轮廓检测深度学习模型中解码网络融合方法
2021-11-20文泽奇,林川,乔亚坤
文泽奇,林川,乔亚坤
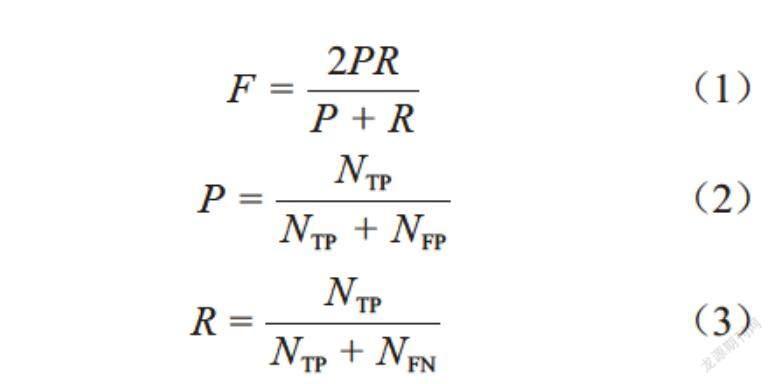
摘 要: 轮廓检测旨在提取目标边界,是高级计算机视觉任务中获取图像基础信息的重要步骤.基于轮廓检测的卷积神经网络(convolutional neural networks,CNNs)模型分为编码网络和解码网络两个部分,关注点集中在采用不同的卷积方式进行解码或是采用逐级融合进行解码,忽略了对编码网络每一层信息的充分利用.针对这一问题,本文提出一种自底向上强化融合的轮廓检测模型:充分利用编码网络中的每一层信息,由低分辨率特征图至高分辨率特征图自底向上逐层融合;以不同空洞率的卷积搭建强化模块,进一步增强对特征信息的提取.从结果上看,本文所提模型既节省了计算机内部存储空间,同时在目前主流的数据集BSDS500上也取得优异成绩 (F-score = 0.819).
关键词:轮廓检测;卷积神经网络;自底向上融合;空洞卷积
中图分类号:TP391.41 DOI:10.16375/j.cnki.cn45-1395/t.2021.04.007
0 引言
轮廓检测的目的是为给定图像的每一个像素分配一个标记,即轮廓或非轮廓像素,它被认为是计算机视觉中的基本任务,并且在诸如语义分割[1-2]、目标识别[3-4]等其他更高级别的任务中起重要作用.轮廓检测一直是一项极其困难的计算机视觉任务,对于复杂场景下的目标图像,尤其是纹理繁杂、对比度低以及含有大量噪声干扰的图像,很难获取理想效果,因此,如何合理设计轮廓检测模型以提取准确的轮廓信息仍然是计算机视觉及图像处理领域热门的研究方向.
早期轮廓检测方法通过求像素值的局部梯度变化来确定边缘位置,如Sobel[5]、LOG算子[6]等,这些检测方法计算速度快,但轮廓信息中包含大量无关内容.Canny[7]在此基础上添加高斯滤波作为预处理,消除噪声影响,并通过双阈值判定候选轮廓像素点,以形成闭合完成轮廓,在性能方面有显著的提升.目前,研究者们主要从两方面进行目标轮廓提取的研究,一种是非学习的方法,主要是利用生物视觉系统对繁杂场景快速锁定目标轮廓的特点,模拟生物视觉组织的特性进行轮廓检测.如Grigorescu等[8]提出的以12个方向的Gabor能量函數模拟初级视皮层的经典感受野模型;桑农等[9]提出的蝶形非经典感受野模型;赵浩钧等[10]根据初级视皮层V1区细胞对颜色、亮度等信息具有拮抗机制及方位敏感性的特性提出的基于颜色拮抗机制的轮廓检测模型等.另外一种是机器学习方法,是把轮廓检测任务看作一个像素级的二分类任务,利用图像的局部或全局特征对每一个像素点进行分类,如Martin等[11]提出的Pb算法,利用图像局部区域的亮度、颜色及纹理特征进行像素分类;Arbeláez等[12]提出gPb算法,即在Pb算法的基础上,通过图像全局的特征信息对像素点进行二分类;Dollár等[13]提出的Boosted边缘检测算法,通过构建一个概率式的树分类器来进行像素点分类.
