基于胶囊网络模型的抑郁症预测研究
2021-11-22王汝传
査 猛,叶 宁*,王汝传,徐 康
(1.南京邮电大学 计算机学院、软件学院、网络空间安全学院,江苏 南京 210003;2.江苏省无线传感网高技术研究重点实验室,江苏 南京 210093)
0 引 言
随着现代生活的快速发展,心理健康问题引起社会各界越来越多的关注。抑郁症也称抑郁障碍,是一类以显著而持久的心境低落为主要特征的情绪障碍疾病,具有慢性、反复发作、迁延不愈、自杀率高的特点[1]。因此,对抑郁症患者进行早期识别诊断,并及时给予治疗十分重要。但是,目前抑郁症的诊断主要以问卷调查为主,并以医生的判断为辅。其准确程度主要依赖于医生的专业水平和经验以及患者的配合程度,并且患者的早期诊断和评估具有非常大的限制,如患者没有意识到自己得病、患者不愿意就医等[2]。针对抑郁症的诊断困难问题,由于近年来微博、推特等社交工具的广泛使用,产生大量的可分析数据,为采用机器学习方法来识别轻度抑郁症患者提供了数据基础,因此利用机器学习来预测网络用户的抑郁症倾向得到了越来越多研究人员的关注,并成为自然语言处理领域的研究热点之一[3]。
国内外许多研究人员针对情绪分析已经做了大量研究,但在社交网络中利用微博或推特评论并基于深度学习框架关于抑郁症的研究很少[4]。近年来,不断有学者提出用图像领域的卷积神经网络来解决自然语言处理的任务。受此启发,文中使用卷积神经网络来处理微博文本的抑郁症预测任务,但是卷积神经网络存在池化层丢失信息以及无法学习文本内在的关联信息等问题,并且抑郁症的预测不是情绪的正负极判断,仅仅通过神经网络模型训练得出的预测结果较为不准确。为了解决难以充分利用文本情绪特征和抑郁症预测不准确的问题,文中设计了融合局部与整体特征的胶囊网络模型。该模型使用胶囊网络来弥补卷积神经网络的缺点,可以充分地学习文本整体与局部的内在空间关系,并且使用情绪词典准确地找出微博数据中与抑郁症相关的文本,提高抑郁症预测的准确率。模型中情绪词典用于选取文本中的局部特征,胶囊网络用于学习文本的整体特征,在模型的输出层使用两种方法将局部特征和整体特征进行融合得到微博用户抑郁症预测的最终结果。通过与几种典型的机器学习算法对比表明,提出的基于局部与整体特征的胶囊网络模型在抑郁症的预测中具有更好的效果。
1 研究现状
抑郁症是一种与情绪密切相关的严重疾病,对人的健康有着非常大的危害。情绪分析相对于抑郁症已经被广泛的研究了很长时间。情绪可以分为基本情绪和复杂情绪,但不同的精神病学家对情绪的详细分类不同,导致了结果也存在一定的差异。根据Ekman[5]提出的被广泛使用的模型,有六种基本情绪:惊讶、恐惧、厌恶、愤怒、快乐和悲伤。通过结合这六个情绪,可以得到各种复杂的情绪描述,如抑郁、紧张、焦虑等。目前,在社交媒体网站中用户产生了丰富的多媒体信息,这种信息不仅包含了用户的不同观点和思想,而且包含了用户的情绪信息,正是这些情绪信息可以用来做心理健康的研究。因此,基于社交媒体的情绪分析现在已经成为了研究热点,并且随着深度学习在自然语言处理领域的发展,使用深度学习来解决情绪分类的研究越来越多,如Kim等人[6]用卷积神经网络对电影评论进行情绪分类;Kalchbrenner等人[7]用卷积神经网络处理Twitter文本;Wang等人[8]用长短期记忆网络对文本情绪极性进行分析。这类基于深度学习的方法都取得了比传统分类器更好的效果,还有一些研究者针对短文本来构建分类模型,如Vo等人[9]提出了使用多样化特征对Twitter文本进行情绪分类;Tang等人[10]通过情绪种子扩充特定领域情绪词对用户评论进行情绪分类。除此以外,还有一批过国内学者利用微博文本进行情绪分析,如冯等人[11]首先将卷积神经网络应用于微博的情绪分类中,取得了不错的效果;陈等人[12]提出了多通道卷积神经网络模型,利用情绪特征信息以及将多方面特征信息进行结合来对微博情绪进行分析;周等人[13]使用基于注意力机制的LSTM模型进行情绪分析,以更好地学习文本中的情绪信息,提升情绪分类的成功率;张等人[14]运用多尺度卷积核改善微博评论中上下文信息有限的条件制约,来提高卷积神经网络对于微博评论情绪分类的效果。但这些都是情绪分类方面的研究,国内对于利用互联网数据进行抑郁症方面的研究还具有很广阔的前景,现有的关于微博情绪分类的研究主要在于识别文本的基本情绪上,这是因为复杂的情绪分析在不同的领域具有不同的策略,并且对人的情绪进行进一步的研究时会有非常多的限制,如抑郁这一情绪的研究。抑郁症是一种病因非常复杂的精神疾病,精神病学、心理学、医学、社会学等方面的专家进行了大量的相关研究。心理学家使用不同的抑郁测量量表,如SDS(自我评价抑郁量表)和CES-D(流行病学研究中心抑郁量表)来确定人们的抑郁程度。医学研究人员还研究了许多行为信号来检测人们的心理状态,比如大脑信号、心率、血压、声音韵律和面部表情来获得心理生理学信息[15]。
随着移动网络技术的飞速发展和智能手机的广泛使用,社交网络也得到了迅速的发展,许多人使用了一种或多种社交网络服务表达他们的观点和情绪,如Facebook、Twitter、微博、微信、QQ等。因为抑郁个体的发帖内容往往含有许多负面情绪词汇,所以这些文本数据为研究者在社交媒体网站上找到潜在的抑郁症患者提供了一种可能的途径。一些研究人员在网上社区或者论坛的基础上对抑郁问题进行了情绪分析,如Nguyen等人[16]研究了网络抑郁社区的特征,并与其他社区的特征进行了比较,利用情绪信息、兴趣话题和语言风格进行抑郁分析。更多的研究人员使用在线社交网站来预测抑郁症,如Park等人[17]努力研究在社交网络中对抑郁症起决定性的因素;王等人[18]建立了预测抑郁症的关联模型,该模型建立在情绪分析算法的基础上,将患者行为特征与影响抑郁症预测的原理症状进行了比较。上述的研究都是通过情绪分析来进行抑郁分析,可见对于抑郁症的预测分析网络中帖子的内容是一个非常有效的方法。
在机器学习领域的发展中,卷积神经网络原本是用来处理二维图像的网络,常用来提取图像的特征,在图像处理领域有非常好的效果。在2014年Kim[6]将CNN网络用在了文本分类任务中,并且取得了目前最好的效果。尽管卷积神经网络在许多领域取得了非常好的效果,但是卷积神经网络有两个无法弥补的缺陷,一个是卷积神经网络无法学习图像内部之间的相对位置关系,另一个是训练一个卷积神经网络需要大量的数据。在2017年Hinton等人[19]提出了改进的卷积神经网络——胶囊网络,胶囊网络在卷积神经网络的基础上增加了胶囊层,并且在胶囊层之间使用动态路由算法来更新参数,这一网络完美地弥补了卷积神经网络的缺点,在MNIST手写数据集上取得了令人满意的效果。但是胶囊网络是使用在图像处理领域的模型,文中受到卷积神经网络用于文本分类任务的启发,将胶囊网络进行细微修改,用于学习微博文本中的情绪特征,通过用户的帖子来辨别该用户是否存在抑郁倾向,使用了适用于抑郁症的情绪词典来提高预测准确率。实验结果表明,与传统的机器学习模型相比取得了不错的预测效果。一旦通过社交媒体的数据发现了潜在的抑郁症患者,就为精神病学家提供了有用的线索,从而可以立即进行干预和治疗。
2 CapsNet抑郁症预测模型
2.1 CapsNet模型
近几年,卷积神经网络因为可以充分利用多层感知机的结构,具备很好的学习复杂、高维和非线性映射关系的能力,在图像识别任务和语音识别任务中得到了广泛的应用。随着研究的不断深入,卷积神经网络也逐渐被应用于自然语言处理领域,并取得了很好的效果,但是卷积神经网络有着不可弥补的缺点,如需要大量的数据来训练网络中的参数,以及无法学习事物内部结构之间的相关关系特征等问题。在2017年CapsNet应运而生——Hinton等人针对CNN的不足提出了胶囊网络模型。模型的结构如图1所示。

