基于YOLO的轻量化目标检测应用研究
2021-11-19包成耀丁霄霏戴立奇吴宗霖杨艳红
包成耀 丁霄霏 戴立奇 吴宗霖 杨艳红
(苏州大学应用技术学院,江苏 苏州 215300)
1 引言
目标检测算法的原理是通过算法模型将输入图像的目标物体识别并圈出其位置同时归属它所在的类别。近年来,得益于深度学习浪潮的来临,目标检测算法的发展十分迅速,从早期依靠手工特征的传统目标检测方法快速过渡到以深度学习为基础的目标检测方法。期间涌现了各种不同的目标检测技术,可将其大致分为两类:先生成预选框再分类的“two-stage”算法和直接分类给出位置信息的“one-stage”算法。two-stage算法的代表有R-CNN[1],Fast R-CNN[2],Faster R-CNN[3]网络等;one-stage算法的代表有yolo系列[4-6]和SSD[7]等。
最早推出的R-CNN由于本身技术上的局限性,有着步骤繁琐、识别效率低下等问题。随后SPP-net、Fast R-CNN和Faster R-CNN等被相继提出,SPP-net在CNN后加入了空间金字塔池化层极大提升了计算速度,Fast R-CNN则是借鉴了前者的方法在R-CNN的基础上用ROI池化层替代了空间金字塔池化层大幅提高了检测速度,Faster R-CNN针对CNN网络对信息获取的不足,提出了RPN(Region Proposal Networks)网络,抛弃传统的滑动窗口改用RPN生成,提升了检测框生成速度。
而one-stage中的代表YOLO(You Only Look Once)算法相比Faster R-CNN算法结构更加简洁,极大提升了检测速度。其实现过程如图1所示,输入一张448*448*3的图片,用一个7*7的网格将其分割并输入到卷积神经网络(CNN)中,经由中间层多次卷积与池化提取图片的抽象特征,再经过两个全连接层预测目标的位置和类别,最终输出7*7*30的结果。

图1 YOLO网络结构
随后推出的YOLO v2,v3也在此基础上不断精进,v2将v1网络中的dropout层移除,取消全连接层,同时采用锚盒(Anchor Box)机制使YOLO更加准确和快速,YOLO v3则是引入了FPN(Feature Pyramid Networks)架构实现多尺度检测,训练了新的网络结构DarkNet53进行特征提取以更好地利用GPU达到更高的检测效率。
将以上几种深度学习目标检测算法以相同数据集训练结果见表1。

