基于VMD和IBA-LSSVM的短期风电功率预测
2021-11-24陈泽坤
王 瑞,陈泽坤,逯 静
(1.河南理工大学电气工程与自动化学院, 河南 焦作 454000; 2.河南理工大学计算机科学与技术学院, 河南 焦作 454000)
近年来为缓解能源紧张,减少环境污染,新能源的开发和利用持续增加,其中风能是具有巨大利用价值的新型清洁环保能源,被广泛应用于风力发电。未来的电力系统必然将为可持续的全球经济增长提供更高渗透率的清洁能源,然而大量清洁能源的不断接入给电力系统提出了前所未有的挑战[1]。对风电场的功率进行短期预测,可以使电力调度部门能够提前根据风电功率变化,及时调整调度计划,保证电能质量,降低电力系统运行成本,这是减轻风电对电网造成不利影响、提高电网中风电装机比例的一种有效途径[2]。
目前,国内外对于风力发电功率的预测已有了深入研究,按照预测模型的不同,可分为物理方法、统计方法和学习方法。其中,物理方法需要对所在风电场进行建模[3],由于受气象预报更新频率的影响,该方法更适合中期风电功率预测。统计方法包括回归分析法[4]、指数平滑法、时间序列法[5-6]和灰色预测法。这种预测模型计算简单,但随着预测时间的增加预测精度会快速下降,且不能很好地适应非线性影响因素。
学习方法包括人工神经网络法[7-9]、决策树[10-11]和支持向量机[12-14]等。其中,最小二乘支持向量机(least squares support vector machine,LSSVM)具有预测精度高、计算简单等优点。但是在实际的风电功率预测中,单一的预测模型存在局限性,无法取得最佳的预测效果,因此目前多采用组合预测模型,如周松林[15]引入粒子群算法(particle swarm optimization,PSO)优化LSSVM参数寻优,可有效缩短搜索时间,但存在过早收敛的问题。赵凤展等[16]采用蝙蝠算法(bat algorithm, BA)优化LSSVM模型,与PSO-LSSVM相比搜索过程具有更好的收敛性,但存在不能保持优化能力等问题。此外,组合预测模型中经常会用信号分解的方法,目的是将原始序列分解成一系列子模态以降低非平稳性,对分解的序列分别建立预测模型并重组来实现最终预测,如姜贵敏等[17]通过集成经验模态分解(ensemble empirical mode decomposition,EEMD)将功率历史数据分解为一系列相对平稳的子序列,解决了经验模态分解(empirical mode decomposition,EMD)方法所产生的模态混叠现象。变分模态分解(variational mode decomposition,VMD)是一种非递归、变模式的分解方法,克服了EEMD递归求解的缺点,具有更好的谐波分离效果[18]。
