适用移动设备的手势识别模型分析
2021-11-19翁耿鹏郑晓帆
翁耿鹏 郑晓帆 潘 良 饶 浩
(韶关学院信息工程学院,广东 韶关 512005)
1 引言
手势作为人与人之间日常沟通的方式之一,已逐渐成为新一代人机交互的热门研究方向,将手势识别应用于硬件设备人机交互控制中在未来将具有重大意义,例如:控制智能家居、手势控制会议投影仪、控制无人机、隔空控制手机等,能够让用户无接触地操控设备,同时也为老人、儿童等一些对数字化设备操作困难的人群提供便利。
目前对手势进行识别的方法主要分为两类:一是依靠数据手套等穿戴式设备通过对关节指尖等关键位置对手势进行采集识别[1],虽然识别精度高,但由于硬件成本高,交互不够便捷,难以在大众中推广。二是依靠计算机视觉的方法,用户仅需搭配摄像头或传感器即可进行手势识别,虽然相对于穿戴式设备而言识别精度较差,但由于用户无需穿戴特殊的设备,具有交互自然、成本低等优点。且目前随着计算机视觉的发展,基于计算机视觉识别方式的识别精度与速度都已达到可以接受的水平。其中基于计算机视觉的手势识别出现了各式各样的方法。王先军等人采用肤色模型与Hu矩描述因子结合,利用BP进行手势识别[2];程淑红等人采用基于多特征融合及生物启发式遗传算法优化多分类支持向量分类器对手势进行识别[3];徐坊等人采用基于3D卷积网络的分级网络结构识别手势[4]。
本系统为移动设备提供一种基于手势的人机交互方式,运行在移动设备的应用层上,而手势识别分为动态手势识别和静态手势识别。动态手势识别虽动作会更加自然,但使用的识别模型一般较为庞大复杂,对设备性能要求较高,难以运行在移动设备上,因此系统采用静态手势进行识别。为了使手势简单易懂,采用手指做出数字手势这种常见的可识别性高的静态手势进行识别。
2 识别模型分析与设计
系统针对用户不方便触碰移动设备屏幕的情况,例如手上有油、水等污渍或用户距离移动设备有一定的距离,用户可以通过本系统对移动设备进行操控。其中当用户在浏览网页或者看电子书是可以使用上滑和下滑功能来操纵屏幕进行浏览。当用户需要截取屏幕内容时,使用截屏功能一则可实现隔空截屏,二则可相比目前的手机需要同时按多个按键或是需要多指滑屏或是需要下拉通知栏进行截屏等的操作方式更加快捷方便。用户在有信息出现在通知栏时可使用下拉通知栏功能查看信息详情,并可使用返回功能回到原来页面,而无需触碰设备屏幕。
