基于用户生成文本的图书标签关联规则识别方法
2021-11-22张劲松
张劲松
(山东管理学院图书馆 济南 250357)
0 引 言
大数据背景下,海量用户文本为数据分析与知识发现提供了丰富的语料来源。用户围绕图书、影视等网络资源,进行标签标注、在线评论、社会交往等活动,逐渐形成各类在线用户社区(Online User Community)[1]。研究如何从在线用户社区中,识别用户的动态兴趣特征,刻画其情感倾向,对实现用户个性化推荐,完善商品营销策略等具有重要的研究价值。
当前,推荐算法可分为基于用户的协同过滤(Collaborative Filtering)[2]以及基于文本的内容发现方法(Context-Based Recommendation)[3]。基于用户的协同过滤方法通过识别用户对兴趣项目的评分,获取最小近邻偏好矩阵,并以此为基础计算用户之间、用户与项目之间的相似度。如汪圳[4]等提出一种基于用户情景感知的图书协同过滤方法,该方法通过构建包含用户属性要素特征、图书使用行为、图书需求场景等的多维特征矩阵,实现用户图书需求的多项目协同过滤推荐。胡代平[5]等将用户借阅行为与图书标签相融合,提出一种基于动态用户阅读偏好的高校图书推荐方法,该方法通过识别读者偏好属性,实现平滑时间维下偏好特征的在线计算。基于用户的协同过滤方法适合数据规模较少且特征区分度较高的图书项目,缺点是在用户数据稀疏时用户标签属性建模存在冷启动问题。基于文本的内容发现方法通过分析用户的文本信息,以用户画像、兴趣标签标注等形式识别用户的兴趣特征,最终实现用户与项目资源间的语义匹配。如李晓敏[6]等提出一种基于用户画像的图书推荐方法,该方法通过抽取用户的多维属性特征,实现用户综合画像,并通过相似度计算推荐相似读者与相似图书。张彬[7]等提出一种基于多源标签的兴趣融合方法,该方法首先将读者与项目划分成不同的层次,并对相邻域进行标签权重计算,最终得到读者的综合兴趣标签集。
随着社交网络技术的快速发展,包含大量用户行为、兴趣、主题等的用户生成文本(User Generated Content)越来越受到关注[8-9]。面向用户生成文本的图书推荐发现,能够识别读者的兴趣热点,实现读者与图书间的内在关联挖掘,从而精准定位读者需求。基于用户生成文本的推荐方法与基于文本的内容发现方法相类似,不同之处在于,前者突出与用户评论相关的文本感知与情感描述,通过概率计算、主题分析等方法,刻画读者的内在图书需求。