基于AA-LSTM网络的语音情感识别研究
2021-11-17张会云黄鹤鸣黄志东
张会云,黄鹤鸣*,李 伟,黄志东
(1.青海师范大学计算机学院,青海 西宁 810008;2.藏文信息处理教育部重点实验室,青海 西宁 810008;3.青海省藏文信息处理与机器翻译重点实验室,青海 西宁 810008)
1 引言
语音包含丰富的语言、副语言和非语言信息[1],这些信息对人机交互具有非常重要的意义。仅理解语言信息并不足以使计算机能够完全理解说话者的意图。为了使计算机类同人类,语音识别系统需要能够处理非语言信息,尤其是说话者的情感状态[2]。因此,语音情感识别(Speech Emotion Recognition,SER)受到越来越多研究者的广泛关注[3-4]。
情感语音包括语义内容和情感特征,大量SER研究主要集中于寻找最能表示情感的不同语音特征[1]。文献[5-6]提出了关于情感的各种短期特征和长期特征,但仍不清楚哪些特征更能提供情感方面的信息。传统方法是提取大量统计特征,并使用机器学习算法分类。很明显,特征提取包括两个阶段。首先,从短帧中提取情感声学特征,即低级描述符;其次,每个低级描述符用不同统计聚合函数表示成特征向量,表达了句子级不同低级描述符的时间变化和轮廓[5]。常用的低级描述符和高级统计函数如表1所示[6]。

表1 常用的低级描述符与高级统计函数
2 相关工作
人类通过潜意识识别情感,为了实现更好的人机交互,需要考虑语音中的情感。由于人类情感界限模糊,因此,识别情感具有很大的挑战性。首先,很难确定语音片段的开始和结束;其次,每个语音片段通常表示不同情感[5-7]。
