多种AI算法在新冠疫情文本情绪识别中的实践
2021-11-17仇建民
仇建民
中国电信股份有限公司江苏分公司
0 引言
1 任务分析
1.1 任务背景
新型冠状病毒(COVID-19)感染的肺炎疫情牵动着全国人民的心。习近平总书记指出:要鼓励运用大数据、人工智能、云计算等数字技术,在疫情监测分析、病毒溯源、防控救治、资源调配等方面更好地发挥支撑作用。为助力疫情防控和疫情之后的经济社会恢复工作,北京市经信局主办了一场科技战疫公益挑战赛。为了帮助政府掌握真实的社会舆论情况,科学、高效地做好防控宣传和舆情引导工作,本赛题针对疫情相关话题开展网民情绪识别的任务。
1.2 任务说明
给定微博文本内容,设计算法对微博内容进行情绪识别,判断微博内容是积极的、消极的还是中性的,是文本三分类任务。
2 实验
2.1 数据准备
2.1.1 数据预处理
为保证后续各类算法实验对比的公平,数据统一进行预处理,后续各类算法均使用处理后的标准数据集。本文使用了以下4种数据预处理方法:(1)数据去噪。只保留微博内容、情感倾向两个字段,并删除空值、异常值等无效数据。(2)去除标点符号等特殊字符。因微博存在表情等数据会变成特殊字符,故统一删除字符,只保留中文、英文、数字,并将多余重复的空格合并为一个空格。(3)繁体字转简体字。将全部繁体字转换为简体字。(4)去除微博中无意义的词语。因为微博场景的特殊性,删除“展开全文”“网页链接”“转发微博”等微博特定词汇。
预处理完成后,最终的样本由原始的100 000条文本,缩减为99 373条文本。
2.1.2 划分相同的训练集、验证集
将预处理完成的数据集拆分为训练集(79 498条,占比80%)、验证集(19 875条,占比20%),为确保在后续的各类算法实践中,使用完全相同的训练集和验证集。使用sklearn.model_selection中的train_test_split进行训练集和验证集的划分,通过设置随机种子确保每个模型的训练集和验证集保持一致。
sklearn代码如下:
包括聚维酮碘,季铵盐络合碘和三碘氧化合物。聚维酮碘和季铵盐络合碘消毒效果受有机物影响很大,所以均不能作环境消毒,但可作饮水、皮肤和器械消毒。只有三碘氧化合物可作环境和带动物消毒。
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2,random_state=1
2.2 建模及调优
2.2.1 评价指标说明
选取19 875条验证集的准确率(accuracy)作为评价指标。计算公式:

可见,准确率越高,证明模型越好。
2.2.2 机器学习算法实践
(1)机器学习算法建模、调优。本文在机器学习算法上采用了5种模型组合,分别为:CountVectorizer+MultinomialNB、CountVectorizer+BernoulliNB、TfidfVectorizer+MultinomialNB、TfidfVectorizer+BernoulliN、TfidfVectorizer+LightGBM。
模型调优思路如下:首先,CountVectorizer、TfidfVectorizer调优:通过设置ngram_range参数,分别取(1,1)、(1,2)、(1,3),用来观察一元模型(unigrams)、二元模型( bigrams)和三元模型(trigrams)。其次,MultinomialNB、BernoulliNB调优:通过穷举alpha,alpha从0.01开始,步长为0.01,到1结束,轮询100次,选择准确率最佳的模型。最后,LightGBM调优:以验证集的准确率为指标,通过早停(earlystopping)功能获取准确率最佳的模型。
需要说明的是:TfidfVectorizer+LightGBM实践中,由于笔者算力有限(机器内存较小),ngram_range=(1,2)以及ngram_range=(1,3)未能尝试,这两个模型运行时由于内存溢出而报错。
(2)机器学习算法对比结论。以上5种算法的最佳准确率对比如图1所示。从实验结果可以得出以下结论:首先,TfidfVectorizer+LightGBM准确率最佳,为72.88%,且在ngram_range=(1,1)参数下,LightGBM准确率显著超过MultinomialNB和BernoulliNB。其次,在另一个算法确定的情况下,TfidfVectorizer的准确率显著超过CountVectorizer,说明在文本特征提取上,TfidfVectorizer优于CountVectorizer。最后,在另一个算法确定的情况下,MultinomialNB的准确率显著超过BernoulliNB,说明MultinomialNB更合适文本分类场景,BernoulliNB可能更适用于数据符合伯努利分布的场景。
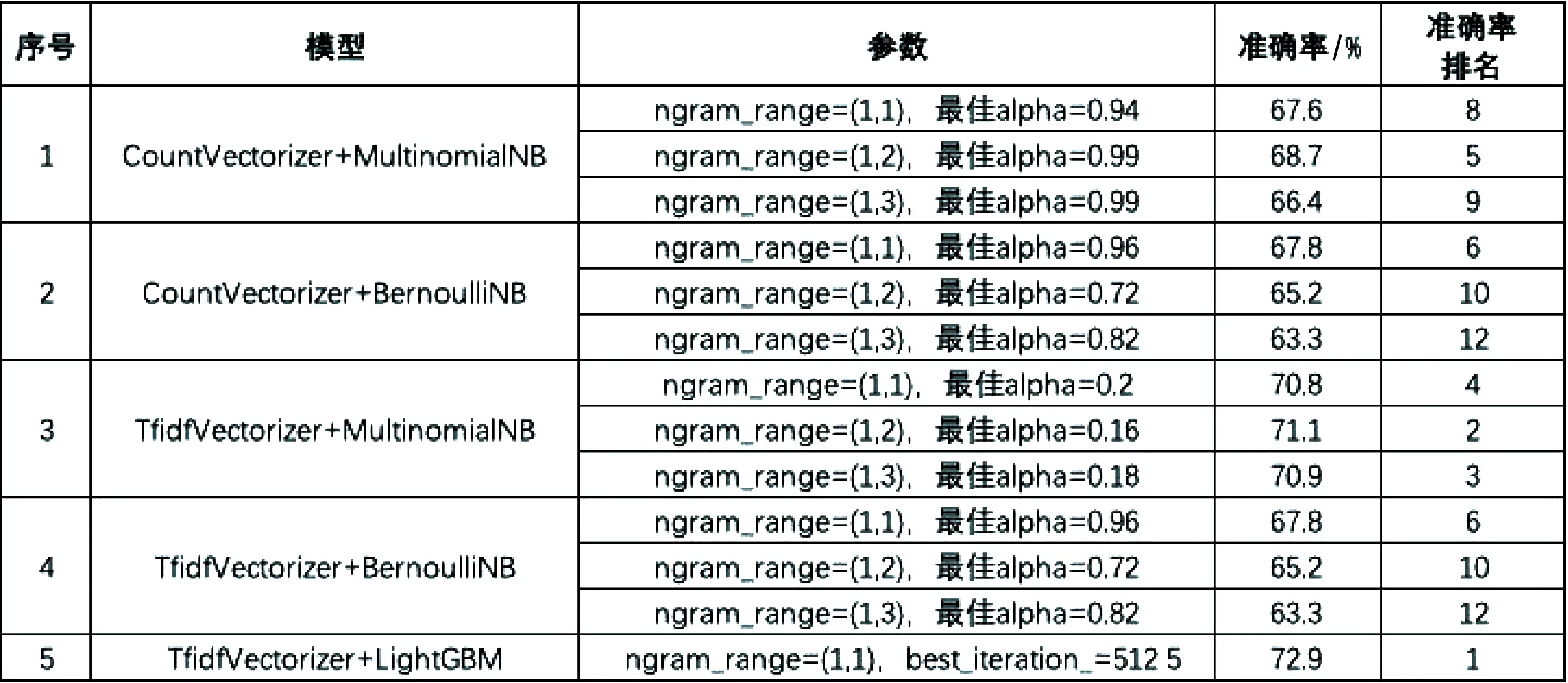
图1 机器学习算法在此案例中的准确率对比
2.2.3 深度学习算法实践
(1)深度学习算法建模、调优。
通过Word2Vec算法对数据集的语料进行训练,设置词向量维度为128维,迭代训练15轮,训练完成后得到78 486个词汇及词向量。选取部分词汇及词向量,比如“武汉”“肺炎”,通过相似度匹配,找到相似度Top10的词汇,发现基本符合常识。
模型调优思路:第一,考虑到双向序列模型可以考虑整个句子的信息,即使在句子中间,也可以综合考虑过去的信息和将来的信息,因此在网络层使用BiGRU(双向GRU)代替GRU(Gate Recurrent Unit)。第二,为避免模型过拟合,超过2个epoch验证集的准确率若无提升,则将学习率减半;超过4个epoch验证集的准确率若无提升,则earlystopping。
根据以上思路,本文在深度学习算法上采用了2种模型组合,分别为Word2Vec+BiGRU、BERT(Bidirectional Encoder Representation from Transformers)+BiGRU。
(2)深度学习算法对比结论。
两种组合模型在训练集和验证集的准确率分布情况如图2所示。实验结果对比如图3所示,可以得出以下结论:预训练好的BERT模型在Embedding层的效果显著优于Word2Vec。

图2 Word2Vec+BiGRU、BERT+BiGRU实验结果

图3 深度学习算法在此案例中的准确率对比
2.3 实验结果汇总对比
综合以上机器学习和深度学习算法实践结果,汇总7种组合模型,选取每种模型在验证集的最佳准确率进行对比,结果如图4所示。由准确率可以发现:深度学习2种算法的平均准确率为74.3%,远超过机器学习5种算法的平均准确率69.7%,且深度学习算法最低准确率为73.5%,也超过机器学习算法的最高准确率72.9%。在机器学习算法中,TfidfVectorizer准确率高于CountVectorizer;MultinomialNB准确率高于BernoulliNB;LightGBM准确率高于朴素贝叶斯。深度学习算法中,BERT准确率高于Word2vec。

图4 机器学习、深度学习算法在此案例中的准确率对比
3 结束语
本文使用了比赛主办方提供的公开数据,并拆分为训练集和验证集,使用验证集的准确率作为评价指标,使用7种机器学习、深度学习模型进行文本分类并分别进行调优,得出以下结论:(1)在文本分类任务上,深度学习算法相比机器学习算法有较为明显的优势。(2)在机器学习算法中:在文本特征提取上,TfidfVectorizer优于CountVectorizer;MultinomialNB相比BernoulliNB更合适文本分类场景;LightGBM集成模型分类效果优于朴素贝叶斯。(3)在深度学习算法中:预训练好的BERT模型在Embedding层的效果优于Word2Vec。(4)综合以上,BERT+BiGRU准确率最高,为75.1%,最终选取BERT+BiGRU为预测模型。后续可以BERT+BiGRU模型为基础,在具体的神经网络层进行改进调优,进一步提升文本分类的准确率。
