基于随机森林的沥青路面性能预测
2021-11-17张金喜郭旺达禚永昌张阳光
张金喜,郭旺达,宋 波,禚永昌,张阳光
(1.北京工业大学城市交通学院交通工程北京市重点实验室,北京 100124;2.北京市道路工程质量监督站,北京 100076)
目前,我国交通基础设施建设日趋完善,道路工程由“建”转“养”已成为当下发展的必然趋势.路面性能预测是路面养护与管理的重要内容,精确地把握沥青路面关键性能指标的衰变情况,有利于针对最佳的养护时机,制定科学的养护决策方案,以发挥路面最大的服役效益[1].路面状况指数(pavement condition index,PCI)作为路面技术状况评定的关键指标之一,用来评价路面的完好程度.因此如何对沥青路面PCI进行更加准确、高效的预测,已经成为路面养护管理领域研究的重要课题.
沥青路面性能衰变是路面在实际服役过程中对引起其原有路面结构或功能改变的因素的反馈.这些因素包括路面结构、交通荷载、自然环境、养护干预等,冗杂繁多,因此表征路面性能的性能指标与其影响因素之间的非线性关系是极其复杂的.针对路面性能预测问题,国内外众多学者研究方法不一.路面性能预测的经典模型是确定型模型,杜艳花[2]、张金喜等[3]通过总结高速公路路面性能指标随时间的变化特点,采用指数型函数对历史数据进行拟合,分别用于预测国际平整度指数(international roughness index,IRI)和路面PCI的衰变情况;肖金平等[4]在分析不同路面结构的基础上,建立了路面性能指标的余弦函数型衰变方程,计算结果与实测结果一致性较好.然而经典研究方法是一般只考虑性能指标关于时间序列的经验预测模型,未能建立路面性能指标与其影响因素之间的非线性关系,与实际路面性能衰变情况匹配度相差较大,并且预测精度随着预测周期的推移会逐渐降低.近年来随着机器学习受到越来越多的关注,针对这种非线性的路面性能预测问题便有了新的研究方向.诸如人工神经网络(artificial neural network,ANN)、支持向量机(support vector machine,SVM)等人工智能方法在路面性能预测领域的出现,解决了传统线性预测模型无法应对性能指标突变的问题.Satish等[5]基于人工神经网络建立平整度预测模型,虽然预测结果优于线性回归模型,但是由于样本集不足导致局部出现过拟合的现象;赵静等[6]将灰色理论与支持向量机模型相结合,综合考虑路龄、交通荷载等因素建立车辙深度指数预测模型,在项目级预测中验证了模型的精度,考虑到支持向量机模型易于表征小样本情况下的非线性映射关系,对于路网级预测的效果仍有待验证.
Breiman提出的随机森林(randorn forest,RF)模型[7],可以有效地处理多因素耦合影响下的非线性回归问题.相较其他机器学习模型,RF的鲁棒性好、预测能力强.RF不仅克服了传统经验模型在处理复杂交互作用的不足,而且与神经网络相比具有更强的抗噪和抗过拟合的能力.此外通过对比选取支持向量机核函数等参数复杂程度,构建RF模型的超参数更容易理解.RF算法已经成功被应用到许多研究领域[8-12].但目前该算法在道路工程领域还未得到充分应用.基于以上分析,本文提出一种基于RF的路面性能预测方法,并与神经网络、支持向量机预测模型的预测能力进行对比,以期找到一种路面状况指数的精确预测方法来指导路面养护管理工作.
1 研究方法
RF算法是一种在决策树的基础上建立的集成学习算法,可以用于解决分类和回归问题.由于其泛化能力强、抗噪性能好,因此在地理[8]、农业[9]、农林学[10-11]、生物学[12]等领域都已经取得了成功的应用和推广.RF对多重共线性不敏感,所以缺失数据和不平衡数据对预测结果的不良影响很小,最多可用数千个特征变量进行准确预测.现阶段RF算法被视作是构建非线性预测模型的最优算法之一.
1.1 决策树回归算法
决策树是RF算法的理论基础,在此对决策树算法进行简要介绍.决策树作为识别重要变量和2个及以上特征变量关系最快的方法之一,可以用于解决分类和回归问题.通常一棵决策树由根节点出发,经由内部节点逐层生长,最终在叶子节点处触发生长阈值而停止生长.其中根节点代表整个总体,决策树通过使用二分递归分割,将样本集合通过相关策略拆分成2个子节点[13].经过逐步拆分,最终由叶子结点输出预测结果.假设存在一个同时包含预测变量和特征变量的训练数据集D,构造决策树回归算法流程如下.