最近深度学习自动学习SER中的情感特征受到很多研究者的关注[8-10]。对情感的识别需要考虑上下文信息,而LSTM网络恰好用于序列输入动态建模,且能够解决网络训练中的梯度消失或爆炸问题。这是由于LSTM的输入通常来自底层和先前时刻时间步长的输出,且LSTM中的记忆单元和门能够控制信息记忆、输出或遗忘[2,10]。
SER受益于神经网络,文献[8,9,11]表明神经网络更高层可获取更多时间步长时,其网络性能将大幅提升,但这仅针对传统神经网络,并未讨论时间序列问题。文献[12-14]表明语音时间信息有利于情感识别。因此,很多研究者提出了将循环神经网络(Recurrent Neural Network,RNN)应用于SER研究,文献[13]使用RNN在帧级学习短期声学特征,并将传统表示映射到句子级表示。由于Attention机制能够选择情感集中区域[14-15],文献[5]提出了将其应用于LSTM网络来提取声学特征。在此基础上,文献[6]引入先进的LSTM(Advanced LSTM,A-LSTM)网络来提取声学特征,能更好地实现上下文建模,实验表明,基于Attention机制的A-LSTM(Attention Advanced LSTM,AA-LSTM)网络对情感的识别性能更优。
为了提取语音中的潜在情感,研究了AA-LSTM网络在不同参数集对情感识别系统性能的影响。
3 语料库描述与特征提取
为了评估基于AA-LSTM网络的SER系统性能,本研究在EMO-DB语料库上进行了大量实验。EMO-DB语料库由柏林工业大学在专业录音室录制,采样率16kHz,16bit量化,共535句语料,由10位演员(5男5女)对10个语句(5长5短)模拟生气W、无聊L、厌恶E、害怕A、高兴F、悲伤T及中性/N等7种情感。