图1 CapsNet模型结构
CapsNet的核心结构由3层构成,模型的第一层与CNN中的卷积层相同,通过第一个卷积层粗略映射事物的局部特征,在卷积层后接一个RELU激活函数将线性映射变为非线性映射。结构中的第二层即为胶囊层,其实这是一个特殊的卷积层,由8×32个大小为9×9的卷积核卷积得到,胶囊层可以将卷积层提取的特征图转化为向量胶囊,它的维度比正常的卷积层要高一维,由32个长度为8大小为6×6的胶囊组成。第三层为数字胶囊层,是一个维度为16×10的矢量,16是一个向量的维度,10代表类别数,其中向量的长度可以表征实体存在的概率,向量的方向可以表示实例化参数(即实体的某些图形属性)。
2.2 动态路由算法
主胶囊层和数字胶囊层之间采用动态路由算法进行更新,这一过程解决了卷积神经网络在池化操作中丢失局部特征的问题,增强了网络鲁棒性,动态路由算法的结构图如图2所示。
在主胶囊层和数字胶囊层之间,一个预测向量首先通过主胶囊层的胶囊向量ui乘以一个权重矩阵Wij计算得到,表达式为:
(1)
然后,在数字胶囊层中,通过对权重Cij和向量uj|i进行线性组合生成胶囊Sj,表达式为:
(2)
其中,cij是动态路由过程中产生的耦合系数,通过对bij进行softmax运算得到cij的值,这一运算保证了胶囊uj的所有系数之和为1,并且bij初始化为0保证了在第一次路由中,每一条路径的耦合系数是一样的。cij的表达式为:
(3)
胶囊的长度表示输入样本具有所描述的对象胶囊的概率,即胶囊的激活。因此,胶囊的长度在[0,1]范围内,使用一个非线性压缩函数进行胶囊的压缩,表达式为:
(4)