本文在现有研究基础上,提出了一种基于VMD和改进蝙蝠算法(improved bat algorithm,IBA)优化的LSSVM预测模型(VMD-IBA-LSSVM模型),并利用该模型对宁夏某风电场的发电功率进行预测,通过与其他几种典型模型进行比较来验证模型的有效性。
1 VMD方法
VMD是基于EMD提出的一种自适应、完全非递归的模态变分和信号处理的方法。与EMD相比,VMD对噪声和采样误差具有更强的鲁棒性。VMD的分解过程是变分问题的求解过程,可分为变分问题的构造和求解过程[19]。
1.1 变分问题的构造
步骤1对于每个模态函数,采用Hilbert变换计算相关的解析信号,以获得单侧频谱。
步骤2通过混合一个调谐到各自中心频率的指数项,将各个模态的频谱调制到相应的基频带。
步骤3由解调信号的高斯平滑度,得到的约束变分问题:
(1)
式中:{uk}、{ωk}——子信号及其相应的中心频率集合;k——子信号总数;t——采样时刻;δ(t)——狄拉克分布;f(t)——一个序列。
1.2 变分问题的求解
步骤1将约束性变分问题重构为非约束性变分问题,增广的拉格朗日表达式为
(2)
式中:λ(t)——拉格朗日乘法算子;α——二次惩罚因子。
步骤2通过交替更新uk,n+1、ωk,n+1和λn+1求解增广后拉格朗日表达式中的“鞍点”。VMD更新过程如下:
(3)
(4)
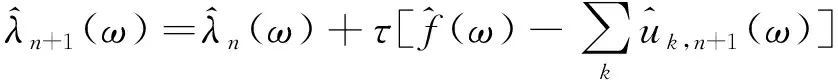
(5)
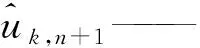
步骤3对于给定判别精度e>0,若满足式(6),则VMD收敛,停止更新。
(6)
2 基于IBA优化的LSSVM预测模型
2.1 LSSVM
LSSVM是一种新型支持向量机方法,LSSVM采用最小二乘线性系统作为损失函数,代替传统的支持向量机采用的二次规划方法。利用等式约束取代SVM中的不等式约束,将原问题转化为一个解线性方程组的问题。LSSVM的优化问题[20]可以转化为
(7)
式中:w——权向量;γ——正则化参数;ek——误差变量;φ(xk)——xk在特征空间的映射;b——偏置。
式(7)可采用拉格朗日乘数法把原问题优化,同时根据KKT最优条件求解。本文选择RBF函数作为LSSVM的核函数。此外,超参数(C,σ)的选取对模型的预测结果有显著影响,本文采用IBA对LSSVM模型参数寻优,建立最优预测模型。
2.2 IBA
BA是一种仿生寻优算法,模拟自然界中微蝙蝠的回声定位行为。BA将回声定位理想化,将蝙蝠种群初始化为一组随机解,然后通过调节蝙蝠发出的声波频率更新个体的脉冲速率和脉冲响度迭代搜寻最优解,且在最优解周围通过随机飞行产生局部新解,加强了局部搜索。