如颜端武[10]提出面向知识服务的推荐方法,该方法以用户生成文本为数据来源,通过挖掘用户的兴趣特征,建立用户兴趣方法,再从兴趣资源建模的角度,构建基于领域本体的图书可视化平台,最终利用文本相似性刻画用户与资源间的关联关系。武雅利[11]基于情感词典提出面向用户生成内容的个性化情感分析方法,该方法通过定量分析用户对文本的情感值,实现了用户对商品资源的有效推荐。此外,考虑到用户生成文本的文法随意、结构不规范等特点,其质量会影响对用户的兴趣偏好识别以及标签标注,因而也有学者针对面向推荐的用户生成文本质量进行研究,如钟将等提出一种基于主题特征格的用户生成文本质量评估方法[12],该方法通过定义文本质量评估函数,基于主题模型构建商品分类体系,最终以概念格的形式生成具有强关联关系的评论特征格。多数基于用户生成文本的图书推荐方法无法有效融合读者的情感特征与图书资源的主题特征,缺乏对用户间聚类关系的概念级多粒度表示能力。
针对以上问题,本文通过挖掘用户标签隐藏的主题依赖关系,将模糊关联规则引入图书标签挖掘方法中,提出一种基于用户生成文本的模糊关联规则识别方法,该方法首先通过识别用户书评文本的主题特征,建立图书标签特征矩阵,实现图书的主题聚类。其次,通过计算不同用户间的主题相似度,获取候选用户集,再利用文本情感分析,得到用户对标签的情感评分,并以此为基础,建立标签模糊形式背景。最后,基于标签模糊概念格,定义模糊关联规则,利用隶属度置信阈值、隶属度期望等参数刻画图书标签间的模糊依赖关系,获取图书资源间的蕴含依赖关系,最终实现图书标签关联规则识别。
1 图书标签关联规则识别
RFAR方法首先将用户对图书的评论数据作为目标数据集,经过预处理等操作后,通过识别图书标签的主题特征,建立图书-主题分布矩阵;其次,通过计算不同用户的图书标签特征矩阵的余弦相似度,构建目标用户对象集,同时采用基于情感词典的文本情感分析,计算用户对不同标签属性的情感评分,据此建立用户对象与标签属性间的模糊关系映射,得到标签模糊形式背景;最后,依据模糊概念格生成算法,构建标签模糊概念格,并结合定义的模糊关联规则,从模糊概念层面挖掘主题特征间的模糊依赖关系。
1.1研究框架本研究框架如图1所示。
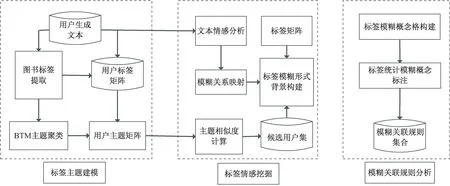
图1 研究框架
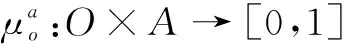
标签模糊形式背景将用户标注的标签集表示成一组内涵模糊属性集,便于从标签的文本信息中获取用户对图书的情感倾向,从而实现基于情感分析的多粒度关联分析。
