN中可提取更关键特征以进一步提升模型效果。
研究分析发现,引入GRU和BiGRU的效果优于LSTM和BiLSTM,这是由于文本中大量的非医疗领域信息会影响模型学习疾病特征的语义质量,GRU网络结构较LSTM更为简洁,可减少因大量非医疗领域信息计算而出现过拟合的影响。此外,引入BiGRU和BiLSTM的实验效果低于GRU和LSTM,这是由于医疗健康文本的语序对语义关系影响不大,而BiGRU和BiLSTM因同时学习文本正负向语义关系造成过拟合,反而降低了文本语义关系的表达质量。
4.5.3 多任务学习实验
根据表3和表4可知,BERT-Base和GRU-CNN两模型的表现最优,因此,在两模型基础上构建了MT-BERT-GCNN模型,用于验证多任务学习对中文疾病名称归一化的影响。为了提高输入向量质量,进一步引入注意力权重词典来调节任务的特征输入,构建MTAD-BERT-GCNN模型以提升实验效果。多任务学习实验结果如表5所示。
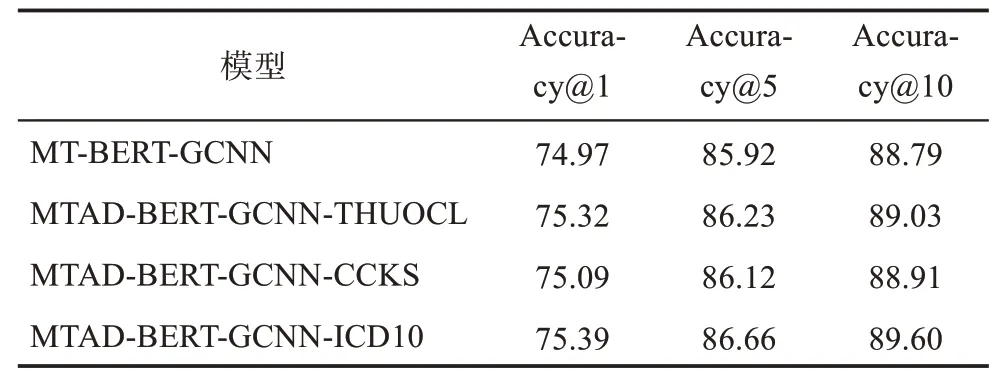
表5 多任务学习实验结果 %
由表5可知,基于多任务学习构建的MT-BERTGCNN效果较BERT和GRU-CNN均有小幅提升,在Accuracy@1、Accuracy@5和Accuracy@10上,较GRU-CNN分别提升了0.97%、0.61%和2.19%,较BERT-Base分别提升了0.55%、0.51%和0.77%。这表明MT-BERT-GCNN的效果提升并非简单线性效果相加,而是能够利用多任务学习共享子任务参数,通过并行训练学习更多特征信息可提升当前主任务学习性能,从而获得更多代表性特征以提高疾病名称归一化的准确率。
进一步分析发现,引入计算注意力矩阵的辅助任务后,MTAD-BERT-GCNN效果较MT-BERTGCNN得到了进一步提升,表明引入辅助任务调节特征输入可以筛选疾病的关键特征,对模型特征提取具有辅助作用。其中,MTAD-BERT-GCNNICD10的效果最佳,在Accuracy@1、Accuracy@5和Accuracy@10上,较MT-BERT-GCNN分别提升了0.42%、0.74%和0.81%,均略高于引入其他注意力权重词典的模型。引入注意力权重词典后,ICD10提升效果最佳,THUOCL次之。通过分析可知,ICD-10中包含了更多的专业医学术语,因而能够更充分地表示疾病特征;而CCKS中用词规范性略低于专业医学词典,在筛选特征时出现了部分非医学术语在辅助任务中权重分配错误的情况。
为了直观地呈现模型组合及多任务学习在中文疾病名称归一化上的效果,图4给出了三组对照实验结果。可以发现,在Accuracy@1、Accuracy@5和Accuracy@10上,MTAD-BERT-GCNN-ICD10较 词级CNN基准模型分别提高了14.41%、11.77%和12.96%,较字级CNN基准模型分别提高了5.33%、3.57%和5.12%,这表明本文所提出的MTAD-BERTGCNN可以在中文疾病名称归一化任务上取得最优效果。通过各模型汇总分析,实验结果可归纳为MTAD-BERT-GCNN>MT-BERT-GCNN>BERT-Base>引入语义关系的CNN>字级CNN>词级CNN。

图4 实验数据对比分析
5 结论
本文基于多任务学习和多态语义特征提出了中文疾病名称归一化模型MTAD-BERT-GCNN,该模型能够更好地利用多任务学习捕获多态语义信息,通过共享多任务间权重参数以深度挖掘文本信息,从而达到最优效果。研究结果发现,在中文疾病名称归一化中:①字级CNN效果优于词级CNN,引入外部语义特征对实验效果有小幅提升,BERTBase较其他基准模型有大幅提升;②在CNN上融入GRU、LSTM、BiGRU和BiLSTM可捕获文本语义关系,进而提升中文疾病名称归一化效果;③基于多任务学习思路构建的MT-BERT-GCNN结合不同子任务的特点,通过优化任务间的共享参数,可进一步提升实验效果,并且引入辅助任务筛选特征构建的MTAD-BERT-GCNN可使中文疾病名称归一化效果达到最优,最终在Accuracy@1、Accuracy@5和Accuracy@10上的准确率分别达到了75.39%、86.66%和89.60%,在Accuracy@10上较词级CNN和字级CNN分别提高了12.96%和5.12%。本研究将多任务学习思路应用于中文疾病名称归一化任务,并在中文数据集上验证了模型效果,为中文疾病名称归一化研究提供了可借鉴的思路。
尽管国外对疾病名称标准化和归一化的研究较多,但中文领域疾病名称归一化研究尚未得到充分重视。在后续研究中,一方面,将考虑结合文本、图片、语音和视频等多模态信息,从多维度进行疾病归一化研究;另一方面,将深入挖掘文本细微特征,以进一步推动中文疾病名称归一化研究进展。