所提取的声学特征包括13维MFCC、过零率、谱重心、谐波噪声比及音高等,并对提取的特征进行归一化处理[16-17]。
4 语音情感识别系统
4. 1 基于Attention机制的LSTM
基于Attention机制的LSTM网络依赖Attention机制学习每个步长的权重并将其表示为加权组合,多任务学习可更好地学习句子级特征[5]。其结构如图1所示。
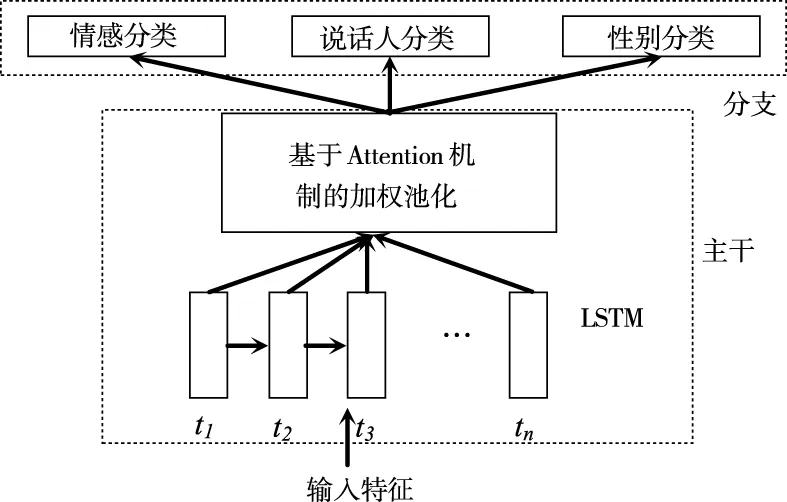
图1 基于Attention机制的加权池化LSTM
该结构分为主干和分支,分支包含情感、说话者和性别分类[5],主干共享所有任务,并处理分类的输入和特征表示,其顶部是加权池层[2],[18],计算如(1)式所示
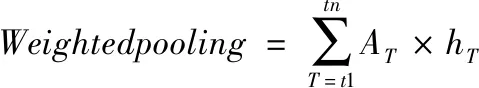
(1)
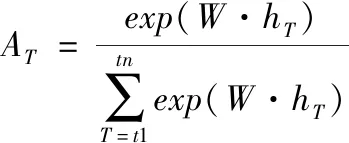
(2)
其中,hT是T时LSTM的输出,AT是T时相应权重的标量,计算过程如(2)式,W是学习参数,exp(W·hT)是T时的能量。若T时帧能量很高,其权重就增大,关注更高;反之,则关注较低,即模型可分配权重[19]。
本研究主干是具有256个ReLU节点的全连接层和128个节点的双向LSTM层,随后进入加权池层。在分支部分,每个任务均有隐含层,即包含256个ReLU神经元和Softmax层。
4. 2 A-LSTM
