基于Fp-growth的分布式并行挖掘算法
2021-11-19长沙南方职业学院刘喜苹黄国芳刘雅筠
长沙南方职业学院 刘喜苹 黄国芳 刘雅筠
Fp-growth算法单机运算占用内存大、且耗时耗空间,挖掘大数据集时运算效率差。本文提出了一种基于Fp-growth的面向大数据集的分布式并行关联规则挖掘算法-DFp-growth算法(Distributed Fp-growth)。该算法在确保频繁项集挖掘数目不变的情况下利用数据链表将大数据集分解成多个子集,然后对分解得到的各个数据集子集用分布式并行方式进行挖掘。实验结果表明,数据集很大时,DFp-growth算法的运行速度比Fpgrowth快,而且数据集越大,并行计算节点越多,运算速度越快,分布并行运算的效率越高。但是当计算节点大到一定程度时,运算速度不增反减。
0 引言
关联规则挖掘算法很多,最经典的有Apriori[1]和Fpgrowth[2]等算法。Fp-growth虽然效率比Apriori要高,但由于需要在内存中创建Fp-树,占用内存大、耗时耗空间,所以挖掘大数据集时运算效率差。
为了提高Fp-growth算法的挖掘效率,分布式并行挖掘一直是研究热点。文献[3]提出基于Fp-growth的Multiple Local Frequent Pattern Tree(MLFPT)算法,它是在共享内存的有64个处理器的SGI系统上实现的。文献[4]提出了一种在普通分布PC机集群上的进行分布式并行计算的Fp-growth算法。文献[5]提出了基于Jumbo框架的并行Fp-growth算法。文献[6]提出了一种基于Map/Reduce模型的Fp-growth并行挖掘算法FPPM。文献[7]创建了垂直FP树(VFP)的格式来存放数据,并用任务并行的方式进行分布式挖掘。
以往的Fp-growth改进算法单机运算时,占用内存大、且耗时耗空间。而分布式并行运算时,并行子任务的分解方式差,以至于挖掘大数据集时,挖掘效率差。本文提出一种基于Fp-growth算法的面向大数据集的分布式并行关联规则挖掘算法DFp-growth算法(Distributed Fp-growth)。
1 DFp-growth算法
新算法的主要思想是利用多个计算机节点分布式并行挖掘大型数据库的关联规则,如图1所示。新算法在确保频繁项集挖掘数目不变的情况下利用数据链表将数据集分解成频繁1-项集的项总数个数据集子集,然后分别对各个数据集子集用Fp-growth算法分布式并行地进行挖掘,得到各个子集的频繁项集。最后合并各个子集的频繁项集便得到数据集的所有频繁项集。
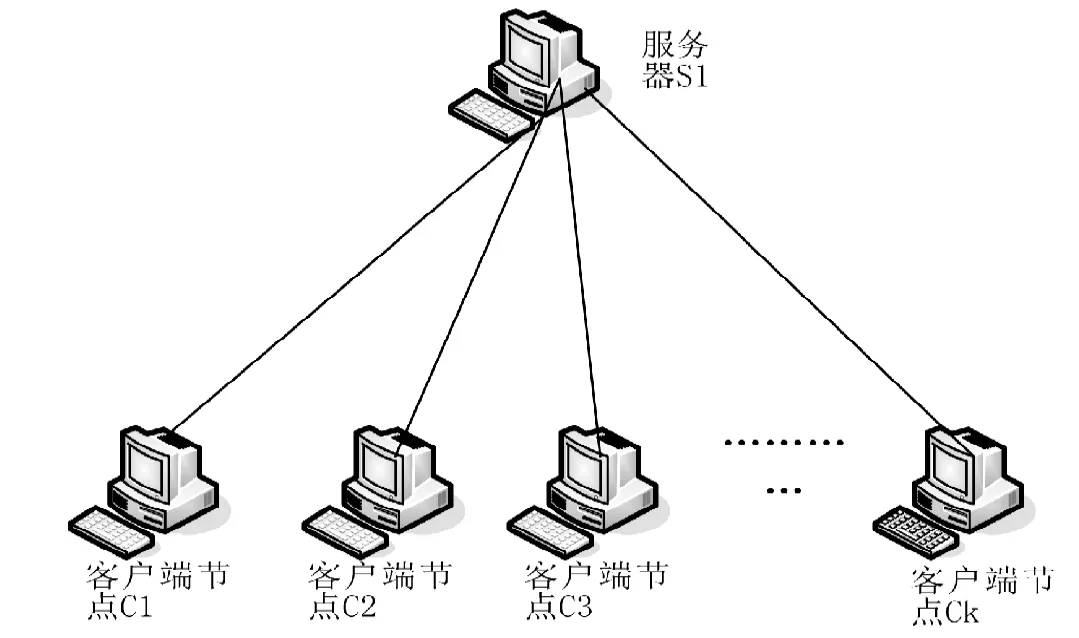
图1 分布式并行架构Fig.1 Distributed parallel architecture
1.1 DFp-growth算法描述
如图1所示。
(1)服务器S1在确保频繁项集不变的情况下,利用数据链表将数据集分解为多个子集,设min_sup=40%,分解的方式如图2和图3所示。
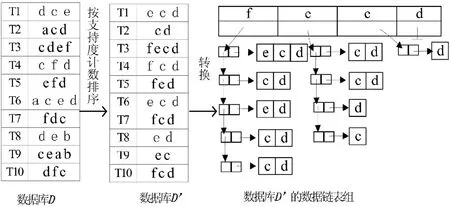
图2 数据集D数据链表组的生成Fig.2 The generation of data linked list group of data set D
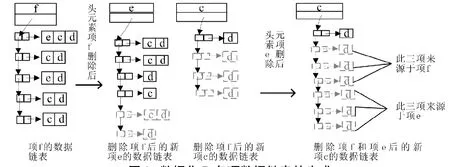
