基于智能主题图的科技文献细粒度知识组织模型*
2021-11-22秦春秀郑梦悦马续补赵捧未
秦春秀 郑梦悦 马续补 赵捧未
(西安电子科技大学经济管理学院 西安 710071)
0 引 言
作为知识的重要载体,科技文献是科研成果和科技创新的重要体现。现有的科技文献检索系统大多是以篇为单位组织资源,检索系统只能反馈整篇科技文献,科研人员需要花费大量时间和精力在每篇文献中寻找需要的知识单元。在科技文献海量的今天,这一检索方式不能满足科研人员们精准化的检索需求。为此,研究科技文献的细粒度知识组织方法,为用户提供精准化的细粒度知识单元服务显得尤为迫切。
针对上述问题,学者们已经开展了科技文献细粒度知识组织方法的研究。科技文献细粒度知识组织方法是以知识单元为基础,揭示文献内部知识内容的知识组织方法[1]。目前基于知识单元的细粒度知识组织有很多研究与应用,如刘东亮针对情报信息挖掘过程中数据存储负载过高的问题,设计了一种基于知识单元挖掘的网络文库信息存储模型,能有效降低文库信息负载[2];李卫民等基于实时动态捕获和挖掘前沿性文献信息资源,提出了基于知识单元挖掘行业前沿文献信息资源的模型,精准化深度服务特色学科专业建设,成为行业内关注焦点[3];秦春秀等从细粒度的角度深入到科技文献内容中,构建了一种面向科技文献知识表示的知识元本体模型[5-6];李祯静等基于语义链接网提出一种基于知识单元的细粒度知识组织方法,通过实验证明该方法具有良好的查全率和查准率[7];刘杰等以知识元理论为基础,通过对知识元进行抽取、标引、连接、集成,构成四层次六梯度的知识元映射,并对其进行了示例和讨论[8]; 谢庆球等提出一种知识元链接的文本资源空间模型及其构建方法,并进行了实验模拟,结果表明该方法在一定程度上是可行的[9]。可见,知识单元在实际应用中取得了较好的成效。但现有的细粒度知识组织方法存在以下不足:细粒度知识组织过程中的语义链接大多是在语法层次上进行操作,没有全面考虑知识单元的语义相似性和语用关联;大部分细粒度知识组织方法只是对索引简单模型化,没有实现对知识单元导航;没有充分考虑知识单元主题间的句法匹配、语义匹配以及语用关联关系;在对知识单元处理的过程中,抽取知识单元的关键词的方法有一定的局限性。
作为主题图的一种,智能主题图[10-11](Intelligent Topic Map,ITM)不再局限于只是把索引模型化,而是扩展到对文本内容中的知识单元进行导航,实现对文本内容的检索。智能主题图具有知识结构化的特点,通过建立主题之间的关联、知识单元之间的关联、主题与知识单元之间的关联等,侧重知识间的关联性,能较好地表达知识间的相互关系,实现对资源的准确定位,有助于用户快速定位相关的资源,节省检索时间。为此,本文以智能主题图为理论基础,探索对科技文献内部知识的有序化,从细粒度角度出发抽取文献中的知识单元,建立主题间、知识单元间以及主题与知识单元间的关联,最终尝试构建一个基于智能主题图的科技文献细粒度知识组织模型。
1 基于智能主题图的科技文献细粒度知识组织模型