定义2 (标签模糊概念):对标签模糊形式背景Kf=(O,A,I)上的二元组(U,V),对任意子集U∈O,V∈A,均存在公式(1)、公式(2)映射关系,则称该二元组是满足隶属度置信阈值λ下的一组标签模糊概念,记为Cf(U,V)。
(1)
(2)
通过调节隶属度置信阈值λ,能够调整标签模糊概念中对象的数量,根据需要构建具有实际意义的内涵模糊概念,从而将对象与属性间的模糊二元关系转化成标签模糊概念的粒度表示。
(3)
1.3标签主题建模RFAR方法主要针对在线图书社区的用户文档进行主题建模,多数用户通常是以书评的形式发表包含创作、学术以及情感评价等短文本。本文通过分词、去停用词等文本清洗操作后,采集到的有效用户评论文本的平均长度为120。但由于LDA主题模型通常不适合挖掘短文本数据[13],同时无法有效解决高频无效词对主题概率分布的影响,因此,首先引入TF-IDF算法获取文本特征词的统计信息,提高文档主题分析的可解释性,然后采用BTM(Biterm Topic Model)短文本主题模型实现主题聚类,改善数据稀疏文档的主题识别能力。
1.3.1 图书标签提取 TF-IDF(Term Frequency-Inverse Document Frequency)算法是一种计算文本词频的统计方法,可用于评估语料库中具体词汇在所有文档中的重要程度[14]。因此,本文基于TF-IDF计算文档评估短语的词频特征,具体计算过程如下:首先统计文本中每个词汇的出现频率(TF值),同时计算相应词汇的逆向文档词频(IDF值),再通过计算TF与IDF的乘积,得到文档词汇的TF-IDF词频。其计算方法如公式(4)所示。
(4)
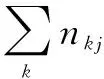
1.3.2 BTM主题聚类 BTM主题模型是一种面向短文本的主题学习模型[15],该模型基于离散词共现的基本思想,将文档表示成若干话题的概率集合,将话题表示成若干词汇的概率集合,并通过构建“文档-主题-词汇”的三层Bayes概率模型,实现文本的主题聚类。
本文将BTM主题模型的文档视为图书标签集合,文档词汇视为用户标签,识别标签的主题信息,具体计算流程如下:
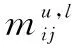
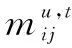
1.4标签情感挖掘
1.4.1 主题相似度计算 以用户-主题概率矩阵为基础,计算不同用户间的主题相关性。采用余弦相似度计算用户间的主题相似距离,得到候选目标用户集U(u1,u2,…,un),计算如公式(5)所示。
