一种融合语义知识和BiLSTM-CNN的短文本分类方法
2021-11-20杨秀璋李晓峰袁杰李坤琪杨鑫罗子江
杨秀璋 李晓峰 袁杰 李坤琪 杨鑫 罗子江

DOI:10.16644/j.cnki.cn33-1094/tp.2021.11.013
摘 要: 为快速准确地从海量新闻中挖掘用户需求,解决短文本语义关系单薄、篇幅较短、特征稀疏问题,提出一种融合语义知识和BiLSTM-CNN的短文本分类方法。该分类模型将新闻短文本预处理成Word2Vec词向量,通過卷积神经网络提取代表性的局部特征,利用双向长短时记忆网络捕获上下文语义特征,再由Softmax分类器实现短文本分类。文章对体育、财经、教育、文化和游戏五大主题的新闻语料进行了实验性的分析。结果表明,融合语义知识和BiLSTM-CNN的短文本分类方法在准确率、召回率和F1值上均有所提升,该方法可以为短文本分类和推荐系统提供有效支撑。
关键词: 短文本分类; BiLSTM-CNN; 深度学习; 语义知识
中图分类号:TP391 文献标识码:A 文章编号:1006-8228(2021)11-49-06
A short text classification method fusing semantic knowledge and BiLSTM-CNN
Yang Xiuzhang, Li Xiaofeng, Yuan Jie, Li Kunqi, Yang Xin, Luo Zijiang
(School of Information of Guizhou University of Finance and Economics, Guiyang, Guizhou 550025, China)
Abstract: In order to quickly and accurately tap users needs from mass news, to solve the problems of thin semantic relations, short length, and sparse features in short texts, this paper proposes a short text classification method combining semantic knowledge and BiLSTM-CNN. In this classification model, news short texts are preprocessed into Word2Vec word vectors, representative local features are extracted by convolutional neural network, contextual semantic features are captured by bidirectional short and long time memory network, and then the short texts are classified by Softmax classifier. This paper experimentally analyzes the news corpus of five topics, namely sports, finance, education, culture and games. The results show that the short text classification method combining semantic knowledge and BiLSTM-CNN has improved in accuracy, recall rate and F1 value. This method can provide effective support for short text classification and recommendation system.
