基于组卷积特征融合的One-Stage目标检测模型
2021-11-22鲍先富强赞霞李丹阳
鲍先富,强赞霞,李丹阳,杨 瑞
(中原工学院,河南 郑州 450007)
0 引 言
随着社会车辆的快速增多,道路交通变得愈加复杂。为了提高道路安全,避免人为驾驶失误造成不必要的交通事故,越来越多的研究学者开始对无人驾驶领域进行研究,其中包括目标识别在内的计算机视觉任务。在车辆行驶过程中,针对汽车、行人等关键目标的识别与检测任务对车辆安全行驶和避障有着举足轻重的作用,得益于近些年来深度学习的快速发展和硬件算力的巨大飞跃,基于深度学习的目标检测算法取得的检测效果受到各方学者的青睐。该文针对无人驾驶领域已有的关于车辆和行人的检测和识别任务进行优化,针对车辆密集场所提高模型检测精度,检测算法以基于YOLOv3[1]目标检测模型对目标检测框架进行优化,其中的改进主要为:(1)对Darknet-53[2]主干网络中的残差模块和基于步长为2的卷积下采样方法进行改进;(2)为提升原YOLOv3目标检测网络对于不同尺度目标的检测能力,该模型在原模型的基础上加入自适应空间特征融合模块(ASFF),在提升对不同目标尺度包容能力的同时提升网络的检测能力,降低对关键目标的漏检率;(3)实验在PASCAL VOC2007和PASCAL VOC2012数据集[3]上进行对比测试,取得了比原始YOLOv3检测框架精度高12%的检测效果,且对改进后主干网络的推理速度没有显著影响。
1 相关工作
传统的目标检测算法多是基于设计手工特征,通过观察待检目标进行人为设计特征学习方式,其算法检测过程主要分为区域选择、特征提取和分类器分类三个步骤。区域选择一般通过滑动窗口的方式对图像区域进行遍历,其中滑动窗口的大小及长宽与检测模型的检测精度与速度密切相关。传统特征提取算法主要包含SIFT[4]、HOG[5]等,这种传统算法对于检测目标的多样性、光照强度、背景的复杂性具有较差的鲁棒性。
自2013年以来,深度学习得到迅速发展和广泛研究,其中基于深度学习的目标检测算法分为:区域法和回归法。基于区域提议方面的目标算法如Faster RCNN[6],由于实时检测效果不够理想,无法用于无人驾驶和检测等领域。在基于回归的单阶段目标检测算法中,张海涛等学者[7]基于SSD算法[8]引入注意力机制和扩大感受野的方式,增强高层特征图所包含的高级特征信息,实现检测效果的提升,但是其总体精度仍然较低;Redmon等学者[9]在YOLOv2的基础上结合ResNet、特征金字塔等思想提出YOLOv3算法,该算法在实时性和检测精度方面得到广泛提升,但是在小目标和目标密集环境中存在漏选和目标重写现象;顾恭等学者[10]在YOLOv3的基础上通过增加主干网络输出特征图数量,增加对不同尺寸目标的检测能力;Bochkovskiy A等[11]在综合许多已有学者研究成果的基础上,通过组合不同的优化技巧对YOLOv3进行优化,使其精度达到新的高度。