表1 深度学习目标检测算法对比[4-8]
从表中数据可以看出,在VOC2007数据集上R-CNN系列和YOLO系列检测时间随着算法不断更新迭代,两者的检测精度在不断提升,所用的检测时间也在不断缩短。将RCNN系列与YOLO系列进行比较,不论是在VOC2007或COCO数据集中,YOLO的检测精度都要略高于R-CNN,而在检测所需时间上YOLO要远低于R-CNN,将Faster R-CNN与YOLO v3相比较,YOLO v3所耗时间仅前者的1/20。而到了YOLO V4,准确率更是在MSCOCO数据集上达到了43.5%的AP,速度在Tesla V100显卡上达到了65FPS,实现了速度和精度的绝佳平衡。
2 YOLO-v4 tiny原理
YOLOv3是由Joseph Redmon等在2018年4月正式提出,也是该作者隐退前最后一篇关于该算法的文章。此后,Alexey Bochkovskiy于2020年4月23日正发布了YOLOv4,凭借着对YOLO算法的不断探索研究获得了原作者的肯定。而YOLO v4表现出的强大性能也没有让人失望,相比YOLOv3它更加准确、快速,其AP和FPS分别提高了10%和12%[8]。从结构上来说,YOLOv4弃用Darknet53转为使用了CSPDarknet53,使用了SPP+PAN的组合,除此之外还运用了CutMix和Mosaic数据增强、DropBlock正则化、类标签平滑等技巧。
如图2所示,YOLOv4的网络结构主要由4部分组成,分别为输入层(Input),主干网络(BackBone),颈部(Neck)和输出层(Prediction)。
(1)输入层大小一般采用608*608*3或416*416*3的大小,这里以416举例。
(2)BackBone层选取了CSPDarknet53作为特征提取网络,相比原有的Darknet53增加了CSP(Cross-stage partial connections)模块,如图2所示,CSP模块借鉴了CSPNet的网络结构,由三个卷积层和X个Resunit模块Concat组成,在降低计算成本的同时保证了卷积神经网络的准确性。同时在CBM模块中使用Mish激活函数,有效防止了梯度消失的问题。整个BackBone有5个CSP模块,以416*416的图像为例,特征图在经过CSP和其之前的卷积后,按照416*416*3->104*104*64->52*52*128->26*26*256->13*13*512的规律变化,最终得到13*13大小的特征图。
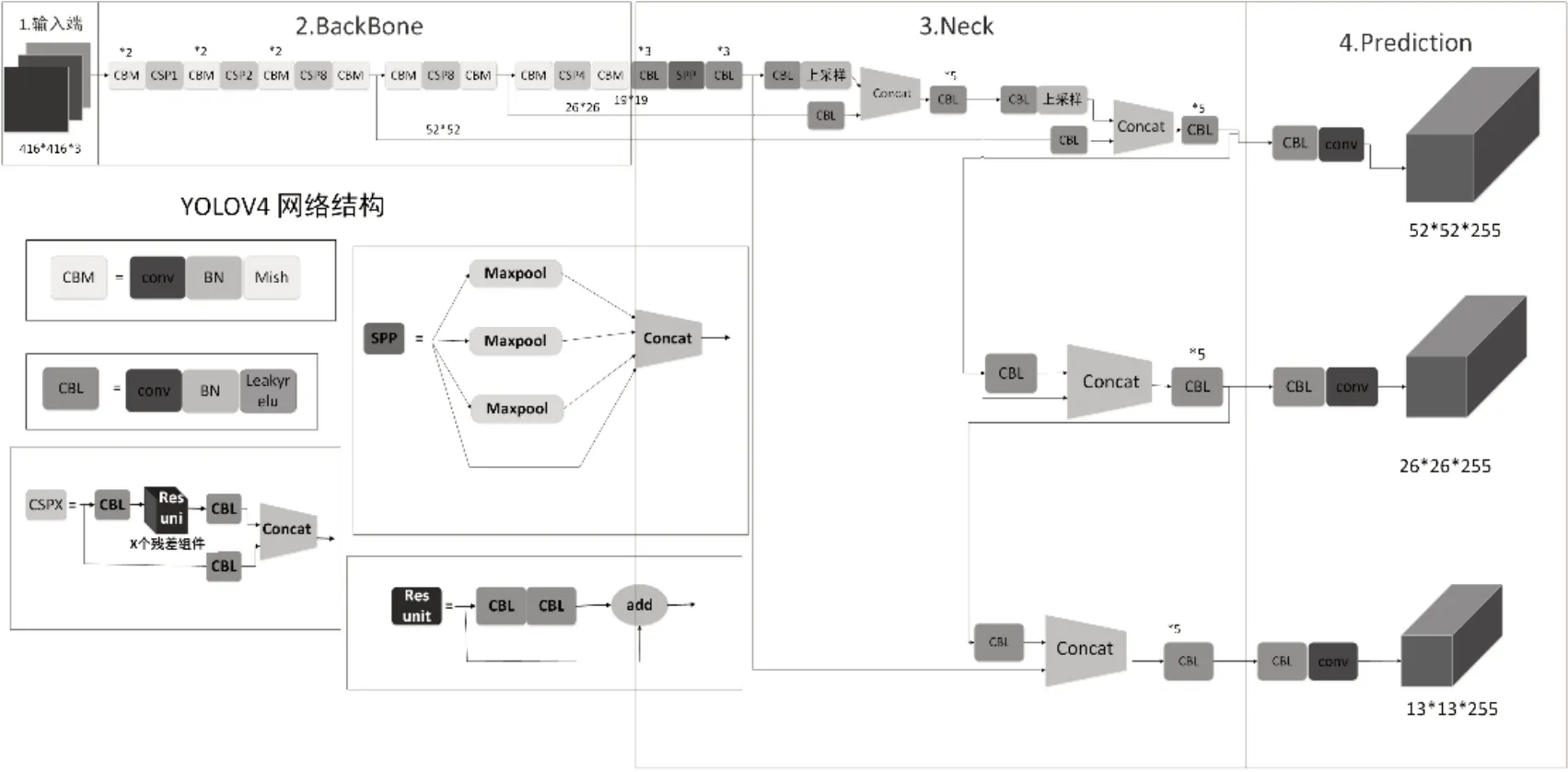
图2 YOLOv4网络结构
(3)在Neck层中,SPP模块采用了4种不同的最大池化方式将不同尺寸的特征图进行整合,相比于BackBone中使用Mish函数的CBM模块,在Neck中改为使用由Leaky relu激活函数组成的CBL模块。在经过了CSPDarknet53网络的下采样操作后得到了52*52,26*26以及13*13的特征图,以传统的FPN特征金字塔所采用自上而下的上采样方式进行的特征融合为基础结合PAN结构再形成一个自下而上的特征金字塔,使网络的特征提取能力得到加强。
(4)在Prediction层中使用了CIOU_Loss损失函数,将预测框筛选方式改为了DIOU_nms非极值抑制方法。在得到3个分支的输出结构后,经过CBL和Conv两层卷积后输出预测3个尺寸。
YOLO v4-tiny作为YOLO v4的简化版本,它在后者的基础上去掉了一部分特征层,主干特征提取网络CSPdarknet53精简为CSPdarknet53-tiny,为提升速度将CBM模块替换为CBL模块,仅保留2个分支进行分类和回归预测,在保证算法的主要框架下其结构得到了大幅精简。
3 人员检测的实现
3.1 数据集
实验所用数据集采用了网上公开的WiderPerson数据集,该数据集是较拥挤场景下的行人检测基准数据集,其选择的图像场景较为多样化,使训练出的模型拥有更广泛的适用性。从其中挑选7000张图片作为训练集,1000张为验证集对模型进行训练。由于标注文件的格式并非YOLO模型的标注格式,需要对其标注文件进行转换。使用python对数据进行处理,生成对应的YOLO标注文件。
3.2 性能指标介绍
平均准确率(AP)是一个能够反应全局性能的指标,准确率召回率曲线下的面积即为AP值。mAP值为所有不同类AP值的平均值,mAP值越大,检测效果越好。其计算公式如下:

其中Pavg为不同类AP值的平均值,Nclass为总类别数。
损失函数(loss)表示了模型的预测值与实际值之间的差距,该数据有助于反映模型的性能,从而确定模型改进的方向,让模型优化更有效率,loss值越低,误差越小,检测效果越好。其计算公式如下:

其中coordErr,iouErr,clsErr分别代表坐标误差,IOU误差与分类误差,λcoord则是坐标误差在公式中所占的权重。
每秒帧率(FPS)是评估目标检测算法的重要指标,代表每秒模型识别的图象数,反映了目标检测模型的速度,其数值越大越好。
3.3 模型训练
本次实验硬件环境为Windows 10,Intel i7-9750H 2.6GHz,GTX 1660Ti(6G显存),16G内存,软件环境为Visual Studio 2015,opencv 3.4.1,cuda 10.1,cudnn 7.6.5和darknet框架,具体模型参数如表2所示。使用YOLO v4作者Alexey Bochkovskiy在Github上提供的预训练权重文件yolov4-tiny.conv.29开始训练。网络训练过程如图3所示。损失函数(loss)随着迭代次数的不断增加而逐渐收敛,最终维持在一个较低的水平,而mAP值也随着迭代次数的增加而增加,最终达到了75.1%。
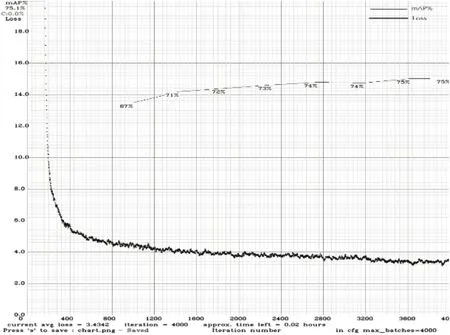
图3 YOLOv4-tiny训练过程

表2 模型配置参数
3.4 模型测试及分析
测试文件为网上下载的一段行人检测用视频,分辨率为1280*720,实验结果如图4。

图4 测试截图
从图中可以看出绝大部分行人模型都能够准确预测出,但仍有将部分商店中的假人误标的情况,出现该情况的原因可能有以下几点:(1)数据集本身存在一些错标漏标的情况,对模型的准确率也产生了一定影响;(2)图中标错的假人在数据集中也被统一标注为person,在训练过程中同样产生了影响。在测试过程中的平均FPS达到了45。
为了比较YOLO v3,YOLO v4与YOLO v4-tiny的性能差异,在尽可能相同环境下(由于实验设备性能限制,将batch值改为了16使训练能够正常进行)将三者以同样的数据集与测试视频进行测试对比,对比结果如表3所示。
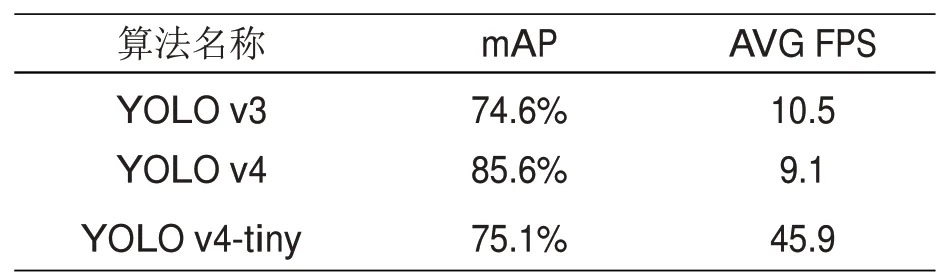
表3 YOLOv3,v4和v4-tiny性能对比
从三者的对比中可以看出,YOLO v4相比之前的版本虽然提高了精度,但仍旧难以满足目标检测的实时性和轻量化的需求。而YOLOv4-tiny在有着近似YOLOv3精度的情况下实现了YOLO v4近5倍的速度。由此可以得出YOLO v4-tiny系列虽然精度上略逊于YOLOv4算法,但该算法的低延迟性使其能够满足高实时场景下拥有足够的检测精度,而其极低的性能占用与精简的结构使其能够被应用于更广泛的场景中。
4 分析与展望
随着模型训练效率的不断提高,神经网络层级的不断加深,信息抽象能力的不断增强,未来的目标检测算法的性能将会不断提升。而随着时代的不断发展,实时检测的需求将会越来越大,同时模型小型化也将成为目标检测领域的一个重要分支,在部分场景中发挥巨大的作用,如监控、无人机、服务型机器人等,在这些设备中无法使用具备强大算力的GPU,那么能够部署于嵌入式设备如FPGA和轻量级CPU中的类似于tiny-YOLO的轻量级模型的分支也将受到更多的关注。
