二十世纪语序类型学的研究方法
2021-11-22鲁方昕
鲁 方 昕
一、引言
Greenberg(1)J.Greenberg,Some universals of grammar with particular reference to the order of meaningful elements.in J.Greenberg,(ed.) Universals of Language.Cambridge,MA:MIT Press,1963,p.73-113.在1963年发表了Some Universals of Grammar -with Particular Reference to the Order of Meaningful Elements,该篇一般被认定为现代类型学的奠基之作。现在看来,文章对现代类型学的发展至少有三项重要贡献:
其一是将类型学的研究目的从分类研究推广到蕴涵共性的探索上,讨论语言中不同范畴之间的关系,极大拓展了类型研究的价值。虽然Greenberg之前已有研究者(2)前期研究者中最重要的当属Jakobson,他关于儿童习得塞音、擦音,以及失语症患者丢失塞音、擦音的研究极大地影响了Greenberg。Greenberg明确地指出,Jakobson的研究使其了解了蕴涵共性的重要性。Jakobsond的研究可以见R.Jakobson,Kindersprache,Aphasie und allgemeine Lautgesetze.Uppsala:Uppsala Universitet Arsskrift,1941.对蕴涵共性的理论进行了探讨,但Greenberg最早将蕴涵共性提升到研究的中心位置并且将理论运用于实践,做出了大量可观察的工作(45条语言共性)。
其二是将研究对象从形态分类转向以语序为中心,这点在论文的标题中就有专门的体现。早期的形态分类预测能力较弱,即便我们知道一种语言是黏着语,但可能也无法推断出这种语言的其他特征。理论上,我们可以使用无数参项对语言分类,但这样分类并无太大意义。此外,形态分类还有一个重要缺陷,即各参项之间的关系错综复杂,无法用单一的标准来定义,比如,什么是黏着。相比而言,语序研究并没有上述这些问题。
其三,在语序共性的基础上,Greenberg进一步提出了“优势”与“和谐”的概念,以此来解释语言内的语序分布及各类语序之间的关系。“和谐”指语言中相似的结构相对应的成分倾向于处于相同的位置。而“优势”是基于“和谐”定义的,即优势的语序总是存在,而与之相反的劣势语序通常只能出现在与之和谐的结构中。这两个概念是语序类型学研究中的核心概念,后来产生的各种理论模型及解释大多都基于这两者而建。
在过去的半个多世纪中,语序类型学是类型学研究的中心,也是语言学领域的热点话题。这种情况下,Greenberg的工作思路、方法、结论在不少著作中都被提及与讨论,这里不再专门分析。相对而言,Greenberg之后的研究者对于语序类型的探索,则很少被系统地讨论。本文写作的目的在于梳理Venemann、Hawkins、Tomlin、Dryer等人的研究,理清这些研究之间的来龙去脉。
二、Venemann与VX/XV语序类型
(一)操作域与操作符
Greenberg最初根据S、V、O的语序将语言分成三种类型,分别是VSO、SVO、SOV。在这三者中,VSO与SOV都可以很好地预测语言中的其他语序,而SVO则很难。比如,VSO语序可以预测语言使用前置词(共性3),而SOV语序可以预测语言使用后置词(共性4)。相比而言,SVO语序不能预测语言使用前置词或是后置词。如果扩大到全部与语序相关的共性,也仅有共性6与SVO语序有关。共性6讨论的是SVO作为VSO的替代语序,也并不是关于不同语序参项之间相关性的共性。
从动词位置来看,VSO与SOV是两类极端的语言,因为二者的动词分别处于首端与末端,而SVO则将动词置于中间,融合了SOV与VSO两种类型的特点,使其在其他语序的分布上也包含了另外两种基本语序的特点。因此,如何处理SVO语言的类型是Greenberg留下的一道难题。Lehmann(3)W.Lehmann,A Structural Principle of Language and Its Implications,Language,no.49,1973.认为,主语与动词的关系是不重要的,甚至句中不一定会出现主语,如意大利语这样的语言,一般情况下会省去主语,而且SVO语言在不同的语法参项上都更接近于VSO类型,虽然这只是概率上的,但这种倾向比较明显。Lehmann进一步提出,S的位置一般情况下并不影响语言的类型特征,而只有V与O的相对位置决定了语言的性质,按照这种思路,人类的语言可以分成两类,OV型与VO型,根据和谐的规律,这两者基本类型的确定意味着语言中的其他特征多数都可以被预测。