综合当今研究的优势与不足,该文以YOLOv3目标检测网络为基础作进一步改进,选择YOLOv3目标检测网络基于如下原因:(1)YOLOv3为单阶段目标检测网络,在实际检测应用中能够达到实时检测效果;(2)为了单独分析优化方法的效果,避免受YOLOv4中的多优化方式影响,单独分析文中优化方法的优劣,所以不使用最新的YOLOv4作为基准网络比较;(3)YOLOv3目标检测模型对于密集、多尺度目标存在漏选特点、密集目标检测回召率低等问题,使用该优化手段验证对YOLOv3的改进程度和效果。
2 模型介绍
2.1 YOLOv3模型
YOLOv3[1]是Redmom等学者于2018年提出的单阶段目标检测网络,该算法主干网络结构为Darknet-53[2],如图1所示。该算法结合残差网络、特征金字塔多尺度检测等一系列优秀的网络设计思想,能够达到较好的检测效果和几乎实时的检测速度。主干网络Darknet-53引入了ResNet[12]网络模型中的残差单元并进行重新组合,主干网络中的残差单元将传递的特征图依次进行卷积核为3×3、步长为2的卷积操作和下采样处理,再依次进行卷积核为1×1、步长为1,卷积核为3×3、步长为2的卷积处理,之后再与输入特征相加,由此组成残差单元。主干网络Darknet-53通过残差单元堆叠、卷积和下采样处理得到不同尺度的特征图,并通过上采样和卷积处理结合不同尺度的特征图,形成特征金字塔结构,从而实现不同尺度目标的检测,有效避免由于网络深度过高而造成的梯度消失问题。
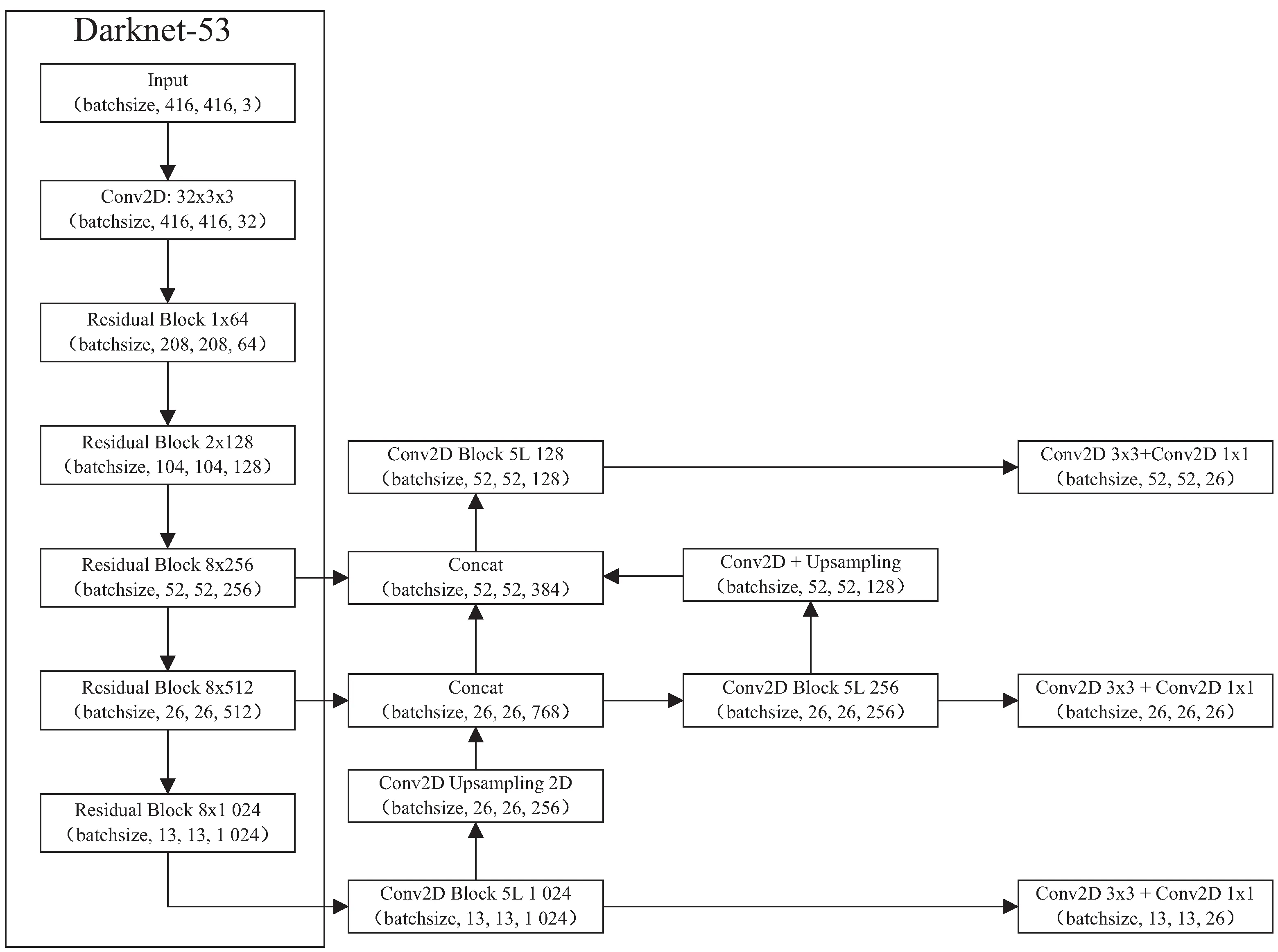
图1 Darknet-53结构
2.2 分组卷积与通道洗牌
基于YOLOv3目标检测框架和最新的目标检测算法思想,该文以主干网络DarkNet-53[2]为基础对网络结构进行修改,重新优化其中的残差单元并引入组卷积和通道洗牌技术。组卷积技术是由Cohen T等学者[13]提出,主要是对输入的特征图进行通道分组,然后对每组特征图分别进行卷积操作,如图2左为传统卷积技术,右为分组卷积技术。在分组卷积中,若输入特征图的大小为C×H×W,输出的特征图数量为N,如果要分为G个分组,则每组输入特征图输入通道为C/G,每组输出特征图的数量为N/G,每个卷积核尺寸为C/G×K×K。