基于智慧矿山平台的人员定位系统关键技术
2021-11-23胡宏泽杜志刚
胡宏泽,杜志刚,储 楠,罗 克
(1.中煤科工集团常州研究院有限公司,江苏常州 213015;2.天地(常州)自动化股份有限公司,江苏常州 213015)
当今社会正处于数字化矿山向智慧矿山发展的重要过渡阶段[1-3],智慧矿山平台的建设要求包括人员定位系统在内的多异构系统之间能够实现多元数据融合和信息共享,特别强调了在紧急情况下的多系统之间的应急处理、预警和告警能力[4-7]。
现有的人员定位系统所采用的设计框架,业务模块大多集成在统一的项目框架中,同时为了实现数据共享和同步,各个模块之间的耦合性极强,任一业务功能的扩展往往会“牵一发而动全身”[8]。随着业务逻辑的不断深化和复杂化,项目规模会变得非常庞大,使得维护成本越来越高。通过对智慧矿山进行调研后发现,在我国大部分煤矿的人员定位系统中数据处理能力依然不足,特别对于人员实时轨迹、历史轨迹的信息显示依然存在着反应慢的问题,同时系统主数据结构仍然束缚在本系统之内,智慧矿山平台中其他系统若想调用本系统的数据往往需要进行二次设备部署和开发,这无疑对平台实现多系统的融合造成了极大的困难[9]。为此,通过对现有的人员定位系统存在的问题进行分析,提出了一种基于微服务架构的设计方案,引入时序数据库[10]和系统软总线结构,实现业务层级和系统层级间的轻量级通信机制,极大提高了人员定位系统在智慧矿山平台中的可扩展性和可移植性。
1 现有的人员定位系统架构
现有的人员定位系统中业务一般采用集中式管理,系统维护着一个统一的关系型数据库,各个业务模块之间的数据交互都是以这个数据库为中心进行。现有的人员定位系统架构如图1。现有的人员定位系统主要存在以下几个问题:1)业务之间耦合性强,可扩展性差。因为采用封闭式的系统架构,所有业务大多固化在一个复杂的单体应用中,随着业务需求的不断增加和处理逻辑的不断深化,项目中的代码的耦合度会越来越严重,每一个功能的开发都需要开发人员理清相关业务之间的逻辑关系,甚至极大可能会产生重复开发工作,这将使得系统的水平扩展性难以满足要求。
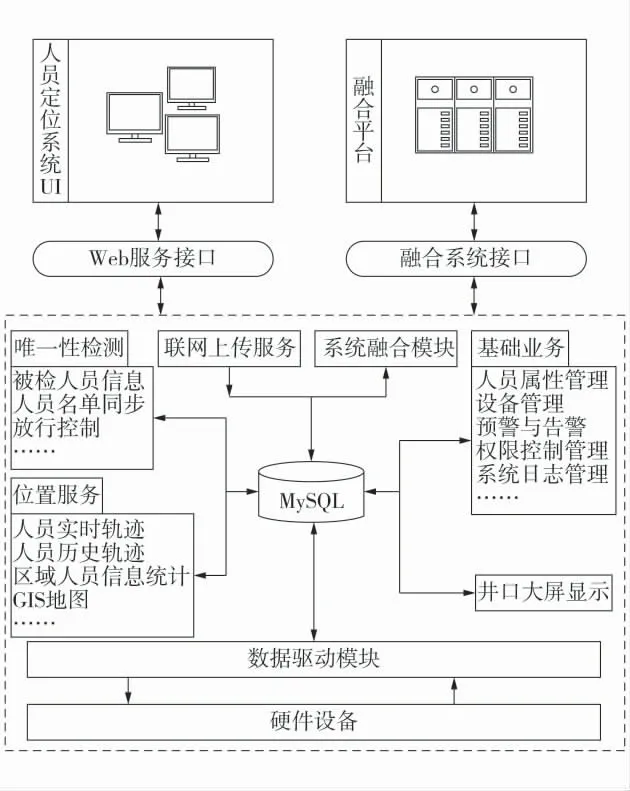
图1 现有的人员定位系统架构Fig.1 System architecture of current personnel positioning platform
2)无法弹性部署,难以维护。因为煤矿企业的业务需求往往千差万别,所以开发人员需要针对不同的煤矿企业的业务需求对人员定位系统进行私有化定制,这就导致同一个人员定位系统会存在非常多的系统版本,开发人员需要花费大量的精力进行版本控制,而且每一个功能模块的更改,都需要对整个项目重新打包、编译和部署,维护工作变得极其复杂。
3)数据库成为系统运行效率的瓶颈。系统中所有业务访问同一个关系数据库,每一个业务的处理能力都受到了数据库承载能力的制约。随着智能矿山平台的推进,现有的数据库结构显然已经成为制约着系统数据处理能力的关键因素。
4)多系统数据共享、融合能力差。外部系统对本系统访问的数据大多来自公共数据和实时数据,针对不同的数据访问需求,系统需要对现有数据进行结构化处理,往往会牵扯到过多的业务逻辑。
2 基于微服务架构的系统设计方案
2.1 微服务
微服务架构的核心思想是将一个复杂的单体应用,按照业务逻辑和使用频次拆分为多个公共服务和私有业务服务,每个服务之间都是松耦合的,可以独立部署,最终达到彻底的组件化、服务化和去中心化[11-12]。
因为业务按照微服务进行分散管理,所以开发人员在开发私有业务过程中,可以快速访问系统公共资源,无需考虑其他业务的影响,不仅减少了大量重复性工作,而且开发过程变得更为规范。同时,每一个服务都具备强大的水平扩展能力,针对不同煤矿企业的私有化定制需求,开发人员不仅可以对系统中的服务进行动态裁剪,而且还可以对每个微服务单独进行升级和部署,使得维护难度大大降低。
