信息相似性下网络对抗文本重复数据分级索引
2021-11-19曹福凯MuhdKhaizerOmar
高 晶,曹福凯,闫 明,Muhd Khaizer Omar
(1.华北理工大学冀唐学院,河北唐山063210;2.华北理工大学,河北唐山063210;3.Faculty of Educational Studies Universiti Putra Malaysia,PutrajayaUPM Serdang,Selangor,Malaysia,43400)
1 引言
处在大数据时代,互联网已经成为人们查找资料的重要检索平台,人类时时刻刻离不开互联网应用,因此必须保证网络数据的完整,确保检索结果十分全面,就这一问题展开研究[1-2]。
朱命冬[3]等人提出面向不确定文本数据的余弦相似性重复数据分级索引方法,该方法通过计算余弦距离并进行转换,改进索引结构MVP-tree,同时利用余弦相似度面向不确定性数据的相似度计算方法,并结合分布式环境下k NN和Rk NN查询算法精确分类数据,实现重复数据分级索引。该方法未将数据进行降维处理,导致运行空间维度较高,加长了时间消耗,降低了分级效率。韩英[4]等人提出云计算环境下具有相似性的重复数据分级索引方法。该方法将云终端作为重复数据的中转站,实时获取网络数据,计算历史数据的相似度,筛选出合适的数据块,经过训练生成基础分类器,利用KL散度计算权重系数,确定分类器的有效权值,以此为依据,构成一个集成分类器,实现重复数据分级索引,该方法在重复数据分级前没有对数据进行预处理,导致无法找出分类特征项,存在分级准确率低的问题。马晓慧[5]等人提出一种基于语义相似性的重复数据分级索引方法,该方法计算了待分类文本与词典之间的语义相似度,将语义距离和嵌入的特征结合起来进行分类,以解决语义特征利用不足的问题。并采用词向量、词典匹配和特征向量来对重复数据分类性能进行了评估,实现重复数据分级索引,该方法没有计算数据特征项权重再进行相似数据的分类,出现相似数据不全的情况,从而降低相似数据的提取率。
为了解决上述问题,提出信息相似性下网络对抗文本重复数据分级索引。
2 网络数据的预处理
网络中的各种文本数据皆不相同,导致互联网无法辨识初始数据,因此需对数据进行预处理,将所有文本转换成互联网可识别的特定模式。
2.1 构建向量空间模型
利用向量空间模型表示网络文本是目前最广泛的使用模型,该模型是在线性代数的基础上设计出的较为简易的模型,此模型是最具操作性及计算性的可进行局部匹配的模型,因此可以更加精确匹配数据。其本质是利用向量空间表示网络数据,构成此向量的分别是数据特征项及特征项权重[6]。特征项权重是衡量数据可利用程度的重要指标,当系统中存在数据Ti,i=(1,2,…,n),得出关于数据T的向量空间模型如下所示
T:(t1,w1,t2,ww,…,tn,wn)
(1)
式中,tn代表网络数据文本的特征项,wn代表特征项相应的权重大小。
计算空间向量间的相似度,假设任选两个数据文本分别为T1:(w11,w12,…,w1n)及T2:(w21,w22,…,w2n),则文本间向量内积的表达式为
(2)
2.2 计算特征项权重
将表示文本的向量空间模型构建完成后,需要立即计算特征项权重大小,进一步对文本进行向量化处理。权重的实质是无论特征项出现次数多或少,都只专注此特征项的可利用程度[7]。
由于TF-IDF权重计算方法即顾忌词频问题又考虑文本长度问题,因此广泛使用该方法计算特征项权重大小,TF-IDF权重由IDF及TF组成,其中TF就是文本中的词频,即文本中的某个数据出现的次数,为防止词频大小影响文本长度,因此在计算中会提前处理词频大小,IDF就是逆文档频率,即衡量较为普通的特征项,其运算方式是文本总数与含有此特征项的文本数量的比值,并对此数值进行运算获取比值,运算公式为
wi=log2(N/ni)×TFi
(3)