假设卷积核的总数仍为N,每组卷积核为N/G,由于卷积核只与同组的输入特征图进行卷积操作,每个卷积组的总参数量为C/G×N×K×K,所以由计算对比可知,分组卷积比传统卷积在参数量上减少为原来的1/G,其组操作如图2右图所示。分组1的输出特征图数量为2,使用2个卷积核,每个卷积核的输入通道数为4,分组中每个卷积核计算所用通道数与输入特征图通道数相同,卷积核只和同组的输入特征图做卷积操作,而不与其他组的输入特征图做卷积操作。

图2 普通卷积与分组卷积示意图
YOLOv3网络模型采用传统卷积和深度可分离卷积(depth separable convolution,DSC)进行特征提取和特征筛选,其中可分离卷积对网络结构存在性能瓶颈[14],如果直接在通道组内进行逐点卷积(point wise convolution,PWC),会导致各个通道内的信息不能进行相互流通交流。为了解决瓶颈问题,文中对主干网络结构引入通道洗牌技术(channel shuffle,CS)[15]。通道洗牌技术[16]是一种组内卷积和整组卷积的折中解决方案,通过组合3×3和1×1卷积的方式进行深度可分离卷积。假设输入的特征图大小为h×w×c1,输出的特征图为h×w×c2,此处进行1×1逐点卷积的浮点运算量为:
F=h·w·c1+h·w·c2
(1)
由公式(1)知:当c1×c2远大于9时,可以发现其可分离卷积的计算量增长主要在1×1逐点卷积上,引入分组卷积后,在组内进行1×1逐点卷积,对于分成g组的分组卷积的计算量为(FLOPs):
(2)
对比公式(1)和公式(2)可以发现,通道内分组后再进行卷积可以有效降低逐点卷积的计算量,同时为了解决深度可分离卷积的各特征图通道之间信息沟通不畅的问题,检测模型引进了通道洗牌技术。如果分组的特征图尺寸为w×h×c1,其中c1=g×n,g表示分组卷积过程中的分组数,进行通道洗牌的操作如下:(1)将特征图展开成g×n×w×h的四维矩阵,此处将w×h用s表示;(2)将g×h×s的矩阵分别对g轴和n轴进行转置操作后,把得到的转置结果矩阵进行平铺,最后使用卷积核为1×1的组卷积操作,如图3所示,先将得到的特征图通道数目分为9个相同的通道数,并将得到的9个通道集合顺序打散,将其与对应卷积核进行卷积操作后,将得到的特征图恢复到开始之前的张量结构。
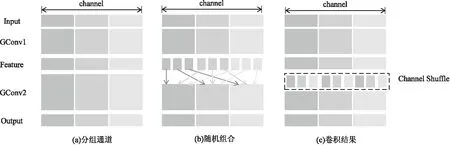
图3 分组卷积和通道洗牌
2.3 残差单元改进
