基于改进遗传算法的软件单元安全性测试仿真
2021-11-18庞先伟
王 超,庞先伟
(西南财经大学,四川 成都 610074)
1 引言
目前,计算机软件在各领域得到广泛使用,已成为人们工作与生活的重要组成部分。软件的安全问题会造成一定的财产与隐私风险。因此在软件开发中安全检测是关键环节。其主要目的是通过少量测试用例实现最大的检测覆盖面,保证及时发现软件存在的安全隐患,进而改善软件可靠性。但是计算机程序日益复杂,软件漏洞查找难度逐渐增大。为解决该问题,相关专家已经得到了一些可应用的研究成果。
文献[1]提出软件安全检测方法。利用安全控制结构,建立描述软件过程的变量模型。综合分析危险发生系统上下文信息,将其作为软件安全性要求。设计控制系统软件,采用模型检验技术对软件安全性进行测试。文献[2]在区块链基础上构建软件安全检测模型。当一个区块链高于六个区块后,此区块的内容将不能被改变,认为其达到稳定状态,威胁出现的概率有效降低,根据每个区块到达稳定状态的几率来判断软件是否安全。
上述两种传统方法具有较好安全检测性能,但是实际应用中出现了漏检率偏高问题。为此本文利用改进的遗传算法测试软件单元安全性。在传统遗传算法基础上,引入种群活力思想,综合分析种群多样性与邻近种群之间相似度,利用并行机理改进变异操作过程。仿真结果表明,所提方法降低了漏检率,对软件可疑点测试更加全面,表现出了较高应用价值。
2 软件威胁分类与异常特征分析
2.1 安全威胁分类
1)系统软件安全威胁
操作系统属于最关键的软件之一,是智能终端的核心,若系统存在安全威胁,则用户隐私信息可能暴露。现阶段操作系统威胁分为:系统漏洞、系统底层API(Core Audio APls)滥用等。
系统漏洞[3]能够对软件安全造成毁灭性危害,例如iOS(Internet work Operating System)越狱行为就是通过存在的漏洞破坏系统,属于主动破坏行为。一些漏洞问题会在网络中公开,因此攻击者能够任意使用漏洞资源对软件进行攻击。
2)应用软件安全威胁
此种威胁主要由恶意软件[4]引起。在传统互联网中对恶意软件研究起步较晚,缺乏对其识别的标准。为提高整体网络安全环境,提出恶意软件代码描述规范。此规范中分类恶意元件,包括信息窃取、资费消耗、系统破坏等。
2.2 软件异常特征分析
软件安全问题体现在多个方面,比如:CPU占用量较大,表明软件存在潜在风险,可优化其空间;电量大量消耗表明可能有恶意软件正在资源消耗;内存快速减少说明内存遭到泄漏。结合上述的软件安全分类结果,将软件有关安全问题与系统性能特性指标一一对应,总结结果表1所示。
3 基于改进遗传算法的软件单元安全性测试
3.1 软件安全性度量性选择
遗传方法是一种自适应搜索算法,与优胜略汰思想相同,存在自适应性与并行性,有助于处理海量复杂数据,可以解决软件质量度量属性选取问题[5]。此外,该方法还能对任意一个度量属性做出优劣评判,而不局限于评价单一软件安全性,确保选择的度量属性子集最优化,提高搜索效率,属性选取过程如图1所示。
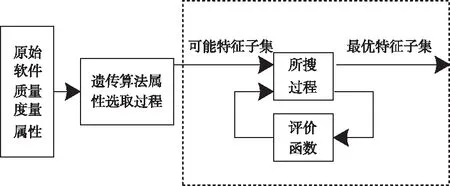
图1 遗传算法的软件质量属性选取过程
3.1.1 度量属性编码
编码方式是遗传算法的重要内容,表示全部软件属性子集的解空间。常用的编码方式较多,由于软件质量度量属性仅有选中与不选两种结果,因此本文利用二进制编码。
例如某六个软件安全性度量属性表示为{y1y2y3y4y5y6},因此{111010}代表一个可能属性子集合,其中1表示被选中,0表征未被选中。
3.1.2 初始种群选择
在遗产算法中必须先确定一个潜在解,将其视为初始种群[6]。因为初始种群分布状况会影响该算法全局收敛性,假设{X(n);n≥1}表示算法中种群马尔科夫链,pm=0,X(0)=X0,因此可以得出:
1)针对Y∈L(X0),有n≥0的情况存在,所以P{Y∈X(n)/X(0)=X0}>0;
2)针对Y∉L(X0),有n≥0的情况发生,因此P{Y∈X(n)/X(0)=X0}=0。
上述中,pm表示变异几率,L(X0)代表初始种群最小规模,X(n)为第n代种群,Y是种群中任意一个个体。
通过上述分析可知,初始种群确定问题的本质是利用有限个体表示空间特征优化。因此种群规模不可随意确定,只有将空间内最优个体作为初始种群,才可以很好的体现空间内部特性。因此在确定种群后需要自适应调整交叉变异概率。
3.1.3 变异概率自适应调整
本文改进传统的AGA(Adaptive Genetic Algorithm)与PAGA(Prominent Adaptive Genetic Algorithm)自适应交叉变异概率调整方法。假定对第t代种群中第i个个体做交叉变异处理[7],则AGA方法中变异几率计算公式如下
(1)