蝙蝠个体更新其声波频率、速度与位置,公式表述为
fi=fmin+(fmax-fmin)β
(8)
vi,t=vi,t-1+(xi,t-x*)fi
(9)
xi,t=xi,t-1+vi,t
(10)
式中:fmax、fmin——最大与最小频率值;v——个体速度;x——个体位置;β——[0,1]之间的随机数。
在局部寻优过程中,每只蝙蝠更新公式如下:
Xnew=Xold+εAt(ε∈[-1,1])
(11)
式中:Xold——当前最优解;ε——随机数;At=〈Ai,t〉——全部个体在第t次迭代时的平均脉冲响度。
当蝙蝠发现目标逼近时,会更新发射脉冲的发射速率和响度:
Ai,t+1=αAi,t
(12)
ri,t-1=ri,0(1-e-γt)
(13)
式中:Ai——脉冲响度;α——脉冲音响衰减系数;ri——脉冲发射速率;γ——搜索频度增强系数。
根据上述BA的优化原理可知,其参数更新方式相对固定,个体本身缺乏变异机制,致使存在后期收敛慢、收敛精度低以及容易陷入局部极小值等问题。为了克服BA的缺点,本文采用改进的惯性权重、自适应频率与变异机制来改善寻优过程[21],形成IBA。
公式(9)中,速度更新时添加惯性权重以改进速度更新的方向,使得种群中个体可以有效地跳出局部最优点:
(14)
式中:g——惯性权重因子;fit——适应度函数;N——种群数量。
当蝙蝠i的适应度低于平均适应度时,该蝙蝠将赋予较低的权重,增强其寻优全局更优解的能力;而蝙蝠i的适应度高于平均适应度时,该蝙蝠将赋予较高的权重,增加其跳出局部最优解的机会,间接增大该蝙蝠寻优全局最优解的能力,主要模仿粒子群算法的惯性权重策略。
在BA中,存在一些蝙蝠已经处在最优解边缘的,仍采用与平时一致的频率来寻优,最终会影响其寻找最优解的机会,因此采用自适应频率调整:
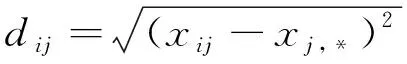
(15)
range=di,max-di,min
(16)
(17)
式中:di——第i个解到最优解距离;range——最大距离与最小距离的差值。
由此,速度更新公式变为
vij,t=vij,t-1+(xij,t-xj,*)fj
(18)
当蝙蝠都趋于收敛时,部分种群陷入了局部最优解,此时增加变异机制,跳出该局部最优解。本文采用的方法是产生一个随机数,当这个随机数大于变异概率的时候,对蝙蝠重新初始化。
2.3 改进的IBA-LSSVM预测模型的建立
为了进一步提高LSSVM模型的预测精度和速度,需要对模型的参数进行优化,优化步骤如下:
步骤1设定LSSVM模型中惩罚参数C、核参数σ的取值范围。