传统LSTM的输入来自底层和前一刻时间步长的输出并将其反馈到更高层。门机制通过点乘法控制信息流动[6],记忆单元更新信息如(3)式。其中,ft和it是t时遗忘门和输入门的输出;Ct是新的候选单元值,计算如(4)式。其中,tanh是激活函数,WC是学习的权重集合,bC是偏置;[ht-1,xt]是先前时间步长(h值)和底层(x值)的串联,t时h值计算如(5)式。其中,Ot是输出门,基于ht-1和Ct-1计算Ct。
(3)
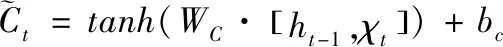
(4)
ht=ot⊙tanh(Ct)
(5)
与传统LSTM不同,A-LSTM释放了时间t状态依赖于t-1状态的假设,并使用多个状态的加权和计算C值和H值,如图2所示。将LSTM中的(3-4)式修改为(6-7)式,C是选定状态的加权和,T是选定时间步长的集合,(9)式中的是标量,表示时间步长对应的权重;(10)式用于计算t时刻隐含值,与(5)式相同,但此时单元值是C′,h′通过(11-12)式进行计算,在(9)(12)式中,W是学习到的共享参数,C′和h′包含集合T中的所有状态和隐含值。
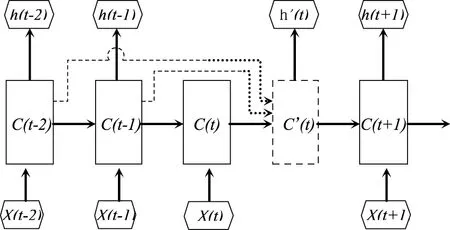
图2 A-LSTM的展开图
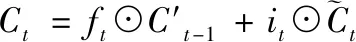
(6)
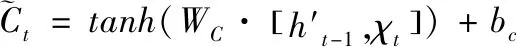
(7)
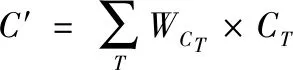
(8)
(9)