(2)
式中,f′t表示未交叉的个体中较高的适应度值,k1、k2、k3与k4是[0,1]区间的数,k3、k4高于k1、k2。在此种算法中,自适应度值越高,参与交叉变异的几率就越低。因此有利于在进化过程中保存较多优质个体,但是其中一些优质个体无法参加遗传操作,易产生早熟现象。
而在PAGA中,适应度值越高,参与交叉操作的可能性就越大,其交叉概率计算公式表示为

(3)
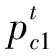
研究上述两种算法,得出产生问题的主要原因是这两种方法均没有分析整个种群进化情况[8]。在进化初始时期,种群差异性较大,自适应值也相对较大,但为使优良模式传播效果更好,对自适应度值较高的个体定义更大的交叉几率。在进化后半段,交叉概率随交叉效果的下降而下降,此时应该保存更多较优个体。
综合上述分析,本文使用种群活力改进上述方法,提出一种新的自适应变化规则:
式(4)定义的是交叉概率变换准则,在进化初始阶段,优质个体可以得到有效传播,在进化后半段,能实现对优质个体的保护。式(5)描述变异几率自适应变换准则,取值大小与种群活力程度相关。当种群活力程度较低时,变异几率取值应较大,以此控制种群变坏。

(5)
式中,pc1、pc2、pc3、pm1、pm2分别表示原始设置的交叉变异机率;θ(t)代表第t代种群活力程度指标,kc1与kc2均属于交叉调节系数,取值范围分别是[1,5]与[5,10]。km使变异调节系数,取值为[1,5],γ的取值在[0.1,0.5]之间,σ∈[1,10]。
3.1.4 并行变异处理
经过上述变异概率自适应调整后在规定取值范围内形成一个随机数,以此替换初始数据。但此数据存在一定随机性,得到的结果对收敛精度改善并不显著,无法有效提高局部寻优能力。因此提出并行机理对变异操作进一步优化。
假设将对第t代任意个体x进行变异处理,则
x1=r(xmax-xmin)+xmin
(6)

(7)
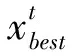

如果连续多代个体平均适应度差值低于设定的阈值时,则认为此种群已经没有继续计划的趋势,可终止算法,并选择适应度最大的个体做并行解码操作[9],此时即可获得软件安全性要求的最佳属性结合,可将其当作下一步测试模型的输入。
3.2 软件安全性测试模型构建
在利用改进的遗传方法进行软件安全性度量性选择后,构建安全测试模型。
当网络环境为开放性时,利用一个四叉树模型代表软件的分布特性,通过三元组SC=(Ex′,En′,He′)代表软件属性数值特性。设定集合O为在n′维论域μ中的软件指标参量,因此O的四叉树可表示为

(8)
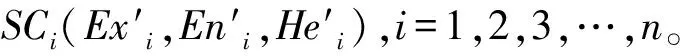

(9)

(10)

(11)
式中a为常数。
经过以上设计,完成软件安全测试模型的构建,利用该模型能够测试出软件安全状况。
4 实验结果与分析
为证明本文提出的软件安全性测试方法性能,从三个不同软件中挑选1000个样本当作仿真目标,其中可疑样本数量为300,训练数量为700,本文确定的安全性度量属性如表2所示。

表2 安全性度量属性表
利用改进的遗传方法获得种群多样性与邻近代迭代种群多样性变换曲线分别如图2与图3所示。

图2 种群多样性

图3 邻近代种群间相似度
从图2与图3中可以看出,随着迭代次数的不断增加,种群多样性趋势下降,但是相邻迭代种群之间相似度不断提升,证明本文方法选取的安全性度量属性较为合理。
将交叉与遗传概率分别设置为0.8与0.3,初始迭代次数为60,最大迭代次数为600,在此环境下,利用本文方法、文献[1]方法、文献[2]方法测试软件可疑点数量,并对测试错误率进行对比。
由表3可知,在相同网络环境下,所提方法可发现更多软件存在的可疑点。这是因为所提方法全面分析软件异常特征,因此在测试过程中综合考虑各种异常状况,提高脆弱点发现几率。

表3 不同方法可疑点测试结果对比表

图4 不同方法软件可疑点测试错误率
从图4可以看出,在所有可疑点测试结果中,本文方法测试的错误率最低。这是因为所提方法在遗传算法中引入并行机理,获取安全性要求的最佳属性结合,提高了算法变异能力,避免陷入局部最优,大幅度提升了测试的精准度。
5 结论
本文改进遗传算法,利用并行变异处理,提高局部寻优能力,更全面发现软件可疑点,提高测试精度,将软件安全问题造成的损失降到最低。
