基于神经网络的无人机影像多目标检测方法
2021-11-17杜祥宇
杜祥宇
(1. 北京市测绘设计研究院, 北京100038; 2. 城市空间信息工程北京市重点实验室, 北京 100038;)
0 引言
无人机平台相对于光学遥感卫星而言更具有高时效性、低成本等优势,因而在区域测量,电力巡检,城市规划,以及应急测绘等应用场景下选择利用无人机采集区域内的影像并进行目标检测与提取是更高效的解决方案。基于无人机影像进行目标的检测与识别一直以来都是热点研究内容。早在2015年,张辰等[1]就提出了以无人机视频为基础,在目标感兴趣区域(Reign of Interest,ROI)内使用Shi-Tomasi算法进行角点提取,然后通过金字塔Lucas-Kanade进行目标检测跟踪的方法,结果表明其结果鲁棒性强且易于实现;汤轶等[2]提出了一种利用加速稳健特征(Speeded Up Robust Features, SURF)和随机抽样一致算法(Random Sample Consensus, RANSAC)算子对背景运动补偿,并基于卡尔曼滤波的目标检测跟踪算法,经实验证明该算法具有很好的实时性与准确性;2018年,李大伟等[3]在场景感知的基础上采用ROI外加融合梯度响应的显著性目标检测方法,该方法在公路场景下可以达到80.43%的准确率。
深度学习技术的兴起为很多传统行业带来了技术性的变革。在无人机影像目标检测领域,卷积神经网络模型因其在检测精度方面的优势得到快速的推广使用。2019年,裴伟等[4]基于改进(Single Shot MultiBox Detector, SSD)算法对航拍目标实施检测,该算法最高可以取得87.8%的准确率;同年,李喆等[5]提出了一种基于候选区域的无人机侦察影像目标检测算法;郭敬东等[6]提出了一种基于 (You Only Look Once, YOLO)算法的无人机电力巡检图像检测算法,在实际的测试中取得了很高的精度与实时性;2020年,曾荻清等[7]以无人机航拍数据为基础利用(You Only Look Once v3,YOLOv3)算法和相邻角度平均算法进行车辆及车道线的检测,进而实现对车辆压线行驶行为的探测,其实验结果相比传统方法具有更高的精度。目前,基于深度学习的无人机影像多目标检测方法已经在精度方面远高于基于人工检测算子以及机器学习的传统手段。因此,本文基于深度学习理论提出了由端到端卷积神经网络构建的多目标检测方法,然后以开源无人机影像数据集VisDrone2019-DET为数据源,利用直方图均衡化等算法进行图像增强处理,制作了增强的无人机目标检测数据集,并以此数据集对所提出的算法及几种对比算法进行训练,在同一测试集上对所有算法进行测试,并采用精度均值(Average Precision, AP),平均精度均值(mean Average Precision, mAP)以及检测速度每秒传输帧数(Frames Per Second, FPS)对所提出方法的整体性能进行综合评价。
1 无人机目标检测网络
本文所提出方法采用基于回归的网络结构设计构建了高分辨率遥感影像检测网络。基于回归的目标检测网络采用端到端的设计思想,即网络的一端输入原始影像,另一端直接输出检测框的位置与类别信息。相比基于候选区域的网络模型,该结构的网络更为简单,因此在检测速度及算力需求方面均优于前者[8]。基于回归的网络结构由特征提取模块、特征增强模块以及检测头三部分组成。其中特征提取骨干网络负责将输入网络的影像进行逐层下采样,输出不同尺寸和通道数的特征图,特征强化模块的作用是通过对小尺寸特征图进行上采样和特征图拼接来增强原始特征图中的语义信息,检测头则负责输出最终的检测结果。