图3 数据集D各项数据链表的生成Fig.3 The generation of the data link list of data set D
(2)将各项数据链表删除时导出即可得到各项的数据子集。

(3)用多个客户端计算节点,分别对各个数据集子集分布式并行地进行频繁项集挖掘,挖掘过程如下:1)服务器将数据集分解后,将数据集子集动态分配发送给空闲的客户端。2)空闲客户端Ck得到数据子集后,将状态设为忙碌,并重新构成FP-树,利用Fp-growth算法进行频繁项集挖掘。3)Ck将挖掘出的频繁项集发送给服务器端,并将状态改为空闲,等待下一次任务。
(4)当所有数据集子集的频繁项集、依次挖掘出来后,服务器S1合并这些约束频繁项集便可得到数据集的所有频繁项集,结束挖掘过程。

1.2 伪码说明
服务器S1将数据集D排序后,将支持度小于最小支持度的项删除,放入数据链表组中。
for(数据链表组中的每一项Vi,i=(1…..数据集D的频繁1-项集的项总数))
{
服务器取出数据链表组中第一项事务组Vi导出成数据集子集Di
服务器将第一项事务组Vi的头元素去除
将去掉头元素的事务根据Vi中后继元素的不同,迭加到其他项的事务组中
形成新数据链表组
2 实验结果
为了分析比较Fp-growth算法和DFp-growth算法的性能,利用C语言实现了Fp-growth算法和DFpgrowth算法,并在PetiumⅣ2.8G、内存1.5G的环境下的进行了仿真实验。实验数据是WebDocs数据集,实验结果如图4,图5所示。图4和图5分别是从数据集WebDocs中抽取了500MB包含58万条左右的数据和1GB包含119万条左右的数据,在最小支持度设为(30%)时进行测试所得的结果。
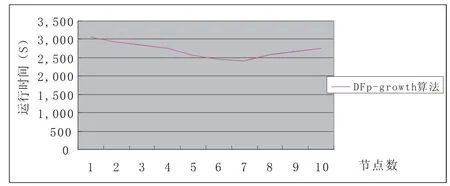
图4 DFp-growth算法在WebDocs数据集上(500M)的测试结果Fig.4 Test results of the DFp-growth algorithm on the WebDocs data set (500M)
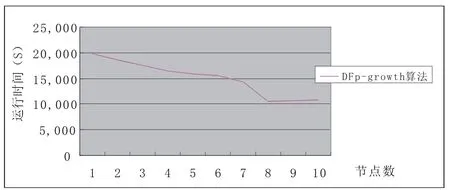
图5 在DFp-growth算法WebDocs数据集上(1G)的测试结果Fig.5 Test results on the DFp-growth algorithm WebDocs data set (1G)
(1)Fp-growth算法挖掘WebDocs数据集(500M)时,所需时间是11,452s,而DFp-growth算法的运行速度比Fp-growth快,而且并行计算节点越多,运算速度越快,测试结果如图4所示。但由于WebDocs数据集上(500M)不是很大的数据集,所以计算节点的增加对运算速度影响不大。
(2)Fp-growth算法挖掘WebDocs数据集(1G)时,因所需内存太大了,所以Fp-growth算法无法计算出结果,而Dis-Fp-growth算法可以运行出来,测试结果如图5所示。而且因WebDocs数据集上(1G)是较大的数据集,所以计算节点的增加对运算速度影响大,分布运算的效率高。
(3)通过图4和图5可知,数据集越大,分布计算节点越多,DFp-growth算法分布并行运算的效率越高,运算速度越快。但是当计算节点大到一定程度时,运算速度不增反减。