研究发现,卷积神经网络(convolutional neural networks,CNNs)在轮廓检测任务上表现出更加优异的性能.CNNs模型分为编码、解码两个部分,编码通常采用公开学习框架进行迁移学习,解码则采用不同的融合方式,以提取更多的特征信息[14].Xie等[15]使用论坛开源学习框架VGG-Net[16]进行迁移学习,解码网络采用多通道拼接的方式将主网络不同尺度的轮廓信息进行结合,得到最终的轮廓.Liu等[17]在HED的基础上,将编码网络中所有卷积层的信息按不同阶段进行对应通道相加,舍弃第4个下采样层,采用空洞卷积替代采样层作用;他们首次在深度学习轮廓检测模型中提出多尺度概念,提出的RCF模型在性能上有了很大的提升.Wang等[18]提出的CED模型则是利用亚像素卷积代替双线性邻近插值,并且改变解码网络融合方式,采用逐级融合的方式替代传统的拼接方法,CED对脆弱轮廓边缘的检测有着较好的效果.Lin等[19]认为拓宽CNNs解码网络可以提取更丰富的特征,以获取更多纹理繁杂处的轮廓信息,因此,他们提取LRC模型,通过邻近卷积层相连接的方式逐级提取特征信息,以获得更好的性能.
本文受CED模型启发,提出自底向上融合的解码网络BTU-Net.与CED不同,BTU网络采用双线性邻近插值进行上采样,并结合编码网络全部卷积层特征,构建双级网络进行融合,有效地利用了编码网络中的每一层信息.此外,本文提出基于空洞卷积设计的强化融合模块,在融合过程中有效地保护了细腻的特征信息,从而不被上采样操作破坏.
1 模型设计
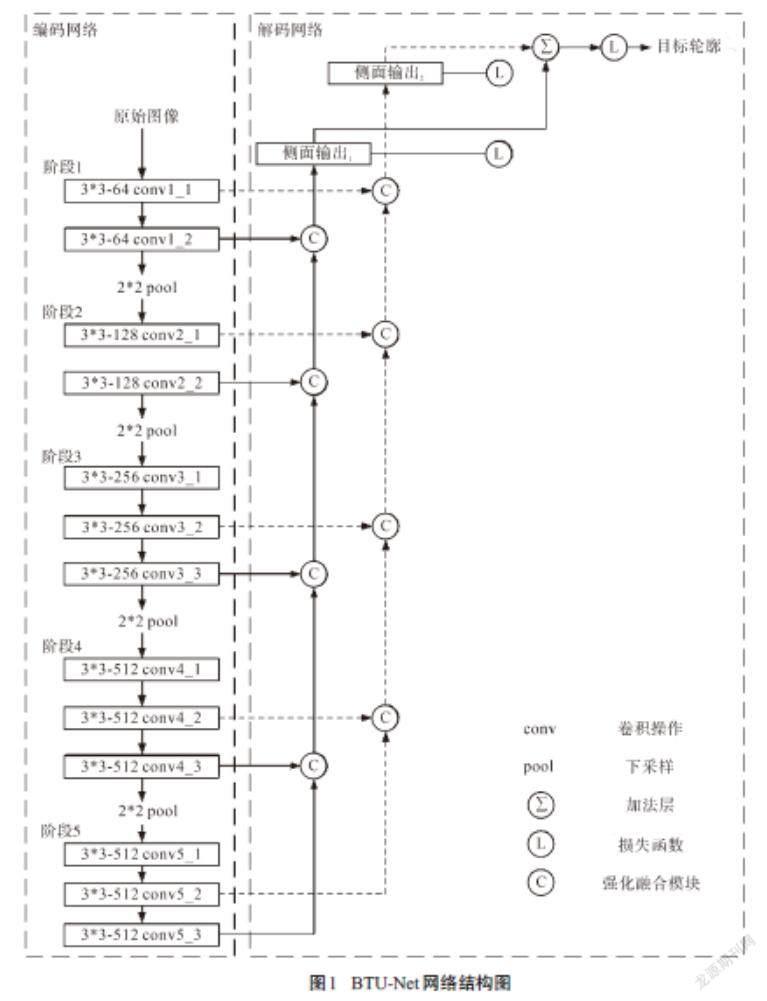
本文基于VGG-Net设计了一种自底向上强化融合轮廓检测模型,其中VGG16网络在对象识别任务中有着出色的表现,结合网络参数进行迁移学习时,在不同的计算机视觉任务中都取得了优异的成绩.VGG16共有13个卷积层和3个全连接层,其中16层网络中间包含5个下采样层,根据下采样层的位置,将VGG16网络分为5个阶段.轮廓检测是一个二分类任务,不需要全连接层进行多分类,因此,本文删除了3个全连接层和最后1个下采样层.如图1所示,VGG16共分为5个阶段,从每个阶段中抽取2个卷积层的结果,然后分为2组,依次对这2组结果进行自底向上的特征融合.此外,考虑到高分辨率图像转换为低分辨率图像造成的特征信息冗余问题,使用空洞卷积构建强化融合模块,通过将卷积核的空洞率设置为1、2、4,依次对高分辨率特征图与低分辨率特征图融合之后的结果进行卷积,并通过自适应学习的方式将3种不同空洞率卷积之后的结果按照不同的权重进行累加,以通过梯度下降算法获取更多的轮廓特征,抑制更多的纹理细节.
