基于深度学习的手写简答题智能评分研究
2021-11-22刘锋
刘 锋
(广东松山职业技术学院 电气工程学院,广东 韶关 512126)
0 引 言
随着大数据、人工智能等技术的快速发展与应用,信息技术正在飞速地改变着教育工作者和学习者之间的交互形式,甚至正在推动着教育意识形态的改变。用人工智能推动教育变革,将人工智能研究的最新成果应用于教育实践中,解决当前教育信息化及互联网在线教育的共同发展诉求,是现今教育改革的一种趋势[1-2]。
对于推动教育形态的改变、驱动教育模式的改革,一个优秀的解决方案是依托于大数据及人工智能技术,将“教、学、考、评、管”融合为相互协同的一体化体系,为师生提供一个全面的智能感知环境和综合信息服务平台[3]。其中“考”和“评”是至关重要的环节。在传统的方式中,对学生的评审和考核往往通过组织大型考试,需要耗费大量的时间、人力;同时老师需要手工对学生做的试卷进行批阅,而在批阅主观题的时候,教师往往容易受到批阅时的精力、情绪、学生的卷面等因素的影响,无法给学生做出客观的评价。为了减少在传统过程中老师手动批阅试卷带来的种种问题,本课题组拟开发出一款基于深度学习的简答题智能评分系统,将原来教学环节中批改试卷这种重复性强、有固定模式的部分用人工智能进行替代。这样不仅能够促进教学向智能化方向发展,还可提高老师的阅卷效率,减少老师在重复性阅卷评分上的工作时间,从而把老师的价值集中在与学生的情感交互、个性化引导和创造性思维的开发等方面。
根据第47次《中国互联网络发展状况统计报告》指出,截至2020年12月,中国在线教育用户规模达3.42亿,而其中移动端在线教育用户规模为3.41亿[4]。在未来的商业市场中,在线教育市场前景十分广阔,而“考”与“评”作为不可或缺的环节,意味着本文的产品将拥有十分独特的市场优势。在未来,教育者们将摆脱单调乏味的试卷批改,将精力和时间投入到更加注重教师亲自教育的领域。而本产品可以作为服务融入到许多智能教育软件当中,推动“教、学、考、评、管”教育产业的一体化。
1 相关技术现状
1.1 手写汉字识别技术
脱机手写文字没有笔顺等信息,而且会因扫描设备在不同光照、分辨率、书写纸张等条件下工作而带来很多的干扰。同时,相较于印刷体汉字,脱机手写汉字随意性大、缺乏规范性,人们常用的横、竖、撇、捺、点等笔画容易变形,各种不同的写字风格可能有巨大的差异,从楷书、行书到草书,识别难度越来越高。除此之外,汉字的字符种类繁多,存在许多相似字和易混淆的汉字,例如“已-己”、“口-囗”、“泪-汨-汩”等,也给汉字识别带来不小的挑战。更为重要的是,目前针对大类别、多风格的无约束手写数据库仍显不足,数据库的采集和整理需要消耗大量的人力和物力来兼顾规模性和准确性[5-6]。
1.2 汉语文本分词技术