1)遍历全部特征后,找到最优划分特征和分割点(x(j),s),满足均方误差MSE(x(j),s)最小,然后划分为2个节点.
2)对生成的2个节点重复调用1),直至满足模型预设的停止生长条件(比如设置树深、叶子节点包含的最少样本数等).
3)根据最终生成的所有叶子节点,得到决策树回归器
(1)
式中:Rm为叶子节点的数量;cm为m点处的输出值;I为指示函数.
1.2 RF基础理论
RF是以决策树为基学习器通过集成方式构建而成的有监督机器学习方法[14],进一步在决策树的训练过程引入了随机性,使其具备优良的抗过拟合以及抗噪能力.RF分别从样本选取和特征选择2个角度体现其随机性[15].
1)随机选取样本:RF中每一棵决策树的样本集均是从原始数据集中采用Bootstrap策略有放回地抽取、重组形成与原始数据集等大的子集合.这就意味着同一个子集里面的样本可以是重复出现的,不同子集中的样本也可以是重复出现的.
2)随机选取特征:不同于单个决策树在分割过程中考虑所有特征后,选择一个最优特征来分割节点.RF通过在基学习器中随机考察一定的特征变量,之后在这些特征中选择最优特征[16].特征变量考察方式的随机性使得RF模型的泛化能力和学习能力优于个体学习器.
1.3 RF回归算法
在回归问题中,随机森林回归(random forest regression,RFR)模型在表征一组输入和输出之间高度非线性关系时表现出强大的学习能力.RFR算法流程如下:
1)组建训练集D,采用Bootstrap策略从训练集D中有放回地重复取样,组成T个与训练集D容量大小相等的新训练集Di(1≤i≤T),即T个互相独立的回归决策树.
2)在回归树i的M个特征中随机考察m个子特征,遍历每一个抽样子特征后找到最优划分特征和分割点,满足均方误差MSE最小,然后划分为2个节点并且不做剪枝处理.
3)对生成的2个节点重复调用步骤2),直至满足模型预设的停止生长条件,决策树hi生长完成.
4)集结所有独立生长完成的回归决策树随即生成RF回归器
(2)
2 基于RF的路面性能预测
RF作为一种结构复杂、实现简单的集成学习算法,无须假设变量服从正态性等条件下即可完成对复杂数据集的分类和回归建模[17],且对数据中的噪声和异常值的包容程度较高,能够有效地处理复杂的非线性交互作用,在很多领域的预测问题中都被证明了是一种有效的预测方法,但是在道路工程中的应用寥寥无几.由于本研究中预测变量与相关解释变量均为连续型的数值变量,因此路面性能预测本质上是一种非线性的回归问题.鉴于此,本研究基于PCI数据组建训练RFR模型的样本集,并通过对比RFR模型较路面性能预测中常用机器学习模型(ANN、SVM)的预测能力,探讨RFR模型在沥青路面性能预测中的应用.本文提出技术路线如图1所示.

图1 技术路线Fig.1 Technical route
2.1 数据准备
特征变量相关描述如表1所示.本文以北京市沥青路面为研究对象,从相关部门收集整理了2010—2016年的道路检测数据,气候相关数据为北京市包括通州、密云在内的9个县区7年的气象数据,交通参数、路面结构相关数据来自相关单位建养计划.通过调查发现,路面性能检测时间可能会与养护工期冲突,因此造成目标年PCI值的缺失.此外在养护干预下路面结构、材料的变化会导致路面性能变化趋势突变.养护干预对于路面性能衰变影响重大,为排除此项因素干扰,本研究在进行数据筛选时选取的路段均为预测目标3年内发生过养护干预.本研究将PCI-1、AADT、AGE、PT、BT、ST、AP、AAT、SD作为模型的输入变量,PCI作为模型的目标输出变量.根据路面性能预测相关数据的收集以及参考国内外文献中进行路面性能预测工作提取的特征变量,确定组建容量为10×1 249的样本集用于构建路面性能预测的RF模型,其中训练集与测试集的划分比例为7∶3.