Key words: short text classification; BiLSTM-CNN; deep learning; semantic knowledge
0 引言
随着互联网与社交网络的迅速发展,以搜索引擎、微博、论坛、博客、评论等为主体的海量短文本信息与日俱增,如何快速精准地将其进行归类,挖掘出所需的关键知识及研究热点,已成为重要的研究课题。
文本分类作为自然语言处理领域的一个热点和难点,旨在精准地划分文本的主题类别,再通过推荐系统或知识图谱实现关联个性化推荐,帮助用户从杂乱信息中快速、高效地提取所需知识。面对大规模短文本语料,传统分类方法是采用向量空间模型表征短文本,再进行相似性计算,或通过机器学习实现文本分类,缺乏对短文本上下文语义的关联分析,难以避免引入干扰信息和克服短文本的特征稀疏问题,较难挖掘到深层次的文本特征,从而限制了短文本分类的精准度[1]。针对这些问题,本文提出一种融合语义知识和BiLSTM-CNN的短文本分类方法,从而有效地利用上下文语义知识,提高短文本分类的精准度。
1 相关研究
1.1 基于机器学习的文本分类
传统的文本分类方法是基于机器学习和特征工程实现的,国内外学者进行了大量研究。常用的方法包括SVM、KNN、决策树、朴素贝叶斯等[2-3]。刘一然等[4]提出了基于支持向量机(SVM)的学科文本自动分类方法。周庆平等[5]通过聚类改进KNN文本分类算法提升分类效果。何伟[6]应用基于IGDC特征加权的朴素贝叶斯方法进行文本分类,并实现了多种中文文本数据集的对比实验。Elberrichi和Bidi[7]通过遗传算法改进文本分类特征提取过程,提升分类的准确率。杨晓花等[8]改进贝叶斯算法,完成图书自动分类任务。
上述方法虽然不断提升着文本分类的准确率,但只能提取文本的浅层知识,缺乏考虑文本上下文依赖关系,忽略语义知识对文本分类的影响。早期基于机器学习的文本分类方法主要通过词频、TF-IDF、信息熵、互信息等技术提取文本特征,再调用无监督学习或有监督学习算法进行文本分类,这些评估函数大多基于统计学原理,缺乏对海量短文本数据的有效分类[9]。
1.2 基于深度学习的文本分类
随着深度学习和人工智能的兴起,以词向量模型为基础,融合深度神经网络、LDA模型、Attention机制的短文本分类方法逐渐出现。2013年Mikolov等[10]提出了Word2Vec模型,通过训练大规模语料得到低维词向量,从而表征语义信息,常用框架包括CBOW和Skip-gram。
近年来,深度学习的各类方法开始广泛应用于文本分类领域。Kim[11]首次运用卷积神经网络(Convolutional Neural Network,简称CNN)来进行特征提取及文本分类。Zhang等[12]基于字符级的卷积神经网络模型提升分类准确率。陈波[13]改进卷积神经网络实现文本分类,从而提升准确率、召回率和F值。邱尔丽等[14]通过字符级CNN技术完成公共政策网民支持的分类研究。
同时,由于循环神经网络(Recurrent Neural Network, 简称RNN)可以联系上下文突出文本序列信息,它也被应用于自然语言处理领域。为进一步解决RNN模型的梯度爆炸和梯度消失问题,门控递归单元网络(GRU)和长短时记忆网络(LSTM)被提出并应用于文本分类任务。Lai等[15]通过RCNN模型提取文本特征及实现文本分类。李云红等[16]提出了一种基于循环神经网络变体和卷积神经网络的文本分类方法。梁志剑等[17]提出一种基于BiGRU和贝叶斯分类器的文本分类方法,有效提高了文本分类的效率和准确率。郑国伟等[18]通过LSTM模型对金融领域的新闻数据进行分类。Zhou等[19]在BiLSTM模型中融合二维池化操作,实现文本特征提取和文本分类。为了更好地提取重点关注的文本数据,注意力(Attention)机制被引入深度神经网络及自然语言处理任务中。Wang等[20]结合LSTM模型和注意力机制实现情感分类研究。陶志勇等[1]提出了基于双向长短时记忆网络的改进注意力短文本分类方法。张宇艺等[21]通过改进CBOW模型,并结合ABiGRU方法实现文本分类。张彦楠等[22]融合CNN、双向GRU及注意力机制,完成录音文本分类任务。姚苗等[23]提出自注意力机制的Att-BLSTMs模型并应用于短文本分类研究,有效地提高了短文本分类的准确率。