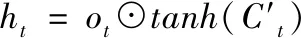
(10)
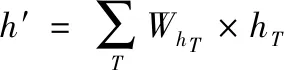
(11)
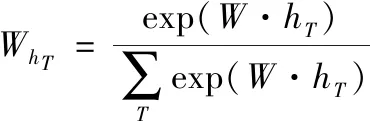
(12)
A-LSTM具有更灵活的时间依赖建模能力,类同人类学习机制,能够回忆起先前时刻信息,使学习变得更好。
4.3 AA-LSTM
将Attention机制与A-LSTM网络相结合得到AA-LSTM网络,其结构如图3所示。与图1不同之处在于该网络将图1中的LSTM网络改为图2中的A-LSTM网络结构,其计算过程如式(6~12)。
5 实验与结果
本研究在EMO-DB德语情感语料库上研究了AA-LSTM网络中的最优参数设置和优化器选择。首先,比较了不同批处理(Batchsize)、迭代周期(Epoch)、交叉验证次数(K_folds)以及训练终止条件(Patience)对AA-LSTM网络系统性能的影响;其次,选择不同的优化器对系统进行优化,其评价指标采用准确率、均值和方差。
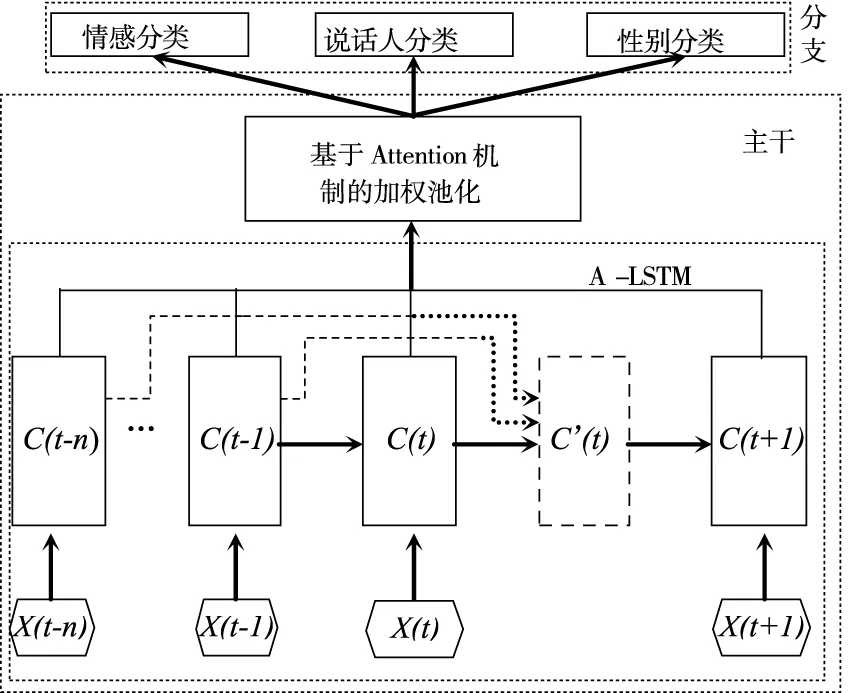
图3 基于Attention机制的A-LSTM网络
表2给出了该模型在不同Batch size下得到的混淆矩阵、最优性能及均值和方差。为了研究不同Batchsize下模型所获得的性能,在该系统中,使K_folds=5,Epoch=100,Patience=10,Optimiser=′Adam′。