式中,wi代表在文本中特征项ti的权重值,N代表训练文本的总数,ni代表文本中含有特征项的文本数量,TFi代表特征项ti出现的次数。
若出现某特征项只存在个别文本内的情况,证明此特征项的集中程度较高,随之提升了它的利用率。
2.3 特征降维算法
向量空间模型所处的维度极高的,且此向量空间中的每一维表示一个文本特征项的权重值,若在进行数据处理时直接利用此模型,由于高维度的原因会出现时间消耗较高的问题,因此在构建完向量空间模型后必须通过特征抽取的方法对模型进行降维。
特征抽取是将原有的特征项高维空间通过线性或非线性两种方法将高维空间转换成低维空间,并生成全新的低维向量空间,此向量空间不属于原有向量空间。
2.3.1 PAC算法
PAC算法又叫主分量分析法[8],它将原始变量线性配对并在线性变换下构成文本的主要成分,进而完成高维空间到低维空间的转换。
假设网络中有n个训练样板,且样板中都含有p维度,则构成的矩阵为
(4)
1)PAC算法步骤
训练样本的关系系数的运算矩阵
(5)
其中,rij表示矩阵变量间的系数。
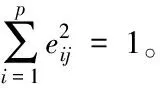
2)文本的利用率
通过上述过程得出文本在网络中的利用率公式为
(6)
式中,i=1,2,…,p,λk表示文本中的第k个主成分,且k≤p。
则叠加后的全部利用率为
(7)
文本的利用率需大于等于85%小于等于95%即为合格。
2.3.2 LDA算法
PAC算法是只针对数据简单、指标易选的线性转换空间降维而言。除此之外都需使用非线性转换的空间降维方法进行降维,即LDA算法,它的主要原理就是将处在高维空间的文本映射到最佳鉴别矢量空间中进行降维,此算法可确保样本在低维空间中仍然具有较好的可区分性[9]。
假设网络中有n个样本,分成w1和w2两个种类,w1中有n1个样本,w2中有n2个样本,且每个样本都有p个维度,利用映射函数将样本全部转化为一维的函数公式为
y=wTx
(8)
映射函数y的最终结果可直接判别样本的类别。
1)算法步骤
在映射过程中需保证w值为最优,以方便映射后的样本数据便于分类,并规定均值点的表达式如下所示
(9)
则样本映射到合适的矢量空间后的均值点为
(10)
映射后的样本数据的中心点需远离地面,且距离越大越好,即满足下列表达式
(11)
但映射后的空间样本类别方差越小越好,方差表达式为
(12)
满足上列两点要求即可求解映射函数。
空间向量映射函数完成求解后就将文本分类函数转化为求解最优解的问题,则最优解为
w=(u1-u2)(s1+s2)-1
(13)
式中,s代表原始样本数据的方差。
经过上述经过可总结出当y≥0时,文本属于c1类别,否则为c2类别。
3 重复数据分级索引
在进行数据分级索引时需要先对数据进行相似度计算再进行分类,以便分类更加准确[10]。
3.1 计算数据属性相似度
通常情况下,计算文本数据的相似度都是利用编辑距离法,此方法可通过字符间的距离来体现文本间的相似度[11]。
在编辑距离的基础上计算出两个属性值之间的距离为0,并根据转换公式求出两个字符之间的相似度为1,但其中一个字符的属性值是0.2,因此两个字符之间的相似度为0.8,由时可总结出,属性值的大小会对最终的相似度计算产生影响。因此需要完善属性值的不确定性。
当数据库中数据之间互相独立时,其属性值也一定是独立的,则同时生成两个属性值的概率就是两个属性值发生的概率的乘积,假设任意两个属性值的概率乘积是在属性层次上的WA权值,可获取WA权值表达式为
WA1=βα
(14)
式中,β表示任意两个数据中的一个数据的属性值,α表示任意两个数据中的另一个数据的属性值。
将具有属性值和不具有属性值的字符进行比较或将都不具有属性值的字符进行比较都不存在意义,因此只比较具有属性值的字符即可[12]。
3.2 朴素贝叶斯分类器
经过计算求出文本数据可能发生的概率后,利用朴素贝叶斯分类算法将所有数据进行最终分类,且此算法只适合数据间属性值相互独立的情况下使用,此算法的过程分为准备、训练及应用三个阶段。