受到Lehmann研究的启发,Venemann进一步扩展了VO与OV的类型学。Venemann(4)T.Venemann,Topics,Subjects,and Word Order:From SXV to SVX via TVX,in J.Anderson and C.Jones (eds.),Historical Linguistics.Amsterdam:North-Holland,1974,p.344,347.指出,Greenberg的共性统计主要基于VSO、SVO、SOV语序的三分,而Lehmann在建立相关性时只涉及了动词的相对位置,因此,“因为Lehmann的研究,现在有一种更好的方法来展示Greenberg的共性”。不过,Venemann并未使用VO与OV的术语,转而使用VX与XV,这里的X指广义上动词后的补语。为了增强VX类型与XV类型两分的解释力以及适用范围,Venemann提出了操作域(operand)与操作符(operator)的概念。Venemann(5)T.Venemann,Topics,Subjects,and Word Order:From SXV to SVX via TVX,in J.Anderson and C.Jones (eds.),Historical Linguistics.Amsterdam:North-Holland,1974,p.344,347.提出了两条确定操作域与操作符的原则:在语义层面,操作符修饰操作域;在句法层面,结构的句法功能与操作域的句法功能相同(6)此处结构的定义类似于Bloomfield提出的向心结构与离心结构。不过,Bloomfield的区分侧重说明整体与部分的关系,而这里的区分主要为了说明结构内两个成分之间的关系。。这里可以以动词与宾语的关系举例,整个组合的结构是动词短语,与动词相同,与宾语(名词短语)不同,因此,动词是操作域,名词是操作符。Venemann(7)T.Venemann,Theoretical Word Order Studies:Results and Problems,Papiere zur Linguistik,no.7,1974.提出了多种操作域与操作符关系,包括宾语(操作符)-动词(操作域)、状语(操作符)-动词(操作域)、主动词(操作符)-助动词(操作域)、主动词(操作符)-内涵动词(8)所谓内涵动词(intensional verb),主要可以分为两类:一类是引语动词,如“认为”“觉得”“看到”;一类是意向动词,如“支持”“道歉”“探寻”。(操作域)、形容词(操作符)-名词(操作域)、关系小句(操作符)-名词(操作域)、数量标记(操作符)-名词(操作域)、领属者(操作符)-被领属者(操作域)、数词(操作符)-名词(操作域)、限定词(操作符)-名词(操作域)、形容词(操作符)-比较标记(操作域)、比较基准(操作符)-形容词(操作域)、副词(操作符)-形容词(操作域)、名词短语(操作符)-附置词(操作域)、间接宾语(操作符)-直接宾语(操作域)等。自然语言中通常使用相同的顺序排列上述不同组的操作域与操作符,即在VO语言中,这些结构都使用操作域-操作符语序,而在OV语言中,这些结构使用操作符-操作域语序。Venemann将这类共性命名为“自然序列化原则(Natural Serialization Principle)”。
(二)Venemann的语序演变研究
Venemann另一项重要的工作,是对语序演变的研究,而且他的研究将语序的演变与语言的共时类型结合起来。Venemann(9)T.Venemann,Explanation in Syntax,in J.P.Kimball (ed.),Syntax and Semantics.New York:Seminar Press,1973,p.1-50.认为,语序演变的基本路径是:1)SOV语序演变为SVO;2)SVO语序可能演变成VSO语序或者自由语序;3)VSO语序优势会恢复成SVO语序或者自由语序;4)自由语序的语言可能演变为SOV语序。
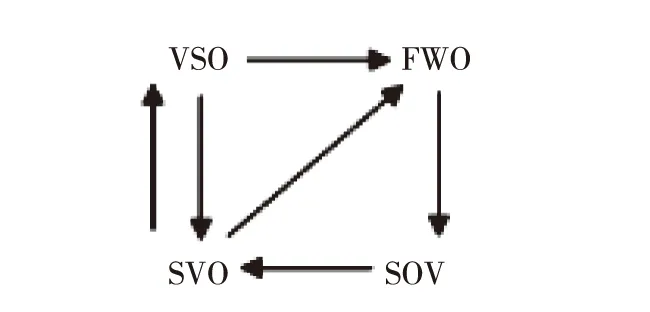
图1 Venemann语序演变路径
对于语言中的其他语序(如附置词与名词的顺序、领属者与被领属者的顺序),这些语序的演变通常受到自然序列化原则的控制,随着主语序的变化而发生变化。当然,Venemann的语序演变研究也存在一些问题。其一,Venemann对于自由语序的定义太过宽泛,一般而言,自由语序语言指无法确定基本语序的语言,但在Venemann的术语体系中,语序可以自由移动(一般拥有格系统)的语言都叫作自由语序语言,比如俄语(10)尽管俄语或拉丁语的S、V、O可以变换六种语序,但通常俄语被视作SVO语言,拉丁语被视作SOV语言,两者都不会被视作自由语序的语言。,如此,自由语序语言的数量便会急剧升高。其次,Venemann似乎也没有提供具体的实例来说明SVO语序向SOV语序的演变,从目前的已发现的材料看,这种演变在语言中较为罕见(11)这里可以提供一个实例,Takia语的语序从SVO语序演变成了SOV语序。不过,Takia语的语序的演变是由于受到Waskia语的影响,接触后产生的。。在同一时期,Givón(12)T.Givón,Serial verbs and syntactic change:Niger-Congo’.in C.Li (ed.).Word Order and Word Order Change,Austin:University of Texas Press,1975,p.47-112.提出了另一条语序演变的基本路径,即人类的原始语言使用SOV语序,然后经历SOV>VSO>SVO演变的路径。不过,据Gell-Mann和Ruhlen(13)M.Gell-Mann & M,Ruhlen,The origin and evolution of word order.Proceedings of the National Academy of Sciences,no.108,2011.的数据,这条演变路径虽然比Venemann的更为合理,但也不太符合语言演变的现实,多数的语言都是直接从SOV演变成了SVO,而没有经过VSO这个中间阶段。