由表2可知,在其它参数确定的情况下,不同Batch Size对系统性能影响有所差异。当Batch Size=16时,系统最佳性能达到66.39%,但均值为61.78%且偏离程度较大;Batch Size=64虽偏离程度较小,但耗时相当大。综合来看,当Batch Size=32时不仅系统平均性能较稳定,耗时也非常小,主要是由于选取的批量大小合适,提高了训练速度;同时,选取合适Batch Size使梯度下降方向更加准确,从而提升了网络整体性能。
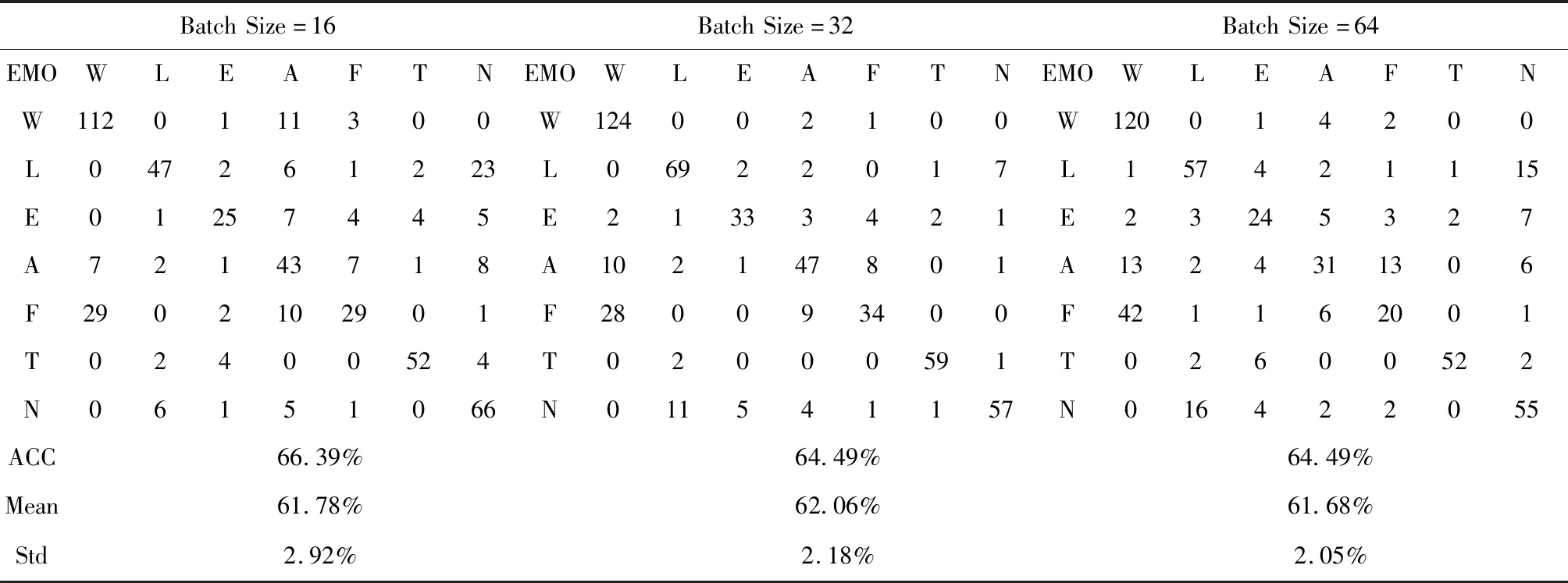
表2 不同Batch Size下的混淆矩阵与性能
表3给出了该模型在不同优化器(Adam,Rmsprop,Sgd)下得到的混淆矩阵、最优性能及均值和方差。为了研究不同优化器下模型所获得的性能,在该系统中,使K_folds=5,Patience=10,Epoch=100,Batch size=32。
由表3可知,在其它参数确定的情况下,不同优化器对系统性能影响有所差异。综合考虑准确率、均值及方差,与Adam,Sgd等优化器相比,选择Rmsprop优化器优化模型时,系统最佳性能可达到67.29%,平均性能为62.26%且偏离程度较小,表明Rmsprop是该系统中的最佳优化器,Adam次之,Sgd优化器不适用于该模型结构。
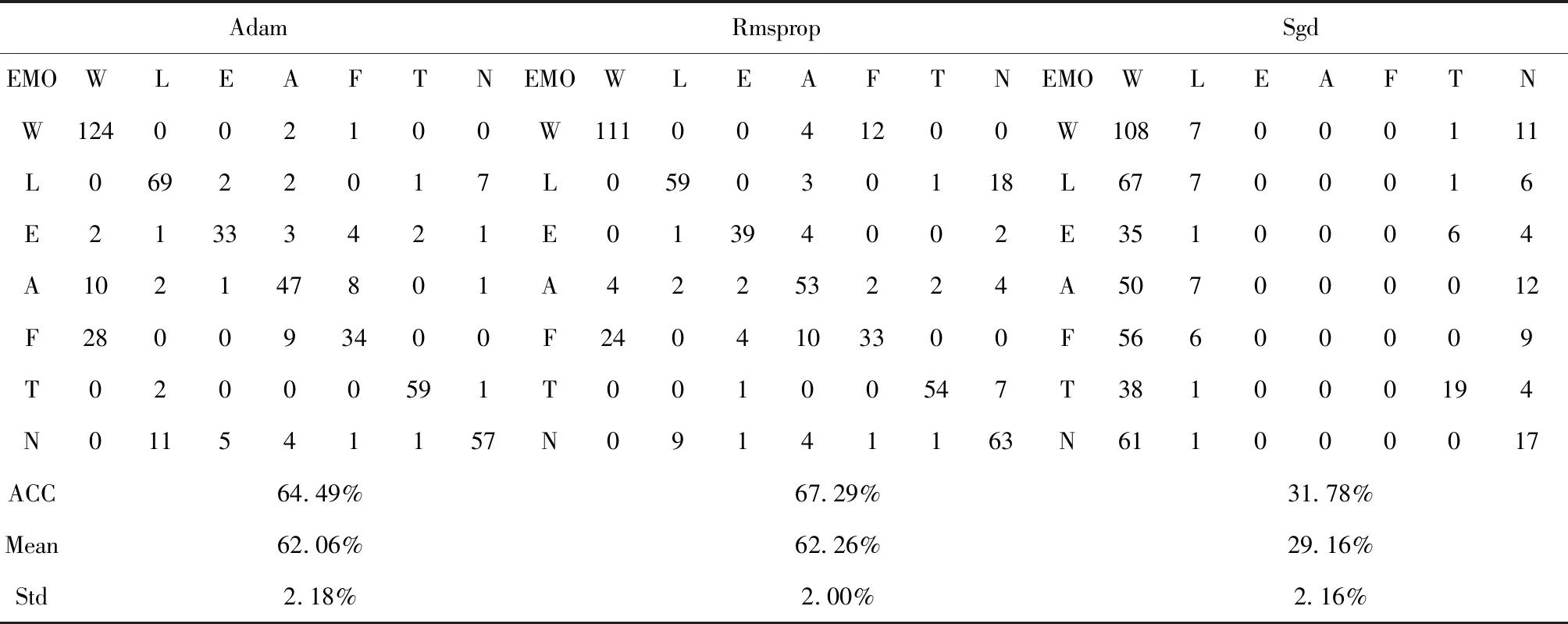
表3 不同优化器下的混淆矩阵与性能
表4给出了该模型在不同训练终止条件(Patience)下所获得的混淆矩阵、最优性能及均值和方差。为了研究不同Patience下模型所获得的性能,在该系统中,Batchsize=32,Optimiser=′Rmsprop′,K_folds=5,Epoch=100。