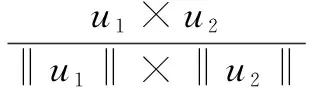
(5)
式(5)中,pmj与pnj分别表示用户u1,u2对主题的标注概率;m,n分别表示用户u1,u2标注的主题数;r=max(m,n)。
1.4.2 文本情感分析 用户通过描述型、情感型书评表达与原创作者在情感上的共鸣或差异,从而显露出对不同标签的情感倾向[18]。挖掘用户间的相似情感,能够最大限度地还原用户对不同标签主题的情感评价,从而在标签主题聚类的基础上,增加对标签情感的程度刻画。本文基于WordNet情感字典[19]识别隐含在用户标签中的正负情感倾向,并将其量化成用户对标签属性的情感评分,实现用户与标签间的模糊关系映射。具体实现过程如下:首先从用户文本中抽取标签及其评论文本,分别建立标签-评论文本矩阵,再从评论文本中抽取情感词,计算用户对标签的情感值,计算如公式(6)所示。
(6)
式(6)中,|D|表示用户文本中标签数量;d表示D中所含的标签;sd(u)表示文本d中用户的情感值,计算如公式(7)所示。
(7)
式(7)中,m,n分别表示情感字典中正、负情感词数;pwi,nwj分别表示情感字典中的正、负情感词;SimPos(w,pwi),SimNeg(w,nwj)分别表示正、负情感相似度。
1.4.3 标签模糊形式背景构建 通过识别用户对标签的情感倾向,经过归一化处理后,得到用户-标签情感评分矩阵,以此作为用户与标注标签间的模糊关系,从而构建标签模糊形式背景,具体流程描述如下:a.对于给定的用户ui,带入公式(4)计算主题相似度,得到目标用户对象集U(u1,u2,…,un);b.遍历用户对象集,从用户-标签矩阵Mu,l(i,j)中选取标签l的TF-IDF词频排名靠前的top-n,并分别将其映射到属性集A(a1,a2,…,am);c.抽取包含标签l的四元组<句子,属性,情感词,情感评分>,其中情感评分由公式(5)和公式(6)计算得到;d.整合用户关于标签l的所有句子评价信息,得到用户对标签属性的综合情感评分,并以此作为用户u关于标签l的模糊关系值。重复上述步骤,最终实现标签模糊形式背景的构建。
1.5模糊关联规则分析基于模糊概念格的关联规则分析,通过将模糊概念的内涵属性映射到模糊关系集中,挖掘满足支持度和置信度的频繁项集,从而发现概念节点之间的强关联关系,并通过调整支持度与可信度阈值参数,从模糊依赖关系角度强化了标签模糊概念的粒度信息。为便于识别模糊关联规则,参考文献[20]在模糊概念的数据结构中添加属性的统计特征,利用概念节点间的偏序关系,实现频繁项集的动态提取。相关定义如下:
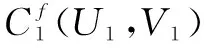
通过构造标签统计模糊概念,并基于定义5提取频繁概念节点及其偏序关系,构造满足模糊依赖关系的模糊关联规则格[22]。本文首先更新标签模糊概念,添加用户对标签的隶属度,构建标签模糊概念格;再从格结构约束中,提取模糊关联规则。限于篇幅,关于模糊概念格的构造过程,可参见文献[23]。模糊关联规则的提取过程算法如下:

Input:(FC(Kf),≤),隶属度置信阈值λ,隶属度期望阈值δ,隶属度方差阈值ω,支持度阈值ψ,置信度阈值ζ。Output:频繁概念节点集F,模糊关联规则集AR,二元概念组BR,支持度Sup(R),可信度Con(R)。GetFC(Kf) from (FC(Kf),≤) //抽取标签模糊概念集合 For i=1 toN // ComputeE(Vi), σ(Vi) UpdateC'i=(Ui,Vi,E(Vi),σ(Vi),parent,children) //更新模糊概念节点 AddC'i to FC'(Kf) For j=1 toM IfE(Vi)>δ and σ(Vi)<ω For eachC'i≥C'j⇔Vi⊆VjSup(R)=E(Vj) //计算支持度Con(R)=Normalized(σ(Vj)) //计算可信度F=F∪C'i Endfor IfC'i.parent or C'i.children∈ F BR= BR∪{C'i.parent∪C'i.children} //遍历频繁概念节点父类与子类节点信息 Endif Endif Endfor If λ≤C'1.μv1u1≤C'2.μv2u2 //利用置信阈值抽取模糊概念Choose R:V1⇒V2-V1 from BR //提取模糊关联规则 IfSupR >ψ and ConR >ζ //调整阈值,得到强关联规则 GetAR= AR ∪{R, Sup(R), Con(R)} Endif EndifEndfor
2 实验结果与分析
2.1实验来源实验数据来源于知乎读书会社区,选取2021年3月10日-5月10日内评论数排名靠前的1 000本图书,涵盖读者46 732人,有效书评文本数123 062份。首先使用中科院的ICTCLAS软件对书评文本进行分词,得到(用户,词汇)矩阵,再基于TF-IDF模型计算用户文档词的词频数值,选取用户文本中的高频词作为图书的标签集,建立(用户,标签)关系矩阵,其中矩阵元素表示用户标签的tf-idf值,表1是部分用户标签的tf-idf值。