1)准备工作阶段
将数据根据其特征项进行分类,组成训练样本,即在分类器中输入其特征项和需要分类的数据,获取训练样本。
2)分类器训练阶段
此阶段主要产生分类器,预测特征项划分对类别条件的概率,并运算出所有类别在训练样本中出现的概率,最后在计算机中输入准备阶段的结果,即可获取分类器。
3)应用阶段
利用分类器对分类型进行分类,在计算机中输入准备分类的项目及分类器,即可获得所有类别。
将训练文本中的每个词汇当成一个事件,训练文本即为事件集合,根据贝叶斯定理公式可得
P(C|X)=[P(C)P(X|C)]/P(X)
(15)
式中,X代表待分类文本的特征向量,C代表规定的文本类别体系。
文本分类的实质就是将向量形式表现的文本划分到类别中,即计算出向量形式表现的文本归类成某一类别的概率,则训练样本属于类别cj的概率计算方式为
P(cj|x1,x2,…,xn)
=[P(cj)P(x1,x2,…,xn|cj)]/P(c1,c2,…,cn)
(16)
式中,P(cj)表示文本特征向量属于cj的概率。
利用式(16)求出的最大概率就是文本向量的类别,由此可知文本分类问题就是求解概率的最大值。
当式(16)为恒定值时,此时的概率代表所有类别的叠加概率,则此时的求解表达式为
(17)
根据贝叶斯定理可知每个特征向量属性值乘积的联合概率为
(18)
此公式即为将重复数据进行最终分级的分类函数。其中,P(xi|cj)及P(cj)的概率值公式分别为
(19)
式中,N表示训练文本总数,N(C=cj)表示归于cj类别的文本数量,M表示经过预处理后的训练样本数量,N(Xi=xi,C=cj)表示具有属性值的文本数量。
4 实验与结果
为了验证所提方法的整体有效性,在Window7操作系统中对信息相似性下网络对抗文本重复数据分级索引方法、文献[3]方法、文献[4]方法进行分级效率、准确率和相似数据提取率测试。
4.1 分级效率对比结果
由图1中的数据可知,在同一环境下比较所提方法、文献[3]方法和文献[4]方法的分级时间消耗,所提方法时间消耗不仅低于其它两种方法,且时间消耗平稳,而其它两种方法的时间消耗较高,波动较大,因为所提方法在分类所有文本等级实现重复数据分级前通过构建向量空间模型对数据进行降维处理,减少运行时间的消耗,提高了分级效率。
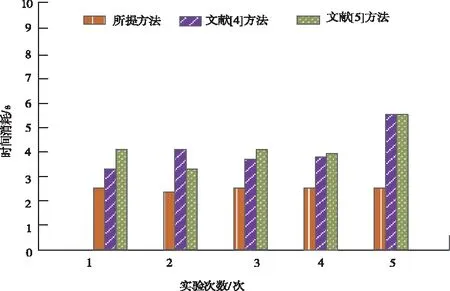
图1 不同方法的分级效率
4.2 准确率对比结果
比较三种方法的分级准确率可直接反映出方法的优劣,分析图2可知,所提方法的准确率经过多次训练其准确率始终保持在80%以上,其它两种准确率均不稳定且低于80%,因为所提方法在进行分级文本前对网络数据进行了预处理,提前找出分类特征项,减少其分类错误,从而提高了分级准确率。
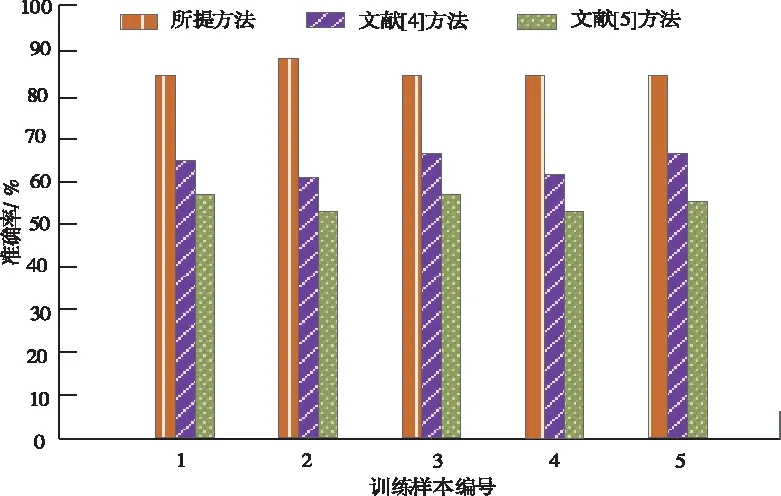
图2 不同方法的分级准确率
4.3 相似数据提取率对比结果
在进行分类相似数据前需要提取出所有相似数据,因此比较提取相似数据的数量也是判断方法的重要指标,由图3可知,与文献[3]方法和文献[4]方法相比,所提方法在网络数据中提取出的相似数据最多,因为所提方法在进行最终分类网络重复数据前计算出网络数据特征项权重,更加准确地提取出相似数据,从而升高了相似数据的提取率。
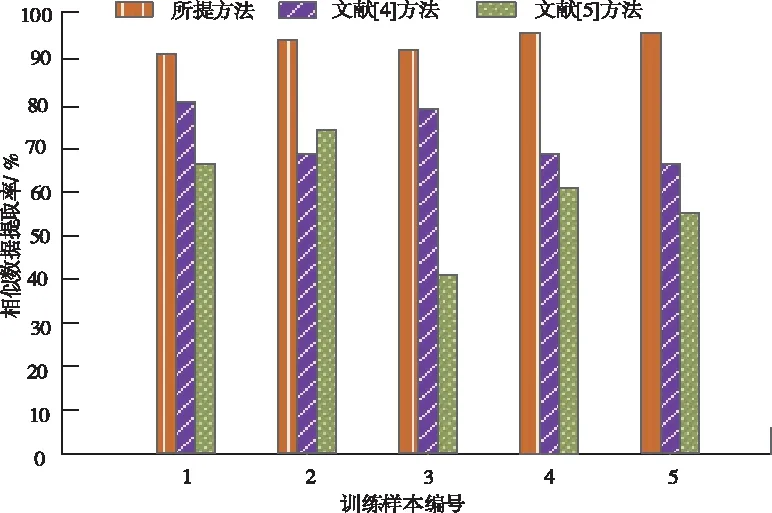
图3 三种方法相似数据的提取率
5 结束语
针对当前方法的不足,提出信息相似性下网络对抗文本重复数据分级索引方法。该方法将网络数据进行降维及特征提取等预处理再计算其相识度,最后利用朴素贝叶斯分类器实现重复数据分级索引。经试验表明,所提方法分级效率高、准确率高和相似数据提取率高。此方法对计算机要求极高,接下来将研究如何在普通计算机环境下也可进行分级索引。
