徽派建筑知识图谱的半自动化构建
2021-11-18张润梅杨超尹蕾张媛
张润梅,杨超,尹蕾,张媛
(1.安徽建筑大学 机械与电气工程学院,安徽 合肥 30601;2.安徽建筑大学 电子与信息工程学院,安徽 合肥 230601)
将传统建筑的特征元素融入到现代建筑设计中是实现传统建筑传承的必要手段,也是弘扬传统文化的有效途径。传统建筑及其构件本身具备独特的美感,且类型丰富,数量巨大,通过传统的手段获取所需的传统建筑数据信息是一件费时费力的工作。2012年,谷歌正式提出知识图谱的概念,旨在实现更加智能化的搜索引擎。随着人工智能和大数据技术的不断发展和应用,知识图谱已在多个领域得到了广泛应用,如智能搜索、智能问答、个性化推荐等。目前基于知识的智能问答和推荐系统有很多,如苹果手机智能语音助手Siri、科大讯飞的讯飞开放平台等,但基于传统建筑知识库构建智能化推荐和搜索系统的研究尚不多见。因此,构建传统建筑知识图谱是实现大规模知识管理和应用的基础,具有重要的研究意义与应用价值。
近年来,特定领域知识图谱构建的研究受到研究者的广泛关注。祁志武将知识图谱与地质标本相结合,通过七步法构建了地质标本知识本体,实现了地质标本知识图谱的构建。王良萸针对碳交易领域的半结构化和非结构化数据,分别采用自定义的Web数据包装器,结合BiLSTM-CRF模型与依存句法分析实现了三元组抽取,构建了碳交易领域知识图谱。汤洁提出了一种基于启发式规则的网页正文内容抽取算法,并提出基于最短路径算法和深度优先搜索算法来分析金融市场中各实体之间的关系。
目前,很多专业领域已完成了知识图谱构建,且基于知识图谱的各类应用开发也得到迅速发展。国内外很多大公司通过知识图谱来提高服务质量,如金融知识图谱、医学知识图谱、化学知识图谱等。在建筑领域更多针对聚落基因图谱开展相关研究,如秦为径等人对凉山彝族地区的乡土景观基因要素进行提取、分类和编码,完成了凉山彝族地区乡土景观基因图谱信息链的构建。聂聆通过对徽州古村落景观特征进行研究识别,构建了徽州古村落景观基因图谱。翟洲燕等人通过对陕西省35个传统村落的分析,识别并提取了传统村落文化遗产景观基因,绘制了陕西传统村落文化遗产景观基因组图谱。但以上均未形成完整的、专业的知识图谱。
徽派建筑形成于宋,成长于元,至明清达到鼎盛,是中国传统建筑的重要组成部分。徽派建筑种类繁多,建筑形式多样,时间跨度大。要实现数据有效整合,自动构建徽派建筑知识图谱存在诸多困难。本文从分析徽派建筑现存资料入手定义了徽派建筑知识图谱的概念层,通过对异构数据过滤、清洗、解析、进行实体、属性以及关系的抽取,并通过构建徽派建筑领域词典,结合先验知识提升了BiLSTM-CRF模型的实体识别效果,通过Neo4j图数据库实现知识的表示、存储并用Cypher实现知识查询。
1 知识图谱构建相关技术
1.1 命名实体识别
命名实体识别作为自然语言处理的一项基础技术,其主要任务是识别出文本数据中的专有名词和有特殊含义的词并将其归类到已定义的类型中。命名实体识别有基于规则的方法、基于大规模语料库的统计方法和基于机器学习的方法三种基本方法,本文采用的是基于机器学习的方法。
1.2 条件随机场模型