2.2 系统架构
针对现有的人员定位系统水平扩展性差、维护困难且无法满足智慧矿山平台对多异构系统间的数据融合和共享的需求的情况,从主流的微服务架构设计思想作为出发点,提出了一种基于微服务架构的人员定位系统设计方案。系统架构主要分为主引擎、硬件层、数据驱动层、软总线、服务层、接口层和交互层。
1)主引擎。主引擎是一个轻量级的应用服务引擎,主要提供公共服务、数据存储服务、部署管理和服务管理的功能。公共服务包括系统日志、权限管理、文件同步等系统公共业务;数据存储提供统一的数据库访问规范;部署管理提供平台无关性、一键化和自动化部署的支持;服务管理实现对服务的控制和服务间的数据共享。
2)硬件层。硬件层主要包括定位基站、网关、定位卡、接收器等设备。
3)数据驱动层。数据驱动层实现数据采集、数据接入、数据优化算法和控制命令解析的功能。数据采集就是根据不同的通信协议(Modbus-RTU、TCP/UDP等)将采集的信息进行解析和接收;数据接入是将接收的数据进行拆解,并且按照统一数据规范写入软总线中;数据优化算法主要提供高精度的定位算法和数据压缩算法等;控制命令解析负责将接收到的命令信息解析成硬件设备能够识别的命令字段,并且下发到硬件层。
4)软总线。软总线提供了数据访问、数据缓存、数据融合以及控制命令通道的功能。数据访问提供统一的数据访问接口,规范化数据访问格式。数据融合是将系统中重用性和共享性高的数据进行结构化统一构建;数据缓存存储公共数据、实时数据以及数据融合的结构化数据,并且按照统一的存储规范将数据存储到数据库;控制指令通道用于提供低延时、独立的指令传送机制。
5)服务层。服务层以微服务的方式加载和运行各个私有业务,例如唯一性检测、位置服务、井口大屏、GIS 服务、多系统融合、考勤管理和联网上传等私有模块。各个微服务之间是水平排列关系,开发人员在开发过程中,不仅可以从主引擎获取公共服务接口,而且还可以从软总线获取公共数据、实时数据以及数据融合的结构化数据,无需关心下层和数据库的具体实现细节,大大减少了重复性工作。同时,各个私有服务可在托管平台中,以Docker 镜像方式独立部署,实现服务之间的松耦合。
6)接口层。接口层主要包括公有业务的接口、私有业务的接口和多系统融合接口,为交互层提供了各类功能的WebAPI 接口和gRPC。其中公有业务接口由主引擎提供,私有业务接口由服务层各个私有服务提供,多系统融合接口由系统融合服务提供。
7)交互层。交互层包括移动端、PC 端和融合平台的用户交互。可采用前后端分离的开发技术[13],利用主流的Angular、Vue 等框架,最终实现一次开发,多平台运行,极大提高了开发人员的开发效率。
2.3 系统部署
在微服务的架构中,开发人员可将自己开发的业务、运行环境以及依赖包打包成Docker 镜像文件,系统中所有已经开发完成的业务则可以镜像文件的形式存放在镜像仓库中。微服务是基于云原生的技术,具备快捷的云端部署能力。因此不仅可在本地服务器上通过拷贝等方式获取全部的镜像文件,也可在云端的托管平台中通过Docker 命令的方式从镜像仓库中拉取所需的镜像文件。系统部署流程如图2。

图2 系统部署流程图Fig.2 System deployment process
开发人员在部署的过程中,可根据拉取的镜像文件创建和启动Docker 容器作为服务运行的载体。系统在启动时,首先运行系统框架中的主引擎模块,其中公共服务、数据存储服务等平台支撑的功能模块已经固化在了主引擎中;接着主数据、融合数据等会依次导入软总线数据缓存中;最后主引擎会加载所有容器中的私有服务,私有服务通过主引擎和系统软总线的接口实现对公共数据、实时数据和融合数据的访问。用户可通过Docker 的映射地址访问具体的业务模块,最终所有的服务都可动态配置和弹性部署,使得整个系统满足复杂化应用场景的需求。