表1 特征变量相关描述Table 1 Description of the feature variables
2.2 预测模型的构建及调优
本研究基于RF的路面性能预测模型的开发在Python 3.5平台上实现.在训练模型过程中,必须定义对应于RF算法的超参数.在RF模型的构建过程中,为了使预测模型误差最小,采用网格搜索和十折交叉验证的方法对路面性能预测模型中关键的超参数进行优化,搜索结果如图2所示.其中R2平均值和R2标准差分别表示十折交叉验证下模型性能平均得分和稳定性,前者越大说明模型性能得分越高,后者越小说明模型稳定性越好.首先要确定的RF中决策树的数量n_estimators,从图2(a)可以看出随着决策树的数量由1增加到200时,R2平均值和R2标准差都呈现急剧变化并逐渐趋于稳定.值得注意的是,如图3所示模型的收敛时间由0.003 s增加至0.470 s.说明较少的树无法很好地刻画非线性关系,导致训练后的RF模型拟合不足,当超过一定的临界值后,继续增加决策树的数量并不会显著提高模型的性能,反而会增加计算时间.除此之外,RF模型通过设置决策树的最大深度max_depth控制其生长,当达到此阈值时决策树会自动终止训练.由图2(b)可知,max_depth的模型性能曲线整体变化趋势基本与n_estimators相同,本文不再进行过多赘述.通过折衷考虑模型性能得分、稳定性和计算时间,本研究采用n_estimators=71、max_depth=51作为预测模型的最优超参数.

图2 十折交叉验证下关键参数调优结果Fig.2 Results of the key parameters optimization using 10-fold cross-validation
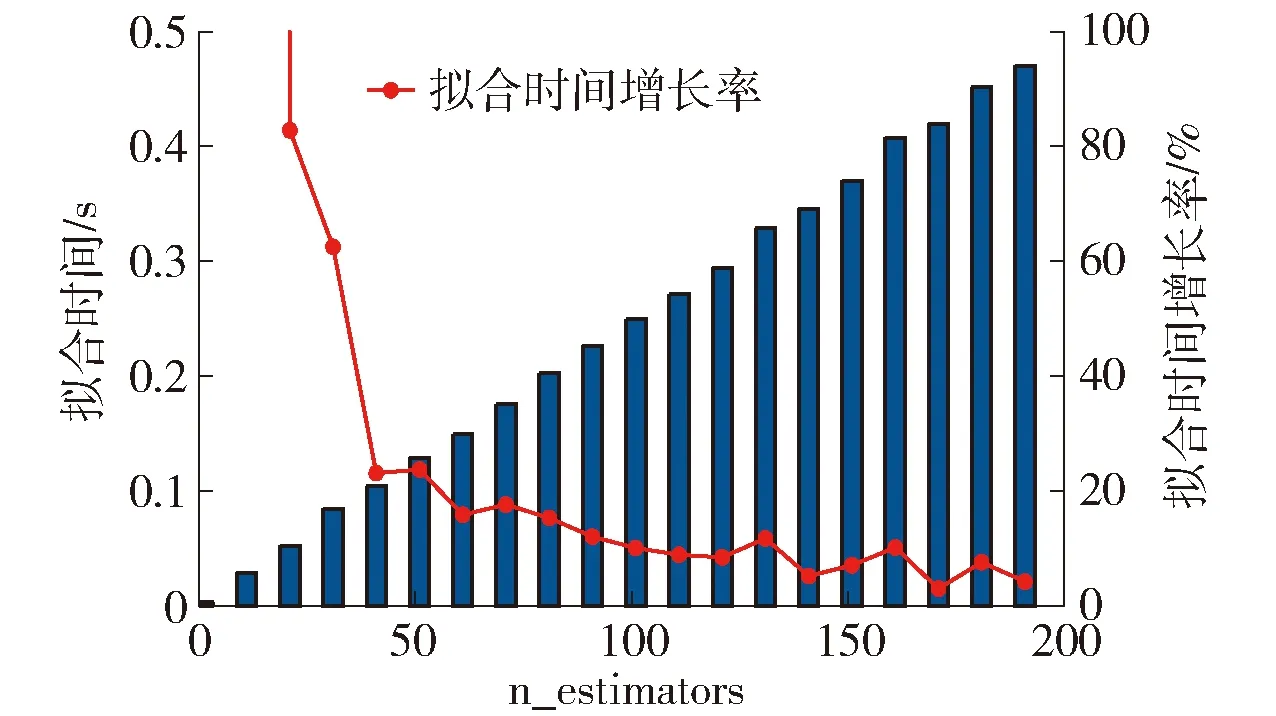
图3 收敛时间随n_estimators变化趋势Fig.3 Trend of the convergence time varies with the n_estimators
2.3 评价指标
定量地比较不同机器学习模型学习效果的优劣,是机器学习中一个不可或缺且十分重要的环节.本研究采用均方根误差(root mean square error,RMSE)、平均绝对误差(mean absolute error,MAE)、决定系数(R2)三个评价指标,评价机器学习模型的性能.前两者是衡量预测值与实际值的接近程度,值越小说明预测精度越高;R2是预测值对于实际值的表达能力,值越大说明预测精度越高(最大为1).表征上述指标的数学表达分别为