深度卷积神经网络如ResNet[14]和DenseNet[15]等类型的复杂网络模型推理速度较慢,不能满足实时检测需求,为了更好地在移动设备上运行,模型设计需要考虑模型的参数规模和移动设备的内存大小。Ma N等学者结合Shufflenet和Mobilenet设计思路,提出了关于轻量级网络的设计观点[16],其中轻量级的神经网络应当符合如下设计准则:(1)使用轻量级网络模型中的深度可分割卷积(depthwise separable convolutions,DSV),在输入通道和输出通道采用相同通道大小的情况下可以最小化内存访问量;(2)过量使用组卷积会增加模型的内存访问量;(3)对于Inception类网络的“多路”结构,会导致网络结构的碎片化并降低网络模型并行度;(4)网络模型中的元素级操作虽然有较大的时间开销,但具有很大的作用,能提升特征的可代表性。根据这四条轻量级网络设计原则,文中对主干网络DarkNet-53中的残差单元进行修改,具体改进结构如图4所示。

(a)ResNet残差单元 (b)改进的残差单元结构 (c)改进的下采样方式
图4 改进结构
原YOLOv3模型中所采用的主干网络DarkNet-53的残差单元如图4(a)所示,在该结构单元采用逐元素操作相加方式(Add)对两分支信息进行整合,这样的元素级操作会增加主干网络模型计算量[16]。如图4(b)所示,改进后的残差结构将其更改为通道连接操作(Concat),同时为增加各通道的信息交流,在结构中加入通道洗牌操作,先将输入的网络特征图分为c′和c-c′,为了符合Ma N提出的网络设计规则[16],一般c′=c/2。其中图4(c)左网络分支作为输入特征图的同等映射,对输出特征图进行复制,右分支对输入特征图连续进行3次卷积操作,令其输入输出通道数相等,对左右两分支进行通道连接操作(Concat),并进行通道洗牌以保证残差结构和特征图内各通道的信息交流,舍去原网络模型中使用步长为2的卷积下采样方式,改为图4(c)所示的下采样方式,以此避免原特征图中的信息丢失,并对其进行特征筛选和深加工。
2.4 自适应空间特征融合
为了充分利用高层特征的语义信息和底层特征的细粒度特征,文中结合基于特征金字塔(feature pyramid networks for object detection,FPN)思想改进而来的自适应空间特征融合金字塔(adaptive spatial feature fusion pyramid,ASFF)[17]。ASFF是一种特征混合的方法,可以在空间上学习其他尺寸特征图的特征信息,并保留有用的特征信息。