在Greenberg的系统中,SVO三者的顺序、附置词的位置以及形容词与名词的语序是主要的研究对象,而Venemann关于操作域-操作符的研究极大扩展了语序类型学研究的范围,将研究对象扩展到接近20种,这些参项之间的关系依然是当下类型学研究的课题,这无疑是Venemann一个重要的贡献。就Venemann提出的自然序列化的研究而言,它不仅强化了Lehmann关于VO与OV在语序类型研究中特殊地位的观点,拓宽了和谐理论的研究视野,同时也使得理论变得更加明晰。因为自然序列化原则几乎将语序的规则归为一种,虽然符合简约精神(奥卡姆剃刀准则),但这意味着该原则存在大量的反例。同时,过于强调和谐的概念,或者几乎将和谐作为语序共性的唯一基础,这种观点本质上不太可取。语序的使用除了受到和谐的限制,也受到其他因素的影响,比如“优势”或者一些其他的因素。此外,Venemann的研究还受到了其他一些批评,如Mallinson和Blake(14)G.Mallinson,& B.Blake,Language Typology:Cross-linguistic Studies in Syntax.Amsterdam:North-Holland,1981,p.384-385.认为,部分操作域与操作符的确定过于主观。
三、Hawkins关于语序的心理语言学研究
(一)附置词类型、重度序列化原则与移动性原则
在前面的研究中,Greenberg的样本数量只有30,而Venemann的研究则更多是理论构想,并没有得到更大规模语言样本的支持。Hawkins(15)J.Hawkins,Word Order Universals.New York:Academic Press,1983.的首要工作是使用更为大量的数据样本(336种语言(16)Hawkins还另外使用了Greenberg的样本语言。)来验证前人理论的可靠性。在Hawkins看来,SVO语序虽然更偏向VSO类型,但以此便把它归入VO类型中并不妥当,因为SVO语序类型下,很多特征依旧比较混乱(17)Comrie也持这一观点,认为SVO类型混乱,无法预测出更多参项。B.Comrie,B.Language Universals and Linguistic Typology:Syntax and Morphology.2nd edn.Oxford:Blackwell,1989,p.96.。同时,他也不否认语序类型的合理性,他提出了使用附置词(前置词与后置词)的相对位置来作为预测语序类型的基本参项。
20世纪70年代,语序研究的重点几乎都是和谐,对于Greenberg另一项重要“优势”却鲜有人问津。Greenberg对于优势的定义,是依赖于和谐而立的,即“优势的语序总是可以出现,而与之相反的劣势语序只有出现在与它和谐的结构中”,同时,他也没有对“优势”进行更多的解读。Hawkins针对附置词类型中的一些反例,提出了“重度序列化原则” (Heaviness Principle)与“移动性原则”(Mobility Principle),而这两者,尤其是前者,是“优势”语序形成的重要因素。所谓“重度序列化原则”,指如果语言中“重度”(Heaviness)更高的成分是前置的,那么“重度”更低的成分也是前置的。Hawkins(18)J.Hawkins,Word Order Universals.New York:Academic Press,1983,p.90.为“重度”设定了四条标准:1)语素的数量与长度;2)词的数量;3)句法分支节点的数量;4)是否相互统辖(19)比如,关系小句或者领属可以管辖形容词或指别词,而形容词或指别词不能管辖关系小句或者领属。因此,关系小句或是领属在重度上更高。。按照这种标准,Hawkins列出了重度等级(Heaviness Hierarchy):
关系小句≥领属≥形容词≥数词/指别词
上述等级可以解读为:在重度上,关系小句不小于领属,领属不小于形容词,形容词不小于数词/指别词。如果无标记的语序中,重度最重的关系小句前置于中心名词,则通常其后的领属成分、形容词、数词、指别词等都前置于名词。在这里,Hawkins讨论的是人类语言中的一种普遍共性,即将更重的成分置于更后,这是“优势”的重要表现之一。“重度”也可以用于解释其他现象,比如Greenberg共性25,因为代词的重度低于名词短语,因此,如果更重的名词宾语前置于动词,那么更轻的代词宾语也会前置于动词,且如果更轻的代词宾语后置于动词,则更重的名词宾语也后置于动词。