本文提出的基于智能主题图的科技文献细粒度知识组织模型是从细粒度知识单元角度出发,由科技文献的主题、知识单元及它们之间的语义关系组成,能表达知识资源多层次、细粒度的知识资源特征,建立“主题-知识单元-文献”三者之间的关系。这个模型包括七个要素:主题、主题关联关系、知识单元、知识单元关联关系、主题与知识单元关联关系、科技文献、科技文献与知识单元之间的关系,如图1所示。

图1 基于智能主题图的科技文献细粒度知识组织模型
本文提出的基于智能主题图的科技文献细粒度知识组织模型简称为TSLM(A fine-grained knowledge organization model for scientific and technical literature based on topic map),它可形式化描述为一个七元组如下:
TSLM=(SL,KU,T,Akk,Akt,Att,ET)
SL(Scientific Literature)= {sl1,sl2,sl3,…… ,sln}为该模型所组织的科技文献集合,对应图中的“资源层”。
KU(Knowledge Unit)= {ku1,ku2,ku3,…… ,kun}为从科技文献中抽取出来的知识单元集合,对应图中的“知识单元层”。“知识单元层”是由从科技文献中抽取出来的知识单元以及它们之间的关联组成。集合中的每个知识单元按照如下的六元组形式化描述:
ku=(id,st,kw(kw1,kw2,kw3,…… ,kwn),text,type,title)
其中,id(identification)为抽取知识单元时所赋予的编号,可以唯一识别该知识单元;st(subject term)为描述该知识单元核心内容的主题词,表现为一个短语或一个短句;kw(keywords)为提取知识单元核心内容的关键词集合,每个kwn表示一个关键词;text为知识单元的内容文本;type为知识单元的类型,比如数值型知识单元、事实型知识单元、概念型知识单元等;title为知识单元来源文献的标题。
T(Theme)={t1,t2,t3,…… ,tn} 为主题集合,从第一层到第N层代表主题层和聚类层,层级越大说明该主题概念越抽象,涵盖范围越广,越往下其涵盖范围越小。其中,除顶层无父主题,第一层无子主题,其它每一层都是上一层主题的子主题,同时也是下一层的父主题。图中同层之间的连线表示主题与主题之间的关系,上下两层主题之间的连线表示上层主题与下层主题之间的隶属关系。
Akk(Association between Knowledge Unit and Knowledge Unit)={Akk1,Akk2,Akk3,…… ,Akkn}表示知识单元之间的关系,如相似关系、创新关系、相关关系、继承关系、属性关系等[3]。其中,知识单元的相似度关系最为常见,实际应用中也更为广泛[4],为此,本文在细粒度知识组织过程中只考虑知识单元的相似关系。
Akt(Association between Knowledge Unit and Theme)={Akt1,Akt2,Akt3,…… ,Aktn}表示知识单元与主题之间的联系。
Att(Association between Theme and Theme)={Att1,Att2,Att3,…… ,Attn}表示主题与主题之间的关联[5]。
ET(Extract)表示知识单元抽取方法,其含义为从科技文献中抽取表示科技文献内容的知识单元。