表1 用户-标签的tf-idf值(部分)
2.2实验结果
2.2.1 标签主题建模 将用户的标签矩阵作为子文档集,对标签进行编码表示。使用Pathon编写程序进行BTM模型训练。其中,文档在不同主题数下的困惑度,如图2所示。由图2可知,在主题数K=40时,困惑度取到最小值(0.934),此时方法性能最佳,因此设置主题数为40,经过1000次抽样迭代后得到不同用户的标签-主题概率矩阵,如表2所示。将用户-标签矩阵与标签-主题概率矩阵进行内积计算,构建用户-主题概率矩阵,如表3所示。
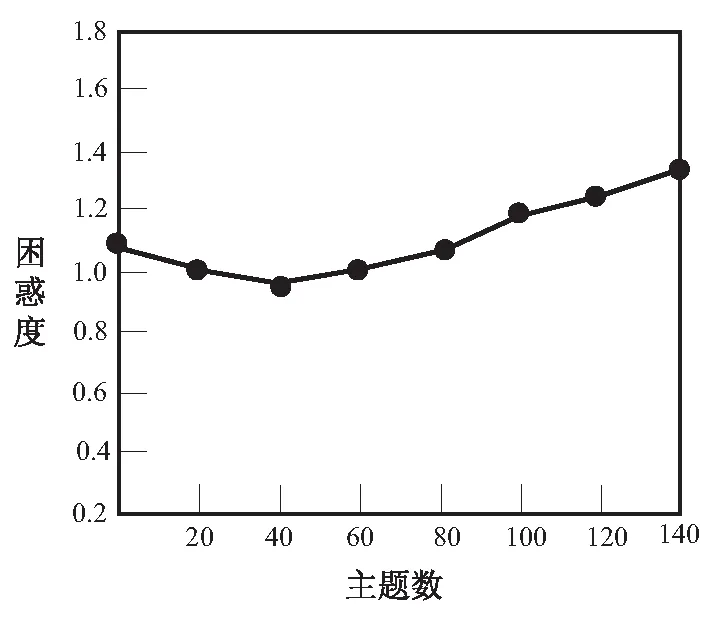
图2 不同主题数下的困惑度取值
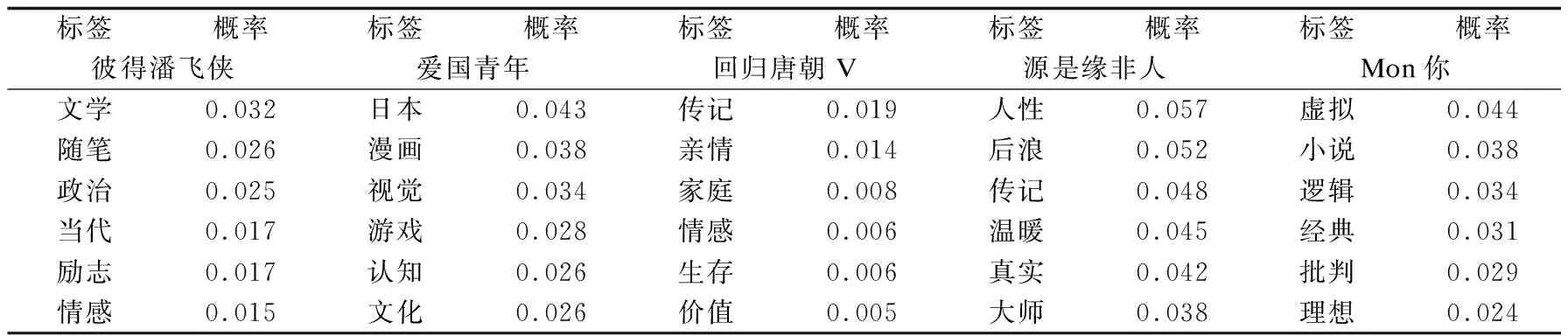
表2 用户的标签-主题概率矩阵(部分)

表3 用户-主题概率矩阵(部分)
2.2.2 标签情感挖掘 通过分析用户在主题上的相关性,得到其在不同主题上的相似度距离。RFAR方法采用余弦相似度计算用户间的主题相似度。以用户“彼得潘飞侠”为例,得到与其存在主题相似性的候选目标用户集。相似度较高的Top10用户如表4所示。
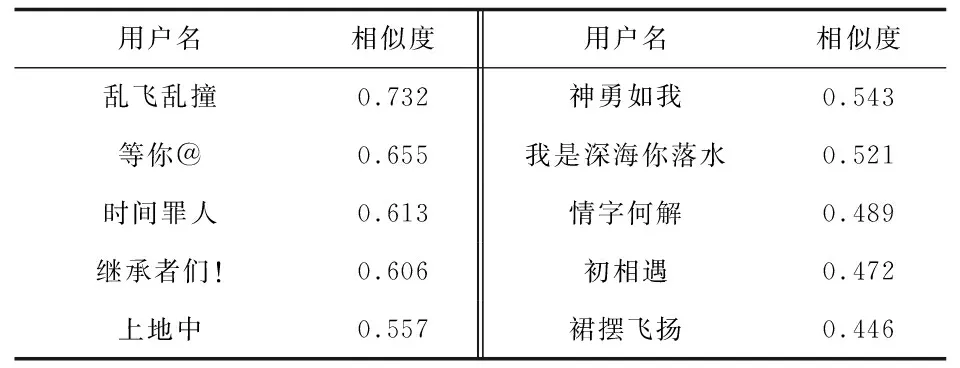
表4 “彼得潘飞侠”的主题相似用户
通过计算用户间的主题相似性,构建用户对象集合。基于情感字典识别标签所属文本的情感词,分析隐含在用户标签中的情感倾向,利用公式(6)和公式(7)计算用户对标签属性的情感评分,并以此作为标签模糊形式背景中对象与属性间的模糊关系。然后依据1.4.3节的描述过程,构建标签模糊形式背景,结果如表5所示,表中数值表示用户对标签的情感评分,其中负值表示用户对该标签具有负向情感。
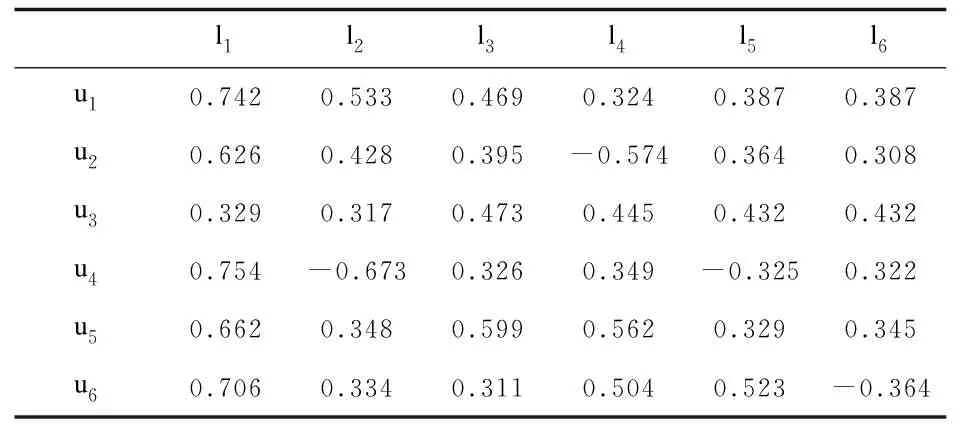
表5 标签模糊形式背景(部分)
2.2.3 参数分析 本文通过融合读者标签的主题特征与情感评分,建立标签模糊概念格,诱导出图书标签的模糊关联规则,实现图书标签的语义发现。参数阈值对标签关联规则的影响,分析如下:
a.隶属度置信阈值通过调整满足用户对象与标签属性的概念数,达到影响标签模糊概念生成规模的目的。为了得到具有实际意义的标签模糊概念,实验选取不同的隶属度置信阈值λ,观测实际获取的标签模糊概念数,结果如图3所示。由图3可知,伴随着λ取值的逐渐增大,获得的有效标签模糊概念数逐渐减少。在λ取值0.32时,标签模糊概念数取到均值865。