图2 动态路由算法结构
通过该函数,短向量就被压缩到接近0,而长向量就被压缩到接近1。
最后,胶囊网络的更新其实就是在计算耦合系数,而耦合系数的计算通过在每次迭代中更新bij的值,表达式如下:
(5)
相对于卷积神经网络的池化操作,使用动态路由算法不仅缩短了模型训练时间,而且保留了数据之间的相对位置关系。
2.3 CapsNet抑郁症预测模型
文中提出的CapsNet抑郁症预测模型如图3所示。

图3 CapsNet抑郁症预测模型
模型中输入数据为已经处理好的一条微博文本,是一个N*50的二维张量,N表示输入文本词向量的数量,50是词向量的维度。
模型分为了整体特征提取和局部特征选择,其中整体特征提取使用CapsNet模型,在模型中第一层是卷积层,使用256个9×9卷积核,这样的卷积核可以弥补模型层数较低,充分学习输入文本数据的特征。卷积核的步幅为1,且卷积层中使用RELU激活函数。之后,主胶囊层使用第一层卷积层得到的张量,将卷积层数据作为输入,使用相同的卷积核进行8次卷积操作,从而产生8个张量组成一组胶囊神经元。第三层为类胶囊层,在第二层输出向量的基础上进行传播和动态路由更新,得到最后的预测向量,通过预测向量的模长得出类别概率。每一条微博数据都可以通过模型获得情绪预测概率,将一个用户的所有微博数据作为一个整体,最后取所有预测概率的平均就可以得到一个用户数据的整体特征。
在局部特征选择中,局部特征的选择是通过使用情绪词典统计微博文本的情绪词来进行抑郁识别。但是,在不同语言中有不同的情绪词典,例如,作为一种英语情绪词典,LIWC词典[20]已经得到了很好的验证,并被广泛应用于情绪分析中;作为中文情绪词典,可供文中使用的有HowNet[21]、NTUSD[22]和Chinese Affective Lexicon Ontology (CALO)[23]情绪词典等。HowNet和NTUSD主要用于粗粒度情绪分析,如积极情绪或消极情绪,而CALO主要用于细粒度情绪分析。所有这些情绪词典都不适合用于特殊的情绪识别,比如文中的抑郁情绪识别。文中参考了Zhichao Peng[24]等人的研究,制作了自己的情绪词典来进行局部特征提取,该情绪词典综合了基础情绪词典和网络用语情绪词典,如表1所示。