3 关键技术
3.1 数据融合技术
智慧矿山平台的建设要求包括人员定位系统在内的各个子系统之间能够实现数据融合及信息共享。大多数煤矿企业中各个子系统都是由不同厂家开发和部署,因此不同系统之间的数据结构大多不同,这就导致了融合过程往往需要大量的重复性翻译工作。
设计了一种系统软总线结构。软总线确定了公共数据、实时数据和融合数据的描述规则和存储规范,它将人员定位系统中的共享性、公共性、重用性高的数据进行抽象和结构化存入数据缓存,并且为各个服务提供统一的数据访问接口和控制命令通道。同时软总线采用数据的订阅发布机制,数据的发布者称为生产者,接收数据的服务称为消费者,系统中各个服务都可通过软总线提供的接口订阅感兴趣的数据。控制命令通道存储生产者发布、消费者订阅的控制命令信息,这种异步消息传递机制确保了控制命令传递过程中的低时延和独立性。对于融合数据的访问接口,开发人员可根据融合平台需求创建融合接口服务,将软总线打包供融合平台调用,这样就可从软总线获取融合后的数据信息。
3.2 基于时序数据库的数据分类存储技术
现有的人员定位系统架构都是将系统主数据、融合数据、历史数据等存放在统一的关系数据库中。随着业务需求越来越多,统一的数据库存储逐渐制约着系统对数据的处理能力。
InfluxDB 是一个由InfluxData 开发的开源时序型数据库,着力于高性能地查询与存储时序型数据[14],被广泛应用于存储系统的监控数据。为了提高人员定位系统数据处理的时效性,可引入时序数据库对数据进行分类存储。例如MySQL+InfluxDB 的存储方案,将系统主数据、融合数据存入MySQL 中,并且同步软总线数据缓存。历史数据结构简单可存入InfluxDB 中,将极大地加快对历史报警信息、人员历史轨迹、设备历史状态等业务的查询速度。MySQL 和InfluxDB 查询速度对比见表1。

表1 MySQL 和InfluxDB 查询速度对比Table 1 Comparison of data query speeds of MySQL and InfluxDB
3.3 容器虚拟化技术
传统的虚拟化技术是通过中间层将1 台或者多台独立的机器虚拟运行与物理硬件之上,而容器则是直接运行在操作系统内核之上的用户空间。容器作为微服务运行的载体,就像是一个完整的宿主机一样,不仅具备独立的用户空间和运行环境,真正做到服务之间的隔离和松耦合,而且还支持网络端口映射、数据持久化以及资源管理功能[15]。Docker 是一个开源的应用容器引擎,开发人员可将自己开发的业务模块和依赖包进行打包,创建Docker 镜像文件,1 个Docker 镜像拥有完整的文件系统结构。当需要对业务进行部署时,开发者只需要在宿主机中根据Docker 镜像创建并运行Docker 容器,Docker容器类似于1 个镜像文件的运行实例,包含特定应用的代码及所需的依赖文件,最终用户即可根据容器的网络映射端口访问具体的业务模块。
4 结 语
1)基于微服务的人员定位系统架构,依托主引擎提供的公共服务、数据存储服务等基础支撑功能,实现了私有业务之间的按需分配,具备敏捷开发、弹性部署和维护简单的优势。
2)人员定位系统、安全监控系统等多源异构系统之间的数据融合、信息共享和大数据处理能力是实现智慧矿山平台的重要前提。软总线结构构建了统一的数据的接入和存储规范,引入时序数据库实现了对海量历史数据的高效查询,以Docker 容器作为运行载体的微服务之间相互隔离,方便开发人员可对融合接口服务进行独立升级和部署。