λ
是对应的权重。上式表示在输入数据序列m的条件下,得到输出序列n的概率。1.3 长短期记忆网络模型
长短期记忆网络模型(Long Short-Term Memory,LSTM)是对循环神经网络模型(Recurrent Neural Network,RNN)改进后的特殊形式的模型,由Hochreiter等人于1997年提出,主要思想是通过改变RNN中的隐藏层机构,采用门结构方式控制RNN中信息的传播方式,通过不同门结构来控制信息的输入、遗忘、变换、输出等过程。LSTM的缺点是无法完整获取语句的上下文信息,因此,研究者们采用双向长短记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)方法。
1.4 BiLSTM-CRF模型结构
将CRF模块作为BiLSTM模块的输出层,解决了字向量经过BiLSTM层后可能得到无效标签序列的问题。CRF层将BiLSTM层输出的标签数列进行集中解码,获得整个句子的序列标注,而不是仅对单一标签进行单独的解码。BiLSTM模型加入CRF层后可以考虑到不同类型标签之间的关联性,使得输入的数据序列经过模型处理后可以得到一个最优的标签序列。BiLSTM-CRF模型结构图如图1所示。

图1 BiLSTM-CRF模型结构图
2 徽派建筑知识图谱的半自动化构建
徽派建筑知识图谱的构建分为四个步骤,如图2所示。

图2 徽派建筑知识图谱构建流程图
(1)概念层的构建。本文采用传统的自顶向下的方法构建了徽派建筑知识图谱的基本概念层。
(2)利用结构化、半结构化以及非结构化的数据,包括网页数据,现有数据库等抽取实体、属性以及关系,然后进行命名实体识别。
(3)知识表示。徽派建筑知识图谱使用属性图为基本的表示形式。
(4)知识存储。使用Neo4j图数据库存储徽派建筑知识数据。