综上所述,BiLSTM模型可以提取上下文语义知识,CNN和RNN模型可以捕获具有代表性的局部文本特征,Attention机制能够突出词语的重要性,强化网络模型的学习和泛化能力。本文在以上研究基础上提出一种融合语义知识和BiLSTM-CNN的短文本分类模型,整个模型尽可能地发挥CNN、BiLSTM和Attention的优势,提升短文本分类的准确率,多角度考虑短文本分类的互补性及协调性。
2 本文模型
本文针对短文本语义关系单薄、篇幅较短、特征稀疏等问题,提出了一种融合BiLSTM-CNN和语义知识的短文本分类模型。
2.1 算法总体框架
该模型将短文本预处理成Word2Vec词向量,再通过卷积神经网络的卷积层和池化层把文本词向量表征成句子词向量,结合BiLSTM神经网络和Attention机制构建文本向量,最终得出分类结果。本文方法的总体框架如图1所示。具体步骤如下。
⑴ 首先通过Python和XPath构建自定义爬虫抓取新闻标题数据,包括体育、财经、教育、文化和游戏五大主题;接着进行数据预处理操作,计算输入层的词向量。
⑵ 输入层中嵌入的词向量会将文本中的每一个词汇表征为相应的词向量空间,接着输入卷积神经网络,卷积层由多个滤波器组成,池化层提取出具有代表性的局部特征。
⑶ 双向长短时记忆网络层(BiLSTM)旨在提取上下文语义特征,BiLSTM能够更好地捕捉到双向语义依赖,从而进行细粒度的分类。
⑷ 当BiLSTM层完成上下文语义特征提取后,其输出会通过Attention机制进一步突出所提取的关键性词语,并赋予相关权重。
⑸ 最后,经过BiLSTM-CNN和Attention神经网络得到的特征向量,会由Softmax分类器计算短文本的分类结果,完成分类任务。
2.2 数据预处理
在进行短文本分类任务前,需要对语料进行数据预处理操作,主要包括以下内容。
⑴ 分词。本文抓取了搜索引擎的新闻标题数据作为实验语料,中文分詞采用Jieba工具完成,并导入自定义词典进行专有名词识别。
⑵ 停用词过滤。通过Python导入哈尔滨工业大学停用词表、百度停用词表和四川大学停用词表进行数据清洗,过滤掉如“我们”“的”“这”等停用词以及标点符号。
⑶ 异常值处理。在中文文本中,还会存在一些异常的词汇,此时需要进行适当的转换及人工标注,从而为后续的文本分类提供辅助。
经过上述处理,将得到更高质量的短文本数据集,从而提升分类效果。最后将清洗后的数据及类标存储至数据库中,进行后续的短文本分类实验。
2.3 Word2Vec词向量
词向量是自然语言处理领域中的基础知识,在文本挖掘、语义分析、情感分析等方面具有一定的价值。Word2Vec是2013年Google开源的一款基于词向量的计算工具,旨在根据上下文信息表征特征词,通过向量空间的相似度来表示语义相似度,从而挖掘出词语之间的内在语义知识和关联信息。
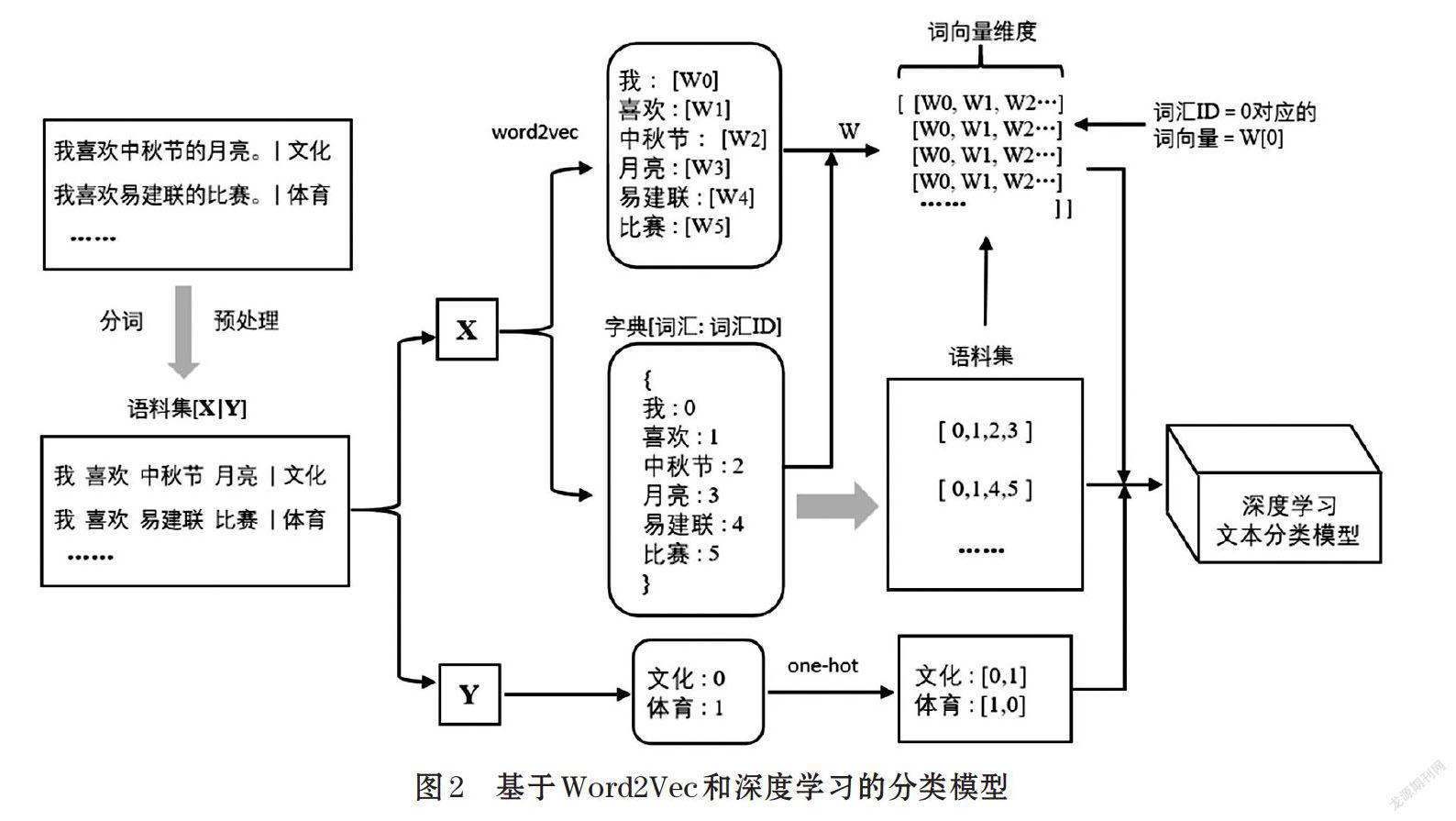
Word2Vec包括CBOW模型和Skip-gram模型。其中,CBOW模型是通过上下文来预测当前词的概率,已知上下文w(t-1)、w(t-2)、w(t+1)、w(t+2),对当前词w(t)的概率进行预测;Skip-gram模型则是利用当前词的词向量来预测上下文。图2为基于Word2Vec和深度学习的文本分类模型,它将句子转换为词向量并结合上下文语义知识完成分类任务,识别出文化(类标0)和体育(类标1)两个类别。