1.1 自底向上融合
图像中,目标轮廓所处位置不同,检测的难易程度也不一样,对于背景与轮廓特征信息相近的区域,轮廓不易被表现出来,此时需要结合全局信息来判断该位置是否具有轮廓,然后利用周围特征信息对不易检测的像素点进行信息补充.卷积神经网络通过采样层,将特征图分辨率降低.低分辨率特征图具有较强的全局特征信息,采用自底向上的融合方式,利用全局特征信息对高分辨率特征图中的局部信息进行调制,可以有效地抑制轮廓处的背景纹理,并补充被纹理覆盖的轮廓断点.
VNF-Net编码网络将图像原始分辨率依次缩小5个等级,在解码网络中,不同分辨率特征图逐步向上进行融合,通过上采样的方式将低分辨率特征图放大,以匹配高分辨率特征图.与CED模型[18]不同,本文采用双线性邻近插值方法进行上采样.对于分类任务而言,亚像素卷积和双线性邻近插值上采样方法对最终结果的影响并不明显,并且双线性邻近插值上采样更加节省内存和运算时间.基于性能和效率的权衡,最终采用双线性邻近插值作为上采样方法.
VGG16网络的13个卷积层分为5个阶段,根据Res-Net模型[20]中提到的,不同分辨率下的特征图所含信息不同,同一分辨率中相邻卷积层功能也不一样,进而提取的内容也不同.因此,从编码网络每个阶段选择2个卷积层的结果,这样共有10个输出,然后将10个输出按分辨率不同进行分组,如图1所示,conv1_1、conv2_1、conv3_1、conv4_1和conv5_1作为一组,conv1_2、conv2_2、conv3_3、conv4_3和conv5_3作为一组,共2组.对2组卷积层结果同时进行自底向上融合,得到2个和原始图像分辨率一样的侧输出;对这2个侧输出分别求损失函数并进行反向传播算法;最后将2个侧边输出进行融合作为BTU-Net轮廓预测图.
1.2 强化融合模块
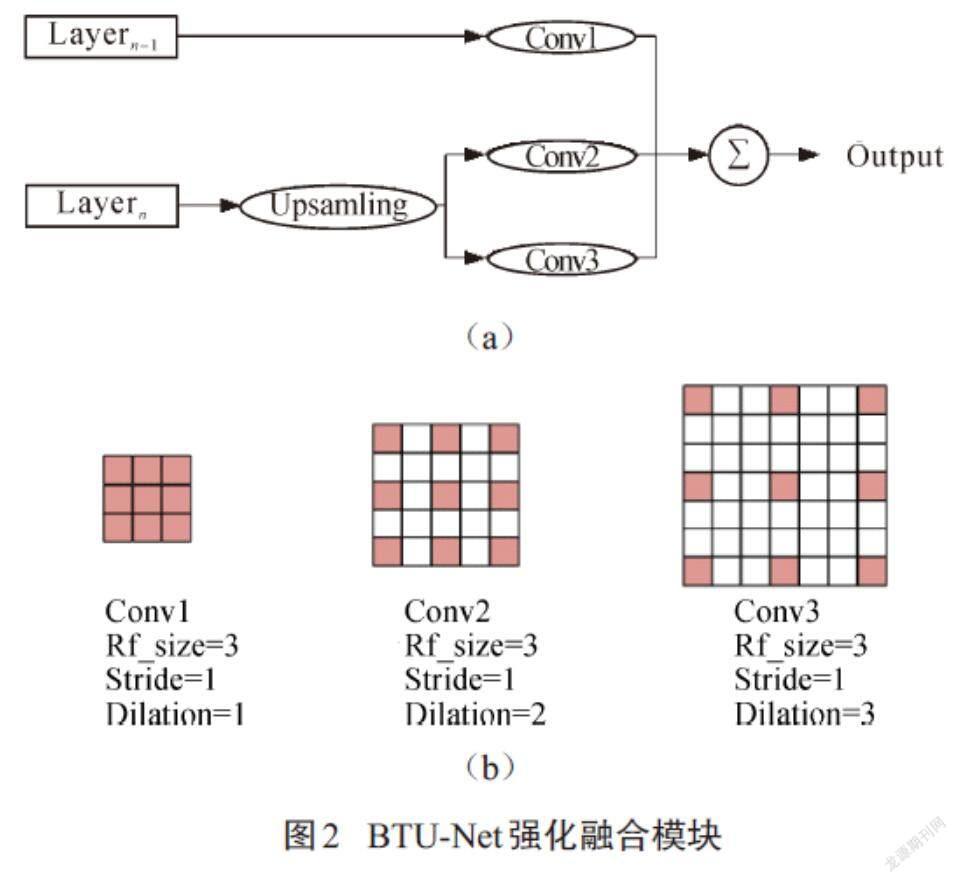
强化融合模块如图2(a)所示,下层卷积结果首先通过上采样与上层卷积结果进行尺度匹配,然后分别使用空洞率为2和3的卷积核进行卷积.上层卷积结果则使用空洞率为1的通用卷积核进行维度匹配,使之与下层卷积结果的特征通道数相同,然后共同传入加法层进行处理.如图2(b)所示,空洞卷积在标准卷积的基础上,根据不同的空洞率对卷积核注入空洞,以此来增加感受野.在图像上中心像素点的值与周围近距离像素点的值相差无异,影响它的是周围较远处的像素值.另外,空洞卷积在不增加模型数据的前提下,有效地拓宽了卷积核的感受野,使中心像素点与周围像素点更好地进行相互作用.利用这一规律,本文采用双空洞卷积层构建强化融合模块,通过分析中心像素点与周围像素点之间的关系,判断待处理像素点属于哪一类别(轮廓或背景).不同空洞率下的卷积核感受野大小不一样,对周围信息的利用率也不一样,较小的空洞率可以有效保护信息的完整性,而较大的空洞率则更有利于周围像素点对中心像素點产生更好的相互影响(促进或抑制).