2.1 概念层构建
概念层构建是对徽派建筑知识图谱主体框架的构建,需要定义类及类之间的关系,即对知识图谱中的概念及概念之间的语义关系进行定义。
本文构建的是徽派建筑知识图谱,以民居、祠堂为主,设计并构建了徽派建筑领域知识图谱的概念层,主要从建筑基本信息、建筑平面信息、建筑立面、建筑空间分布、雕刻、文化特色六大类进行定义。
概念类通过相关属性进行详细描述,传统建筑基本信息属性包括建筑名称、类型、坐落位置、建造时期。建筑平面的属性包括建筑开间、布局、外观。立面属性包括马头墙、门楼。空间属性有檐高、屋脊高度、院落进数和拼接方式。雕刻属性包括石雕、砖雕、木雕。徽派建筑知识图谱模式层如图3所示。
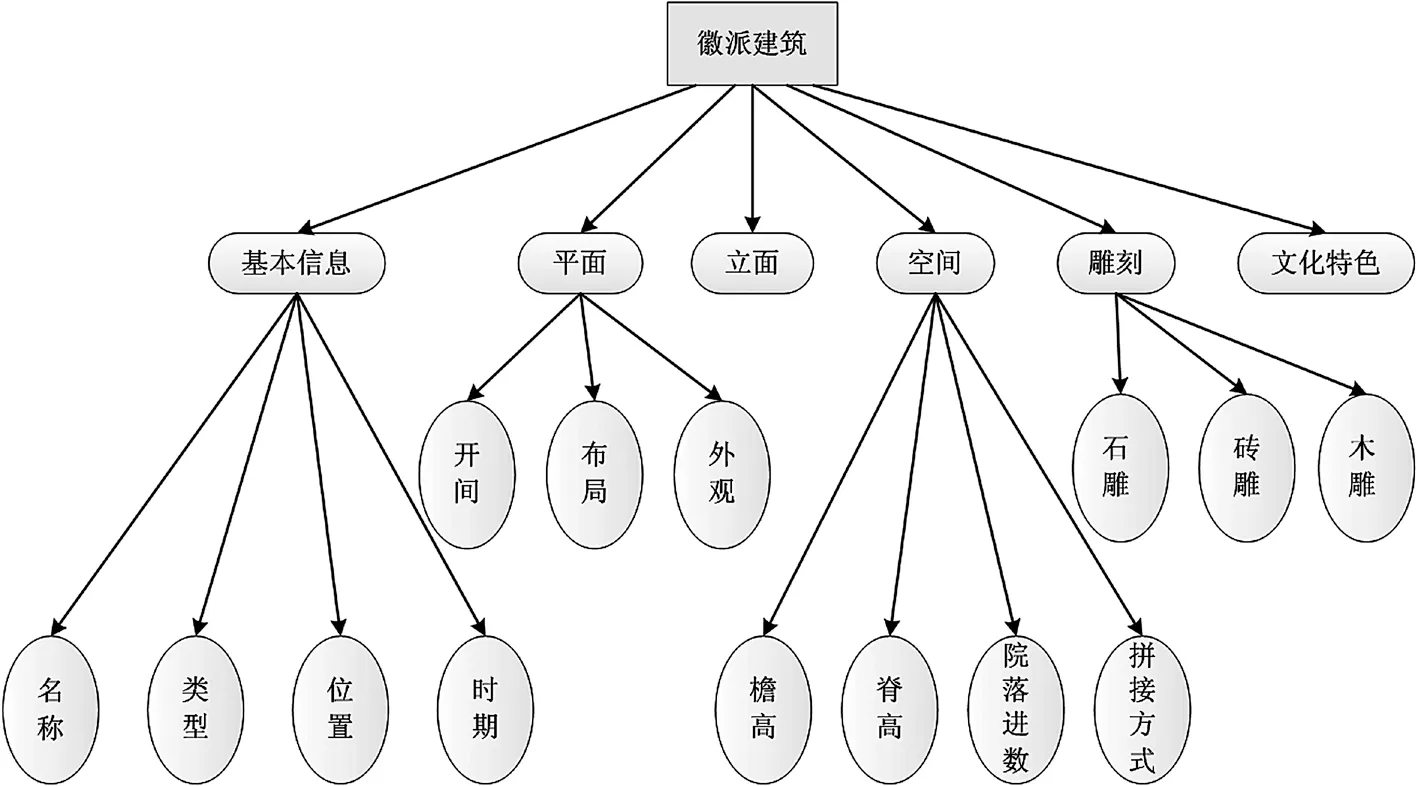
图3 徽派建筑知识图谱模式层
2.2 基于BiLSTM-CRF模型的命名实体识别
从获取到的原始数据文本中获取实体是构建徽派建筑知识图谱的关键步骤,基于神经网络的命名实体识别模型已在通用领域中广泛使用。神经网络模型方法的优势在于可以对数据特征进行自动提取,而且训练模型的过程是端到端的,生成的模型可以直接用于命名实体识别。因此,本文采用BiLSTM-CRF学习框架与徽派建筑词典相结合的方法,对徽州传统建筑的命名实体进行识别。图4为徽派建筑命名实体识别关键技术框架图。
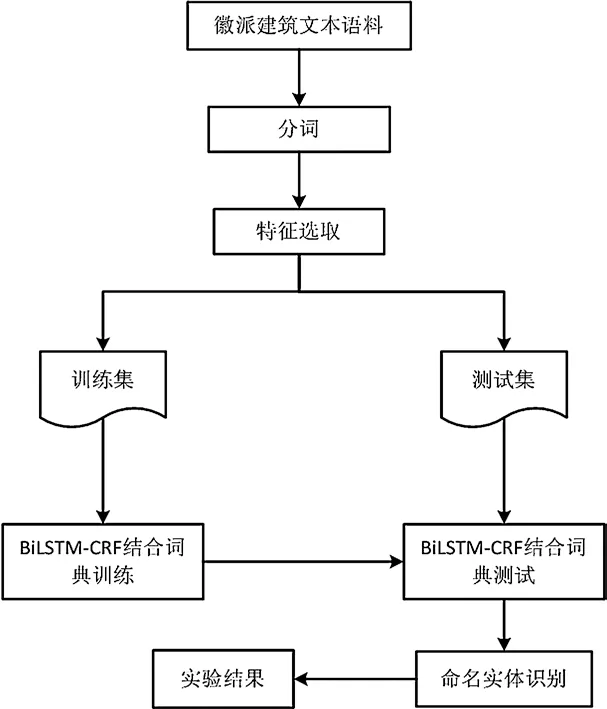
图4 徽派建筑命名实体识别关键技术框架图
2.2.1 分词
本文选择基于中文语料库的CorpusWordParser进行分词。CorpusWordParser基于现代汉语通用平衡语料库开发,具有中文分词和词性标注等功能,用户可以自行添加词表来增强分词效果。分词结果如图5所示。