2.4 卷积神经网络模型
卷积神经网络(Convolutional Neural Network, 简称CNN)通过提取局部特征进行文本分类,利用卷积核滑动搜集句子信息来提取特征,从而提高特征利用率。典型的CNN模型包括输入层、卷积层、池化层和全连接层。
卷积层旨在提取输入语料的数据特征,采用不同尺寸的卷积核进行卷积运算,其计算如公式(1)所示,最终得到新的特征hdi。
其中,f表示ReLU激活函数,wd表示大小为d的卷积核,Vi表示输入层的词向量,bd表示偏置项。通过设置d个不同大小的卷积核对Vi进行特征提取,滑动滤波器映射得到最终的局部特征集合Hd:
池化层旨在降低数据维度,缩减文本特征向量和网络参数的大小,同时能保持文本特征统计属性并增大模型的适应性。本文对卷积操作得到的局部特征Hd进行池化操作,采用最大池化方法来提取特征,其计算公式如下:
经过池化层提取出文本的局部重要特征,接着将所有池化层得到的特征在全连接层进行组合,得到输出向量S。最后将全连接层输出向量S输入Softmax分类器中进行短文本分类,从而预测最终类别。
2.5 BiLSTM模型和Attention
双向长短时记忆网络模型(Bi-directional Long Short-Term Memory, 简称BiLSTM)可以从两个方向对句子进行编码,提取上下文语义特征,更好地捕捉到双向语义依赖,从而进行细粒度的分类。
针对在短文本分类任务中,不同词语对整个文本语义的贡献不同,本文利用Attention机制为BiLSTM-CNN模型的输出赋予不同的权重,从而将单词级别的特征融合成句子级别的特征,提高关键词信息对分类结果的影响。最后,经过Attention机制得到了向量将输入到softmax分类器中,从而实现短文本分类任务。
3 实验
提出一种融合语义知识的短文本分类方法,为验证其有效性和实用性,采用TensorFlow深度学习框架构建神经网络模型进行对比实验。
3.1 实验数据和预处理
实验通过Python自定义爬虫采集50000条新闻标题数据,涉及体育、财经、教育、文化和游戏共五个主题,并将数据集按照6:2:2的比例随机划分成训练集、验证集和测试集,具体数据分布情况如表1所示。数据预处理采用Jieba工具实现,包括对文本语料的中文分词、停用词过滤、去除低频特征词等,从而提高文本分类的准确率。
3.2 评估指标
文本分类任务通常会采用准确率(Precision)、召回率(Recall)和F值(F-measure)评价指标。其计算公式如下:
其中,TP表示短文本分类正确的数量,Sum表示实际分类的文本数量,TS表示属于该类别的文本数量。准确率旨在评估被分类模型正确划分到某个类别中的比例,召回率旨在评估属于某个类别的查全率,F值是准确率和召回率的加权调和平均值,常用于评价分类模型的最终好坏。
3.3 实验结果与分析
为了保证实验结果更加真实有效,本研究进行了多次交叉验证,最终的实验结果为10次短文本分类实验结果的平均值。同时,该模型的文本序列长度设置为600,CNN模型的卷积核数量设置为128,卷积核尺寸设置为3,学习率为0.001,BiLSTM模型的正反向神经元数均设置为300,词向量维度为300,优化算法选择Adam优化器,并且增加Dropout层防止出现过拟合现象。
采用融合语义知识和BiLSTM-CNN方法对所抓取的新闻标题语料进行短文本分类,得到的实验结果如表2所示。其中,短文本分类准确率最高的是体育类别,值为0.9253;准确率最低的是游戏类别,值为0.8745。短文本分类召回率最高的是游戏类别,值为0.9125;召回率最低的是财经类别,值为0.8845;短文本分类F值最高的是体育类别,值为0.9178;F值最低的是财经类别,值为0.8874。