(3)
(4)
(5)

3 结果与分析
3.1 特征重要性分析
本研究将基于RF的PCI预测模型的特征重要程度置换为相对特征重要程度.图4给出了9种特征变量对于PCI预测的相对重要性得分.可以看出,PCI与目标年上1年的PCI高度相关,时间序列数据对于路面性能预测至关重要.年平均日交通量AADT对于PCI预测的重要程度较大,这点通过交通荷载增加对路面结构综合累计损伤作用的增加不难被解释.不同路龄状况下路面性能衰变趋势差异性显著,因此PCI对于路龄这一特征变量敏感度较高.与路面自身结构相关的特征变量中面层厚度PT、基层厚度BT这2个特征重要性略有差异,底基层厚度ST重要程度略低.由图4可知,与气象相关的特征变量对于PCI的影响同样不容忽视,相对重要程度由大到小排序依次是日照时数SD、年降水量AP、年平均气温AAT,三者直接影响路面材料性能进而影响路面性能的衰变.

图4 特征变量重要性Fig.4 Feature variable importance
3.2 预测模型验证与评价
本研究为证明基于RF的PCI预测模型的预测能力,保持与前者相同的训练集和测试集,分别采用路面性能预测领域成功应用的2种机器学习模型(SVM和ANN)进行对比研究.按照式(3)~(5)提出的评价指标,进一步定量地对比本文提出的3种机器学习模型性能.
表2给出了不同预测模型的RMSE、MAE、R2值以及计算时间.从表2看出,RFR模型在测试集和训练集上表现出的学习能力和泛化能力强于ANN、SVR模型,对PCI预测具有可接受的准确性.总体来说,3种模型在训练集上的RMSE分别为1.042、0.650、0.399,MAE分别为0.778、0.455、0.306,RFR表现出来的学习能力要优于SVR和ANN模型.RFR预测模型的泛化能力优越性显著:相较前两者,RFR模型的RMSE在测试集上分别降低了42.5%和17.7%,MAE分别下降了44.1%和15.8%,说明RF的预测值更加逼近实际值.此外,3种模型计算时间分别为0.259、0.130、0.174 s,这表明三者在此数据量大小下的计算效率并未存在显著性差异.

表2 评价指标汇总Table 2 Summary of the evaluation indices
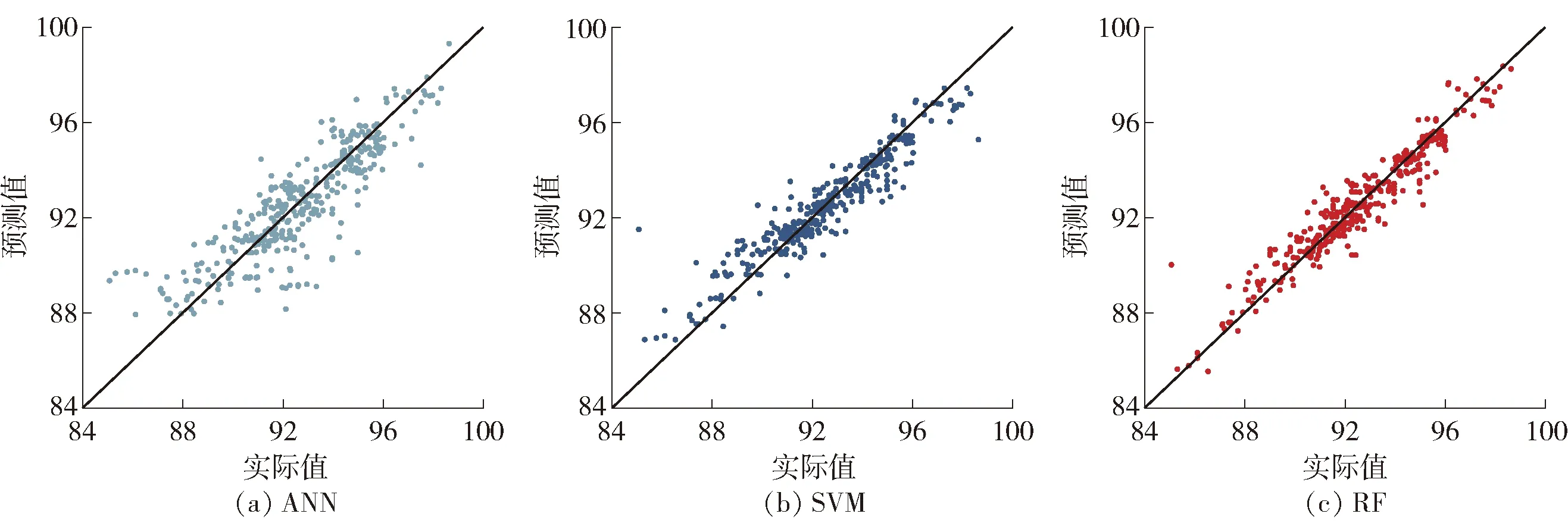
图6 3种模型测试集预测值与实际值对比Fig.6 Comparison of the predicted and actual testing set of three models