图5 分词结果图
2.2.2 数据搜集与处理
由于目前缺乏用于徽派建筑命名实体识别的公开数据集,本文通过实验室已建成的数据库及百科词条构造了徽派建筑语料库,语料库涵盖了徽派建筑典型的建筑类型。另外,实验室已建成的国内唯一的徽州传统建筑特征元素数据库,收集了近百种建筑构件相关数据近万条,徽州地区100多个聚落、万幢建筑的相关信息。本文的实验数据来自经过整理分析的数据库数据和相关徽派建筑百度百科词条信息。
本文抽取了168个描述徽派建筑文本,将其中80%的样本数据作为训练集,20%作为测试集。当训练出的准确率达到设定的标准后,用训练好的模型从168条文本中抽取徽派建筑的实体,使用BRAT文本标注工具进行数据标注,对获取的语料进行数据格式转换。按照BIO格式对语料进行标记,标记为:B、I、O,分别表示实体的首字符、中间字符和非建筑名词。
2.2.3 BiLSTM-CRF与徽派建筑词典相结合的命名实体识别
通过对《中国古代建筑辞典》的参考分析,构建本文所需要的徽派建筑词典,通过词典来获取非结构化文本中的语料类别信息,把获取的信息作为特征值传递给BiLSTM-CRF模型去识别数据中的徽派建筑实体,类别信息如表1所示。本文将描述徽派建筑的数据分为两类,一类是描述徽派建筑的术语,标记为“HA”。其他非建筑术语,标记为“HO”。

表1 类别信息
2.2.4 实验与结果
实验抽取168条非结构化文本数据,任意选取其中的130条数据进行命名实体识别。将100条数据作为训练样本,30条数据作为测试样本。为了缓解模型存在过拟合性,将BiLSTM模型网络输入与输出端的Dropout rate值设为0.5,实验结果如表2所示。