2 基于智能主题图的科技文献细粒度知识组织过程
基于智能主题图的科技文献细粒度知识组织过程包括以下四个步骤:主题抽取,该步骤对科技文献中的主题进行抽取,抽取结果作为后期构建聚类层的基础;知识单元抽取,该步骤对科技文献中的知识单元进行抽取,抽取结果为生成智能主题图作铺垫;主题聚类与关联,将相似度大于给定阈值的主题聚到一起;生成智能主题图,该步骤计算知识单元间以及主题与知识单元间的相似度,并结合步骤三的结果生成智能主题图。基于智能主题图的科技文献细粒度知识组织过程如图2所示。
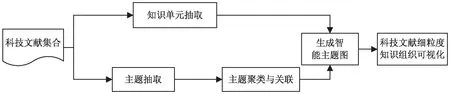
图2 基于智能主题图的科技文献细粒度知识组织过程
2.1主题抽取从科技文献中挖掘科学研究主题已成为对科技文献分析的研究热点和核心内容,大量的主题挖掘模型被提出,而潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)是主题模型中最核心的模型之一,它是使用最广泛、最具一般性的主题模型。另外,研究表明,用摘要作为语料,能广泛全面的抽取一篇科技文献的主题,是构建LDA文本语料库比较理想的选择[12]。因此本文采用LDA方法以科技文献的摘要作为语料库进行主题抽取。
由于我们抽取的主题对应的是所提出模型中的第一层主题,第一层主题希望得到更多的主题信息,因此应该选择较多的词语。根据LDA算法思想,本研究主题抽取的具体步骤如下:
步骤1:将所有文献的pdf格式转换为txt格式,将每篇文献中的摘要抽取出来保存到新的txt文档中,文档命名为“摘要-”+标题。
步骤2:对N篇文档集合中的每篇文档d做分词,并过滤掉无意义词,得到语料集合W={w1,w2,w3,……,wN}。
步骤3:为语料集合W中的每个词wi随机赋予一个主题编号t,作为初始主题。
步骤4:通过吉布斯采样公式,重新采样每个wi的所属主题t,并在语料中更新,直到吉布斯采样收敛。
步骤5:统计语料库中的主题-词共现频率矩阵,该矩阵就是LDA的模型,最后生成文档-主题概率分布。
经过以上的步骤,就得到一个训练好的LDA模型,接下来就可以根据模型对新文档的主题进行预估,具体操作如下:
对当前文档做分词,并过滤掉无意义词,对剩下的每个词随机赋予一个主题编号t;
通过吉布斯采样公式,重新采样每个词的所属主题t,并在语料中更新,
重复以上步骤直到吉布斯采样收敛;
统计文档中的主题分布即为预估结果。
2.2知识单元抽取本文将根据科技文献的文本结构对其内部的知识单元进行抽取,文本结构是由物理结构和逻辑结构两部分组成[13]。文献的物理结构表示了文献的组成,包含标题、章、节、段等。文献的逻辑结构着重表示文本的思想内容,包含主题、层次、段落、主题词等。首先通过对文献的章、节、段等物理结构的分析,采用向量空间模型表示文本的各个部分;接着对其进行文本的逻辑结构分析,重点是划分文本层次,文本的层次划分是根据同一层次的若干连续自然段共同支持该层次表达的主要思想,因此,可采用有序聚类的方式划分文本层次[10,14],并找出该层次的主题。