对于待融合的特征图后的特征图信息,网络使用卷积操作将其他尺度大小的特征图进行融合,此时通过使用上采样和1×1卷积进行通道变换,将尺寸需要调到相同的大小,然后进行加权,通过训练学习找到最好的参数组合。在每一个特征空间位置上,不同的特征会被自适应融合,如果有矛盾信息,通过训练可通过小权重参数将其过滤掉。ASFF具备很多的优点,如实现成本低,几乎不增加模型推理时间,对一般的主干网络模型也具备一定的泛化能力,适用于类似YOLOv3等一系列具有特征金字塔结构的One-Stage目标检测器。针对YOLOv3中提取的3个不同尺寸的特征图,文中通过将三个不同尺度和权重的特征图进行结合,将特征金字塔结构进行修改,有效提升了对不同尺寸目标的检测精度,在一定程度上解决了模型的漏检问题。
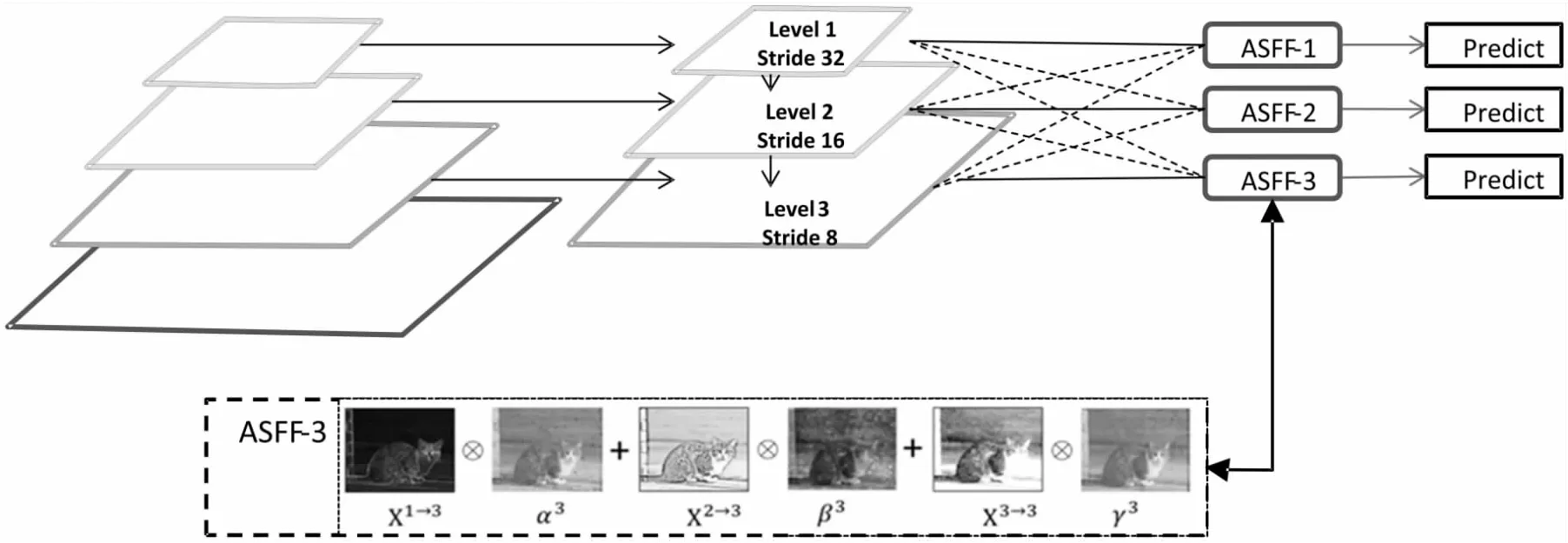
图5 混合特征金字塔模型
针对来自不同层的特征进行融合,每一层有它对应的权重系数。为了确保在融合时不同层输出的特征和通道数是相同的,当特征图尺寸不相同的时候可以通过上采样或者下采样来进行调整,其中权重系数是由预定义尺寸的特征图经过1×1卷积得到的,其各权重矩阵中权重因子的累加和为1,权重系数在[0,1]之间,特征融合的公式如(3)所示:
(3)
2.5 模型概述
基于YOLOv3进行改进,文中在主干网络基础上对网络残差单元和下采样方式进行优化,并将提取到的特征图结合ASFF模型进行混合特征提取,残差单元改进与组卷积、通道洗牌相结合是针对主干网络的改进,ASFF是针对特征检测层的特征提取优化,整体目标检测框架是基于YOLOv3进行优化而来,如图6所示。其中Stage2模块由图4(b)所示的改进残差单元组成,且下采样方法如图4(c)模块所示,Stage2部分是由改进的残差单元重复4次得到的,Stage3由改进残差单元重复8次得到,同理Stage4也是由改进后的残差单元重复8次组合得到。由此,改进后的主干网络(restruct network,RN)结构如图6所示。
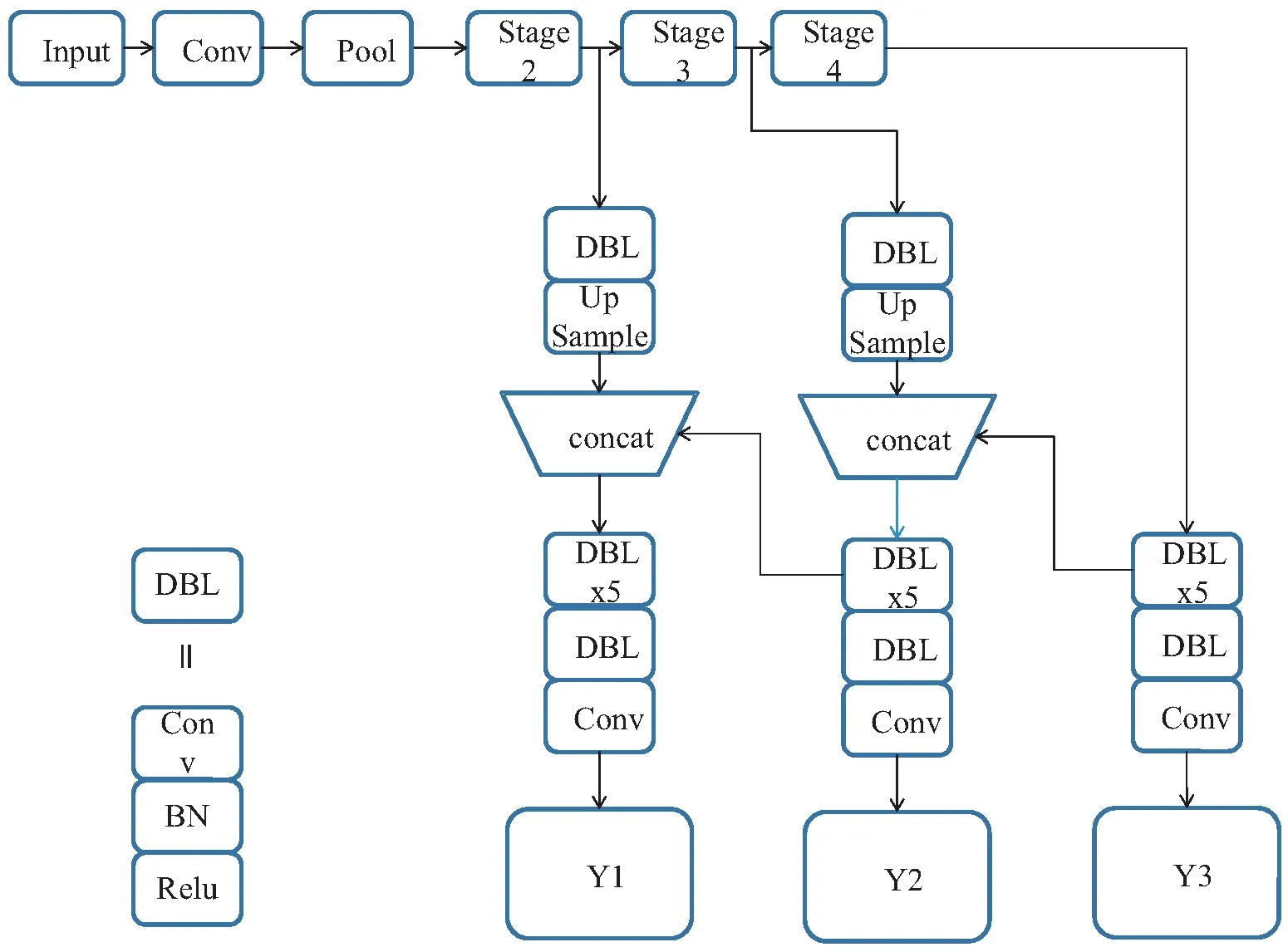
图6 改进后的主干网络模型
设置目标检测的损失函数是为了让候选框坐标、置信度、分类损失三者之间达到平衡,如果简单地将各个损失相加,会存在以下问题:(1)不同维度的分类损失同等重要,简单将其相加会将二者视为同等重要,这种做法不够合理;(2)大目标物体的定位损失偏大,小目标物体的定位损失偏小,直接进行损失相加,会导致网络发散无法收敛。为缓解这些问题,将各类损失进行加系数和变形的方式进行改写,损失函数如公式(4)所示:
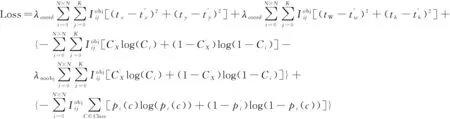
(4)

在训练开始阶段,实验对模型进行如下设计:(1)对没有目标的候选窗口的置信度损失赋予更小的损失权重,并记为λnoobj,在数据集PASCAL VOC中取0.5;(2)为了使模型更加重视有目标的单元格,并记为λcoord将这些损失钱赋予更大的权重,在PASCALVOC2007和2012数据集上训练时设置为5;(3)侯选窗的置信度和类别损失初始设置为1,对不同大小侯选框进行预测,较大的侯选窗置信度预测存在偏大问题,为避免小候选窗预测值偏低的情形,将候选窗高宽取平方根代替原本的宽高值。
3 实 验
主干网络是以DarketNet-53为基础进行改进得到,整个检测模型的优化效果是通过VOC2007和VOC2012数据集进行验证和比较。在实验部分,通过设置相同的初始化变量和超参,使用不同的方法对整个模型结构进行测试,通过不同的实验结果对模型优化程度进行说明,并将改进后的目标检测架构运用于车辆和行人的检测过程,进行密集目标检测测试。实验环境:在Windows10系统环境下,使用16 GB RTX2080ti显卡进行测试,深度学习框架采用Tensorflow-GPU1.4、CUDA10.2。
3.1 数据集
此次实验使用的数据集是作为基准数据集之一的Pascal VOC2012和Pascal VOC2007,该数据集在目标检测、图像分割网络对比实验与模型效果评估中得到广泛应用。Pascal VOC数据集主要是针对视觉任务中监督学习提供标签数据,共有二十个类别数据,主要分为四个大类别,如人、常见动物、交通车辆、室内家具用品等。VOC数据集主要由Annotation、ImageSets、JPEGImages、SegmentationClass文件夹组成。Annotation文件夹是XML文件,是对JPEGImages文件中每个图片的标注信息,一张图片对应一个XML文件;ImageSets文件存放的是txt文件,这些文件将图片切分为各种集合;JPEGImages文件夹存放该数据集所有的图片;SegmentationClass文件夹适用于语义分割任务。文中主要使用VOC数据集进行目标检测,通过将改进后的网络模型与原模型效果进行对比,同时为了加大数据集容量,将VOC2007和VOC2012的数据集结合进行综合训练,并对训练后的网络模型进行评估。
3.2 实验结果