为进一步对比短文本分类的实验结果,本文详细对比了多种分类算法,其实验结果如表3所示。由表可知,本文所提出方法在该数据集的短文本分类比较中,平均准确率、平均召回率和平均F值都有一定程度的提升。
本文方法的平均准确率为0.9010,平均召回率为0.9006,平均F值为0.9008。相比于传统的机器学习分类方法有较大提升,其平均F值比决策树(DT)方法提升了0.0898,比最近邻(KNN)方法提升了0.1145,比支持向量机(SVM)方法提升了0.855。
本文方法与经典的深度神经网络相比,F值也有一定程度提升,F值分别比CNN、GRU、LSTM和BiLSTM高出0.0585、0.0675、0.0560和0.0445。随着文本分类模型进一步演化,TextCNN和Attention机制融合模型逐渐被提出,本文方法依舊显示优于这些方法,其F值比TextCNN模型提升0.0194,比Attention+CNN模型提升0.0124,比Attention+BiLSTM模型提升0.0091。总体而言,本文提出的方法在该新闻标题中文数据集的短文本分类效果更好。
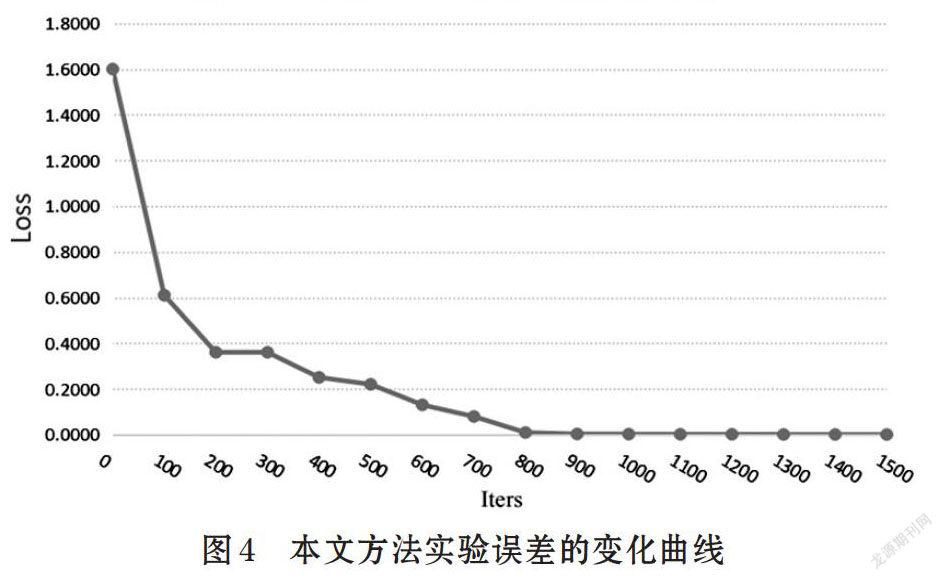
同时,该模型的正确率(Accuracy)和误差变化曲线如图4和图5所示。随着迭代次数增加,其正确率逐渐升高,而误差逐渐降低,并且每隔100次迭代输出一次结果。最终趋于平缓,BiLSTM-CNN和Attention模型正确率稳定在0.9078,误差稳定在0.001。
4 结束语
针对短文本语义关系单薄、篇幅较短、特征稀疏问题,本文提出了一种融合BiLSTM-CNN和语义知识的短文本分类模型。通过CNN模型提取短文本的局部特征,利用BiLSTM提取上下文语义依赖,考虑文本中每个词语前后的语义关系影响,并经过Attention机制进一步突出所提取的关键性词语,赋予相关权重,从而提升短文本的准确率。实验结果表明,本文提出的方法优于传统的机器学习分类方法和经典的深度学习分类方法,最终的平均准确率为0.9010,平均召回率为0.9006,平均F值为0.9008。相较于其他方法,这三个评价指标均有所提升。本文的方法可以应用于短文本分类、推荐系统、数据挖掘、自然语言处理等领域,具有较好的准确率和实用性。未来,将一方面进一步扩大实验数据集,研究该算法的普适性;另一方面将结合深度语义知识,进一步提升模型对文本分类准确率的影响。
参考文献(References):
[1] 陶志勇,李小兵,刘影等.基于双向长短时记忆网络的改进注意力短文本分类方法[J].数据分析与知识发现,2019.12:21-29
[2] 郭诗瑶.融合上下文信息的文本分类算法的研究及应用[D].北京邮电大学,2019:27
[3] 杨秀璋,夏换,于小民等.基于多视图融合的论文自动分类方法研究[J].现代电子技术,2020.43(8):120-124
[4] Joachims T. Text categorization with support vector machines: learning with many relevant features[J]. Proc of the 10th European Conf on Machine Learning (ECML-98).Chemnitz: Springer-Verlag,1998:137-142
[5] 周慶平,谭长庚,王宏君等.基于聚类改进的KNN文本分类算法[J].计算机应用研究,2016.33(11):3374-3377
[6] 何伟.基于朴素贝叶斯的文本分类算法研究[D].南京邮电大学,2019:22
[7] BidiN,Elberrichi Z. Feature selection for text classification using genetic algorithm[C]//International Conference on Modelling,Identification and Control. IEEE,2017:806-810