只有“重度序列化原则”,依然不能解释语言中较为常见的前置词与AdjN(如大多数的印欧语)的共现,Hawkins(20)J.Hawkins,Word Order Universals.New York:Academic Press,1983,p.93-95.进一步提出了“移动性原则”,指相比于移动性更弱的成分(包括关系小句、领属),语言中移动性更强的成分(包括形容词、数词、指别词)更容易离开自己的位置,形成违反附置词类型的语序。Hawkins随后用两种原则的竞争来说明人类语言中语序的可能情况:1)就指别词与关系小句而言,两者重度相差为3,重度原则几乎总是压过移动性原则,如后置词语言(21)前置词与后置词的情况类似,这里讨论后置词只是为了举例。中出现NDem语序以及RelN语序是几乎不可能的,而后置词语言中出现DemN语序以及NRel语序是较为常见的;2)数词与关系小句的情况与上述指别词(情形1)类似;3)形容词与关系小句的重度差为2,重度原则有时超过移动性原则,因此,后置词语言中NA语序搭配RelN语序与AN语序搭配NRel语序都有一定数量的语言实例;4)指别词与领属的重度差为2;重度原则不能压过移动性,这体现在后置词语言中NDem语序搭配GN语序经常出现,而与之相反的DemN语序搭配NG语序总是不出现;5)数词与关系小句的情况与上述指别词(情形4)类似;6)形容词与领属的重度差为1,重度原则不能压过移动性原则,即后置词语言中NA语序搭配GN语序经常出现,而与之相反的AN语序搭配NG语序总是不出现。准确来说,“移动性原则”并不是解释,而更像是描写,即说明了哪些参项可能不符合语序类型。其实,Dryer(22)M.Dryer,Object-Verb Order and Adjective-Noun Order:Dispelling a Myth,Lingua,no.74,1988.的研究似乎也说明了相同的问题,即一些与名词相关的语序参项不太符合语序类型的整体框架(VO-OV或者前置词-后置词),应该从中拿掉,这点会在下文有专门讨论。
如前文所述,Venemann的自然序列化原则非常精简,但精简通常会带来反例。事实上,据Hawkins 1983:183-184),只有23%的语言(在Greenberg30样本中)以及48%的语言(在Greenberg扩展样本中)符合自然序列化原则。从这个角度看,Venemann的模型过于理想化且不符合语言实际。Hawkins放弃了这种“纯和谐主义”的观点,但他并不否认和谐对于语序共性的作用,他提出了一种新的解释原则,即“跨范畴和谐原则(Principle of Cross Category Harmony)”。所谓“跨范畴和谐原则”,指语言中不同范畴的成分(操作符)与其操作域相对位置相似的程度越高,则这种类型的语言在世界范围内数量越多。这里以SOV/Po语言为例,SOV/Po/AN/GN的组合是语言中最多的,因为这些不同范畴的语序关系是全部和谐的,而相比之下,SOV/Po/NA/GN的组合数量会更少,因为NA语序与其他三种类型不和谐。数量最少的类型是SOV/Po/NA/NG(23)在Hawkins的样本中,这三种类型的数量分别为59.3%(SOV/Po/AN/GN)、33.9%(SOV/Po/NA/ GN)、6.8%(SOV/Po/NA/NG)。,因为其中有两组不和谐。
Hawkins认识到语序的形成受多重因素共同的作用,和谐在人类语言中只是倾向性的,先前的共性多数都有例外。为此,他进一步提出无例外的共性。所谓无例外共性(unexceptional universal),本质是在一些共性的基础上增加另外一些参项作为条件,这样可以使共性中没有例外,比如,如果一种是前置词语言,且这种语言指别词位于名词之后,那么形容词也位于名词之后(24)J.Hawkins,Word Order Universals.New York:Academic Press,1983,p.71.。
(二)直接成分尽早确定原则与语法的效能
如前文所述,重度序列化原则与移动性原则对于语序的解释经常矛盾,而Hawkins并没有从机制上十分明晰地解释二者的竞争。为了解决这一问题,Hawkins(25)J.Hawkins,A Parsing Theory of Word Order Universals,Linguistic Inquiry,no.21,1990.提出了直接成分尽早确定原则(Principle of Early Immediate Constituent),试图从大脑运算的角度更为全面合理地解释语序类型。首先,Hawkins(26)J.Hawkins,A Performance Theory of Order and Constituency.Cambridge:Cambridge University Press,1994,p.58-59,p.70.引入了“成分识别域”(Constituent Recognition Domain)的概念,指识别母节点M所需的全部终端节点与非终端节点的集合。成分识别域越大,句子解析起来越困难,而影响成分识别域大小的最重要因素便是语序。下面以Hawkins(27)J.Hawkins,A Performance Theory of Order and Constituency.Cambridge:Cambridge University Press,1994,p.58-59,p.70.所举的例子来说明,上面a)、b)两句在语义上相同,主语也相同,差别主要在动词短语部分。这里动词短语可以分为三个直接成分:主动词(looked)、宾语(the number of the ticket)、小品词(up)。由于“up”位置的不同,a)、b)两句的动词短语成分识别域差别较大。前者的成分识别域一直延续到句末“up”处,而后者的成分识别域则只持续到“the”。因为这里的冠词“the”是名词短语的母节点构造范畴(28)母节点构造范畴(mother node constructing category),指确定了母节点身份的范畴,部分类似于X-bar理论中核心X。