本文主要抽取概念类知识单元和方法类知识单元。文献[14]中描述了概念类知识单元通常含有以下规则:“是(指)/指(的是)/定义为/被定义为/…”,设这些规则集合为ru1;方法类知识单元通常具有以下规则:“是一种…方法/定义…方法/基于…方法,提出…/展示…方法/采用…(方法)/提出…方法/…”,设这些规则集合为ru2。
设科技文献SL具有n个自然段p,k个知识单元ku,知识单元是由若干个自然段构成的,则有组成关系
SL={ku1,ku2,ku3,…,kuk}={pi1,…,pi2-1}{pi2,…,pi3-1}…{pik,…,pik+1-1}
其中,i1=1≤ik≤ik-1=n。
则知识单元抽取过程如下:
步骤1:将科技文献按段落进行划分并进行相应的编号,SL={p1,p2,p3,…,pn};
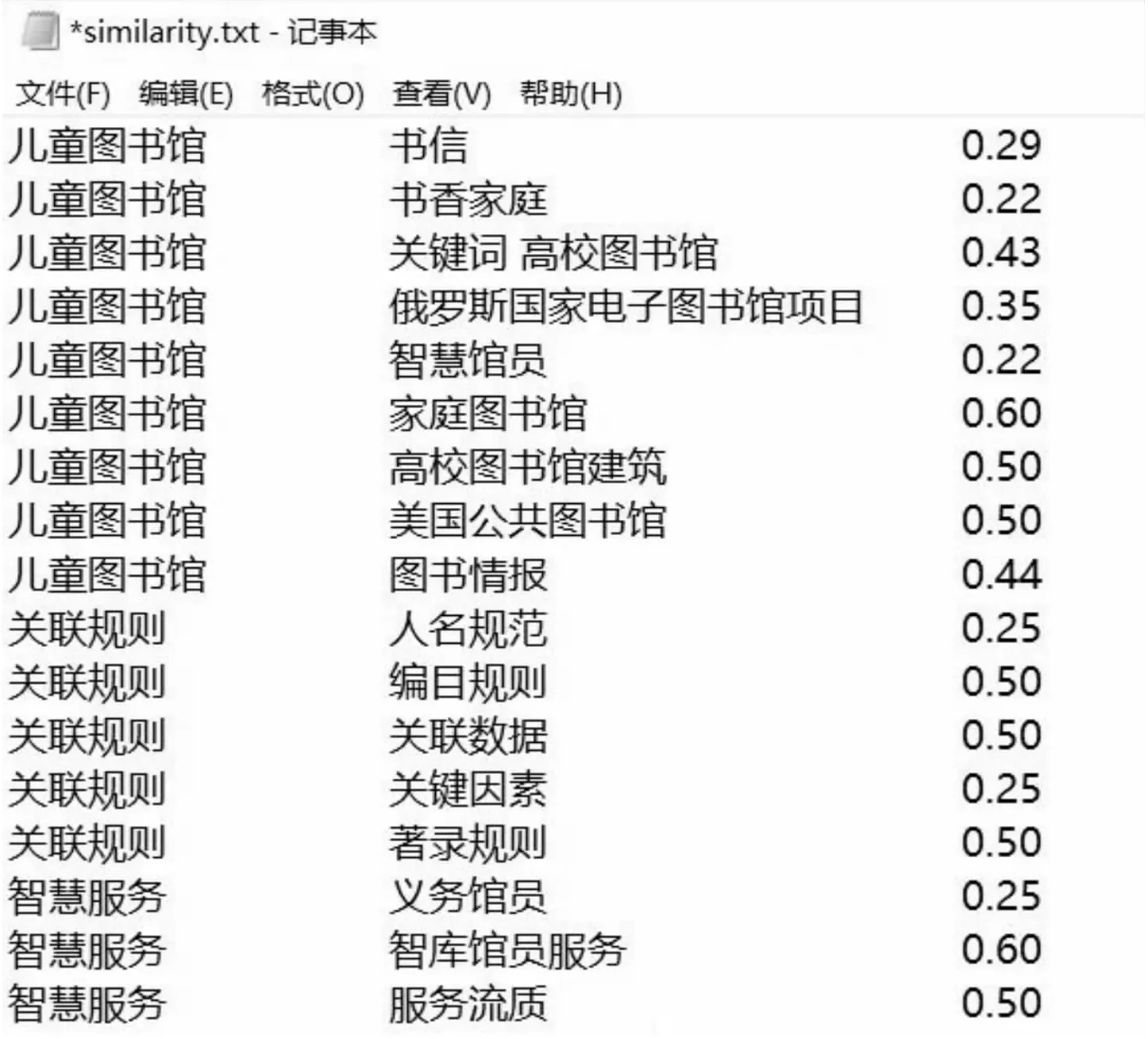
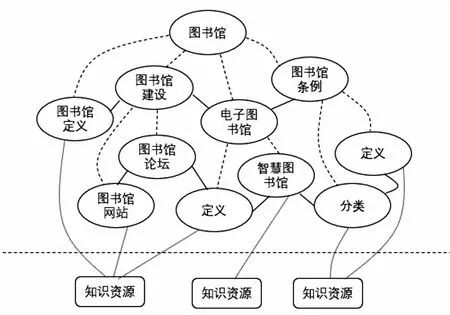
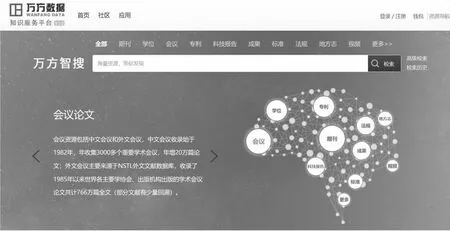
步骤2:对段落pi(1 步骤3:设段落pi的特征项集为{t1,t2,t3,…,tm},pi={wi1,wi2,wi3,…,wim}为第i个段落的特征向量,其中wij为特征项tj在第i段中的权重,则科技文献的特征矩阵为: 步骤4:计算k个知识单元内部差异量: 步骤5:计算知识单元总体误差:Sij(Cij用来存储每次的分割点) Sij=Dij,j=1,2,…,n Cij=ik,i=2,3,…,k,j=i+1,…,n 步骤6:得出最佳k分法: {i1=pi1,…,pi2-1},{pi2,…,pi3-1},…,{pik,…,pn} 步骤7:判断知识单元中是否包含ru1或ru2中的规则,进一步判断知识单元类型。 2.3主题聚类与关联基于智能主题图中聚类层层次化的特点,本文选用层次聚类的方法对主题进行聚类。层次聚类中采用的全信息匹配算法实现了语法、语义和语用匹配,该方法在查全率、查准率等方面均优于单纯采用语义或语用的相似性算法[15]。全信息匹配算法的具体过程将在3.4小节中介绍。主题聚类过程如下所示: 第一轮聚类:假设每个主题为一类,采用全信息相似性算法计算任意两个主题间的相似性,并选择相似性最大的两个主题聚为一类,这样类别数就少了一个,重新计算新类和旧类(去掉已经合并的两个类)之间的相似度,重复此聚类过程,直到类之间的相似性比设定的阈值小。设L表示主题层,则L1Fi(1≤i≤m)表示第一个主题层的第i个主题,m表示第一个主题层的主题个数。L2Sf(1≤f 第二轮聚类:第二轮聚类与第一轮聚类相似。L3Ts(1≤s 重复此聚类过程,直到得到满足条件的聚类主题,则停止聚类,整个聚类过程结束,主题间的关联在聚类过程中由全信息相似性算法得出。 2.4生成智能主题图本小节计算知识单元间、主题间以及主题与知识单元间的相似度,这是生成智能主题图的关键。 2.4.1 知识单元间以及主题间的相似度计算 知识单元间以及主题间的相似度计算采用Lu等[15]提出的基于综合信息论的相似性度量方法,该方法不仅考虑了语法层次上的相似度计算,也考虑了语义和语用层面的匹配,它的相似性计算过程包含句法匹配、语义匹配和语用匹配三方面。具体过程如下: 句法匹配:通过分析主题或知识单元的组成特征来计算句法相似度。 