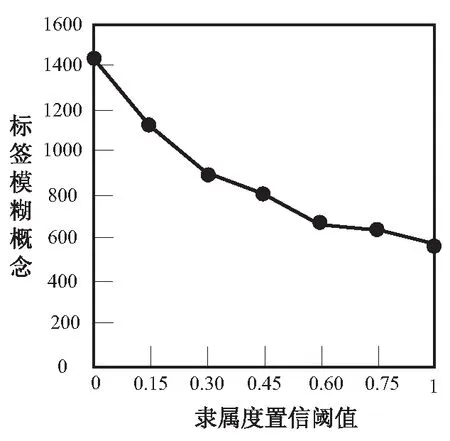
图3 隶属度置信阈值对标签模糊概念的影响
b.隶属度期望表示标签统计模糊概念所含有的平均属性数,体现了概念本身的属性模糊度。通过调整阈值δ,能够控制标签统计模糊概念所含的属性规模。在λ=0.32时,通过计算每个概念的内涵标签属性数,取其均值0.36作为隶属度期望阈值δ的取值。隶属度方差则反映了用户对象对标签属性的情感评价偏离程度。阈值ω设置为所有标签统计模糊概念中隶属度方差的均值,取值0.0126。
c.通过调整支持度阈值与置信度阈值,能够控制模糊关联规则的数量。RFAR方法按照步长0.2分别对ψ,ζ赋值,提取到的关联规则数如表6所示。分析表6可知,当ψ=0.4,ζ=0.8时,获得的关联规则数最接近平均值。

表6 支持度与置信度阈值对生成关联规则数的影响
2.2.4 模糊关联规则挖掘 首先采用Godin[24]渐进式算法,基于标签模糊形式背景构造模糊概念格(λ=0.32)。然后依据定义3计算模糊概念属性的统计特征,并将结果加入候选频繁概念节点集,将标签模糊概念格转换成标签模糊关联规则格,结果如图4所示。统计模糊概念信息如表7所示。
图4中的标签模糊关联规则格共包括26个统计模糊概念节点,依据模糊概念节点间的上下位关系,可以分成7个层级。节点所在层级越高,其包含的对象就越多,内涵模糊属性则越少,如表7中节点2-节点4,含有5个对象,1个属性。随着层级的不断增加,节点所含的对象逐渐较少,最终缩减成仅含有一个对象的概念节点,如图4中灰色节点表示仅含有1个用户的统计模糊概念节点。针对此类节点展开分析,能够实现用户的个性化阅读兴趣分析。
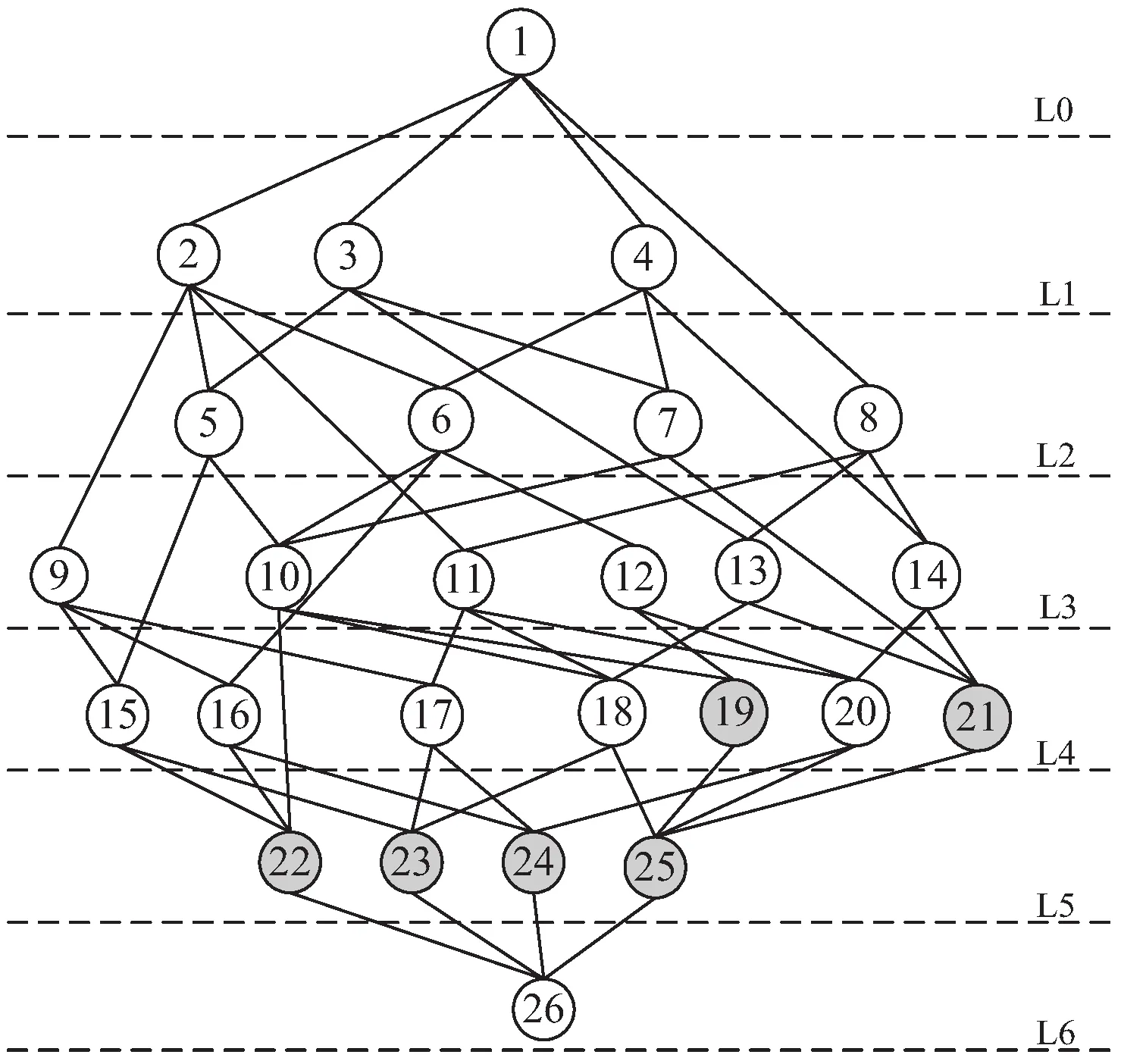
图4 标签模糊关联规则格

表7 统计模糊概念信息
此外,分析表7可知,统计模糊概念的隶属度期望并未随着节点所含属性的增加而增加,而是呈现出数值波动的变化特点,此结论表明标签的平均模糊程度不仅取决于其概念节点所含的属性个数,还与读者对其的情感评价有关。另一方面,数值较大的隶属度方差主要集中在标签模糊关联规则格的较低层级(L4,L5),体现出读者对标签的评价偏差较大。
采用定义5的方法标记频繁概念节点及其偏序关系,分别计算其支持度与可信度;再从格结构中检索出满足参数阈值的统计模糊概念及其父子关系节点,提取模糊关联规则。依据2.2.3节的阈值参数设置方法,由表7生成的部分模糊关联规则如表8所示,为便于说明,将表7中标签属性还原成具体的标签内容。
