一种针对快速梯度下降对抗攻击的防御方法
2021-11-18王晓鹏杨锦涛
王晓鹏,罗 威,秦 克,杨锦涛,王 敏
(1.中国舰船研究设计中心,武汉 430064;2.武汉大学 电子信息学院,武汉 430072)
0 概述
舰船目标识别系统是舰船装备智能化的一大热点应用领域,如在合成孔径雷达(Synthetic Aperture Radar,SAR)图像舰船识别[1]中应用人工智能技术来实现智能舰船目标识别[2-4],然而智能舰船识别的安全问题却没有受到重视。文献[5-7]中的红外图像舰船目标识别方法以及文献[8]中改进型的舰船目标识别系统都有可能进化成智能舰船识别系统,因此,应提前考虑安全识别问题。在实战中部署好的舰船图像智能识别的安全性主要集中在针对已经训练好的分类神经网络模型的攻击领域上,暂不考虑针对数据集的投毒[9]和模型在训练过程中的攻击[10],因为在投入实战之前必须经过一系列测试检验,这可以有效地过滤掉前面的攻击,所以图像分类领域的对抗攻击[11]是主要研究对象。目前抵御对抗样本攻击的主流方法都是通过优化神经网络的结构来重新训练分类模型或采取新的数据和方法来重新训练分类模型。文献[12]指出防御蒸馏的方法并不会显著提高神经网络的鲁棒性,文献[13-15]分别研究了压缩格式、降噪和随机离散化的方法来应对对抗攻击,文献[16]提出在神经网络旁加一个辅助块来防御攻击,文献[17]则提出了较为经典的对抗性训练的方法来防御对抗攻击。如果一个性能非常好的分类模型遭到对抗攻击,则应寻求更为简单的方法来抵御这种攻击,一是因为训练一个顶级分类性能的分类模型十分不易,二是因为人工智能神经网络模型的不可解释性导致不能保证在短时间内复现分类模型顶级性能。本文在不改变神经网络结构同时避免重新训练分类模型的前提下,提出一种防御舰船对抗样本攻击的方法。
1 舰船对抗样本
生成对抗样本的方法(即对抗攻击方法)可以分为白盒攻击、黑盒攻击和灰盒攻击[18],目前主流的对抗攻击方法以白盒攻击为主,如快速梯度下降法(Fast Gradient Sign Method,FGSM)[19]、雅克比映射攻击(Jacobian Saliency Map Approach,JSMA)[20]、深度欺骗攻击(DeepFool)[21]等。白盒攻击是指攻击者知晓被攻击者的全部神经网络结构和各项参数以及数据集等,同理可理解灰盒攻击和黑盒攻击,其中FGSM 和DeepFool 最具代表性。
FGSM 是GOODFELLOW 在高维度线性假设的基础上提出的一种白盒攻击的方法,基本思想是:先寻找深度学习模型的梯度变化最大化的方向,再沿该方向施加一些图像扰动噪声,最终使模型产生错误的分类。FGSM 产生的微小扰动噪声不容易被人眼观察到,其优势是攻击效率高。FGSM 原理如式(1)所示[19]:

其中:x'是对抗样本;x是模型输入即图像;y是结果标签;J(x,y)是损失函数;sign 是符号函数;ε是步长。
DeepFool 基本思想与FGSM 保持一致但性能优于FGSM,因为DeepFool 更好更合理地设定了FGSM 原理公式中的步长ε,通过迭代的方式生成累加干扰噪声,这样产生的对抗样本中噪声扰动的幅度比FGSM 更小。可以从Github 上找到FGSM 开源代 码(https://github.com/soumyac1999/FGSM-Keras),该代码实际上使用DeepFool 算法的思路即通过迭代的方式累加干扰噪声并最终生成对抗样本。如图1所示,该方法产生的对抗样本可以使分类模型将航空母舰(原图,置信度为0.99)归类于灰鲸(对抗样本,置信度为0.60)。代码中所用的神经网络模型是基于ImageNet 的VGG16 预训练好的分类模型,可以识别1 000 种生活中常见的类别,该模型曾在ILSVRC(ImageNet Large Scale Visual Recognition Challenge)国际竞赛中拿到第二名、项目类别第一的成绩。VGG16 是经典卷积神经网络模型,16 表示其深度,由13 个卷积层和3 个全连接层叠加而成[22]。