通常,动词是动词短语的母节点构造范畴,而名词短语的母节点构造范畴可以是限定词(冠词)或者名词,具体的分析可参考Abney,S.Abney,The English Noun Phrase in Its Sentential Aspect,Ph.D.diss.,MIT,1987.,而这个名词短语是动词短语中的最后一个直接成分,从句法上说,识别了“the”句法解析就完成了。Hawkins提出了量化的方法来计算成分识别域的大小与效能,具体算法是使用直接成分节点的数量除以非直接成分节点的数量(IC-to-non-IC ratios)。a)句动词短语成分识别域共有17个节点(V、NP、Part、looked、Det、N、PP、up、the、number、Pr、NP、of、Det、N、the、ticket),直接成分的节点为3(V、Part、NP),比值为3/14(21.4%);而b)句动词短语成分识别域只有7个节点(V、NP、Part、looked、up、Det、the),直接成分的节点也为3,比值为3/4(75%)。

基于以上的分析,Hawkins提出了直接成分尽早确定原则,即听话人更倾向将成分识别域最优化(直接成分节点数量与非直接成分节点数量之比最小)的语序。简单地说,句中的直接成分不应相隔太远。以汉语为例,在“我刚才看到了张老师的邻居昨天下午在海淀公园丢的那只猫”中,直接成分之一的宾语一直没有确定,听话人在解析宾语时会出现多次歧义,增加解码负担。在Hawkins的框架下,VO语序与RelN语序搭配所产生的动词短语的成分识别域很大,不符合直接成分尽早确定原则。
在直接成分尽早确定原则的基础上,Hawkins进一步扩展了心理运算与句法倾向相关性的研究。首先,他(29)J.Hawkins,Efficiency and Complexity in Grammars.Oxford:Oxford University Press,2004,p.3.提出了表现与语法一致假说(Performance-Grammar Correspondence Hypothesis),即语言中的句法结构与语言使用中的倾向是一致的,而语言的使用倾向可以用效能(efficiency)来阐释。“效能”由三条标准来定义:1)辖域最小化(Minimize Domains);2)形式最小化(Minimize Forms);3)在线处理最大化(Maximize Online Processing)。 “辖域最小化”,指语言处理器倾向于挑选辖域最小的结构来表达,这条与直接成分尽早确定原则有类似的算法,即直接成分与词数之比越高的成分,在处理时越有效率。“形式最小化”,指语言处理器倾向于挑选形式复杂度低的形式来表达,比如,形式上更长的词可以用缩略形式来表示,数量关系可以通过数标记来表达,完整的名词短语可以使用代词来代替,完整的小句可以使用代用式来代替,等等。“在线处理最大化”指语言处理器倾向于将语法特征赋值给更多的形式。比如,在处理I realize the boy knows the answer时,当语言处理器加工到“the boy”时,由于realize是不及物动词,无法获得“the boy”的题元角色以及语法关系,因此会出现延迟赋值的情况,直到处理至“knows”;而相比而言,“I realize that the boy knows the answer”不会出现上述的延迟赋值的情况,更符合“在线处理最大化”的准则。虽然效能与复杂度的计算与直接成分尽早确定原则在处理语序问题上有很多相似的地方,但效能与复杂度的研究提供了更为具体的计算大脑处理语言难度的方法,可以用来解决更多非语序的问题(30)这种方案可以参考J,Hawkins,Cross-Linguistic Variation and Efficiency.Oxford:Oxford University Press,2014.。
四、S、V、O语序的分布及其解释
(一)Tomlin的三原则
Tomlin(31)R.Tomlin,Basic Word Order:Functional Principles.London:Croom Helm,1986,p.22.将研究的焦点从不同语序之间的关系上移开,转而研究一种语序内部的分布。他统计了一千多种语言的基本语序,以其中的402种为样本,得出了表1。

表1 Tomlin样本语言的S、V、O语序的分布
从表中可以看出,语序分布的频率为SOV>SVO>VSO>VOS>OVS>OSV。通过卡方检验(0.05的显著水平),SOV的分布(44.78%)与SVO的分布(41.79%)没有显著差异,因此,SOV=SVO。而虽然VOS的分布(2.99%)与OVS(1.24%)有显著差异,但由于这两者样本都过小(12与5),因此,也将二者的差异视作没有显著差异。最终,Tomlin得出了修正的频率等级,即SOV=SVO>VSO>VOS=OVS>OSV。