文中分别对修改后的主干网络(RestructNet)和混合特征金字塔模型(ASFF)进行测试,通过与YOLOv3的实验结果进行对比,分别在平均精度(MAP)、总体损失(Total Loss)和每秒传输帧数(FPS)指标上验证不同优化方法的检测效果和处理速度。实验结果如表1所示,修改后的主干网络和自适应特征混合模型组合的方法对于模型检测精度有明显优化效果。由实验结果可知,对原残差单元的修改和主干网络的重构对检测精度有明显的提升效果,在精度方面提升4.36%,其中混合空间特征金字塔模型的使用在精度方面提升3.0%,综合精度提升8.31%,在不影响检测速度的情况下,实现检测模型精度方面的优化。

表1 实验结果对比
为了与主流One-Stage目标检测模型进行对比,文中在相同实验环境和训练参数下,与最新YOLOv4和其他YOLO系列目标检测算法进行对比,分别比较推理速度(FPS)、在VOC2007+2012数据集上的测试精度(MAP)、网络参数数量(Parameter)等指标,进一步说明该网络模型的优化效果。通过实验可知,结合残差网络的更改和混合特征融合金字塔优化后的网络结构,大体可以达到和YOLOv4的精度,且模型推理速度及网络参数数量较YOLOv4减少1.21 MB,整体精度较YOLOv3提高8.17%。
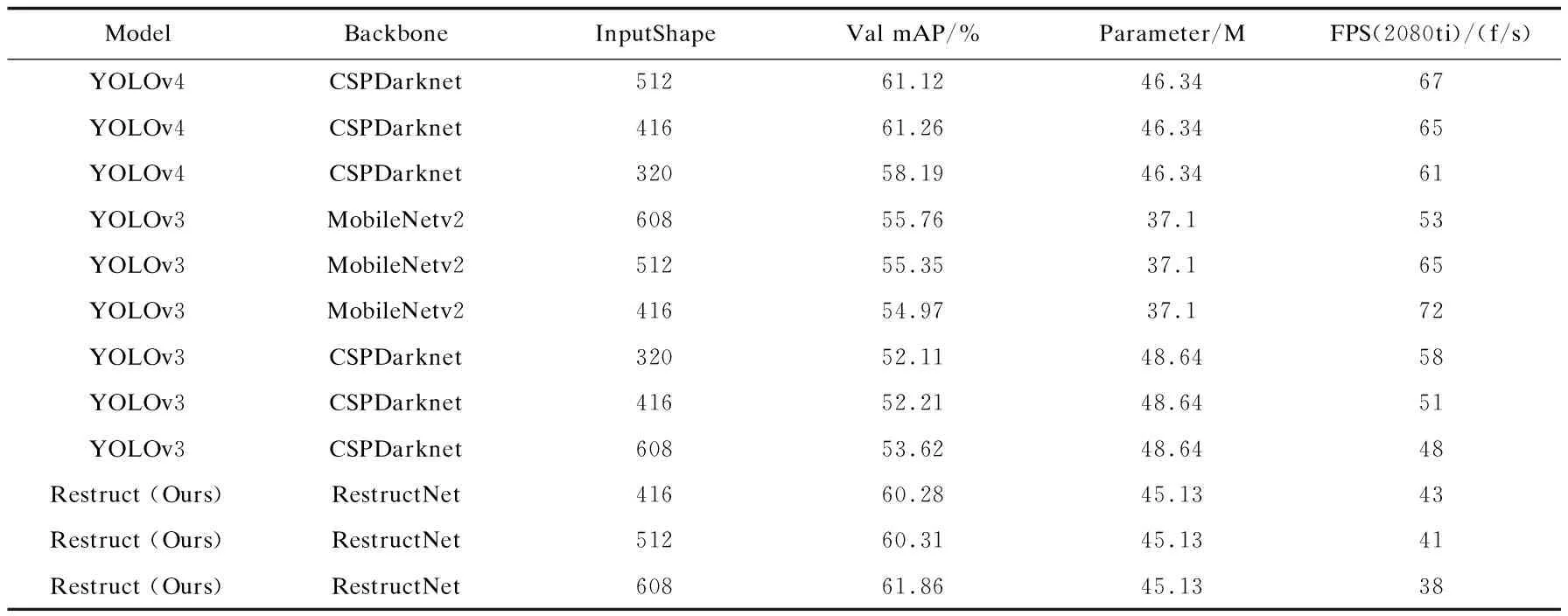
表2 与目前流行的One-Stage算法对比
3.3 实验结果分析
在YOLOv3模型中,将特征图直接输入主干网络结构的残差单元,用分支结构将卷积处理的特征图与原特征图进行相加,这样虽避免梯度爆炸和梯度消失问题,但新生成的特征图包含了许多不必要的背景信息。通过使用图4(b)所示的残差单元进行改进,同时对两个网络分支进行信息处理,由实验结果可知,检测模型精度提升了8.07%。
由Hurtik P提出[18],原YOLOv3网络模型对于密集目标存在漏选和标签重写问题[1],为了解决该问题,实验基于数据驱动的金字塔特征融合方式,该方法通过学习在空间上过滤冲突信息以抑制梯度反传时的不一致性,以此增加待检目标尺度的容纳性,同时降低推理开销。通过使用统计的日志文件绘制训练损失图,如表2所示,使用ASFF的模型在测试集上的验证损失明显低于原YOLOv3模型的训练损失,且比原模型具有更快的收敛速度,借助ASFF和组卷积优化残差单元组合的方式,在VOC数据集上实现了60.28%的平均精度以及43 FPS的运算速度。为了更好地进行对比,训练均未采用预训练的主干网络权重,因为改进的网络结构没有预训练权重可供参考。

图7 模型训练收敛及精度提升变化