1.1 特征提取骨干网络
特征提取骨干网络由负责特征提取的卷积核及下采样的操作层采用自上而下的结构拼接而成,本文所提出方法采用一个3×3和1×1的卷积核来实现特征提取和通道操作功能,其中3×3的卷积核位于上层,对每个由上层输入的特征图采用卷积步长为1的操作进行特征提取来生成新的特征图,然后由大小为1×1的卷积核同样采用步长为1的操作进行通道扩张。为避免使用池化层进行下采样操作而产生的特征信息过度丢失,因此采用3×3的卷积核进行步长为2的卷积操作对图像进行2倍下采样。为了减弱由网络层数过深而导致的内部协变量偏移(Internal Covariate Shift,ICS)问题[9],在每个特征提取层后面添加一个批量再规范化层(Batch Renormalization,BRN)来保证模型在训练过程中不因为上层的输入数据分布不均匀而产生发散,同时也保证了模型在训练和测试的极端可以基于单个样本而非整个minibatch而生成同样的输出。为了增强输出特征的非线性映射能力,使用扩展指数线性单元(Scaled Exponential Linear Unit, SELU)作为激活函数,具体如公式1所示:
(1)
式中,x为上层输入值;α=1.05和β=1.67均为经验参数。
在传统的前馈结构基础上,本文所提出方法在骨干网络中额外添加了密集连接来进一步强化不同特征层之间的信息流通,密集连接的方式具体如公式(2)所示:
xi=Hi[x0,x1,x2,…,xi-1]
(2)
式中,xi表示第i层的输出;Hi表示第i层的卷积变换。最终的骨干网络层数为49层。
1.2 特征增强模块
为了获得语义信息更为丰富的特征图,在特征提取骨干网络的末端连接特征增强模块。
根据目标在无人机影像中的大小特点,本文所提出方法设计了一个四层的特征增强模块,采用子下而上的特征图金字塔结构[10],每层的操作均为步长为2的上采样层。在进行四次上采样的同时,还采取两种不同的路径来丰富特征图中的语义信息。首先是横向连接,即采用add连接的方式将上采样后的特征图与特征提取骨干网络中的图像进行拼接,其次是密集连接,在特征增强模块中同样采用Concatenate连接将不同上采样层的特征图进行连接。最终输入到四个不同的检测末端进行检测,在获得多个近似结果后,采用非极大值抑制(Non-Maximum Suppression, NMS)算法获取唯一的最佳检测框。
模型的训练损失函数由目标框定位损失函数以及类别判断损失函数,具体如公式(3)所示:
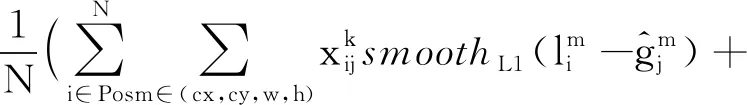
(3)
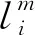
2 实验与结果分析
为验证本文所提出方法在精度方面的优势,本文将在同一数据集上分别对YOLOv3,SSD,R-FCN算法以及本文提出方法进行训练和测试,并使用AP,mAP与FPS三种指标对模型的检测精度于检测速度进行客观评价。
2.1 数据集构建
本文以开源数据集VisDrone2019-DET为基础进行模型的训练与测试。为了让训练后的模型泛化能力更强,有必要采用数字图像处理手段对图像进一步进行增强处理。本文所提出方法采用直方图均衡化算法等算法对原始数据集中的影像进行强化处理,结果如图1所示。处理后的数据集共有3 615张影像,其中3 268张为训练数据集,347张为测试集,数据集中目标的类别及数量情况如图2所示。