随后,Tomlin从功能视角解释了这些语序的分布,而这部分内容是专著的核心。他提出了三条原则来分析基本语序的问题:1)主题领先原则(The Theme First Principle),即在跨语言的环境中,主题的内容通常领先于述题;2)动词-宾语连接(Verb-Object Bonding),即动词与宾语倾向相连;3)生命度领先原则(The Animated First Principle),即生命度高的成分一般领先于生命度低的成分。以此出发,SOV语序与SVO语序符合全部三条原则,因此数量显著领先于其他语序;VSO违反一项(动词与宾语连接),数量次之;VOS语序与OVS语序违反两项(主题领先原则、生命度领先原则),数量更少;而OSV违反全部三条原则,数量最少。
Tomlin的原则存在一个显著的问题,即主题领先原则与生命都领先原则相关性过强。主题与述题是语用层面的,而生命度等级属于句法层面,通常生命度高的句法成分更容易成为句子的主语,也更容易成为话语的主题。因此,认同一条原则几乎等同于认同另一条。Song(32)Song,J,On Tomlin,and Manning and Parker on basic word order.Language Sciences,no.13,1991.从赋值的角度探讨了Tomlin的分析,认为Tomlin对三条原则使用相同赋值的做法是不太科学的,因为生命度领先原则与主题领先原则都只关注S与O的相对位置,而不关注S与V的相对位置,因此,如果S同时领先于V以及O,应该在主题领先原则(33)生命度领先原则执行同样的操作。上赋值为2(即遵循了主题领先原则两次),而如果S领先于O而落后于V,应该在主题领先原则上赋值为1(即遵循了主题领先原则一次)。按照这种方法,SVO与SOV两种语序都被赋值为5,VSO被赋值为2,VOS与OVS被赋值为1,OSV被赋值为1。相比于Tomlin,Song的方案更加强化了S作为句首的重要性,即在世界上多数语言中主语领先于全句(34)无论何种统计,SOV语序与SVO语序相加的比例都在七成以上。,这应该反映了语序的一个重要特征。
(二)图形背景框架
除了Tomlin的功能视角分析,对于S、V、O语序分布的解读还有认知的视角,比如Manning和Parker。Manning和Parker并没有像Tomlin一样使用统计上的显著性来讨论语序的分布,他们使用了纯粹的语序的分布等级:SOV>SVO>VSO>VOS>OVS>OSV。Manning和Parker(35)A.Manning,& F.Parker.The sov >62; … >62; osv frequency hierarchy.Language Sciences,no.11,1989,p.52,p.55-56,p.55.指出,S、V、O的排列与语义形式的分布是一致的,而语义形式的分布是由视觉形式的识解。视觉形式的识解通常被分为两步:第一步是整体的识解,确定整体中的图形(entire figure);第二步是确定剩下的(两个)成分中的图形(relative figure)。在这两者之中,无疑整体图形的确定要比相对图形的确定更为重要。至于如何确定图形,Manning 和Parker(36)A.Manning,& F.Parker.The sov >62; … >62; osv frequency hierarchy.Language Sciences,no.11,1989,p.52,p.55-56,p.55.进一步提出:1)越小的成员被识解成图形,符合这一原则是“优选的”;2)越大的成员被识解为图形,符合这一原则是“可能的”。图2是Manning & Parker(37)A.Manning,& F.Parker.The sov >62; … >62; osv frequency hierarchy.Language Sciences,no.11,1989,p.52,p.55-56,p.55.提出的S、V、O三者的图形背景框架。

图2 图形背景框架下的S、V、O
对于整体图形来说,存在三种基本情况:1)最小的S作为图形,其先于O、V是优选的;2)最大的V作为图形,其先于O、S是可能的;3)中间的O作为图形,不符两条原则中的任意一条,是最差的。按照整体图形的分类,我们进一步讨论分类图形的选择:在S作为整体图形的情况下(SOV、SVO),O作为相对图形是优选的,V作为相对图形是可能的;在V作为整体图形的情况下(VSO、VOS),S作为相对图形是优选的,O作为相对图形是可能的;在O作为整体图形的情况下(OSV、OVS),S作为相对图形是优选的,V作为相对图形是可能的。因此,语序的分布是SOV>SVO>VSO>VOS>OVS>OSV。
五、Dryer的分支方向理论
(一)排除无关语序
与Hawkins类似,Dryer的第一项工作也是通过大量的样本(600种左右(38)不同时期著作使用的样本数量不太一致,一般在300至600之间。)来验证Greenberg的和谐以及Venemann的自然序列化原则。在Greenberg的系统中,形容词与名词的语序是语言类型研究的三种重要参项之一,在Venemann的系统中,形容词与名词是重要的一组操作符与操作域,而Dryer(39)M.Dryer,Object-Verb Order and Adjective-Noun Order:Dispelling a Myth,Lingua,no.74,1988;又见M.Dryer,The Greenbergian Word Order Correlations,Language,no.68,1992.指出,形容词与名词的语序与其他语序类型并不具备显著的相关性,比如,形容词-名词语序(AdjN)不能推出领属-被领属语序(GN)或者宾语-动词语序(OV),反之亦不能。表2是Dryer(40)M.Dryer,The Greenbergian Word Order Correlations,Language,no.68,1992.统计的动词-宾语参项与形容词-名词参项组合的数量。