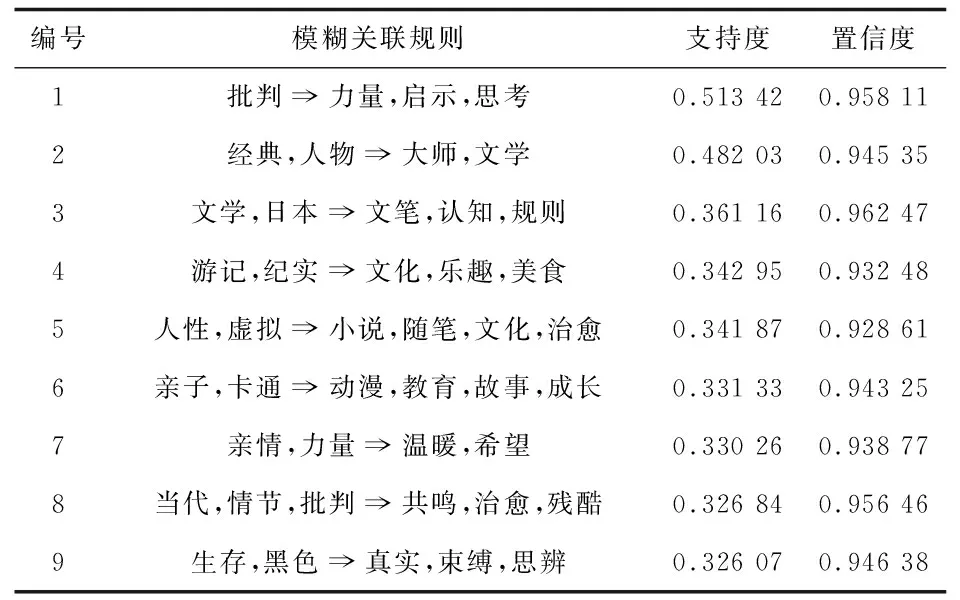
表8 模糊关联规则
2.2.5 图书标签推荐 a.基于模糊概念的用户发现。由于标签模糊关联规则格中,模糊概念体现了外延对象与内涵属性间的模糊伽罗瓦连接,所以在一定程度上,表达了不同用户群对图书标签的情感评价程度。如表7中的概念15,体现了用户u3,u6对标签l4,l5,l6的情感评价程度。
此外,在满足阈值的条件下,模糊概念格的概念节点之间具有偏序关系,层级越高,其聚类的用户对象越少,相应地标签属性的数量则越多,反之亦然。利用模糊概念格的上述特性,可以从两个方面进行用户或标签推荐:一方面,若想推荐与用户u1具有类似兴趣的用户群,可以先定位到仅含有对象u1的概念节点(编号24),再向上检索其父类节点(编号16,17,20)及其感兴趣的标签属性(l1,l3,l4,l5,l6),实现“以书会友,以文化人”的朋友圈推荐。另一方面,通过查询模糊概念格中层级较高的概念节点,如检索仅含有l1标签的概念节点(编号4),通过关联与其相关的图书信息,可以实现满足用户多样化需求的图书推荐。
b.基于模糊关联规则的标签发现。由于模糊关联规则格是在标签主题聚类的基础上,增加用户对标签情感的程度刻画。由此生成的模糊关联规则不仅仅能够反映标签间的主题相关度,更能够体现用户对不同标签的情感关联度,从而在标签的情感维度上建立起可以量化的关联关系,如规则1反映出在置信度为0.95811,支持度为0.51342时,批判类作品与包含力量,启示及思考内容的作品间的模糊关联关系。
另外,考虑到用户生成文本的语言特点,大量的用户评价是以信息缺省的方式存在,利用模糊关联规则能够实现一定程度的知识推理,从而实现非完备形式背景的知识填充。如用户“就是希望”发表的评论:“挺喜欢看当代题材的,但有时往往读起来比较伤感”。此时基于规则8,可知该用户也可能不喜欢情节类与批判类的书籍,从而有选择性地推荐其感兴趣的图书资源。
3 结 语
本文通过识别用户生成文本的主题特征与情感特征,提出一种基于用户生成文本的模糊关联规则识别方法,该方法通过计算不同用户间的主题相似度,实现用户间兴趣的主题聚类,再利用文本情感分析,建立用户对标签的情感模糊关系映射。基于标签模糊形式背景,构建标签模糊概念格。最后将标签属性的统计特征引入模糊关联规则的定义中,量化标签间的蕴含依赖关系,实现多粒度的模糊关联规则识别。未来的研究可以将文本主题识别与粗糙概念格[25]、三支概念格[26]等理论相结合,提升方法在模糊知识建模上的鲁棒性。