图1 数据集增强处理

图2 训练数据集样本数量分布图
2.2 模型训练
本文所提出方法使用Pytorch作为深度学习框架来实现具体模型的构建,为了进行客观评价,训练与测试均在同一环境下进行,具体的配置环境如表1所示。在训练过程中模型迭代次数为5 000次,所采用具体的训练参数如表2所示。

表1 训练环境配置表
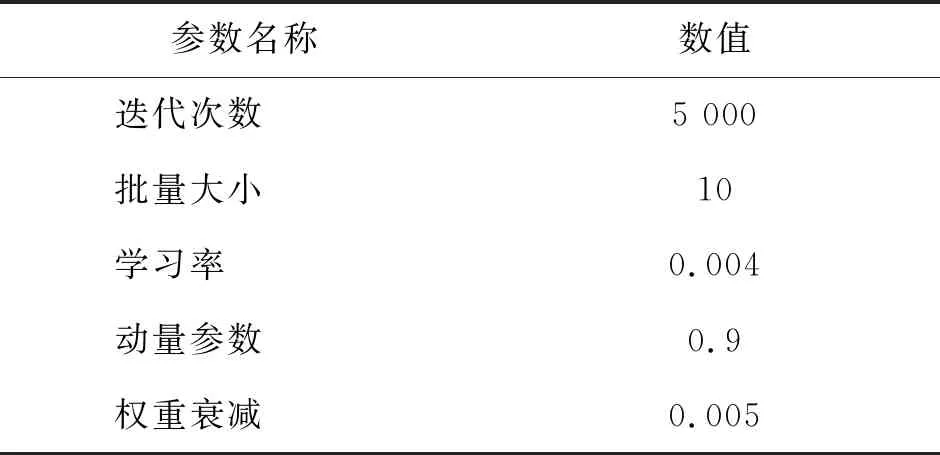
表2 训练参数表
2.3 结果分析
随着训练迭代次数的增加,对应的损失曲线如图3所示。从图中可以看出,在初始损失制较大的情况下,本文所提出方法在训练过程中能迅速收敛并在整个训练过程中保持损失下降趋势。

图3 迭代损失曲线示意图
在测试集上的部分检测结果如图4所示。在相同的运算环境下使用训练数据集分别对YOLOv3,R-FCN,SSD模型进行训练,然后采用每一类目标的AP以及三种模型的平均精度均值对模型检测精度进行评价,最终结果如表3所示。
从图4中可以看出,本文所提出方法对于影像中不同分布位置,不同类别以及不同大小的目标均有比较好的检测效果。

图4 检测结果示意图
根据表3的中评价结果可以看出,本文所提出方法在精度均值方面最高可以达到93.52%,对于在影像中分布较为稀疏的小个体行人目标也能够达到89.75%的检测精度,并且平均精度均值可以达到89.57%,相比YOLOv3在综合检测精度方面提高了6.53%,相比基于候选区域机制的R-FCN方法在精度方面提高了3.11%,并且在所有类别的检测精度上均优于其余对比算法。说明本文所提出的方法在精度方面具有一定的优势。在检测速度方面,本文所提出方法在测试环境下可以达到每秒27帧的检测速度,虽然相比传统的快速检测算法YOLOv3要低,但是仍然能够满足大部分检测任务对于速度的需求。

表3 检测精度及评价表
3 结束语
针对以无人机航拍影像为对象实施多目标检测时存在的漏检率较高以及泛化能力较差等问题,基于回归结构设计并搭建了卷积神经网络来进行目标的分类与识别,通过在特征提取骨干网络中添加密集连接结构来增强网络不同层次特征的沟通能力,然后利用四层的特征金字塔作为特征增强模块来强化模型对小目标的检测能力。以开源数据集VisDrone2019-DET为基础进行数据强化后,来提高训练后模型的泛化能力。将本文所提出方法与SSD及YOLOv3网络的检测结果对比,得出以下结论:
(1)对于无人机影像中大小不同,分布不均的多种目标,本文所提出方法均能够实施高精度、快速地检测,并且最终的平均精度均值能够达到89.57%,相比的经典的快速检测算YOLOv3和基于候选区域的R-FCN算法在检测精度方面有了明显的提高。
(2)在测试硬件环境下网络的检测速度也可以达到每秒27帧,可以满足大部分实际场景下检测任务对于检测速度方面的需求。