由表4可知,在其它参数确定的情况下,不同Patience对系统性能影响有所差异。综合考虑准确率、均值及方差等因素,当Patience=10时,系统性能达到最优、整体性能稳定、偏离程度较小且耗时较小。随着Patience值不断增大,系统性能有所下降,这是由于过拟合现象造成的。
表5给出了该模型在不同交叉验证次数(K_folds)下得到的混淆矩阵、最优性能及均值和方差。为了研究不同K_folds下模型所获得的性能,在该系统中,使Batchsize=32,Optimiser=′Rmsprop′,Patience=10,Epoch=100。
由表5可知,在其它参数确定的情况下,不同K_folds对系统性能影响有所差异。综合考虑准确率、均值及方差等因素,随着K_folds逐渐增大,模型最佳性能可达到70.09%,且整体性能有所提升,这是一个非常可观的结果,但系统偏离程度较大且非常耗时。
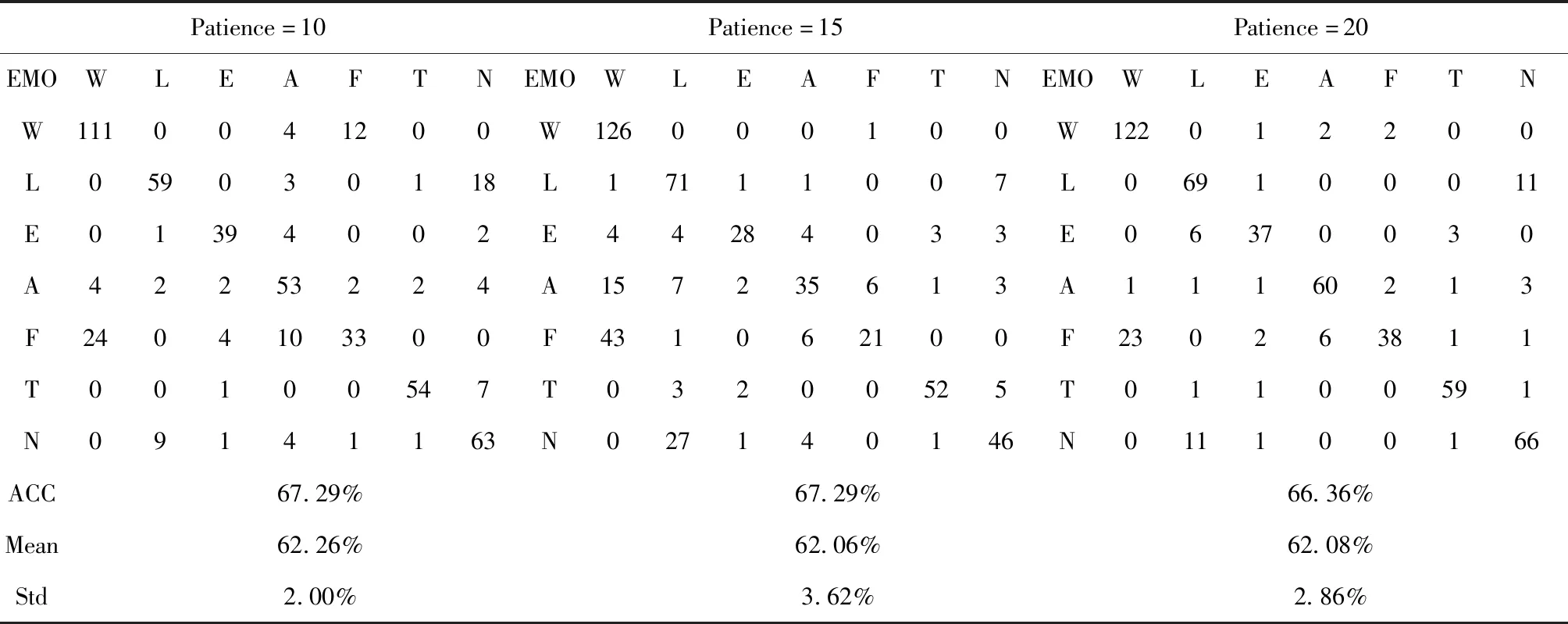
表4 不同Patience下的混淆矩阵与性能
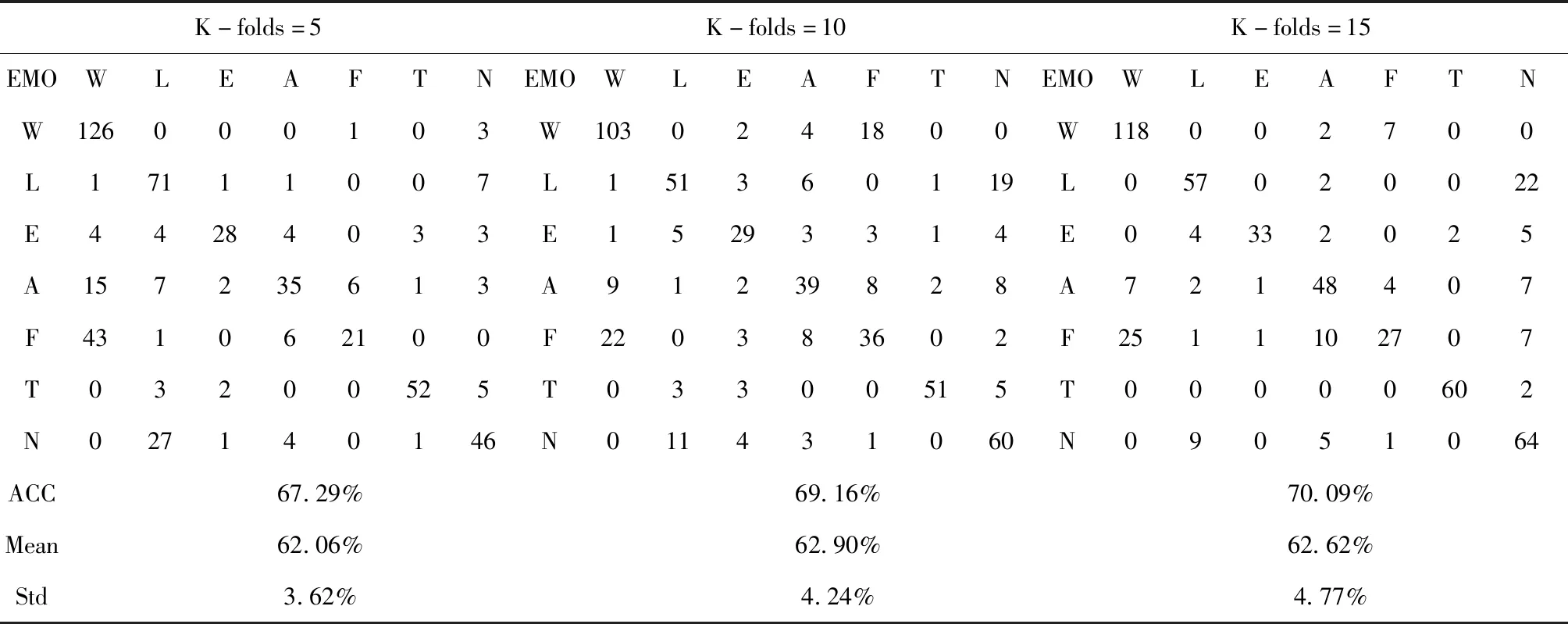
表5 不同K-folds下的混淆矩阵与性能
表6、表7给出了该模型在不同迭代周期(Epoch)下得到的混淆矩阵、最优性能及均值和方差。为了研究不同Epoch下模型的性能,在该系统中,使Batchsize=32,Optimiser=′Rmsprop′,Patience=10,K_folds=5。