当链接一对主题(或知识单元)时,语法相似度SIMsyntatic(w1,w2)定义如下: c表示两个单词中包含的最大公共子字符串的字符数,|w1|和|w2|表示一对主题(或知识单元)的字符数。 语义匹配:语义匹配分析关于同义词的语义相似性。给出一对主题(或知识单元),假设主题(或知识单元)为词集合,ES为词与词相似度值集合= {sv1,sv2,…,svm*n}。将ES分为四个区间:A: [0.0, 0.1),B: [0.1, 0.2),C: [0.2, 0.8),D:[0.8, 1.0)。我们分析了这四种相似度值区间对词语相似度、认知歧义度的贡献。语义相似度定义如下: SIMsemantic(w1,w2)= 词义相似度定义如下: SIMsense=β1SIMMP+β2SIMOP+β3SIMRP+β4SIMSP β1+β2+β3+β4=1 其中,β1、β2、β3、β4表示权重,SIMMP是主要义原相似度,SIMOP为基本义原相似度,SIMRP为关系义原相似度,SIMRP为符号义原相似度。义原相似度计算方法参考文献[16]。 语用匹配:语用匹配计算动态语义相似度,解决了一词多义问题。它考虑了语言语境中的语用关联。当链接一对主题时,语用相似度用(Ta, Tb)定义如下: SIMpramatic(Ta,Tb)=wSIMpt(CTa,CTb)+(1-w)SIMpk(CKa,CKb) 式中,SIMpt(CTa,CTb)为集合CTa与CTb之间的相似性,CTa是与主题Ta直接相关的所有主题的集合,CTb是与主题Tb直接相关的所有主题的集合,φ1表示CTa中的主题,φ2表示CTb中的主题。SIMpt(CTa,CTb)的定义如下: 其中,SIMpk(CKa,CKb)为集合CKa与CKb之间的相似性,CKa是与主题Ta直接相关的所有知识单元的集合,CKb是与主题Tb直接相关的所有知识单元的集合,SIMpk(CKa,CKb)的计算方法与公式5相同。 2.4.2 提取主题与知识单元间的相似度并生成智能主题图 对于每个知识单元、主题以及聚类层生成的主题通过下述步骤建立主题与知识单元之间的关联,由此可生成智能主题图。设主题节点集T={ti|1≤i≤m},知识单元节点集KU={kuj|1≤i≤n},知识单元所属主题集A={ai|1≤i≤m},m表示主题节点数最大值,n表示知识单元节点数最大值。具体过程如下: 第一步,建立主题ti与知识单元kuj关联,计算其相关度,如果相关度高于最低阈值,则ti∈A,A是知识单元所属的主题集合,即一个知识单元可能与很多主题相关联; 第三步,重复第二步,直到Ai+1中每个主题都处理完成。 本文构建科技文献细粒度知识组织模型的目的是满足用户对科技文献内部知识单元资源快速定位、精准检索的需求。为了评价提出的科技文献细粒度知识组织模型的特征,本文采用Python语言基于提出的科技文献细粒度知识组织模型对实验数据集进行细粒度知识组织;使用基于Python语言编写的Networkx包完成基于智能主题图的科技文献细粒度知识组织的可视化。并在构建的科技文献细粒度知识组织原型系统上进行知识搜寻,将搜寻结果与从万方数据库中的相应情况进行对比,分析本文给出的基于智能主题图的科技文献细粒度知识组织模型在定位知识点、呈现知识单元方面的特征和优处。 