表2 识别结果统计
为了判别BiLSTM-CRF模型结合徽派建筑词典特征的性能,分别进行了BiLSTM模型、BiLSTMCRF模型和BiLSTM-CRF模型结合徽派建筑词典特征的对比实验。根据表2的实验结果可以看出,结合词典特征的BiLSTM-CRF模型比其他两组实验,在准确率、召回率和F1值上都取得了最好的效果。BiLSTM-CRF模型比BiLSTM模型效果好,是因为BiLSTM-CRF模型能够利用上下文的语义信息以及相邻标签间的关系,产生更优的标签序列。结合徽派建筑词典特征的BiLSTM-CRF模型比单独使用BiLSTM-CRF模型准确率提升了3.49%,召回率上升了1.34%,F1值提高了2.41%。分析实验结果发现,在徽派建筑训练数据集中没有明显特征的建筑名词被结合词典的BiLSTM-CRF模型准确地识别了出来,体现了作为先验知识的词典对实体识别起到了重要的辅助作用。例如佛塔,在徽州区,塔主要指的是村口的风水塔,如黟县柯村乡的旋溪塔。佛塔的相关数据不多,在本文的训练样本中没有描述佛塔的术语,但是徽派建筑词典能准确的识别出此类建筑术语,利用这些建筑术语的语料信息为BiLSTMCRF模型提供支持,使得识别效果更好。
因为实验在准确率、召回率和F值上都取得了比较好的效果,因此,本文利用结合徽派建筑词典的BiLSTM-CRF模型,对168条非结构化数据进行徽派建筑实体的抽取,共抽取出504个徽派建筑实体。
2.3 知识表示
知识图谱是一种网络结构图,实体就是图里面的节点,实体之间的关系就是图的边。知识图谱有两种表示形式:三元组和属性图。本文采用Neo4j图数据库来存储徽派建筑领域知识,用属性图模型表示知识。
属性图模型就是顶点、边、标签、关系类型和属性组成的有向图。实体可以表示成一个或多个键值对形式的属性:
(1)顶点。每个顶点具有一个唯一的ID,每个顶点还有一个实体类,表示顶点所对应的概念类型,每个顶点属性的集合通过键值对来表示。
(2)边。每一条边都有一个唯一的ID,每一条边都有一个头结点和尾结点。同时,每一条边有一个实体类type,表示头节点和尾结点的关系,每条边也由键值对来定义边属性集合。
图6为Neo4j的一个实体属性图模型,实体大菩萨厅和空间布局串联之间的关系是拼接方式。其中,id是实体的位置符号,是其唯一的标识符;type表示实体类别;start表示头结点id;end表示尾结点id;name表示对应节点属性描述。

图6 实体的属性图模型
2.4 知识存储与可视化展示
本文采用的是Neo4j图数据库来存储数据。Neo4j是一个高性能的、基于Java语言开发并且开源的图形数据库,它将结构化数据存储在灵活的、面向对象的网络结构中而不是表格中,它还具备了完整的数据库特性。通过对知识图谱进行可视化展示,使得用户更加直观、清晰地了解实体之间的关联规则。
将提取出的徽派建筑的建筑实体以及实体与实体之间的关系等数据信息全部整理成结构化的数据,并设置相应的概念类存储在CSV格式的文件中,如表3、4所示。然后将所有的CSV文件通过Cypher导入到Neo4j图数据库中,即完成了徽派建筑知识图谱的数据存储。

表3 徽派建筑实体在CSV文件中的录入格式

表4 徽派建筑实体、类型实体及两者关系在CSV文件中的存储格式
将徽派建筑知识数据存储到Neo4j图数据库后,图7徽派建筑知识图谱(节选)中紫色圆圈表示建筑类型实体,深蓝色圆圈表示建筑实体,连接建筑类型实体与建筑实体之间的线段表示这些实体之间相对应的关系。图中展示了包括民居、祠堂、牌坊等16种不同的建筑类型,每种建筑实体展示出了建筑位置,开间及门楼形式等信息,同时介绍了徽派建筑著名的三雕技术,包括7种雕刻手法,形式多样的雕刻内容和装饰位置等信息。Neo4j图数据库使用Cypher语言对数据库进行增删改查操作,实现了对每一座建筑的检索、遍历等功能。

图7 徽派建筑图谱(节选)
3 结论
本文详细描述了在传统建筑领域通过数据抽取来构建徽派建筑知识图谱的方法,并介绍了徽派建筑知识图谱的构建流程。针对徽派建筑数据异构多源和非结构化的特点,提出了BiLSTM-CRF模型结合徽派建筑词典的方法来对徽派建筑实体进行识别抽取。实验结果表明,在先验知识的辅助作用下,实体识别的效果更好。在获取到徽派建筑的知识之后,利用Neo4j数据库存储知识,用属性图模型表示知识。最后利用Neo4j图数据库可视化地展示了构建的徽派建筑知识图谱。本文所构建的徽派建筑知识图谱,为研究徽派建筑知识的智能化推荐和搜索系统奠定了基础。