[8] 杨晓花,高海云.基于改进贝叶斯的书目自动分类算法[J].计算机科学,2018.45(8):203-207
[9] 熊漩,严佩敏.融合多头自注意力机制的中文分类方法[J].电子测量技术,2020.43(10):125-130
[10] MikolovT,ChenKai,CorradoG,et al. Efficient estimation of word representations in vector space[J].arXiv:1301.3781,2013.
[11] Kim Y. Convolutional neural networks for sentence classification[J].Association for the Computation Linguistics,2014.15(6):1746-1751
[12] Zhang X, Zhao J, Lecun Y. Character-level convolutional networks for text classification[C] //International Conferenceon Neural Information Processing Systems.MIT Press,2015:649-657
[13] 陈波.基于循环结构的卷积神经网络文本分类方法[J].重庆邮电大学学报(自然科学版),2018.30(5): 705-710
[14] 邱尔丽,何鸿魏,易成岐等.基于字符级CNN技术的公共政策网民支持度研究[J].数据分析与知识发现,2020.4(7):28-37
[15] Lai S, Xu L, Liu K, et al. Recurrent convolutional neural networks for text classification[C] //Proc of the 29th AAAI Conference on Artificial Intelligence,2015:2267-2273
[16] 李云红,梁思程,任劼等.基于循环神经网络变体和卷积神经网络的文本分类方法[J].西北大学学报(自然科学版),2019.49(4):573-579
[17] 梁志剑,谢红宇,安卫钢.基于BiGRU和贝叶斯分类器的文本分类[J].计算机工程与设计,2020.41(2): 381-385
[18] 郑国伟,吕学强,夏红科等.基于LSTM的金融新闻倾向性[J].计算机工程与设计,2018.39(11):3462-3467
[19] Zhou P, Qi Z, Zheng S, et al. Text Classification Improved by Integrating Bidirectional LSTM with Two-dimensional Max Pooling[OL]. arXiv Preprint, arXiv: 1611.06639
[20] Wang Y, Huang M, Zhao L, et al. Attention-based LSTM for Aspect-level Sentiment Classification[C] //Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics,2016:606-615
[21] 张宇艺,左亚尧,陈小帮.基于改进的CBOW与ABiGRU的文本分类研究[J].计算机工程与应用,2019,55(24):135-140
[22] 张彦楠,黄小红,马严等.基于深度学习的录音文本分类方法[J].浙江大学学报 (工学版),2020.54(7):1-8
[23] 姚苗,杨文忠,袁婷婷等.自注意力机制的短文本分类算法[J].计算机工程与设计,2020.41(6):1592-1598