3.1数据集本文选取《中国图书馆学报》中以“图书馆”为主题的科技文献作为本文的实验数据集,在CNKI数据库专业检索搜索框中以“SU =图书馆 AND JN=中国图书馆学报”为检索式,随机下载其中的1 000篇文献作为实验数据集。 3.2采用提出的模型对实验数据集进行细粒度知识组织 a.主题抽取与聚类。通过对科技文献中摘要部分识别,利用LDA算法识别每篇文献摘要中的主题,该程序共抽取出1 531个主题。根据2.3节中的层次聚类算法对抽取出的主题进行聚类,从而构建出主题层和聚类层。 b.知识元抽取与表示。通过识别文献中的段落以及它们之间的关系,将每篇文献分为多个知识单元,同时根据算法抽取出知识单元的主题以及关键词,按照编号、主题、关键词、标题、知识单元内容六元组的形式对知识单元进行存储,本实验从1 000篇文献共抽取出4413个知识单元。 c.相似度计算。主题之间、知识单元之间以及主题与知识单元间的相似度计算采用基于综合信息论的相似性度量方法[15]。主题之间的链接选择相似度θ≥0.2的主题,低相关度的主题之间不进行链接,同时将相似度值保留两位小数。 经过以上操作,完成了主题抽取、主题聚类以及主题之间的相似度计算,主题与主题之间的相似性度计算结果以TXT文档输出(相似度值保留两位小数),部分主题相似度计算结果如图3所示。 图3 主题与主题相似度计算的部分结果 输出文件中一共包含三列,左边两列为主题,最后一列为相似度值,图3中第一行内容“儿童图书馆 书信 0.29”,其含义为主题“儿童图书馆”与主题“书信”的相似度值为0.29;第六行内容“儿童图书馆 家庭图书馆 0.60”,其含义为主题“儿童图书馆”与主题“家庭图书馆”的相似度值为0.60。 3.3可视化结果展示本实验采用基于Python语言里的工具包Networkx对科技文献细粒度知识组织结果进行可视化呈现。以主题、知识单元以及它们之间的关联作为输入来构建科技文献细粒度知识组织模型,同层主题之间采用短实线连接,非同层主题之间采用虚线连接,主题与知识资源之间采用长实线连接,知识资源表示知识单元集合,部分构建结果如图4所示。 3.4与传统知识搜寻方式和现有相似研究的对比分析 3.4.1 与传统知识搜寻方式的对比分析 科研人员在进行科技文献搜寻时,通常有两种方式:浏览与检索[17]。浏览是指从页面上获取可见的信息,检索是指从用户特定的需求出发,采用一定的方法对特定信息集合,按照一定的规则并找出相关的信息[18]。 图4 科技文献细粒度知识组织模型部分可视化结果展示 a.采用浏览方式的对比分析。基于科技文献细粒度知识实验原型部分展示如图4,万方数据知识服务平台的首页如图5。从用户浏览方式的角度来看,从万方数据知识服务检索系统界面最上面,用户可以选择不同的文献类型,比如期刊、学位、专利等,并不能直接浏览具体的内容,在界面的右下边则对应页面最上面的文献类别,页面的左下边则是对应具体文献类别的介绍,并没有直接向用户提供具体的文献内容;而采用本研究提出的科技文献细粒度知识实验原型能实现文献内主题导航, 可以准确定位到某一主题所在的资源位置,同时表示了主题之间的关联,直接向用户展示可选择的文献主题。 