由表6、表7可知,在其它参数确定的情况下,不同Epoch对系统性能影响有所差异。综合考虑准确率、均值及方差,当Epoch增大到100时,模型最佳性能可达到67.29%,且整体性能有所提升,但偏离程度较大;当Epoch继续增大到200时,模型的性能有所下降且非常耗时。同时,纵观表6,表7可得出:针对同一Epoch,K_folds越大,系统性能越好。进一步证明了K_folds对系统性能的作用。
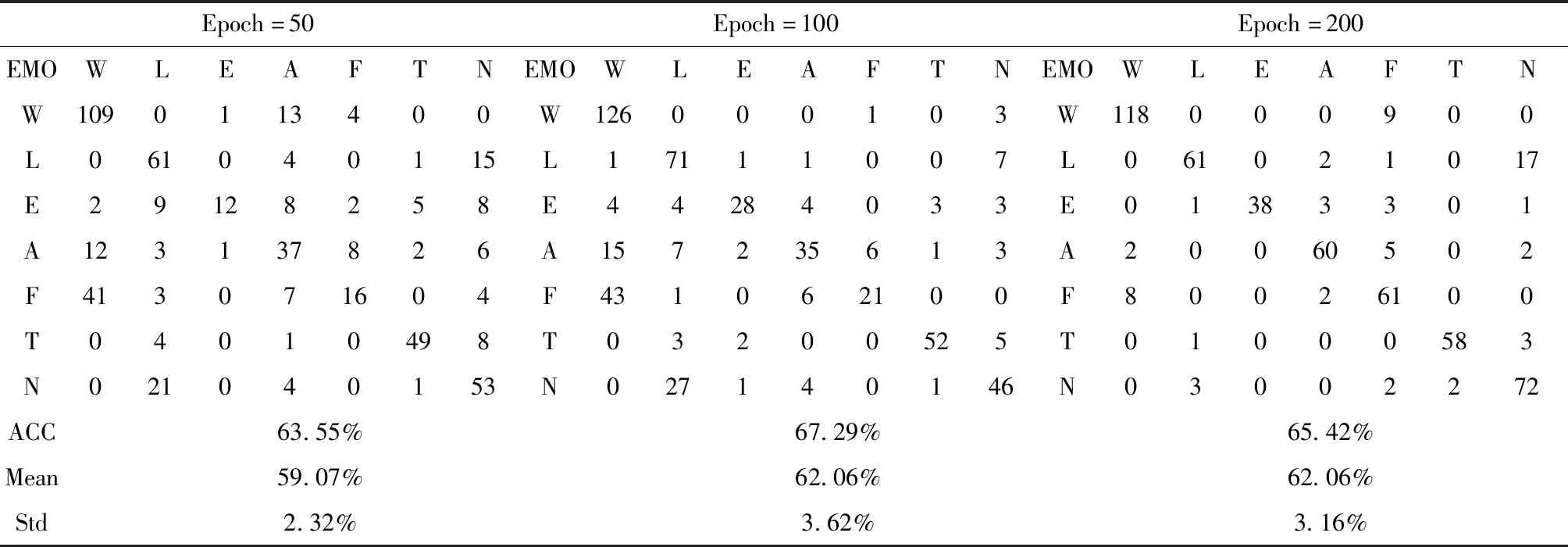
表6 K_folds=5在不同Epoch下的混淆矩阵与性能
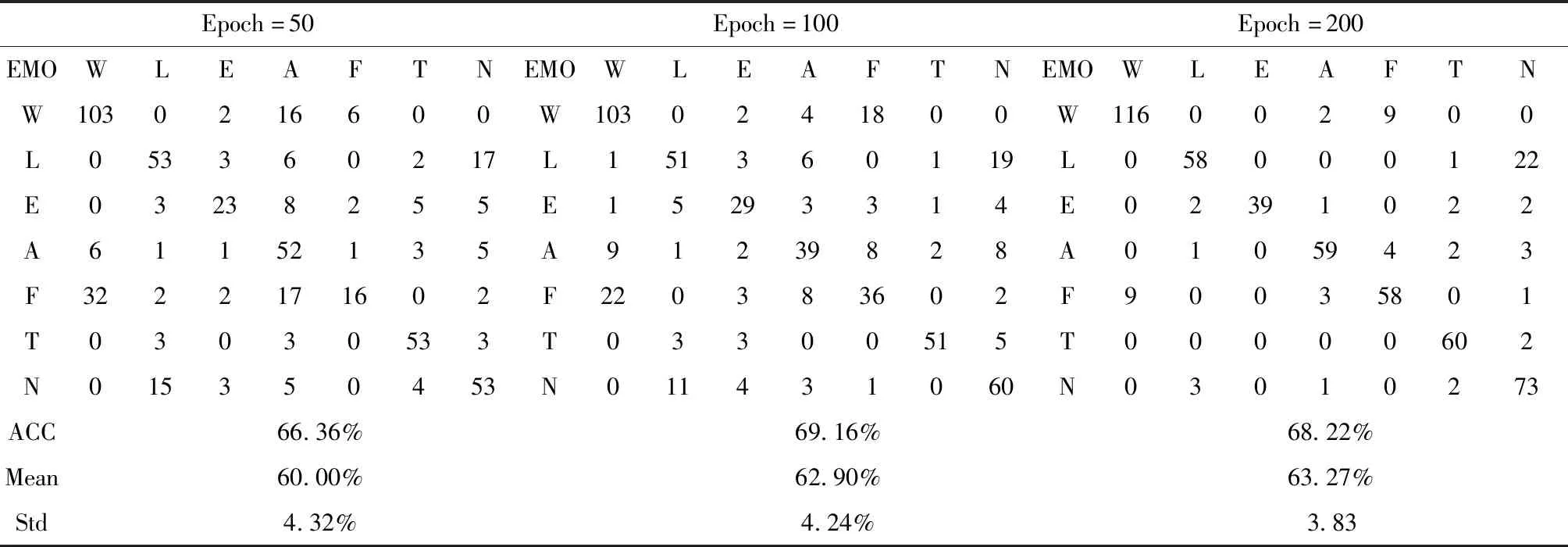
表7 K_folds=10在不同Epoch下的混淆矩阵与性能
6 结论与展望
本研究采用AA-LSTM网络对SER系统中的参数进行了验证,该实验中涉及到的网络参数有:模型交叉验证次数(K_folds)、模型在训练集上运行的周期(Epoch)、每次训练模型时选取的批量大小(Batch size)、检测模型终止的条件(Patience)以及模型优化器(Adam,Rmsprop,Sgd)等。实验结果表明:网络结构中的参数对情感识别系统性能影响较大,即选取适当参数集不仅能够提高网络模型的性能,还能大大减少模型的训练时间;同时,优化器的选择对系统性能影响也较大。本研究通过大量实验以选择AA-LSTM网络性能达到最优时的参数设置,今后将利用对抗网络生成足够数量SER数据,并在最优参数设置下将跳跃连接引入该网络以研究其性能,或将结合多时间步长状态的思想扩展到门控循环单元(GRU)。