1.3 多尺度策略
在VNF-Net中,样本训练采用单尺度图像进行,样本测试则采用单尺度和多尺度结合的方式进行,以进一步提高边缘检测的准确率.具体来说,调整图像大小以构建图像金字塔,并将同一图像的不同尺度输入单尺度检测器中,然后利用双线性邻近插值将所有尺度得到的轮廓预测图调整为原始图像尺寸.最后,将这些图进行平均得到最终的预测结果.对不同尺度的图像进行加权求平均,但是效果均不佳.考虑性能和效率之间的权衡,本文使用0.5、1.0、2.0 这3个尺度.通过BSDS和PASCAL数据集的测试,BTU-Net在多尺度策略下F值(ODS)从0.810提升到了0.819.
2 实验结果与分析
2.1 实施细节
采用论坛公开VGG16网络的预训练模型进行迁移学习,其他层使用均值0和方差0.02的高斯随机分布进行初始化.内在超参数初始学习率、衰减权重和动量分别设置为[1×10?3]、[2×10?4]和0.90.对于自底向上的卷积层内核参数设置为512,之后逐层依次减半,直至顶层64.
BTU-Net模型在3个国际通用数据集上分别进行了2组实验:首先联合使用BSDS500数据集和PASCAL数据集作为训练集,以BSDS500中的200幅图像作为测试集进行实验;其次,单独对室内复杂场景数据集NYUD-v2进行训练,并以其数据集中的654幅图像进行测试.基于通用F-measure性能评测体系对BTU-Net模型的性能进行定性与定量分析(设置容差参数Distmax=0.007 5),F-measure具体计算如下:
[F=2PRP+R] (1)
[P=NTPNTP+NFP] (2)
[R=NTPNTP+NFN] (3)
其中:[P]表示精确率(Precision),[R]代表召回率(Recall),[F]则是[P]与[R]二者的调和平均,[NTP]表示图像中属于轮廓像素点被正确检测出的个数,[NFP]表示误将背景像素点检测为轮廓像素点的个数,[NFN]表示属于轮廓像素点但漏检的个数.通常,以 3个标准来判断轮廓检测模型的性能指标:ODS(整个数据集取最优阈值)、OIS(每幅图像取最优阈值)和AP(平均精确率),三者统称为F-measure.
