基于分布式符号数据的混合推荐算法研究
2021-11-17王仲君
钟 乾,王仲君
(武汉理工大学理学院,湖北 武汉 430070 )
1 引言
近年来,随着云计算,大数据,物联网等技术的迅猛发展,在为顾客提供越来越多选择的同时,网络数据的规模也呈爆发式增长。顾客在复杂的网络结构面前往往需要浏览大量的不必要信息来寻找自己喜好的物品,这就是所谓的“网络信息过载”。针对这个问题,个性化推荐技术能够快速的从纷繁复杂的数据中为用户获取有价值的信息,从而受到越来越多人的青睐。一些大型的电子商务网站,如Amazon、eBay、Netflix等都将推荐系统作为网站的核心技术。
关注度的提高使得国内外众多学者对推荐算法展开了大量研究,个性化混合推荐凭借着可以综合各种推荐算法的优势而备受瞩目[1-3]。刘沛文,陈华锋[4]针对传统的推荐算法存在评分矩阵稀疏性的问题,提出了基于用户行为特征的动态权重混合推荐,在数据预处理时,计算出了用户对于不同物品的个性化行为特征指数,并与协同过滤混合以提高推荐精度。杨卫芳,李学明[5]将基于热传导和基于物质扩散的两种方法混合进行推荐,并引入用户活跃度的概念进行调节,实现了资源的重新分配,从而获得了更好的效果。传统推荐算法中存在着用户兴趣描述过大的问题,基于此,任磊[6]提出了一种增量学习的混合推荐算法。此外,于波[7]等人通过计算项目间属性的相似性,并与基于项目的协同过滤算法中的相似性动态结合,解决了混合推荐中了推荐精度差,效率低下的问题。为更全面地反映用户偏好,提高推荐的准确度,冀振燕[8]提出了融合多源异构数据的混合推荐模型,该模型综合考虑了用户社交关系和用户评论对用户评分的影响,从评论中提取主题信息作为用户的特征,结合机器学习方法建立模型,实现推荐。宋文君[9]基于用户的近期行为能够更好的反映潜在兴趣偏好的思想,提出了基于有限时间窗口的改进混合推荐算法,该算法在标准数据集上的结果证实了用户近期的历史记录可以提高算法的推荐精度。Jian Wei[10]等人利用降噪自编码器挖掘出项目内容的特征信息,并结合到了改进的时序矩阵分解算法中,有效的解决了推荐算法中的完全冷启动和不完全冷启动的问题。王全民[11]提出了一种基于特征偏好分析的改进混合推荐算法,该方法将用户特征偏好和物品特征相结合,再使用传统的协同过滤思想,将最优评分对象推荐给用户等。
上述的个性化混合推荐模型均是针对点数据构建出来的,即数据是数值型的。在实际中,由于数据的来源渠道不同,数据的类型多种多样,点数据模型不可避免的存在着信息丢失,无法精确建模的问题。而符号数据分析(Symbolic Data Analysis,SDA)可以处理多类型的数据,有效的弥补了点数据建模时的不足。考虑到符号数据的优势,Bezerra[12-14]等人将符号数据引入到了个性化推荐算法中,提出了基于符号数据的内容过滤,协同过滤和混合过滤三种方法,提高了推荐算法的效率,但降低了推荐算法的精度。Queiroz[15]等人最先将符号数据引入到了群体推荐算法中,有效的表征了用户群体的模型。郭均鹏[16-18]等人基于文献[12]的思想利用模态型,区间型,分布式符号数据分别为用户进行建模,进而预测产生推荐,实验结果表明符号数据比点数据更能刻画用户的兴趣偏好,构建出理想的用户模型,为用户推荐出满意度高的项目。
为能够将符号数据与传统的个性化混合推荐算法的优势结合起来,本文提出了基于分布式符号数据的混合推荐算法。该算法利用分布式符号数据表征项目内容,将项目内容量化。在利用项目内容构建出用户的不同偏好子模型后,改进的符号数据的距离度量被用来计算它们之间的相似度。最后结合传统的协同过滤算法完成推荐预测。该算法与传统的推荐算法在电影评分数据集上进行实证分析,并比较它们之间的优劣。
2 符号数据
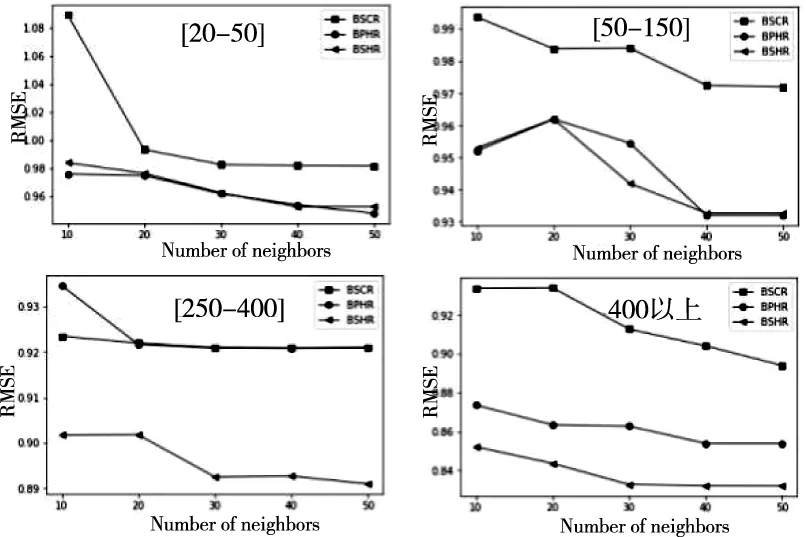
符号数据分析是一种研究如何从海量数据中挖掘系统知识的理论和方法,其运用“数据打包”技术,不仅能处理类型复杂,规模巨大的数据,实现对庞大的样本空间的降维处理,更可以从全局上把握数据对象的内在结构特征,有利于解释隐含在数据内部的规律。一般而言,符号数据有定性数据和定量数据两种,而每一种都有多种表现形式。常用的符号数据类型有1)分布式变量,例如X=({2,4,6}(0.2,0.5,0.3))表示X以(0.2,0.5,0.3)概率分布取值(2,4,6)。2)区间变量,Y=[a,b]={x:a 本节以电影推荐领域为例,阐述本文模型的构建过程。在电影推荐领域中,用户对电影的偏好表示为一个评分矩阵R。其中行Ui表示用户,列Ij表示项目(电影),矩阵中的元素rij是用户对项目的评分,取{1,2,3,4,5}上的任意值,1分表示用户对该电影的兴趣偏好很消极,5分表示用户很偏好该部电影。空缺的部分表示用户对电影未进行评价,需要去做预测推荐,见表1。 表1 用户项目原始评价矩阵R 实际的电影数据中还可以得到有关电影的一些内容描述,例如电影的演员表(Cast),导演(Director),以及电影归属的流派(Genre)信息等,见表2。 