图1 舰船对抗样本Fig.1 Ship adversarial example
2 对抗攻击防御方法
FGSM 和DeepFool 这2 种方法最明显的特征是沿着分类模型梯度的方向施加干扰,这样微小干扰的影响会在神经网络里滚雪球式地越来越大,从而导致分类模型出错,而且模型输入的维度越大越容易受到攻击[19]。图1 所示是有目标攻击,航空母舰被指定攻击为灰鲸。有目标攻击是指攻击者生成的对抗样本可以使被攻击的分类模型错误地分类成指定目标。与有目标攻击对应的是无目标攻击,即对抗样本使分类模型将其错误地归类而并不指定错误地归为哪一类。本文进行一次专项实验,用于验证在对于已经被干扰的图像(即对抗样本)再进行有目标攻击且目标指定为其原本真实类别的情况下,能否使分类模型重新认识该对抗样本。如图2 所示,对对抗样本再进行一次有目标攻击,将目标人为设置为航空母舰,攻击结果图像被正确识别为航空母舰(置信度为0.72)。实验结果表明,对抗样本在相较于原图没有明显形变的情况下,可以通过有目标再攻击,使被分类模型重新正确地归类。

图2 对抗样本再次有目标攻击后的分类结果Fig.2 Classification result after targeted attack of adversarial example
如果事先知道对抗样本的类别,就可以通过有目标再攻击来防御对抗样本的攻击,这确实是一个悖论。本文针对如何让分类模型获得对抗样本原本真实的分类,进行一次对比实验。图3所示是将火烈鸟错误识别为蚂蚁的对抗样本再次设定为火烈鸟有目标攻击时,置信度随迭代次数的变化图。可以看出,当迭代次数达到200 时,该图像已经可以被正确地识别为火烈鸟,置信度大于0.7,随着迭代次数的增加还会上升。与之对比的是目标随便设定,图4 所示是以错误目标攻击时置信度随迭代次数的变化图,源代码中最大迭代次数默认值是400,图片来源是对橘子的图像进行目标设定为黄瓜的有目标攻击,产生的对抗样本被以0.4 的置信度识别为黄瓜。之所以采用火烈鸟和橘子的对抗性数据,是因为这2 个数据更经典更具代表性,图1 所示的有目标攻击过程只需100 代以内,相对更容易。随着迭代次数的增加,置信度还会继续缓慢地上升,当以错误目标攻击时还会出现置信度随迭代次数增加反而下降的情况。
图3 和图4 的实验结果表明,置信度曲线的斜率与再攻击的目标有关系,本文提出以下假设:可以根据置信度曲线的变化来判定再攻击的目标是否为其真实的类别,其中最重要的问题是:如果假设成立,那么需要找到置信度曲线的斜率应符合怎样的标准或规律才能判定当前再攻击的目标就是其真实的类别。

图3 再次以正确目标攻击时置信度随迭代次数的变化图Fig.3 Change diagram of confidence when attacking with the right target again