通过对残差单元、下采样方式进行修改,然后和ASFF进行组合得到新的检测模型,通过实验进行综合测试,新的检测模型可以在VOC2007和VOC2012得到60.28%的检测精度。由图7对比所示,为了发挥One-Satge目标检测模型实时检测的优势,在不影响改进模型精度的条件下,主干网络(beckbone network,BN)和检测网络(neck network,NN)对不必要的卷积层进行删除,可明显看出新模型较原YOLOv3模型,关于平均精度的提升和训练的快速收敛情况,在每张图(416×416)的检测时间仍然可达43 ms帧率,与原YOLOv3模型相比,仍然可以达到实时性的检测效果。
3.4 模型运用
由实验证明,通过引入组卷积和通道洗牌技术对残差单元进行修改,和自适应空间特征混合(ASFF)组合的方法,可以取得明显的优化效果。为了验证在实际环境中改进后的目标检测模型的检测效果,文中将数据集COCO2017内的关于无人驾驶相关的检测类别进行分离,对分离的数据集使用K-means方法产生锚框并进行矛框大小设置。实验对分离后的数据集使用K-means方法进行锚框大小选取,通过聚类分出各个锚框的类别,然后分别对各个类别的锚框宽高取均值,得到目标的候选锚框大小分别为(10,13),(16,30),(33,23),(30,61),(62,45),(59,119),(116,90),(156,198),(373,326)。改进后的模型在分离的数据集上进行训练得到的检测效果如图8、图9所示,训练后的模型在密集车流下进行测试,改进后的目标检测模型可以取得理想的检测效果且能够达到实时的检测速度,原YOLOv3模型存在的密集目标漏选和标签重写现象[18]也得到改善。

图8 YOLOv3测试效果

图9 改进模型的测试效果
4 结束语
文中以YOLOv3为基础进行改进,得到一种单阶段实时目标检测模型,旨在针对无人驾驶、安全监控等领域进行目标检测和识别。首先,引入组卷积和通道洗牌技术,并对原Darknet-53网络的残差结构进行优化改写,为了更多地保留特征图的有效信息,使用了全新的下采样方式对特征图进行尺寸缩减;其次,为了克服原YOLOv3检测模型对密集目标存在的漏选和标签重写问题,使用自适应特征混合金字塔对输出的特征图进行空间特征混合处理,加强不同尺寸的检测特征图之间的信息交流,以此加强对密集目标的检测能力;最后,使用PASCAL VOC2007和VOC2012进行测试,改进后的目标检测模型相较于YOLOv3提升了8.17%,取得了和YOLOv4大体相同的精度,并且可以达到实时的检测速度。通过实验进行测试,该模型可以有效地运用于交通监测和交通目标识别应用中,具有很强的应用性。