步骤2种群基本参数化,设定种群数个体xi(i=1,2,…,N)、脉冲频率最大值fmax和最小值fmin、脉冲响度Ai、脉冲发射率ri、空间维度d和最大迭代次数MI。
步骤3初始化种群中每只蝙蝠个体的位置xi和速度vi,其中蝙蝠i的位置代表着参数C和σ。
步骤4计算每只蝙蝠的适应度值,寻找当前时刻最优解。以蝙蝠位置对应的参数训练LSSVM模型,然后选取训练集进行训练和测试,按照降序排列,找到当前最优解。
步骤5分别按照式(8)(9)和(18)更新种群中各个蝙蝠个体的脉冲发射率、所在位置和飞行速度,采用改进的惯性权重、自适应频率与变异机制来改善寻优过程。
步骤6出现第一个随机数rand1,当rand1>ri时,根据式(11)更新出局部最优解Xnew。
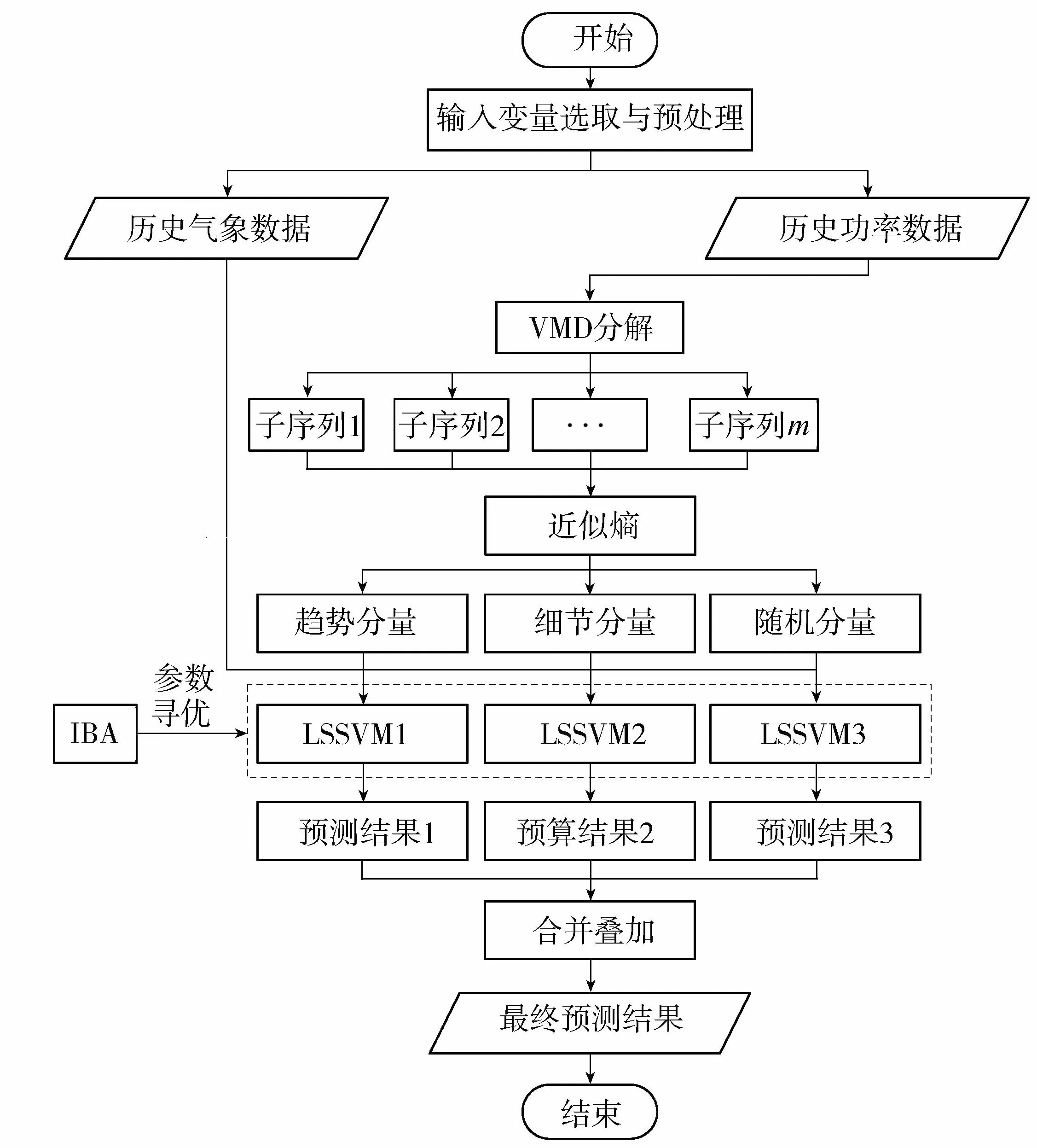
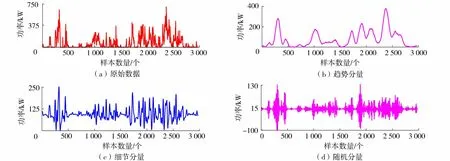
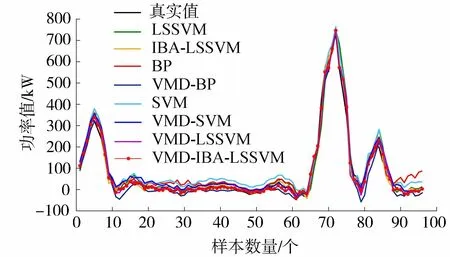
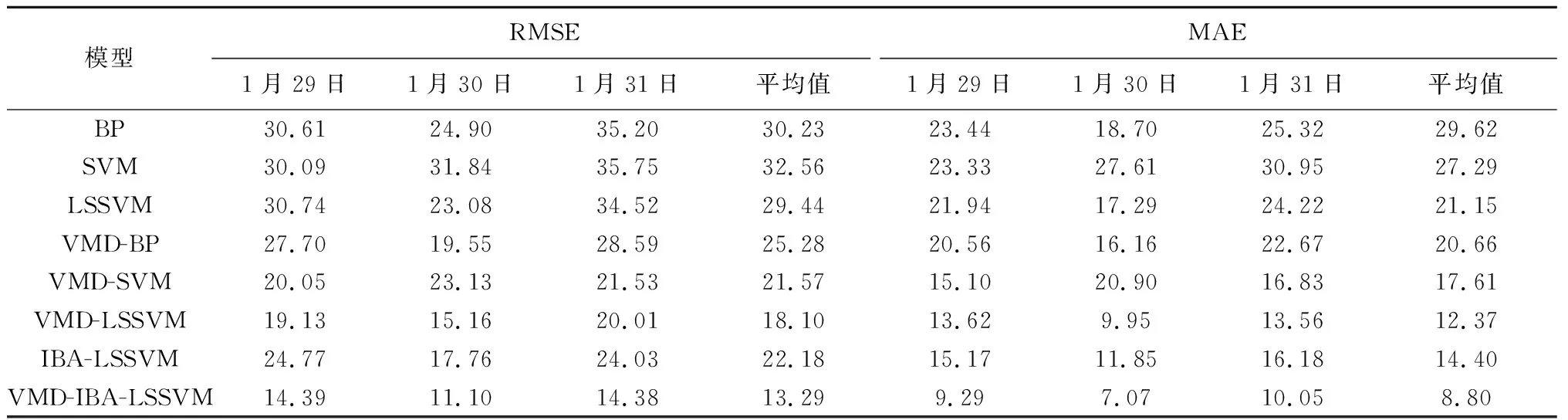
步骤7出现第二个随机数rand2,若rand2 步骤8对蝙蝠的适应度重新排序,确认当前最优值,重复迭代过程,直到满足设定的终止条件,停止循环并输出全局最优解。 VMD-IBA-LSSVM模型的建模流程为:①利用VMD将具有非线性、随机性的原始风电功率序列分解为一系列平稳的模态分量,根据各个子模态的近似熵的分析结果进行子序列重组,对于每个重组后模态分量,结合历史气象数据,分别建立第2.3节中的IBA-LSSVM模型; ②叠加各子模态模型预测值,得到最终的风电功率预测值。建模过程如图1所示。 图1 风电功率预测流程Fig.1 Flow chart of wind power prediction 输入变量的选取对预测精度有直接影响,本文将输入原始数据集分为历史气象数据和历史功率数据两类。其中历史气象数据包含多种风速等,历史功率数据作为输入变量的主体,需要进行VMD分解,而风速数据只需要加入分解后的子序列中。原始数据集中各个数据量纲不同,为了提高风电功率预测精度,需要进行数据标准化处理,将原始数据线性化转换到[0,1]的范围,归一化公式如下: (19) a.数据来源。以宁夏某风电场2017年1月1—31日的样本作为研究数据,数据包括24 h风电功率数据和日环境数据。数据采样时间间隔为15 min,总共96个点。在实际建模过程中,将2017年1月1—28日数据作为LSSVM模型的训练集,其余数据作为模型的测试集。 b.预测模型。