由于传统手势识别算法在背景相对复杂的情况下识别精度易受影响,因此在图像预处理过程中加入基于肤色检测算法的手势分割,将背景与手势分割出来,以提高后续的识别精度,降低背景对手势细节信息的影响。
2.1 肤色检测
在训练过程,为了降低背景噪音对模型训练时手势特征提取产生的影响,同时尽可能保存待识别手势的细节信息,采取先基于肤色对手势进行分割提取[5]再进行图像数据增强处理。在基于肤色对手势分割主要用到的图像处理技术为颜色空间转换、高斯滤波和对图像二值化处理的大津法等。流程如图1所示。

图1 肤色检测流程图
2.2 颜色空间转换
目前基于颜色空间的肤色检测主要是基于RGB、YCrCb等颜色空间。其中RGB颜色空间是最基本、最常用的颜色空间。摄像头采集的图片一般也是以RGB颜色空间保存的,显示器一般也是采用RGB颜色标准进行显示的。但由于RGB格式的颜色空间中R、G、B三个分量对亮度比较敏感,当对图片的亮度进行调整时,RGB颜色空间的R、G、B三个分量也会随之发生改变,不适用于图像处理。YCrCb空间由RGB空间转换而来,受亮度影响较小,是目前使用较多的一种颜色提取算法。故本实验采取将从摄像头读取的图像,从默认的RGB格式转换为YCrCb格式的肤色提取算法。
2.3 手势分割
由于从摄像头读取原始图像后,因受图片的拍摄环境或者拍摄设备自身的影响,一般收集到的图片都会或多或少存在一些图像噪音,为尽可能保证采集到完整的手势信息,提高图像二值化后手势的完整性,需要先对原始图像进行去噪处理。具体方法为在将图片从RGB颜色空间转换成YCrCb颜色空间后,将其中的Cr分量分离出来,并对其进行高斯滤波处理消除高斯噪声,之后对已消除高斯噪声的Cr分量结合OTSU算法对手势图像进行二值化处理,最后将二值化处理后的手势图像与原手势图像进行“与”运算,得到分割完整的手势图像,如图2所示。
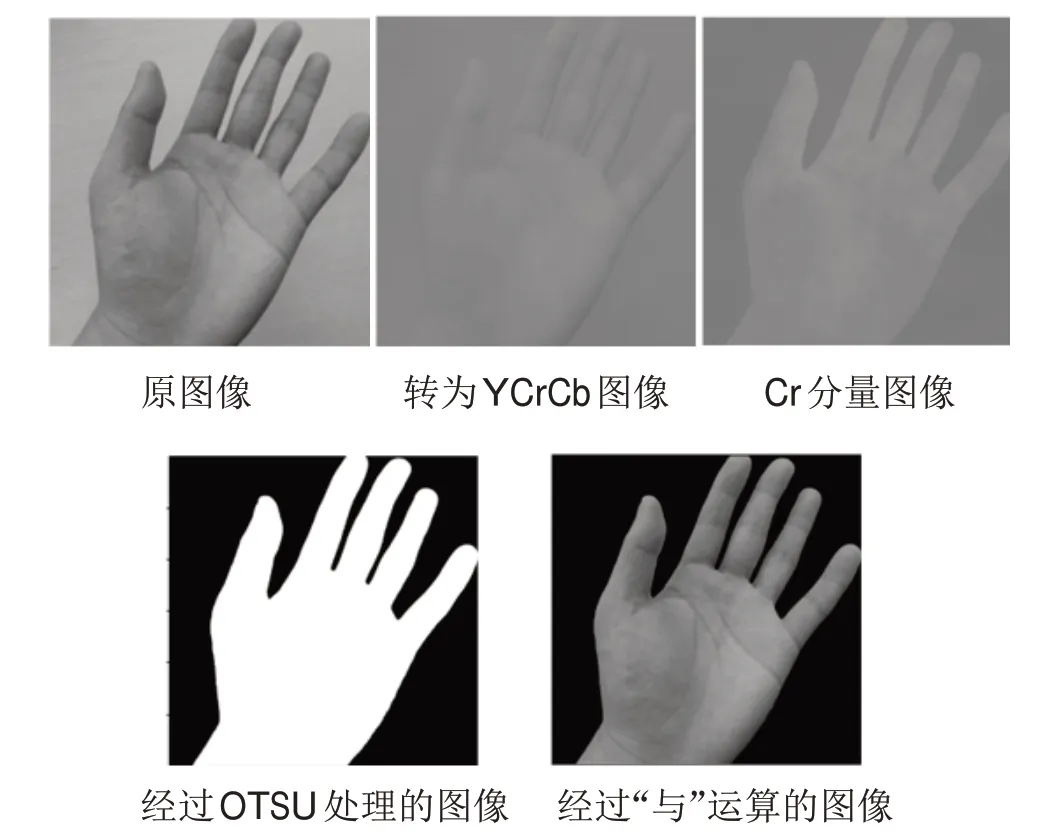
图2 图像处理步骤
2.4 数据预处理及数据增强
首先,在数据增强前先将手势数据集图片经过基于肤色的手势分割处理,分割出手势信息保留完整的图片。随后由于采集的样本有限且没法兼顾到所有的角度,为提高模型的泛化能力,增强数据集的多样性,采用了数据增强(Data Augmentation)手段对数据集扩充,主要为随机选取图片进行水平翻转或者垂直翻转后又在-45度到45度范围内随机旋转一定的角度,以模拟出不同的拍摄角度。最后由于数据集的图片尺寸并不完全相同,因此需要将图片调整成统一尺寸,同时也为了提高训练速度,在这里主要通过缩放和中心裁剪操作将图片尺寸统一为224*224。经过图像预处理和图像增强后部分图像如图3所示。