表2 电影项目I4的内容描述 (1) 对于表1中项目的内容,依据上面的方法均可以得到对应的分布式描述,见表3(为了使下文的计算更加简便,这里用字母代替元素,例如G3代表的是Science,P2代表的是导演Nalan)。 表3 电影项目的分布式内容描述 本文利用表3中电影的分布式内容描述来构建用户模型。在电影推荐领域中,由于用户评价过的项目中包含着他所喜欢的项目(评分为4和5)和不喜欢的项目(评分为1和2),因此可以为每一个用户构建两个偏好模型,积极子模型和消极子模型。令u+代表用户u的积极子模型,它是由用户u所评价过的项目中评分为4和5的项目的分布式内容描述所构成的。同理用u-来代表用户u的消极子模型,它是由用户u所评价过的项目中评分为1和2的项目的分布式内容描述所构成的(在文献[14]构建用户模型的过程中,认为3分是一个中性评价,对应项目无法合理地表述用户偏好,因此被忽略,本文同理)。 (2) m∈Sj(uσ)是领域Dj上的一个元素,那么它的权重W(m)∈qj(uσ)的计算公式如下 (3) 这里|uδ|表示属于模型uσ的电影项目数量。例如用户U1,他的I2和I5的评分较高,所以用表3中I2和I5的分布式内容描述来构建用户U1的积极子模型U1+。I1和I3的评分较低,所以可以用来构建用户U1的消极子模型U1-。此外,在用户模型的构建过程中,不同的评分理应拥有不同的权重。评分为5(1)比评分为4(2)更能说明用户喜欢(讨厌)该项目,这一点在文献[14]中已经指出,解决方法是W(m)计算时评分为5(1)的项目重复3次,评分为4(2)的项目重复两次。本文同理用该种方法进行计算,得到U1的最终模型见表4。 表4 用户U1的偏好模型 同理,还可以得到用户U2基于分布式 符号数据的模型见表5。 表5 用户U2的偏好模型 (4) (5) 分析式(5)中的φ,p代表模型中特征的数量,φs是计算分布式符号数据集合S的差异度函数,φwh是计算集合S对应的权重q的差异度函数。φs的定义如下 (6) 例如集合Scast(U1+)={A2,A3,A6,A7,A8,A9}和集合Scast(U2+)={A1,A3,A5,A6,A7,A8},依据式(6)计算,它们之间的差异度为0.5。φwh的计算要复杂一些。①当φs=0时,即两个集合元素完全相同。φwh的计算为集合中对应元素权重差的绝对值之和。②当φs≠0时,需要考虑集合间不同元素的权重和所占比例的大小。由四部分构成,计算两个集合间相同元素的权重和α和β,以及计算两个集合之间不同元素的权重和γ和δ,如下所示 (7) 对于集合Scast(U1+)和Scast(U2+),因为φs≠0,且其对应的权重为(320,110,1/4,110,14,3/20)和(320,110,320,14,1/4,1/10),那么α,β,γ,δ的计算过程如下 Scast(U1+)∩Scast(U2+)={A3,A6,A7,A8} (8) 基于式(7)中的φwh,能够计算出集合Scast(U1+)和Scast(U2+)的权重差异度为 φwh(qcast(U1+),qcast(U2+)) (9) 这个值表明在属性Cast(演员)下,用户U1和用户U2的积极子模型之间权重大约相差46.2%。由于集合间相差了50%,因此在属性Cast下,用户U1和用户U2积极子模型间的总差异度为0.5*(0.462+0.5)=0.481。同样的计算还应该作用在用户子模型的属性Director(导演)和属性Genre(流派上)上,最终U1与U2的积极子模型间的总差异度为 0.462+2/3+0.75)≈0.561 (10) 同理,还可以计算出U1与U2的消极子模型之间的总差异度为(注意,此时Φs=0) (11) 基于式(5)中的φ,得到用户U1和用户U2的混合相似度为 (12) 同理,可以计算出表中所有用户间的相似度。 (13) (14) 其中|T|表示测试数据集中评分的数量。RMSE值越低,算法的推荐精度越高。 为了验证本文基于分布式符号数据的混合推荐算法(BSHR)在个体推荐上的功效性,选取了经典的movielens数据集作为实验数据集。Movielens网站(http:∥www.movi-elens,.org)拥有三种不同量集的数据集,这里选择了943个用户对1682部电影的约10万条评分的数据集,其中每个用户至少评价过20部电影。该数据集中包含了电影的流派(Genre)信息,因此本文从IMDB网站(https:∥www.imdb.com)上只收集了有关电影的演员和导演信息,并将其整理为了内容字段Cast和Director。用户对电影的评分取集合{1,2,3,4,5}上的值,同样数值越高表明用户越喜好该部电影。此外,随机选择了80%的评分作为训练数据集和20%的评分作为测试数据集。实验过程中,首先根据训练集中用户评分的电影内容建立用户的积极子模型和消极子模型,然后计算用户间的相似度,根据最近邻思想预测用户对未知项目的评分值,最后与测试数据集进行对比检验。 选取两种推荐算法作为本文算法的对比算法。