为了让计算机可以理解人类语言、分析考卷中学生答案和标准答案,就需要进行自然语言处理(NLP)。其中分词是非常重要的一个模块。对于英文等拉丁语系的语言来说,由于词之间有空格作为词边界表示,词语一般情况下都能简单且准确地提取出来[7]。但是汉字除了标点符号之外,字之间紧密相连,没有明显的词边界,因此很难将词提取出来;而且在中文中,单字作为最基本的语义单位,虽然有自己的意义,但是表意能力差,意义较为分散,而词的表意能力更强,能够更加准确地描述事物和情感。因此在NLP中,通常情况下词是最基本的处理单位。
在中文分词中有两个最主要的挑战:歧义词识别和未登录词识别。一般来说在句子中一个字可以同时作为两个词的组成部分,当这两个词同时出现,就可能会出现歧义现象。而未登录词是分词词典中没有收录的,但又确实是大家公认的词语,也被叫做新词。虽然可以通过将新词收录到字典中进行解决,但是在互联网时代,人们会不断创造出一些新词。所以对于新词的自动识别,也是需要解决的问题[8]。
1.3 汉语文本对比技术
主观题阅卷就是将试卷中的学生答案和标准答案进行比对,判断学生答案是否与标准答案相似,并根据它们的相似度进行评分[9]。然而,存在着一些句子,它们当中没有相同的词,但表达的意思相近或者有逻辑关系,例如:“乔布斯离我们而去了。”“苹果手机价格会不会降?”使用传统的方法判断这些句子的相似度是无法得到满意的结果的,因此,在判断文档相关性或相似性的时候,需要考虑文档的语义,对其中的语义进行挖掘。
2 基于深度学习的手写简答题智能评分研究
为实现汉语考试中试卷的自动化批改,本课题以深度学习技术为基础,开发面向简答题评分的智能阅卷系统。该系统涉及汉字手写体识别、中文语义理解、文本相似度评定等科学和技术问题。该文的研究系统流程如图1所示,研究内容及框架如图2所示。
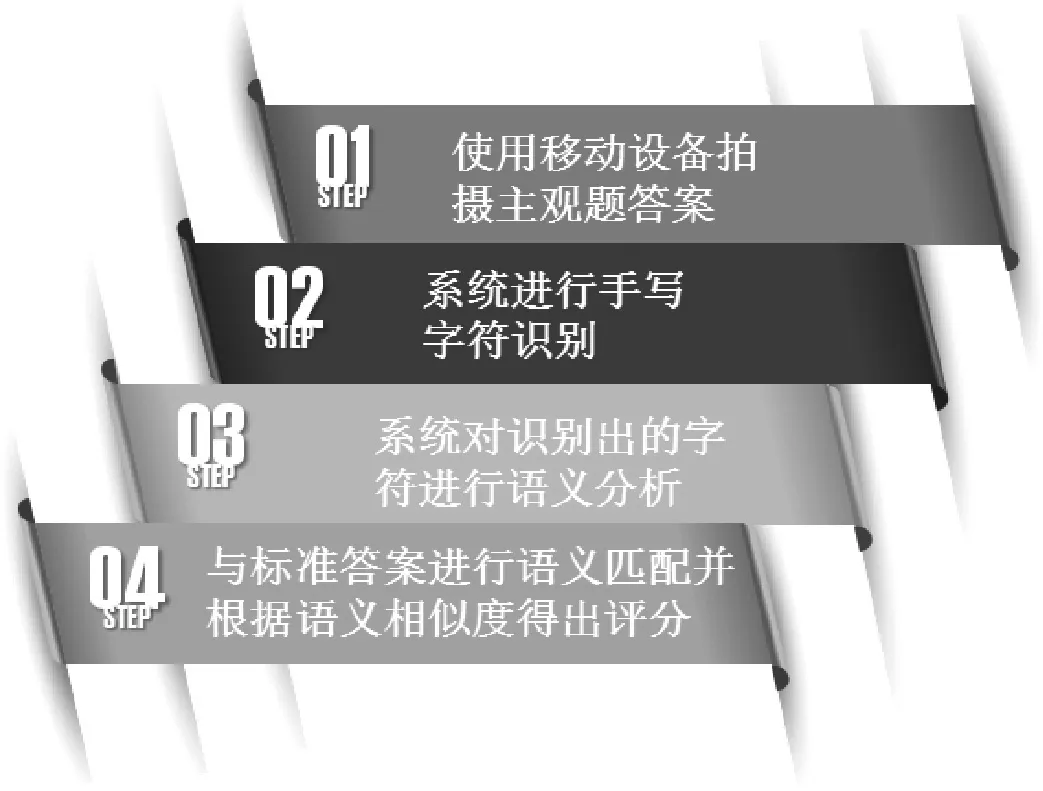
图1 系统流程
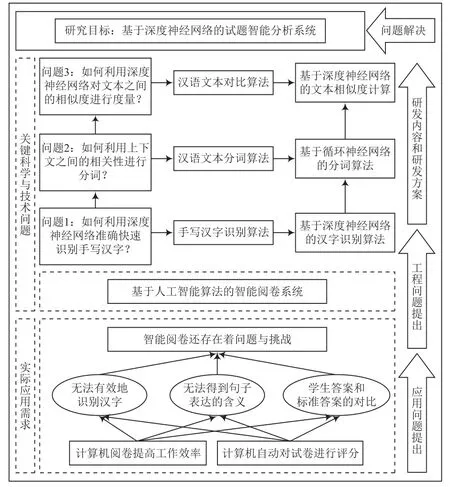
图2 研究内容及方案框架
2.1 基于深度神经网络的手写汉字识别技术
针对手写汉字识别率与识别精度一直比较低的问题,文献[10]采用卷积神经网络(CNN)进行手写体汉字识别。如图3所示,在卷积层上利用多个滤波器对输入的汉字图片进行卷积运算,通过一个激励函数在卷积层得到多个特征图,又对每个特征图进行池化。经过多层的卷积和池化后最终将得到的特征图进行连接,可以得到汉字图片的特征向量;最后通过使用两层Softmax全连接的神经网络,将预测结果通过如下公式进行归一化,对不同的识别结果进行比较后,得到最后识别的手写汉字。

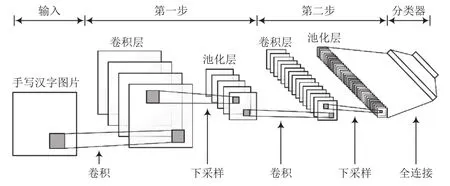
图3 基于CNN的手写体汉字识别示意图
在卷积层中,每个神经元只取前一层的局部区域作为输入,利用局部感受野,减少了神经网络本身需要训练的参数个数,提取汉字图像局部的、细微的特征。在池化层中通过包含的多个特征映射,减少数据处理量、保留有用信息。另外,利用映射平面上所有神经元权值相等,减少了网络中参数的数量,降低训练的复杂度,同时提高对汉字样本中的位移、亮度等变化的容忍能力。