2.2 实验结果
BSDS500是轮廓检测中广泛使用的数据集,由200个训练图像、200个测试图像和100个验证图像组成,其利用训练和验证集进行微调,并利用测试集进行评估.本文将BSDS500增强后的数据集与PASCAL(VOC)数据集混合训练.评估时,利用标准非极大值抑制(NMS)进行轮廓细化,并且将BTU-Net与Canny算法及先进的深度学习算法进行比较.表1是最近比较热门的深度学习轮廓检测模型及本文模型(BTU)的各项得分,其中本文模型检测结果相较最新方法(LRC-Net(2020年)结构)在多尺度和单尺度图像测试下,ODS值分别提高0.99%和0.37%.另外,CED模型与本文模型相比,尽管同样使用了自底向上方法融合,但本文模型性能更佳.由此说明,本文设计的强化融合模块在上采样过程有效地保护了图像的细节.
为了进行定性实验,本文从BSDS500測试集中随机选取了4幅检测效果图进行对比,如图3所示,其中第1行为自然图像,第2行为真实轮廓图(Ground Truth),第3行至第6行分别为HED、CED、LRC及本文模型(BTU),在每幅图像的右下角标注了得分情况(F-score).从图3中可以看出,与其他算法相比,本文模型(BTU)有效地保护了纹理繁杂处的细节信息,突出了重要的特征信息,对轮廓部分保护完整,极少出现轮廓断裂现象.
NYUD-v2数据集由1 449个密集标记的成对RGB图像和对应的深度图组成,共分为381个训练图像和414个验证图像以及654个测试图像.数据集的深度信息用HHA表示,HHA被编码为3个通道:水平视差、据地高度及重力角,类似地将HHA功能视为彩色图像.与BSDS500数据集不同,NYUD-v2中RGB图像和HHA特征图像分别进行训练,每组训练40次,8次循环作为一个周期,学习率以[10%]速度下降,测试时,将RGB模型和HHA模型的输出进行平均并定义为最终边缘预测.在评估过程中,将定位公差[Distmax]从0.007 5增加到0.011 0,其余参数同BSDS数据集一致,结果如 表2所示.BTU网络秉承了在BSDS500数据集上的特性,对室内场景的轮廓提取也有较好的效果,相比于最新方法LRC(2020年)有所提升.
BTU在NYUD-v2数据集评测图像如图4所示,第1行是原图像,第2行是原图像的深度信息, 第3行是真实轮廓图,第4、5行分别是BTU网络在NYUD-v2数据集中的单尺度和多尺度检测结果.NYUD-v2数据集图像内容复杂,且数据集容量较少,因此,很难达到其他数据集一样的性能.与最近几年的轮廓检测深度学习模型对比,BTU模型在NYUD-v2数据集中多尺度F值(ODS=0.764)要优于其他模型,其检测性能有着不错的提升.
3 结论
针对轮廓检测深度学习模型,本文设计的自底向上强化融合网络具有良好的性能,可以应对复杂的轮廓检测任务,更高效地为高级视觉任务服务.文中提出的BTU模型主要有以下2个优点:1)通过不同空洞率的强化融合模块,对纹理繁杂处的轮廓信息具有优异的检测效果;2)利用双级自底向上的解码方式,有效利用编码网络中更多的特征信 息,对轮廓的保护更加有效,减少了轮廓断点现象.与近几年的优秀算法比较,BTU模型在 BSDS500&PASCAL数据集上取得了ODS=0.819的好成绩,通过与CED模型对比,更能体现出BTU-Net模型中强化融合模块的效果.一直以来,研究者们主要关注不同的融合方式所得到的结果,却忽略了对编码网络中特征信息的保护以及不断的上采样或倍数过大的上采样导致的纹理信息丢失等问题.BTU模型以此为出发点,针对这2个问题进行了分析和解决,并取得一定的效果.本文也仅是利用了编码网络中更多卷积层的特征,而VGG16学习框架具有13个卷积层和2万多个卷积核,对应2万多个特征图,如何尽可能挖掘每一幅特征图的信息并采用有效的方法进行融合,抑制背景纹理,保护轮廓信息是未来的研究方向.