一种是传统的基于点数据的混合推荐算法(BPHR),主要思想是利用用户的评分算出电影的评分相似度,利用电影的内容算出电影的内容相似度,将两种相似度混合,采取最近邻思想预测推荐。另一种是基于符号数据的协同过滤推荐算法(BSCR),算法的主要思想是根据用户的评分生成用户评分权重模型,利用模型间的相似度函数计算出用户间的相似度,最后采取最近邻方法实现推荐[18]。 4.4.1 用户评分的稀疏性对实验结果的影响 本节首先探讨了三种算法中,用户评分的稀疏性对实验结果的影响。将训练数据集中的用户按照其所评价过的项目的数量分为了5组,数量在[20-50]的用户为一组,[50-150]为一组,[150-250]为一组,[250-400]为一组,以及400以上为一组。固定近邻个数为50后,三种算法分别在5个组中独立进行实验,计算每一个组中的RMSE,并进行比较。得的实验结果见表6。 表6 数据集的稀疏程度对实验结果的影响 从表6整体来看,三种算法在用户评分数量的增加下,RMSE都呈现下降的趋势。这说明随着数据集评分矩阵的稀疏性降低,各种算法的推荐质量会逐渐提高。其中以本文提出的算法下降的程度最为明显(0.12>0.09>0.08),表明了基于符号数据的混合推荐算法受数据集稀疏性的影响较大。分析其原因,认为这主要是由于用户的的积极子模型与消极子模型的构建基于用户所评价过项目,评价的项目越多,越能代表用户的偏好,构建的模型也会更加精确。当用户评分数量较少时([20-50]和[50-150]),本文算法得到的模型较粗糙,因此最终精度也要差于基于点数据的混合推荐算法(0.9528>0.948,0.9370>0.9320)。 从推荐精度来看,本文算法在评分矩阵稀疏性低([150-250],[250-400]和400以上)的情况下得到的实验结果要优于其它两种算法,而基于符号数据的协同过滤推荐算法整体上的实验结果要差于其它两种算法。分析其原因,认为基于符号数据的协同过滤算法并没有将电影的内容考虑进去,用户模型的构建仅仅依赖于历史的评分,因为信息没有充分利用,导致推荐精度的降低。 4.4.2 近邻个数对实验结果的影响 本节旨在探讨数据集稀疏性稳定的情况下,算法近邻个数的增加对实验结果的影响,这里选择用户评分数量在[150-250]区间内的组。各种算法初始的近邻个数设置为10,每次实验近邻个数递增10个,一共进行5次对比实验,得到的实验结果如图1。 图1 各种算法近邻数量h对实验结果的影响 通过分析图1,可以得到如下的结论: 1)最初三种算法随近邻个数的增加,RMSE都在下降(h=10,20,30),即推荐精度呈上升的趋势。这一时间段,近邻个数对各种算法实验结果的影响较为显著。当近邻个数达到一定程度的时候,RMSE会趋向于一个定值,表明近邻个数的增加对实验结果的影响将会越来越小。 2)此外,还可以得到,在[150-250]区间内,固定近邻个数的情况下,本文算法的最终推荐精度要高于另外两种算法,基于符号数据的协同过滤推荐算法的最终精确度却低于其它的两种算法。 在这里同样给出其它评分子集下,近邻个数h对三种推荐算法精度的影响,如图2。分析图2可以发现结论1)的成立,但也注意到,在用户评分数量较少时,固定近邻个数的情况下,本文算法的最终精度不一定高于基于点数据的混合推荐算法 图2 不同评分数量下h对推荐精度的影响 4.4.3 不同算法的推荐效率 衡量一个算法的好坏不仅看推荐精度,还需考虑推荐效率,即时间的长短。同样的条件下,所需时间越短,表明了该算法的推荐效率越高。这里给出特定条件下,基于符号数据的混合推荐算法与基于点数据的混合推荐算法完成推荐的时长,见表7,8。 表7 基于点数据的混合推荐算法的完成时间 表8 基于符号数据的混合推荐算法的完成时间 由于基于符号数据的协同过滤推荐算法没有利用到内容信息,推荐时间自然较短,所以不再将它列出。考虑到不同组内测试集中用户数量的不同,对于模型的构建,推荐的时间会造成一定的影响,表格中数据因此无法横向对比。从表7,8列来看,即在固定稀疏度与近邻数量的情况下,本文的推荐算法所耗费的时长大多数情况下高于点数据推荐,推荐效率较低。分析其原因,认为本文算法为了更加精确的表征用户模型,利用到了符号数据中的集合和权重,模型的构建上花费了较多的时间,因此效率要低于点数据推荐,相反带来的益处是计算出的用户相似度会更加精确,在评分矩阵稀疏性较低的情况下,推荐精度更高。因此,本文算法在数据量大,推荐实时性要求不高的场景下较为适用。 为了能够处理多源异构数据,本文将分布式符号变量引入到了传统的混合推荐算法中,利用其表征用户,构建偏好模型,预测实现推荐。将本文的算法与传统的推荐算法进行对比实验,表明基于分布式符号数据的混合推荐算法在推荐精度上更优,但效率上较差,因此适用于推荐实时性要求不高的领域中。由于目前基于分布式符号数据的混合推荐算法仍然是一个全新的领域,不可避免面临着冷启动的问题,此外,如何用分步 式符号变量量化用户的隐式评分,也将会是 未来的研究方向。3 基于分布式符号数据的混合推荐算法
3.1 构建用户积极子模型和消极子模型