图5 万方知识服务平台 b.采用检索方式的对比分析。本实验采用关键字匹配的检索方式,分别在科技文献细粒度知识实验原型以及万方数据知识服务平台上进行检索。根据实验数据集采集的情况,本文选择“智慧图书馆”为关键词进行检索。基于科技文献细粒度知识实验原型与万方数据知识服务平台的检索结果如图6、图7所示。 图6 基于科技文献细粒度知识组织模型检索结果 图7 基于万方数据知识服务平台检索结果 从用户检索方式的角度来看,使用万方数据知识服务检索系统得到的检索结果是文献名称列表,具体每一个条目中包含文献名称、摘要等,想获得更多信息必须点击下一页按钮获得更多相关内容。从检索系统呈现出的内容中,我们不能直接获得有效可用的具体知识点,只能获取和检索词相关文献的外部特征。如果想获取与检索词相关的信息,我们必须点击下载或者在线阅读按钮获取文献整篇内容,仔细阅读文献内容,再做进一步的判断。我们不能直接从检索系统呈现的检索结果中获得有效的信息,如果想获得具体的某个知识点,我们需要点击在线阅读或者下载文献作进一步的判断。而采用本研究提出的科技文献细粒度知识组织方法得到的检索结果是与关键词相关的知识单元,用户无需阅读具体的文献就能获取与关键词相关的具体内容,如图6中左侧所示的概念类知识单元、方法类知识单元等,如果想获取与关键词相关的方法类知识单元,则点击左侧的方法类按钮就可获得。在图6的右侧则是与用户输入信息相似的主题和用户最近浏览的信息,如果想作进一步的了解,就可点击相关按钮获取,在图6的最下边,则是相关知识单元的文献标题,可供用户作进一步的查看分析。 3.4.2 与现有相似研究的对比分析 与本文研究最相似的是李祯静等在文献[7]中提出的细粒度组织方法—资源语义空间,这篇文章与本文的核心差异有三点:文献[7]只是对索引简单模型化,没有实现对知识单元导航,而本文构建的基于智能主题图的科技文献细粒度知识组织方法构建了知识单元间主题之间的关联,并对其做了进一步的聚类,使相关主题也能实现对知识单元的定位,实现基于主题对知识单元进行导航;文献[7]根据句子间的相似度对知识单元中的主题词进行句法匹配和语义匹配,没有进一步研究这些主题词之间的语用关联,而本文综合计算了主题之间的句法匹配、语义匹配以及语用关联;在对知识单元处理的过程中,基于词频的方式确定了知识单元的主题词,这种采用词频确定知识单元主题词的方法依赖语料库,对语料库的质量要求较高,而本文采用LDA的方法抽取主题能弥补这个缺陷。 为了实现对科技文献内部内容的知识导航,向用户提供精准化的检索内容,本文提出了一种基于智能主题图的科技文献细粒度知识组织方法。该方法抽取了科技文献内部的主题、知识单元,并建立主题之间的关联、知识单元之间的关联、主题与知识单元之间的关联,能较好地表达知识间的相互关系,实现对资源的准确定位,将用户引导到相关的资源,节省用户检索时间,提高用户学习效率。然而,受限于知识抽取技术的支持,采用智能化的知识单元抽取后还需人工对知识单元抽取结果进行核对、筛选。因此,后期将加强专业化对科技文献内部知识单元抽取,实现全自动化的信息处理。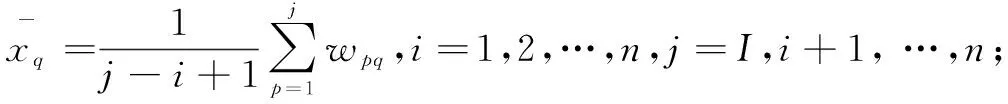
3 实验与评价


4 结论与展望