本文VMD-IBA-LSSVM模型和BP、SVM、LSSVM、VMD-BP、VMD-SVM、VMD-LSSVM、IBA-LSSVM 7种对比模型。8种模型在输入量不变的情况下进行对比预测。 c.功率预测模型参数。在建立IBA-LSSVM模型过程中,惩罚参数C、核参数σ的寻优范围均为[0.001,1 000],IBA参数设置为:种群数大小N=10,脉冲频率最大值fmax=2,最小值fmin=0,解的维度d=2,脉冲响度Ai=0.9,初始脉冲发射率r0=0.5,最大迭代次数MI=1 000,惯性权重因子最大值wmax=0.5、最小值wmin=0.2。对比模型BP隐含层神经元数量为20,学习率为0.01,学习目标为0.001,迭代次数为5 000。对比模型SVM中的模型学习参数C与ε与LSSVM中参数选取均通过网格搜索法优化得出,参数范围为[2-8,28],迭代步长为0.1。 采用均方根误差(RMSE)和平均绝对误差(MAE)作为模型预测精度评价指标。 VMD的参数设置如下:惩罚参数C=2 000;模态函数个数K由于当其大于5后子序列趋于相似,因此取K=5;初始中心频率ω=0;收敛判据t=10-7。VMD分解效果如图2和图3所示。 图2 原始风电功率序列及VMD分解结果Fig.2 Original wind power sequence and VMD decomposition results 图3 原始风电功率序列及模态函数重构结果Fig.3 Original wind power sequence and modal function reconstruction results 从图2可以看出,原始风电功率被分解为多个存在不同波动性的子序列,若分别对各个子序列分别建立模型进行预测,不仅增加了任务量,而且忽略了各个子序列的相关性。本文采用近似熵度量各个子序列的复杂度,将具有相关性的序列进行重组,合并成新的序列,形成趋势分量、细节分量、随机分量,这样不仅可以有效缩短运算时间,而且可以更好地突显同类序列的特性[22]。 根据各分量的近似熵,图2(b)中第一分量为0.01数量级,图2(c)中第2分量和图2(d)中第3分量为0.1数量级,图2(e)中第4分量和图2(f)中第5分量为1数量级,按照数量级不同可以将子序列重新分组。即第1分量作为趋势分量,第2和第3分量组成细节分量,第4和第5分量组成随机分量,重构的新序列如图3所示。 分析图3重构后的分量序列,3种分量都具有各自明显的特点,其中趋势分量波动平缓,可以将原始序列的总体波动趋势表现出来;细节分量规律性较强,可以很好地表征出原始序列的细节波动;随机分量以很好地表征出原始序列的细节波动,随机分量具有一定的随机性和波动性表明了一些不确定因素造成的波动。 