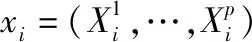
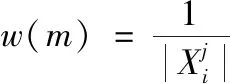


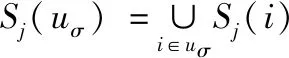



3.2 计算用户之间的相似度
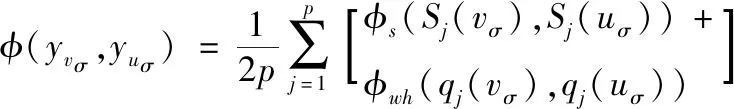

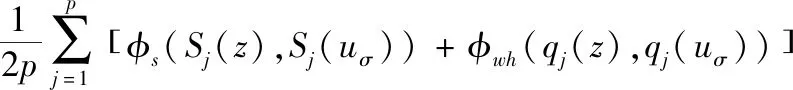




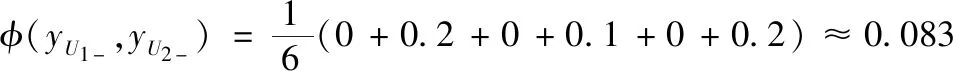
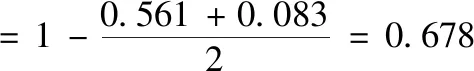
3.3 生成推荐预测

4 实验研究与算法评价
4.1 算法的评估标准

4.2 实验数据集的来源
4.3 对比算法
4.4 实验过程与结果分析




5 结论