表1 情绪词典
文中使用情绪词典对处理好的微博文本数据进行情绪词数计算,得出每条微博文本数据中的情绪词数,将一个用户的所有微博以情绪词数进行排序,找出并标记情绪词数多的微博,之后将其对应的序号输入到输出层,由模型得到对应微博的情绪预测概率,作为整个微博数据的局部特征。
由于整体特征和局部特征都是由CapsNet模型产生的二维预测结果,文中将两个特征融合到最终预测中,考虑两个策略,分别是max pooling和sum pooling。
在max pooling中,整体特征和概率大的局部特征被保留,忽略了概率小的局部特征,最终的预测概率Y的表达式为:
(6)
其中,YGlobal表示整体的预测概率,YPartj表示第j个局部的预测概率。文中根据情绪词典选取了排在前K个的局部特征。Y,YGlobal,YPartj都具有一致的向量结构(ypos,yneg),二维向量中的ypos和yneg分别表示积极情绪预测概率以及消极情绪预测概率。
在sum pooling中,所有的局部特征都被使用,文中添加参数β来权衡整体预测概率和局部预测概率,表达式如下:
(7)
3 实 验
3.1 数据集获取
文中的数据来自新浪微博,分为两部分数据,一部分是抑郁症用户的微博数据,另一部分是非抑郁症用户的微博数据。其中,抑郁症用户的数据来自于一家专门做抑郁症监测的公司,帖子的抑郁特征较为明显,例如,“也不是真的崩溃,也不太想活,也不敢去死”、“压死骆驼的不是最后一根稻草,而是所有稻草”、“真不知道自己接下来的人生要怎么办了,很迷茫很迷茫”等。对于非抑郁症用户的微博数据,为了使该部分数据对于模型的训练有明显效果,由笔者团队对网上获取的微博帖子进行严格的筛选,剔除了所有具有负面情绪的数据,保留情感趋向积极的用户数据,内容包括用户基本信息和用户发布的所有微博数据,根据实验需求,选取了自2019年1月到2019年12月的用户微博数据。
绘本的形象也就是绘本的主人公,他既是整个故事的主体,也是情感传达的载体,同时也表现了作者内心索要表达的一些思想。通常治愈系绘本的形象可以分为三大类:第一类是作者的思想载体,作者通过自己塑造的人物形象或者是动物形象来表达作者的内心世界。第二类是对着这本人进行夸张处理,这种绘本的形象通常是作者本身,作者通过自己的日常生活,或者是自己的一些经历通过绘本的形式呈现给读者。第三类是人物形象并不是故事的主角,而是作为一个情节的需要,也会随着故事的改变而改变,这类绘本读者容易跟着作者的节奏一步一步慢慢进入正题,这样也更容易是读者有探索性。
3.2 数据集预处理
从获得的数据中,实验只使用到用户的帖子数据,所以除去了个人简介以及转发数评论数等信息。微博设置的帖子限制符号数为150,由于微博的帖子长短不一,加上含有许多表情符号,为了与文中框架模型的输入数据格式一致,避免高维稀疏向量影响实验的准确率,经过剔除标点符号、表情符号、数字和字母等,从剩下的帖子中选取字数在15以上的帖子。对每个用户的微博数据进行处理后,选取了剩余帖子在150条以上的用户。
如表2所示,根据实验需求,选取了120个抑郁用户和200个非抑郁用户。其中抑郁用户总共发布了24 785条帖子,非抑郁用户发布了62 456条帖子。

表2 实验数据的组成及数量
3.3 词向量的生成
神经网络模型通过接收文本的向量化输入来学习输入句子的特征信息,在文本分类任务中,句子中词语的内容隐含着句子最重要的特征信息。文中以词为单位来表示句子,通过jieba分词工具将上文中处理得到的单一文本数据(不含有标点符号、表情符号、数字和字母等)划分为词,之后将每一个词映射为一个多维的连续值向量,将词向量逐行排列为矩阵,用补齐的方式统一矩阵大小,最终每段文本被表示为长为最大句长、宽为词向量维度的稠密矩阵,可以得到整个数据集词集合的词向量矩阵E∈Rm×|V|,其中m为每个词的向量维度,|V|为数据集的词条集合大小。对于长度为n的句子,句子中每一个词语wi都可以映射为一个m维向量,一个文本的词向量形式如图4所示。
实验中,对句子的输入设定一个最大长度maxlen,对于长度小于maxlen的句子用0向量补全,为了有效降低高维稀疏向量对实验的影响,在数据预处理阶段就已经删去了大量的不合适文本。对词向量的生成,使用的是Word2Vec工具的CBOW模型,未登录词使用均匀分布U(-0.01,0.01)来进行随机初始化,为了降低模型的学习时间,实验中训练的词向量维度为50维。

图4 输入词向量形式
3.4 实验过程和评价指标
通常,较大部分的数据用于训练,较小部分的数据用于测试,文中采用5折交叉验证来进行实验。因此,以用户为单位将实验数据分成5份相同大小的互斥子集,使用4份数据进行训练,1份数据用于测试,最后选择损失函数评估最优的模型参数。
将提出的模型和传统的机器学习模型进行实验对比,验证文中提出的基于局部和整体的胶囊网络模型的有效性。对比的机器学习模型有KNN、DNN、TextCNN和BiRNN等模型。其中,输入数据使用的词向量维度均为50,KNN模型中K取10;DNN模型使用3个隐藏层,维度分别为100、50、25,第一个和第三个隐藏层均使用RELU激活函数;TextCNN模型中含有一个卷积层、一个池化层和一个全连接层,卷积核大小为9×9;BiRNN模型为含有两个隐藏层的双向循环神经网络;以上模型的学习速率均为0.01。