2.2 基于双端长短期记忆神经网络的文本分词与理解技术
为确保试卷评判质量,需要高精度的中文分词及文本理解技术。为此,利用上下文信息进行中文分词与理解就显得尤为重要。本课题拟使用双端长短期记忆网络(Bi-LSTM)实现文本分词与理解,其网络结构如图4所示。

图4 双端长短期记忆网络示意图
长短期记忆网络(LSTM)通过各个计算层的相互连接和作用,保证在分词过程中可与远距离的前文本信息联系,避免了梯度消失和梯度爆炸的问题。利用双端模式,将两个LSTM上下叠加在一起,将分词的输出由两个LSTM的隐藏层状态决定。这样可以让Bi-LSTM不仅仅依赖于前文本的文字,还与后面的文本文字有关,从而真正意义上根据上下文进行分词,保证了分词的准确性。
2.3 基于深度神经网络的文本相似度计算
本文使用词汇语义特征CNN模型(LSF-CNN)计算学生答案与正确答案之间的相似性。该模型在原有CNN基础上引入三种优化策略:词汇语义特征(Lexical Semantic Feature, LSF)、跳跃卷积(Skip Convolution, SC)和K-Max均值采样(K-Max Average Pooling, KMA),抽取更加丰富的语义特征。
该模型对于输入的两个文本进行如下处理:首先,对于学生答案和标准答案的分词序列,利用词汇语义特征技术为每个单词计算LSF特征值,以此来表征文本之间的语义交互特征。LSF特征会与词嵌入拼接在一起构成词语粒度上更加丰富的特征表达,表达词的向量再次拼接构成句子矩阵。然后,学生答案和正确答案的句子矩阵经过跳跃卷积层和K-Max均值采样层,最终形成各自的向量表达,两个向量会根据学习得到的相似度计算矩阵M得到一个相似度分数。最后,将相似度分数和向量整合在一起作为分类器的输入,最终得到学生答案为正确答案的概率。
3 结 语
手写汉字的识别是智能阅卷过程中最基础的一个部分。然而,由于手写汉字的不规范和环境的不断变化,手写汉字的识别可能会受到很大的干扰。如果不能对手写汉字进行准确和快速地识别就无法得到有意义的文本,这样对于文本的分词和文本间相似度的比对也就毫无意义。因此,通过该研究可以解决手写汉字的准确识别。针对汉语文本的分词是计算机可以理解学生答案和标准答案所表达语义的必要途径。然而,由于汉语文本的独特性,分词可能会受到歧义词和未登录词的影响,使得句子偏离原本的表达意义。因此,通过本文的研究,结合文字上下文的相关性进行分词,还可以让文本可以被正确地分词。在试卷阅卷过程中,为了得到每个同学在题目上的分数,需要将学生答案和标准答案进行比对,通过判断它们之间的相似度,系统才能得到学生答题的正确率,以此为基础算出相应的分数。因此,可以利用神经网络对文本间的相似度进行度量,最终实现手写答案智能评分研究的效果。