图4 以错误目标攻击时置信度随迭代次数的变化图Fig.4 Change diagram of confidence when attacking with the wrong target
2.1 再攻击过程中置信度曲线的变化规律
在寻找符合真实目标类别的再攻击过程中,置信度曲线斜率变化的标准是关键所在。为了量化问题,本文引入参数,设对抗样本的真实目标类别为K,在再攻击过程中,设指定攻击的目标为A,分类模型被攻击时把对抗样本归类为A 的置信度设为m,同时设攻击目标为A 的再攻击过程中的实时置信度为x,显然,x在再攻击过程中是一直变化的,而且在再攻击开始的瞬间x=m。此时,关键问题就转化为参数关系,即寻找当再攻击目标A 为K 类别时再攻击过程中x和迭代次数i的关系,这里设这层关系为F,即寻找关系F。显然,图3 所展示的关系是符合关系F 的,可以根据图3 来进行逆推关系F,同时用图4做反例来进行简单对比,然后再进行验证和校正。总体步骤分为3 步:首先找出能解决一张对抗样本的关系F;然后优化推广到多张或一批对抗样本;最后使关系F 适用于所有的或多数的对抗样本。
第2 步和第3 步的成功取决于第1 步。将图3 中置信度变化分为3 段:前段是平缓期,该段的最大特点是置信度上升较平缓,以迭代次数i=25 为界;中段是上升期,最大特点是置信度曲线斜率在该段出现最大值,以i=100 为界;后段也是平缓期。以此来合理推测关系F,考虑开始时x=m,那么m值决定了x的起点,例如可以预见当m>0.1 时前段将变得非常短,因此,关系F 必定是x、i、m三者的动态关系。为了使逆推出的关系F 避免出现过拟合的情况,需要适当放宽条件。
根据图3 逆推出关系F,如表1 所示,以此判断A是否为真实目标。其中:i是迭代次数;m是目标A的攻击前的置信度;x是攻击过程中的实时置信度(每迭代一次都会给予置信度)。由m的3 个范围设计不同的判决条件系数,经过验证可知能够防御图3中对抗样本,即实现了第1 步,解决了1 张对抗样本。这一设计是考虑到第2 步的进行,经过不太复杂的优化(优化m值的范围区分精度和相对于i的x的判决精度)就可以实现第2 步。关系F 的最大优点是:如果A 不为K 类别则不会耗费很多的时间,只有真实目标才会耗费很多的迭代次数以及时间。

表1 关系F 的设置Table 1 Setting of the F condition
解决了关键问题,就可以设计出初始防御方法的流程。笔者在实验中发现,对抗样本被分类模型错误归类的同时,分类模型会给出预测此次分类结果的置信度,分类结果按置信度从大到小排行,排在第1 位即置信度最高的即是分类结果,真实的类别通常排名比较靠前,例如,攻击代码中被预测为蚂蚁的对抗样本其真实类别火烈鸟的排名为63,对于能识别1 000 种类别的分类模型而言,这一排名已经很靠前了。因此,推测1 张对抗样本的真实类别的排名一定在前150 名,用暴力搜索的方法找出符合的关系F 的目标即是真实的目标。基于关系F 的防御方法流程如图5 所示,针对对抗样本的攻击,利用条件F 可以采用暴力搜索的方法来找出对抗样本的真实目标分类,图中a的默认值为150。
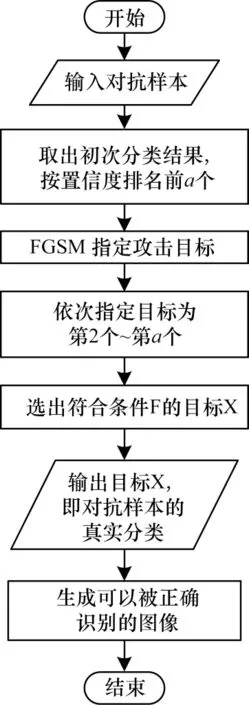
图5 防御流程Fig.5 Procedure of defense
经过验证,此方法可以成功地找出图3 中对抗样本的真实类别,采用经过优化的关系F 后可以实现多张对抗样本的防御,结果如图6 所示,图7 是每组对抗样本复原过程中置信度变化曲线图,可以看出它们具有的相似特征,这正是关系F 的体现。暂不考虑遇到相似目标时的情况,例如双胞胎,因为这是分类模型自身带有的问题。