(8)
(9)
(10)
(11)
其中,TP表示正确分类到该类的文本数,FP表示错误分类到该类的文本数,FN表示属于该类但未被分类到该类的文本数。
3.5 实验结果与分析
在该模型中,输出最后预测时使用max pooling和sum pooling两种融合策略,其中含有两个超参数K和β。首先对于sum pooling策略使用不同的β进行对比,如图5所示,在测试集中,设置β=0.4达到抑郁症预测的最佳总体精度。
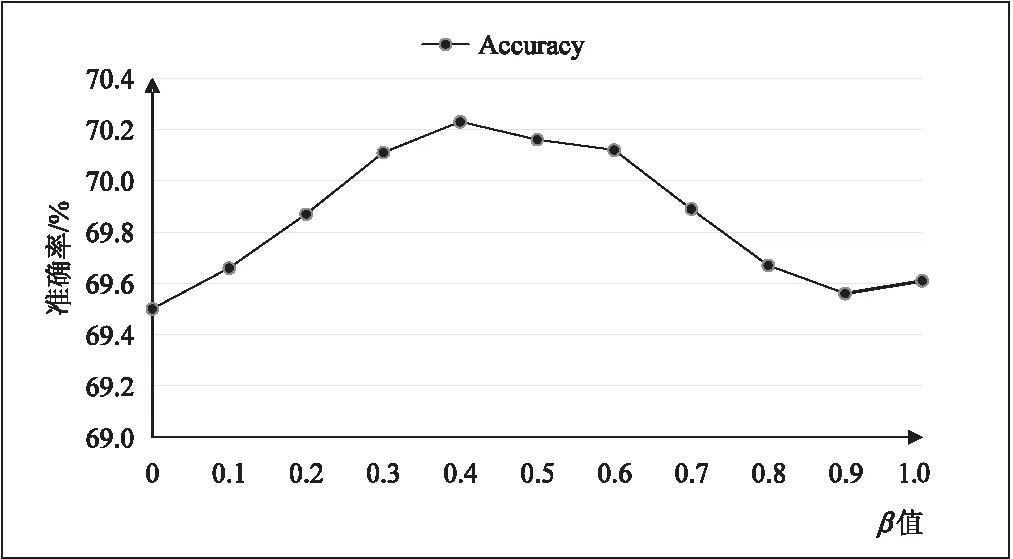
图5 模型准确率-β参数
之后再对两个策略都要使用的局部特征K进行不同值的对比,如图6所示,可以发现在K=7时max pooling策略达到最佳精度,K=8时sum pooling策略达到最佳精度。还可以发现sum pooling策略在效果上要明显好于max pooling策略,因此在之后的对比实验中,均采用sum pooling策略进行对比。

图6 模型准确率-K值
在处理好的数据集上,运行了不同的模型,将实验结果的精确率、召回率、综合评价指标和准确率进行对比,实验结果如表3所示。

表3 实验结果
实验结果中,PGCapsNet模型得到了比其他模型更好的精确率、召回率和综合评价指标,除此以外,PGCapsNet模型获得了73.79%的准确率,而传统的文本分类模型KNN和DNN的准确率分别为61.07%和65.54%,此外TextCNN和BiRNN模型的准确率要高一点,分别为70.66%和70.39%。实验结果证明,提出的PGCapsNet模型对于抑郁情绪分类的性能要优于其他模型。
4 结束语
随着互联网的发展,社交媒体提供了新的方法去识别潜在的抑郁症患者,由此提出了面向微博文本的抑郁症预测模型。模型中,首先将文本特征划分为局部特征和整体特征,之后使用情绪词典选取局部特征,以及CapsNet模型学习整体特征,最后在输出层将两部分特征进行融合得到用户的抑郁症预测概率。实验证明,提出的模型在基于微博文本的抑郁症预测方面具有不错的效果。
在今后的研究中,将尝试使用BERT(bidirectional encoder representation from transformers)模型与胶囊网络模型相结合,进一步提高模型对于抑郁情绪预测的准确率。此外,文中实验数据集并不丰富,未来的研究中将使用样本量足够大的数据来训练复杂的模型,使得模型可以取得更好的性能。