3 结语
本文在Fp-growth算法的基础上,提出了一种分布式并行关联规则挖掘算法——DFp-growth算法。该算法将大型数据集利用数据链表分解成多个子集,然后对分解得到的各个数据集子集用Fp-growth算法进行分布式并行挖掘,得到含有各个子集的频繁项集。最后合并各个子集的频繁项集便得到数据集的所有频繁项集。实验结果表明DFp-growth算法所采用的数据链表划分子集策略克服了Fp-growth算法对大型数据集进行挖掘时,占用内存大,运行速度慢的不足。且DFp-growth算法采用分布式并行挖掘也极大地提高了挖掘效率。测试结果如图4和图5所示,测试结果表明数据集越大,分布计算节点越多,DFpgrowth算法分布并行运算的效率越高,运算速度越快。但是当计算节点大到一定程度时,运算速度不增反减。
引用
[1] Rakesh Agrawal,Tomasz Imielienski,and Arum Swami.Mining Association Rules between Sets of Items in large Databases[A].Proc Conf on Management of Data[C].ACM Press,New York,NY,USA 1993.
[2] Jiawen Han,Jian Pei,and Yiwen Yin.Mining frequent patterns without candidate generation[A].In Proc.2000 ACM-SIGMOD Int.Conf.Management of Data(SIGMOD 2000) [C].New York:ACM Press,2000.
[3] ZAIANE O R,EI-HAJJ M,LU P.Fast parallel association rule mining without candidate Generation[A].Technical Report TR01-12,Department of Computing Science,University of Alberts[C],Canada,2001.
[4] Pramudiono I,Kitsuregawa M.Parallel FP-Growth on PC cluster[A].In:proceeding of Advances in Knowledge Discovery and Data Mining[C].Springer Berlin Heidelberg,2003.
[5] S.Groot,M.Kitsuregawa.Jumbo:Beyond MapReduce for workload balancing[A].In:Proceedings of 36th International Conference on Very Large Data Bases[C].Singapore,Sep.2010.
[6] 章志刚,吉根林.一种基于Fp-growth的频繁项目集并行挖掘算法[J].计算机工程与应用,2014(2):103-106.
[7] 徐杰,李云,刘博,等.基于垂直FP树的并行频繁项集挖掘[J].计算机与数字工程,2012,40(10):12-15.