参考文献
[1] 刘丹,刘学军,王美珍.一种多尺度CNN的图像语义分割算法[J].遥感信息,2017,32(1):57-64.
[2] LONG J,SHELHAMER E,DARRELL T.Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR). 2015:3431-3440.
[3] FELZENSZWALB P F,GIRSHICK R B,MCALLESTER D,et al. Object detection with discriminatively trained part-based models[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32(9): 1627-1645.
[4] 刘亚,艾海舟,徐光佑. 一种基于背景模型的运动目标检测与跟踪算法[J].信息与控制,2002(4):315-319.
[5] DUDA R O,HART P E.Pattern classification and scene analysis[M].New York:John Wiley & Sons,1973.
[6] MARR D C,HILDRETH E C.Theory of edge detection[J].Proceedings of the Royal Society of London.Series B,Biological Sciences,1980,207(1167):187-217.
[7] CANNY J. A computational approach to edge detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1986(6):679-698.
[8] GRIGORESCU C,PETKOV N,WESTENBERG M A.Contour detection based on nonclassical receptive field inhibition[J].IEEE Transactions on Image Processing:a Publication of the IEEE Signal Processing Society,2003,12(7):729-739.
[9] 桑农,唐奇伶,张天序.基于初级视皮層抑制的轮廓检测方法[J].红外与毫米波学报,2007,26(1):47-51.
[10] 赵浩钧,林川,陈海杰,等.基于颜色拮抗和纹理抑制的轮廓检测模型[J].广西科技大学学报,2018,29(4):6-12.
[11] MARTIN D R,FOWLKES C C,MALIK J.Learning to detect natural image boundaries using local brightness,color,and texture cues[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2004,26(5):530-549.
[12] ARBEL?EZ P,MAIRE M,FOWLKES C,et al. Contour detection and hierarchical image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(5):898-916.
[13] DOLL?R P,ZITNICK C L. Fast edge detection using structured forests[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(8):1558-1570.
[14] 林川,曹以隽.基于深度学习的轮廓检测算法:综述[J].广西科技大学学报,2019,30(2):1-12.
[15] XIE S N,TU Z W. Holistically-nested edge detection[J].International Journal of Computer Vision,2017,125(1-3):3-18.
[16] SIMONYAN K,ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]// International Conference on Representation Learning,2014.
[17] LIU Y,CHENG M M,HU X W,et al.Richer convolutional features for edge detection[C]//IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,USA,IEEE,2017:5872-5881.
[18] WANG Y P,ZHAO X,HUANG K Q. Deep crisp boundaries[C]//IEEE Conference on Computer Vision and Pattern Recognition.Honolulu,USA:IEEE,2017:1724-1732.DOI:10.1109/CVPR.2017.187.
[19] LIN C,CUI L H,LI F Z,et al.Lateral refinement network for contour detection[J].Neurocomputing,2020, 409:361-371.
[20] HE K M,ZHANG X Y,REN S Q,et al.Deep residual learning for image recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition.IEEE,2016:770-778.
[21] SHEN W,WANG X G,WANG Y,et al. Deepcontour:a deep convolutional feature learned by positive-sharing loss for contour detection[C]//Conference on Computer Vision and Pattern Recognition,Boston,USA.IEEE,2015:3982-3991.
[22] MANINIS K-K,PONT-TUSET J,ARBEL?EZ P,et al.Convolutional oriented boundaries[C]//European Conference on Computer Vision. Switzerland:Springer,2016:580-596.
The decoding network fusion method in deep learning of
contour detection
WEN Zeqi, LIN Chuan*, QIAO Yakun
(School of Electric, Electronic and Computer Science, Guangxi University of Science and Technology,
Liuzhou 545006, China)
Abstract: Contour detection aims to extract the boundary of the target, which is an important step in obtaining basic image information in high-level computer vision task. In recent years, with the development of deep learning technology, the application of Convolutional Neural Networks (CNNs) to contour detection tasks has become a research hotspot. The CNNs model based on contour detection is divided into two parts: the coding network and the decoding network. The former usually uses a mature deep learning framework, while the latter is a research hotspot for scholars in related fields. However, their focus is usually on adopting different convolution methods for decoding or using gradual fusion for decoding, thus ignoring the full use of the information of each layer of the coding network. Aiming