表2 OV/VO语序与AN/NA语序(41) Afr指非洲地区,Eura指欧亚地区,SEAsia&Oc指东南亚及太平洋岛屿地区,A-NG指澳大利亚与新几内亚地区,NAm指北美地区,Sam指南美地区。
可以发现,OV语言使用与之不和谐的NA语序的语言数量还要大过VO语言,而虽然VO语言使用NA语序的数量要大过AN语序,但语言间数量的差别较小,因此形容词与名词的语序与动词-宾语的语序不存在通常所谓的和谐关系。使用这种方法,Dryer还将指别词-名词、副词-形容词、否定词-动词、时体标记-动词等剥离出相关性的系统。
Dryer在样本的选取上,也与前人的研究有着极大的不同。虽然先前研究的样本选取同时考虑了共时与历时的因素,但主要以系属(历史)的划分为基础。Dryer的选取则更加看重地理因素的作用,他(42)M.Dryer,Large Linguistic Areas and Language Sampling,Studies in Language,no.13,1989.将世界分为6块主要的语言区域:欧亚地区、非洲地区、南美地区、北美地区、东南亚与太平洋岛屿地区(43)“太平洋岛屿地区”的语言,主要指南岛语。、澳大利亚与新几内亚地区。这种划分具有更强的类型学眼光。一方面,语言接触对于语法特征变化的影响可能要高于自源的变化,同时,语言接触会极大加速语法演变,因此,一个语言接触频繁的地区两种语言语法特征的相似程度应该比同一系属中语言的语法特征相似程度更高;另一方面,从目前的调查来看, 太平洋岛屿上的语言(包括东南亚与太平洋岛屿地区、澳大利亚与新几内亚地区)所呈现的多样性要大于世界其他地区的语言,如果忽视这一地区的语言,类型调查的结果可能会不太精确。
(二)分支方向理论
Dryer(44)M,Dryer,SVO Languages and the OV:VO Typology,Journal of Linguistics,no.27,1991.重新讨论了OV与VO语序类型作为基本语序参项的可能性,他认为Hawkins过于夸大了SVO语序类型的混合性,在多数情况下,VO型语言的特征在SVO语言中也可以找到,因此,他重新将VO与OV作为预测语序的基本参项。在此基础上,Dryer(45)M.Dryer,The Greenbergian Word Order Correlations,Language,no.68,1992.提出了分支方向理论(Branching Direction Theory)。Dryer首先引入了两个新的概念:动词模件(verb patterner)与宾语模件(object patterner),前者指语序类型中与动词对应的成分,类似于先前研究中的核心或者操作域,后者指语序类型中与宾语对应的成分,类似于先前研究中的从属或者操作符。Dryer引入这两个概念的原因,主要在于核心与从属的关系是更为广泛的,其中有多组关系(如前文提到的形容词-名词)不应该被纳入语序和谐的讨论。具体来说,虽然同为名词的从属成分,关系小句与名词的语序容易预测,而形容词与名词的语言较难预测。同样的情况发生在程度副词与比较基准上,二者均为形容词的从属成分,但后者与形容词的语序较易预测,前者则更难预测。动词的两类从属成分附置词短语与否定小品词也有同样的问题。在Dryer看来,这两类成分的差别在于形容词、程度副词、否定小品词都是非短语范畴,而关系小句、比较基础、附置词短语都是短语范畴。显然,短语的从属成分与核心的语序是易于判定的,而非短语的从属成分与核心的语序是难判定的。按照这种思路,Dryer(46)M.Dryer,The Greenbergian Word Order Correlations,Language,no.68,1992.提出了分支方向理论(Branching Direction Theory),这一理论具体表述为:
“动词模件是不可分支的非短语范畴,而宾语模件是可分支的短语范畴。一组成分X与Y在VO语言中使用XY语序比在OV语言中比例更高,只有在X是非短语范畴而Y是短语范畴的情况下”。
分支方向理论本质上是和谐理论的一种发展,照此可以将世界语言分为两类。左分支的语言指短语成分置于核心左侧的语言,而右分支的语言指将短语成分置于核心右侧的语言。表3是Dryer(47)M.Dryer,The branching direction theory of word order correlations revisited.Universals of language today,Springer,Dordrecht,2009.提出的符合语言中动词模件与宾语模件关系的成分。Dryer的分支方向理论适应性虽然不及自然序列化原则,但也增加了先前研究没有关注的一些参项,如系动词-表语、动词-方式副词、标句词-分句。

表3 Dryer的分支方向模件