采用上述8种预测模型对2017年1月29—31日进行提前24 h风电功率预测,最后一天的预测结果如图4所示,可以看出VMD和IBA-LSSVM模型相较于其他对比模型可以更好地对真实曲线的波动规律进行预测,整体趋势与真实曲线更为贴合。而单一的预测模型在风电功率预测中其曲线明显滞后于实际曲线,采用VMD对原始序列进行分解,分别对各个分量建立预测模型可以改善这一现象,预测精度有不同程度的提高。 图4 不同模型1月31日功率预测曲线Fig.4 Power prediction curves of different models on 31st January 以上8种预测模型2017年1月29—31日预测误差及3日预测误差平均值如表1所示。 表1 不同模型预测误差对比 从表1预测误差值可以看出,VMD-IBA-LSSVM模型的RMSE和MAE均低于其他模型,证明该模型预测效果相比于其他模型更好。同时相较于单一的预测模型BP、SVM和LSSVM,经过VMD进行数据分解,建立组合预测模型的VMD-BP、VMD-SVM和VMD-LSSVM其预测性能都有不同程度的提高,其中RMSE精度分别提高了4.95%、10.99%和11.34%;MAE精度分别提高了8.96%、9.68%和8.78%。在运行时间方面,基础模型BP、SVM和LSSVM平均训练用时分别为9 s、384 s和127 s,虽然LSSVM耗时较长,但是预测效果最好。此外,采用IBA对LSSVM模型优化后,其训练时间缩短为48 s。分析对比LSSVM与IBA-LSSVM预测模型,在采用了IBA后,其预测精度具有明显的提高,在此基础上利用IBA-LSSVM预测模型对VMD技术分解的原始序列产生的各个变量分别进行建模,从而进一步提高了预测精度,RMSE和MAE分别仅为13.29%和8.80%。 a.针对具有非线性的原始风电功率序列,采用VMD分解为一系列平稳的模态分量,利用近似熵度量各个子序列的复杂度,将具有相关性的序列进行重组,降低了预测模型的计算规模。 b.针对LSSVM模型参数难以选取,影响模型预测性能,提出了采用IBA优化LSSVM的核参数选取,利用其全局寻优能力强、收敛精度高等优点,为重组后的子序列分别构建IBA-LSSVM预测模型,提高了模型预测精度。 c.VMD-IBA-LSSVM模型能有效对风电场的功率进行短期预测,从而可以及时调整调度计划,降低电力系统运行成本,具有一定的应用价值。下一步应对风电机组特性进行深入分析并考虑更多的环境信息作为输入样本,从而进一步提高其预测精度。3 VMD-IBA-LSSVM模型

4 算例分析
4.1 算例概况
4.2 评价标准
4.3 原始风电功率序列的分解结果

4.4 预测结果对比分析
5 结 论