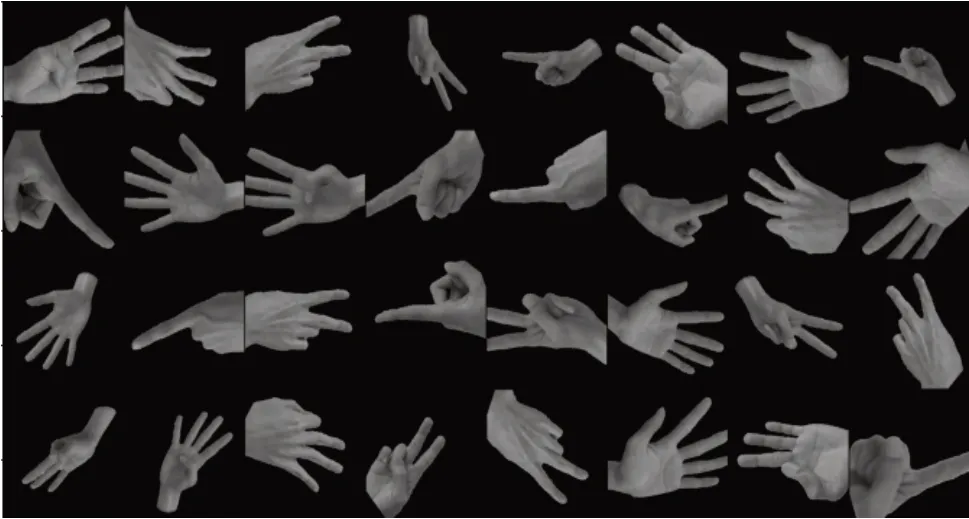
图3 数据增强后的部分手势数据集
3 实验分析
本文的手势识别模型在编写代码时所使用的硬件环境为:Inteli5-9300H2.4GHz4核CPU、16GBDDR4内存(RAM)、NVIDIAGTX10503G显卡;软件开发平台为:python3.8、Pytorch1.7.1;使用JupyterNotebook6.1.6编写手势识别模型的代码,使用GoogleColab进行模型训练。
3.1 模型选择与调整
目前卷积神经网络已普遍应用于计算机视觉领域,并且取得良好效果,如AlexNet、VGG、ResNet等。但为了提高卷积神经网络对图像分类的准确率,卷积神经网络的深度越来越大,复杂度也越来越高。考虑到本文实现的手势识别是应用于移动设备,一个复杂且庞大的卷积神经网络应用于移动设备往往会因为计算资源不足而导致无法运行,基本要依靠互联网将图像数据传输到服务端才能识别,但这样需要消耗大量的网络资源,因此将参数多、网络复杂的神经网络部署到移动设备并不现实。同时由于训练出一个良好的神经网络模型往往需要有大量规范的数据集并且花费大量的计算资源与时间去训练模型和优化参数。而通过迁移学习,将在大型数据集上训练的对某些问题具有良好识别率的模型参数迁移到新的图像识别任务上,可以使用少量的训练数据就能达到良好的训练效果,利用迁移学习可以快速训练出一个良好的模型并且实现了模型的复用。鉴于此,实验选取MobileNetV2为手势识别的模型,MobileNetV2是Google公司推出的可解决传统神经网络对设备要求高的轻量级卷积神经网络[6],并将pytorch官方在大型数据集ImageNet上训练出具有卓越性能的MobileNetV2模型作为预训练模型进行手势识别。
MobileNetV2模型的主要思想是采用深度可分离卷积,其将标准卷积的一次计算分解为深度卷积和逐点卷积二次计算,其网络结构如图4所示。假设进行卷积的特征图尺寸为(DI,DI,M),经过卷积后变为(DO,DO,N),使用的卷积核尺寸为(Dk,Dk),则标准卷积计算量为Dk×Dk×M×N×DI×DI,而深度可分离卷积的计算量为Dk×Dk×M×DI×DI+M×N×DI×DI。在采用3×3的卷积核,深度可分离卷积计算量大约为原来的1/9[7]。深度可分离卷积将标准卷积分解减少了模型的参数量和计算量,使得模型轻量化。
