基于文本密度的网页抽取研究
2021-11-18谢俊宇
谢俊宇
摘要:面对海量的信息库,如何从网页中将与网页主题相关度较高的正文信息抽取出来是比较困难的。本文针对新闻网页,提出基于文本密度的网页抽取算法,这是一种快速、准确通用的网页提取算法。通过与现有的一些算法对比,该算法可以较好的支持大数据量网页正文提取操作。
关键词:数据采集;网页抽取;智能页面解析
1 引言
随着Web技术的发展,人类的日常生活方式已经发生了巨大的变化。这些变化使得许多传统的纸质载体都被电子载体取而代之,许多信息都通过互联网上的网页来传递和展示。新闻网站是实时新闻发布的主要平台,也是获取实时新闻的关键平台,要及时、全面地获取新闻实时信息并作为后续研究的基础信息,对新闻站点进行实时采集很有必要。因此,如何从大量的半结构化网页信息中快速抽取用户感兴趣的内容是需要研究的重要课题。
2 国内外研究现状
目前较为成熟的信息抽取方法为基于统计的方法。主要有统计文本密度、标签密度和行块分布等方法。Weninger等提出CETR算法,利用聚类方法并基于网页源代码的标签比特征值来进行网页信息抽取。Mehta 等在DOM树的基础上提出阈值和数据过滤器的概念,用于检测和删除网页中不相关和冗余的数据,从而动态消除不同结构化网页的噪声内容,来提取网页关键内容。吴共庆等根据DOM树标签路径特征,提出将不同特征融合得到融合特征值的方法,然后在利用融合后的特征对新闻网页进行内容抽取。
3 网页抽取算法
本文通过对新闻网页的正文页进行分块,提出基于标签文本密度的网页抽取算法。缩小了抽取新闻标题、正文、发布时间的范围,并结合符号密度,计算最终文本密度得分,提高了抽取正文的准确率。
在新闻网页的正文页面中:
1. 文本字数较多
2. <a>标签文本字数较少
3. 标点符号(尤其是句号等)使用较多
4. 段落较多
正文标题通常会用<h*></h> (*:1-6) 标签包含,而正文通常会使用<p></p>标签包含。有可能在<p></p>标签中还会包含<a>链接或者<span>标签等,但是只需要找到包含正文内容的<p></p>,无论<p></p>标签内会包含什么标签,都可以视为新闻正文内容。例如以下是新闻正文页html代码示例:
<body>
<h1 class="post_title">习近平谈为基层减负 </h1>
<div class="post_info">2021-02-03 08:18:37 来源:党建网微平台</div>
<div class="post_body">
<p>2020年岁末,一份名为《关于持续解决形式主义问题深化拓展基层减负工作情况的报告》……</p>
<p>要坚决整治形式主义、官僚主义,让基层干部从繁文缛节、文山会海、迎来送往中解脱出来。</p>
<p>在疫情防控工作中,有些地方出现了形式主义、官僚主义现象……</p>
<p>要控制各级开展监督检查、索要材料报表的总量和频次,同类事项可以合并的要合并进行…… </p>
</div>
</body>
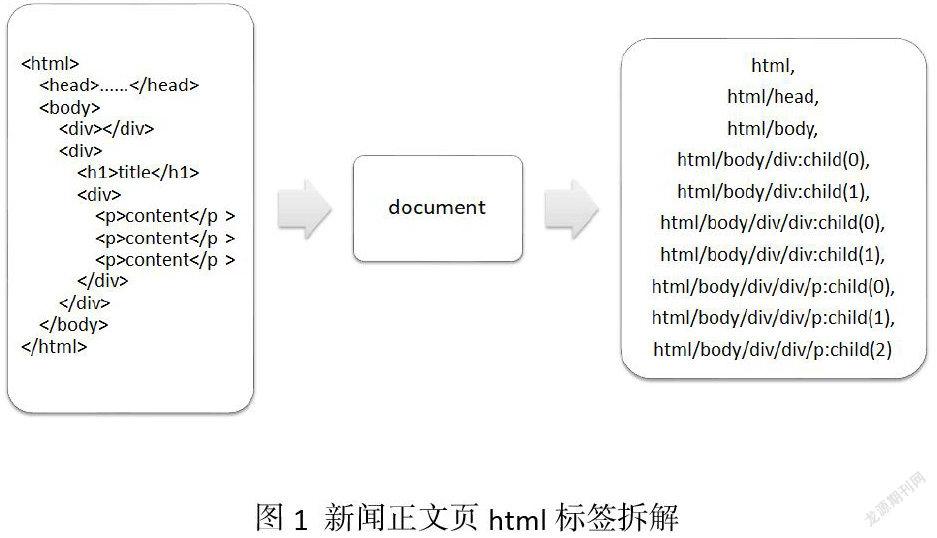
我们首先需要初始化html,将html文件解析为document对象,并且拆分取出每一个标签。如图所示:
接着获取每个div盒子中的标签文本统计信息,分别计算每个div中的标签文本密度,再计算每个div中的标点符号密度,最终结合标签文本密度和标点符号密度,使用不同底数的对数函数对数据进行压缩,调整权重占比,计算每个div中的文本密度得分,文本密度得分最高的div盒子即为我们的正文内容。
4 验证实验
4.1 数据集的选取
为验证算法性能,我们采集了来自不同大型新闻网站、时间跨度30天的9313篇新闻网页作为算法的性能评测样本数据集。实验最后将新闻样本的使用人工方法抽取的正文字符与算法自动抽取的结果作对比,以此来衡量算法的抽取准确率。
4.2 评测指标及实验结果
本文对提取内容和标准内容进行对比,采用Precision、Recall、F1值这3个通用的评测指标来衡量通用网页新闻标题自动抽取算法的性能。文本对比过程采用改进的LCS(Longest Common Sequence)算法,LCS算法是将两个给定字符串分别删去零个或者多个字符,但不改变剩余字符的顺序后得到的长度最长的相同字符序列。
F1值是Precision和Recall调和平均数。它综合了P和R的结果,当F1值较高时,則能说明算法性能较好。若实验数据量越大,数据集分布越平衡,则评测指标的可信度也会越高。最后通过计算,可以得出自动抽取算法在整个样本数据集上的平均准确率P、平均召回率R以及平均F1值分别为98.3、99.2和98.75。
实验结果发现通过算法提取的网页正文内容与人工提取的标准结果吻合度较高,所以该算法对于国内的新闻网站的智能提取还是较为不错的。
参考文献:
[1] WENINGER T,HSU W H,HAN J. CETR:content extraction via tag ratios[C]// Proc of the 19th International Conference on World Wide Web. New York:ACM,2010:971-980.
[2] MEHTA B,NARVEKAR M. DOM tree based approach for web content extraction[C]// 2015 International Conference on Communication,Information & Computing Technology. Mumbai:IEEE,2015:1-6.
[3] 吴共庆,胡骏,李莉,等. 基于标签路径特征融合的在线Web新闻内容抽取[J]. 软件学报,2016,27 (3) :714-735.WU Gongqing,HU Jun,LI Li,et al. Online Web news extraction via tag path feature fusion[J]. Journal of Software,2016,27 (3) :714-735.
[4] 王永新,王秋芬,梁道雷.一种高效LCS算法[J].南阳理工学院学报,2013 (6) :67-70.