图5、6分别给出了评估3种模型在训练集和测试集上预测值和实际值对比的散点图.通过对比训练集、测试集的预测结果,其中基于RF的PCI预测模型的R2分别达到0.976和0.916,预测精度优于其他2个模型.对比图5、6可知,训练集的预测精度普遍高于其对应的测试集的精度,考虑到R2相差不过10%且测试集样本量不大,所以这种偏差并不严重.就训练集样本来说,ANN模型的预测值和实际值较零误差线分散程度最大,SVM模型次之,RFR模型几乎拟合在零误差线附近,说明预测值和实际值基本达到一致.在测试集训练结果中显示,RFR模型的R2达到0.916均高于ANN模型(0.746)和SVM模型(0.866).
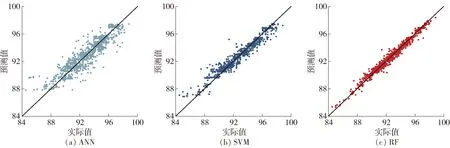
图5 3种模型训练集预测值与实际值对比Fig.5 Comparison of the predicted and actual training set of three models
3种模型预测结果存在差异性的原因在于,ANN模型需要依靠大量数据样本不断地修正模型来防止过拟合,提高自身的学习效果.本研究中数据集的数量相较于超量、海量数据集来说,训练不足难以发挥人工神经网络的性能.SVM模型较ANN模型来说可以较好地表征小样本下的非线性映射关系,但是其本身属于弱学习器,而RF属于由一系列弱学习器(决策树)集结在一起的集成算法,并且通过引入随机性增加模型抗噪能力,对于复杂结构的路面性能预测数据集预测精度势必强于单一的弱学习器(ANN、SVM).综上所述,基于RF的沥青路面状况指数PCI预测模型就路网级预测能力来说,优于人工神经网络和支持向量机预测模型,在处理非线性回归问题上优势显著.
4 结论
1)本研究依据北京地区2010—2016年间路面性能特征、路面结构特征、气象特征以及交通参数特征,以沥青路面PCI为研究对象,采用机器学习中的RF算法建立了北京市沥青路面PCI预测模型.该模型能够准确识别相关特征变量与PCI间复杂的耦合关系,用于预测目标年的PCI有较高的准确率.
2)本研究引入神经网络和支持向量机2种经典机器学习算法,利用可视化散点图以及参考的3种评价指标,通过对比研究证明了RF模型强大的学习和泛化能力:对学习结果和样本集拟合后,RF模型预测值更为逼近实际值;在训练集和测试集上的RMSE、MAE和R2都要优于ANN和SVM机预测模型,验证了RF模型的有效性以及优越性.
3)路面性能预测是路面养护管理的重要内容,基于RF算法的PCI预测模型通过高效、准确的预测可以推动建立现代公路养护管理体系,为后续北京市沥青路面养护规划以及养护资金调配提供指导.