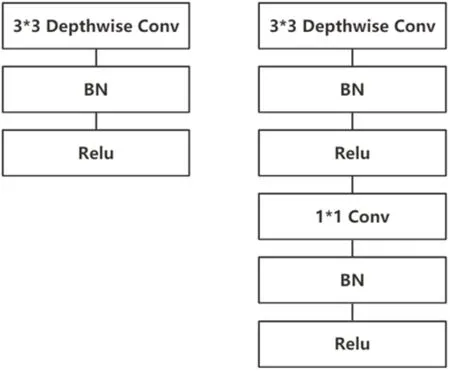
图4 标准卷积结构和深度可分离卷积结构
实验中对MobileNetV2预训练模型所做的具体调整为删除MobileNetV2上原有的全连接层分类器,加入了适合于手势识别任务全连接层,在全连接层的最后还加入SoftMax函数输出每张手势图片属于各个手势类别的概率。并在模型上所有的3*3卷积层上加入了L2正则化约束,将模型参数的权重控制在一定的范围内,使得模型的抗过拟合能力更强,提高了模型的泛化能力,调整后网络的基本结构单元如图5。由于MobileNetV2模型的网络参数较少,在文中采用对预训练的MobileNetV2模型的所有网络参数的权重进行重训练。
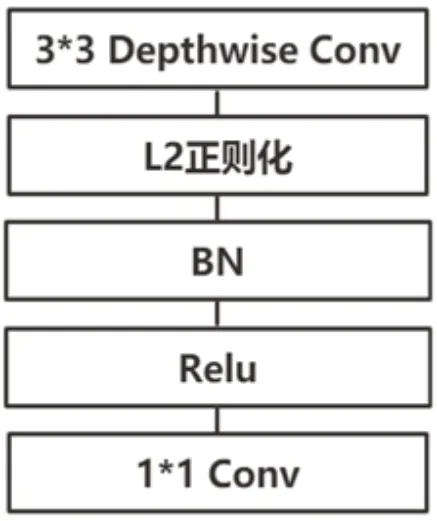
图5 调整后网络基本结构单元
3.2 模型训练及优化
在训练卷积神经网络模型过程中,学习率是影响模型训练效果的一个重要因素。实验采用自适应矩估计(Adaptive moment estimation,Adam)优化算法对模型进行优化,且使用等间隔调整学习率的方法对学习率进行调整。选择0.0001作为初始学习率进行学习,并每经过400个步数,学习率调整为原来的0.8倍,以防止在微调因学习率过大,破坏了模型权重,影响模型训练效果,且不会因为学习率太小,使得模型收敛缓慢。使用交叉熵损失函数(CrossEntropy Loss)来衡量模型输出的预测值与实际值的拟合程度,指引模型的优化方向。批训练样本数(batchsize)为128,每一个批训练样本为一个步数(step),设置了40个迭代次数(epoch)进行训练。训练过程中MobileNetV2模型随着步数的增加,识别的准确率(Accuracy)和损失值(loss)的变化如图6所示,最终模型在训练集上的识别准确率能达到98.13%,在测试集上的准确率也能到达88.31%。
4 结语
本文针对背景容易影响识别率的问题,利用肤色检测算法对手势图像进行分割处理,对经过手势分割的图像进行翻转等空间处理,实现了手势数据增强;针对移动设备性能不足,采用轻量级卷积神经网络MobileNetV2,通过迁移学习对模型进行微调训练,得到适用于在移动设备运行的手势识别模型。