分支方向理论存在一个显著的问题,即如何看待短语结构,Dryer同样注意到这一问题。在短语结构的框架中,短语成分可以有两种分析。这里使用冠词-名词的组合来说明,在Dryer早期的系统中,冠词-名词处于分支方向理论的框架中,其中冠词是动词模件,而名词是宾语模件。这种分析基于结构的层级关系,以Dryer(48)M.Dryer,The branching direction theory of word order correlations revisited.Universals of language today. Springer,Dordrecht,2009,p.193.所举的“the man who told me that Smith left”为例,“the”是标志语,“man”是中心,“who told me that Smith left”是补语。其中“the”与“man(who told me that Smith left)”存在短语范畴与非短语范畴的区分,可以纳入语序相关性的理论。除了上述分析,还有一种分析方法,即将这一结构视作扁平结构(如b的分析),这种情况下“the”与“man”的关系似乎与形容词-名词的关系,没有短语范畴与非短语范畴的差别。因此,Dryer逐步放弃了分支方向理论,转而以前文提及的语法效能的理论来处理语序问题。

六、Dunn等(2011)对语序相关性的讨论
Dunn等(49)M.Dunn,S.Greenhill,S.Levinson & R.Gray.Evolved structure of language shows lineage-specific trends in word-order universals,Nature,no.473(7345).讨论了语序类型学中不同语序参项相关性(和谐)的合理性。Dunn等选取了四种系属关系相对清楚的语系(印欧语、南岛语、班图语、尤特阿兹特克语(50)南岛语系(1268种语言,约5200年时间深度)、印欧语系(449种语言,约8700年时间深度)、班图语系(668种语言,约4000年时间深度)、犹特阿兹特克语系(61种语言,约5000年时间深度)。括号中的语言数量以及时间深度是原文给出的。),在其中抽取79种印欧语、130种南岛语、66种班图语以及26种尤特阿兹特克语作为样本,将八种语序参项(数词-名词、领属-名词、主语-动词、形容词-名词、指别词-名词、关系小句-名词、宾语-动词、附置词-名词)作为主要研究对象,通过贝叶斯算法计算了这些变量之间的相关性,所得的结果如图2,图中的粗线表示这两组语序关系较为紧密,而没有线条表示这两组语序之间没有显著的相关性。

图3 Dunn等(51)M.Dunn,S.Greenhill,S.Levinson & R.Gray.Evolved structure of language shows lineage-specific trends in word-order universals,Nature,no.473(7345).的语序相关性
Dunn等发现,多数的语序在跨语言中都无法找到相关性,没有两种语序在四种不同的语系中都存在相关性。而只有两组语序的相关性在两种语系中都存在,即南岛语与印欧语中存在附置词-名词与动词-宾语之间的相关性,印欧语与尤特阿兹特克语与领属-名词与动词-宾语之间的相关性。同时,多数的语序相关性都只存在于一种语系的语言中,比如,尤特阿兹特克语中主语-动词以及宾语-动词有显著的相关性,印欧语中形容词-名词语领属-名词之间存在显著的相关性,南岛语中数词-名词与领属-名词存在显著的相关性。因此,Dunn等得出结论,就语序而言,人类语言的共性是不显著的,这些共性通常只存在于个别语系中,更进一步,语言的多样性似乎不受人类共同的认知的限制,而是文化演变的产物。
Dunn等的结论与语序类型的基本观点相悖,受到了不少批评,其中以Dryer的反驳最具代表性。Dryer(52)M.Dryer,The evidence for word order correlations.Linguistic Typology,no.15,2011.首先指出,语序间确实存在跨语言的相关关系,Dryer列出了五组强相关的语序参项,比如动词与宾语的语序与附置词的使用,在全部的六个语言区域中,OV语序都与后置词有强相关关系,VO语序都与前置词有强相关关系。其次,Dryer分析了从独立语系中找相关性与从跨语系的样本中找相关性的差异,即前者容易受到语系挑选的影响。最后,语言的类型差异不仅受到谱系关系的影响,更受到语言接触的影响,因此很难得出语序的相关性只存在于谱系内部的观点。
七、余论
Dryer(53)M.Dryer,On the order of demonstrative,numeral,adjective and noun,Language,no.94,2018.最近讨论了Greenberg的共性20,共性20涉及了指别词、数词、修饰性形容词与名词的语序。传统语序类型学的研究重点是两个成分的语序,对于多个成分产生的多种语序,一般用多种功能因素的竞争来解释,但到底哪种因素的作用更大则需要根据具体情境来分析。这种分析的最大问题在于只能解释,不能预测。然而,Dryer采用了新的优选论方案,他预先设定了5条原则并进行排序,以此来解释所有可能语序出现的频率。此前,Tomlin在解释基本语序的分布时也采取了类似思路,不过他使用的是赋值操作。赋值在语言学研究中难以掌握,加之其原则的区分度不大,因此Tomlin方案的解释力稍弱。Dryer的研究或许可以启发我们对多成分语序的研究,这将有益于语序类型学整个领域的发展。