图6 实验组图Fig.6 The experimental figures

图7 复原过程中置信度变化图Fig.7 Change diagrams of confidence in recovery process
2.2 FGSM-Defense 算法
为了能使上述方法能应对更为普遍的对抗攻击而不只是特定的几张对抗样本,实现第3 步防御多数对抗样本的目的,需要把方法推广到针对未知的对抗样本上去,以调整优化核心条件和策略,获得更好的防御效果。笔者在推广的过程中发现有2 个明显的缺点;1)该方法的成功率依赖于核心判决条件是否符合相应数据集的数据特征;2)方法中采用的暴力搜索式的搜索方法在应用中存在障碍,如果真实目标恰巧排在第150 名就会花费很长的时间,造成资源长时间被占用,而且对核心判决条件的精准度要求非常高。总地来说,在此过程中难以找到高精准度的判决条件F,且暴力搜索的范围太大。
针对这两个明显的缺点,本文对关系F 进行了策略性调整,为控制时间花费,取消了采用小步长ε并通过循环累加噪声进行攻击的方式,改为直接控制步长ε的大小从而一次性完成攻击任务的方式;同时,为了适应更加广泛的未知样本,不再追求一次性找出真实目标,而是分步缩小真实目标所在的范围,然后再通过一定的手段以较大的概率筛选出真实的目标。由此,最终提出防御算法FGSM-Defense。图8 所示是FGSM-Defense 的模型框图,模型中分两步缩小真实目标所在的范围,缩小后的范围为别为N和G。
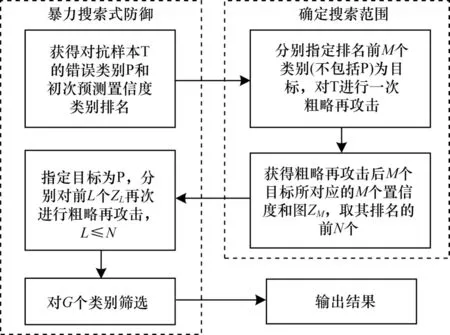
图8 FGSM-Defense 模型框图Fig.8 Block diagram of FGSM-Defense model
先解释范围N是如何确定的。在FGSM 原理公式中并没有明确地给出步长ε的设定,而DeepFool算法很好地分析了最短步长ε的设定,并通过循环累加干扰噪声,使产生的对抗样本的噪声扰动幅度更小。在此次所用的FGSM 原攻击代码中,ε=0.01,循环次数为400,而在防御过程中无需考虑扰动噪声的大小,因此,在确定搜索范围模块中攻击代码的步长设定ε=5,并取消了循环,一步完成攻击,大幅缩短了时间花费。虽然这样产生的噪声扰动很大,但攻击成功后目标分类的置信度大小和设定小步长并循环400 次的攻击结果相似,故简称粗略再攻击。在确定搜索范围模块中,扰动噪声的幅度不重要,重要的是能很快获得对抗样本T 被M次目标分别为前M个类别的粗略再攻击过后被分类器归类于指定目标类别的置信度,此时共有M个类别的置信度,将其大小排序,取出前N个置信度所对应的目标类别,这样就确定了搜索的范围为这N个目标。
再解释搜索范围N是否有效地缩小。由于对抗样本的真实目标类别的初次排名一定在前150 名,因此M=150。经过实验验证,分别指定目标为这150 个目标类别对T 进行粗略再攻击后,不考虑扰动噪声的大小,原对抗样本真实的目标类别的置信度比较大,通常排名在前5 名,较大概率排在前10 名,所以N=10,远远小于150,而且这150 次粗略再攻击花费的时间较短,为3 min 左右,因此搜索范围缩小到了N=10。
在这N个目标中选出置信度大于0.75 的L个类别,此时L≤N,即L≤10。如图9 所示,其中0+代表原图,在施加噪声扰动x0后对于分类器来说变成了0-(0+和x0都是未知的),再对0-进行有目标攻击生成新的类别,即1,2,…,L,施加的噪声干扰分别为x1,x2,…,xL,再对生成的图像1,2,…,L进行目标为0-的有目标攻击,施加的噪声干扰分别为t1,t2,…,tL。在L小于10 的前提下,由于未知的x0一直存在于对抗样本中,因此如果L是对抗样本0-真实目标分类,那么在第3 次有目标攻击过程中x0对tL产生的影响是相对独特的,直观表现就是在攻击过程中分类器对目标L置信度评价下降速度相比于非真实目标类别较为缓慢,甚至会出现小幅度的上升。因此,第3 次在攻击过程中检测所有类别的置信度变化情况,选出前G个下降幅度较小或出现上升的目标类别,最终,在实验中锁定G=2,即真实目标以较大的概率出现在前2 个排名中。

图9 有目标攻击示意图Fig.9 Schematic diagram of targeted attacks
从G=2 个目标中筛选出一个目标,要求选中真实目标的概率应大于50%(至少应比随机猜强),筛选条件选定的是,相反从第2 次有目标攻击过程中,通过控制步长ε 的大小来观察2 个目标类别的置信度大小,选出置信度较大者,根据L的大小设定3 个范围,即:L≤3 时ε=2;3
FGSM-Defense 算法伪代码如下:
算法1FGSM-Defense 算法

如果对抗样本中的物体是该类别的典型代表,同时展现的是物体的经典角度面,并且图片的背景比较纯净的话,防御成功率较高,反之较低。图10所示是2 张不同角度的对抗样本,防御程序在防御图10(a)对抗样本的成功率比在防御图10(b)对抗样本时高出约23%。

图10 不同目标角度的对比Fig.10 Comparison by different target angles
2.3 舰船识别安全防御模型
为了使舰船智能识别系统更安全,需要给安全防御方法设置一道防火墙。由于舰船特征识别里最为显著的特征是轮廓特征,因此采用轮廓特征识别作为最后的安全验证防火墙,如果验证不通过系统将会报警。对抗样本并不会影响舰船的轮廓特征的提取,图11 所示是利用RCF(Richer Convolutional Features)[23]物体边缘识别技术提取的舰船对抗样本的轮廓图,图中采用的正是图1 中被识别为灰鲸的对抗样本,并提供了原图轮廓提取图的对行对比。舰船图像识别的安全防御模型如图12 所示,图像传入分类模型,分类结果提交给验证模块,通过验证就输出结果,否则传输至安全模块进行安全防御识别,最终将正确分类传输至智能平台并输出结果。安全模块采用FGSM-Defense 防御方法,安全验证模块采用的是舰船轮廓特征提取模块,并将数据发给智能学习平台,用来监测舰船图像分类结果是否符合其轮廓特征,即安全识别防火墙。智能平台负责数据分析,当分类模型遭到大量重复攻击时可以学习并标记重复数据并直接输出结果。

图11 轮廓图对比Fig.11 Comparison of comtour diagrams
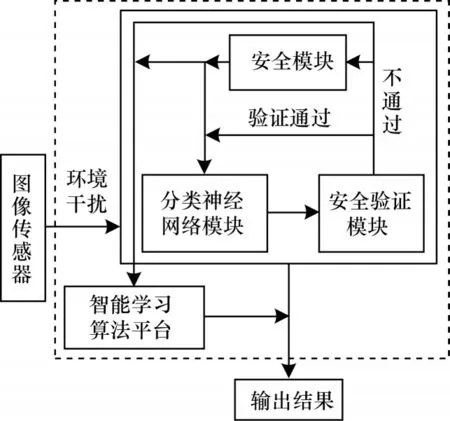
图12 安全防御模型Fig.12 Security defense model
3 防御测试与结果分析
从ImageNet上选500 张图片,剪切为1∶1 的比例。如图13 所示,经过分类器初次预测后,筛掉置信度小于0.9 的图片259 张(其中212 张小于0.8),然后仔细筛查掉识别错误或分类有争议的图片36 张,再去除图片中物体占比不到1/4 的图片或由剪切导致的物体形状不全的图片39 张,最后经过FGSM 攻击成功生成对抗样本的图片数为143 张(剩余23 张攻击失败,并没有使分类器产生错误分类),防御程序能找出76 张对抗样本的真实分类。

图13 防御测试数据Fig.13 Defense test data
经过测试,FGSM-Defense 算法在ImageNet 数据集上的防御成功率为53.1%(测试条件是图片比例1∶1、分辨率为224 像素×224 像素以上的彩色图片,对抗样本必须使分类器产生错误分类,并且与原图相比不能有明显的形变,原图必须能被分类器以0.9以上的置信度正确的识别与归类),程序运行一次的时间花费为5 min,无论防御成功与否,都不会长时间占用资源。
4 结束语
舰船图像识别系统的鲁棒性和安全性是其应用过程中所面临的最大难题,为使舰船图像识别可靠且安全,本文构建一种应对恶意对抗攻击的新方法和相应的防御模型。利用攻击算法的特点,在对抗样本的基础上再对其进行多次不同目标的有目标攻击,寻找其中特定规律。在此基础上进行验证,根据验证结果对方法进行优化,直到从多次有目标攻击的结果或过程中筛选出该对抗样本的真实目标类别。在ImageNet 数据集上的测试结果表明,该方法可以在较短时间内找出对抗样本的真实类别,有效降低防御成本。后续将加强数据测试并优化防御方法,以进一步提高防御成功率。
