基于改进蚁群算法的错架图书边缘特征提取
2021-11-17郑若池
朱 瑛,谢 睿,郑若池
(沈阳航空航天大学机电工程学院,辽宁 沈阳 110136)
1 引言
在图书馆的管理与运维中,对错架、错序图书的分拣和归类是其中最为繁琐的工作。常规的人工分拣不仅会浪费大量的人力、物力,而且还存在遗漏多,效率低的问题。随着智能机器人技术的发展,机器人应用的领域也越来越广泛,将智能机器人技术应用于图书馆的运维中能极大地节省图书馆的工作开支,提升图书馆的服务效率。要实现通过机器人完成对错序图书的分拣和识别,需要对书架上图书的书名,轮廓大小等边缘轮廓特征进行识别和提取。传统的以一阶微分和二阶微分为基础的边缘检测算子对噪声敏感,在边缘检测和提取时会出现图像边缘缺失,边缘不平滑的现象[1]。为了提高图像边缘检测的稳定性和精确性,避免噪声对图像检测结果的影响,本文采用改进的蚁群算法结合高斯金字塔模型对图书的边缘进行检测提取。
蚁群算法自从1991年由意大利科学家Marco Dorigo等人首次提出,由于其具备正反馈性,自启发性,强鲁棒性,并行性等一些优良的特性,在图像边缘检测中蚁群算法与遗传算法[2],粒子群优化算法[3]等多种智能算法相结合,都取得了良好的边缘提取效果。蚁群算法在对图像边缘轮廓进行提取时,初始设置的参数和信息素矩阵分割阈值的选取对提取的边缘效果有着很重要的影响[4]。本文通过建立目标图像的高斯金字塔图像,通过对每层图像的边缘检测提取出重要特征区域,根据特征区域位置调整蚁群分布位置,依次映射迭代,在底层图像中采用二维otsu算法对信息素矩阵进行分割提取出完整清晰的边缘特征。在对蚁群算法初始参数的选取中利用GA-BP神经网络寻找出最优参数组合。
2 蚁群算法的初始参数分析与设定
蚁群算法是基于蚂蚁种群的觅食行为而提出的优化算法,Marco Dorigo曾经归纳总结了蚁群优化算法成功解决的问题[5]。但其存在着进化速度慢,容易陷入局部最优解,随着解决问题规模的扩大寻找到最优解所需要的迭代次数也随之增加的缺点,设定合适的初始参数能在一定程度上避免陷入局部最优解,在尽可能少的迭代次数里寻找到最优解。为了寻找蚁群算法的最优初始参数,本文通过训练GA-BP神经网络,利用Pratt提出的品质因数[6]作为蚁群算法算子优劣的客观评价标准,寻找出最优初始参数组合品质因数的取值范围介于(0,1],品质因数越高表明,该种初始参数组合越接近理想最优参数组合。
在蚁群算法的三种系统中蚁周系统中信息素的释放对全局信息的依赖性更强,信息素的含量于最优解成正比,可以在一定程度上避免陷入局部最优解,而蚁密和蚁量系统只依赖于局部信息,容易陷入最优解[7]。因此,本文着重利用蚁周系统进行建模和对其初始参数进行分析。蚁群算法中的初始参数有:每次迭代所使用的蚂蚁的数量m,信息启发因子α,期望启发因子β和信息素挥发因子ρ,其中蚂蚁数量m的取值在接近目标图片的像素点个数时效果最好。
蚁群算法的最优参数组合获得的流程如图1所示,为了保证算法能发挥正反馈效果,增强梯度值对蚂蚁选择概率的影响,α和β的取值在(0,1],ρ在(0,1)的范围内[8],将三个初始参数按步长0.1选取后随机排列组合,收集在不同初始参数组合下提取的边缘特征图像的品质因数,本文所检测的图像为128×128的棋盘格相机标定板图像。得到的数据中将3个初始参数作为神经网络的输入,相应的品质因数作为网络的输出,来训练所搭建的BP神经网络,本文中采用3-7-1三层BP神经网络,训练数据为950组,测试数据为50组。测试结果图像如图2所示,网络预测输出的均方误差为1.0122×10-4,网络训练比较成功,最后将初始参数作为遗传算法中的种群个体,神经网络预测的品质因数作为个体适应度,适应度越大,参数组合越佳。通过遗传算法得出最佳的品质参数和最优的初始参数组合如表1所示。该参数组合与穷举法求解最优参数组合所得出的结果一致,GA-BP神经网络求解最优参数组合的方法是有效的。

图1 GA-BP神经网络算法流程图

图2 神经网络预测输出 图3 遗传算法适应度曲线
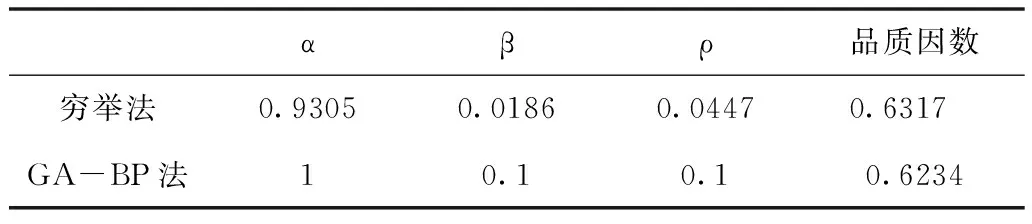
表1 最优参数组合及品质因数值
3 图书图像边缘检测
将蚁群算法应用到图像边缘处理上时,将预处理的图片看作是一幅无向图,无向图中的像素点看作是蚂蚁运动的节点,所采集图像的灰度梯度作为蚁群算法的期望启发因子。本文边缘特征检测流程如图4所示。

图4 图书边缘特征检测流程
首先对采集的图像进行winner滤波去噪,图片增强等预处理,降低外界噪声对目标检测图像的干扰,通过高斯函数对图像进行采样,构建高斯金字塔图像,高斯金字塔模型如图5所示,高斯金字塔的层数根据初始图像大小来决定,本文所采集的图书图像大小为1024×1024,建立四层高斯金字塔。

图5 高斯金字塔模型 图6 像素点邻域示意图
依次从顶层到底层对目标图像利用蚁群算法进行边缘检测,蚂蚁所处的像素点为I(i,j),可视距离可为8-邻域(如图6),蚂蚁向各个邻域I(x,y)转移移动概率P(如式(1))

(1)


(2)

在对目标图像的边缘提取时,顶层图像中的蚁群随机分布,之后在每一层图像的边缘边缘特征图像后,统计各个区域内像素点的数量,划分出像素点密集的重要特征区域和像素点稀疏的非重要特征区域(本文区域划分为矩形),该区域映射到下一层图像,在下一层图像的边缘检测中,保证总体蚁群数量不变,在重要特征区域按统计像素点数量占总像素点数量的比例增加该区域内初始蚁群数目,相反,在非特征区域比例减少初始蚁群数量,同时增加小图像上的迭代次数,较少大图像的迭代次数,这样能实现实现了在保证边缘提取完整的情况下增加边缘检测的速度。
4 改进二维otsu算法的阈值选取
对通过蚁群算法得到的信息素图像进行阈值分割,才能提取出目标图像的边缘特征,本文在对信息素图像分割时在二维otsu斜分快速算法的基础上通过对概率密度分布曲线拟合的方法,求出斜方窄带区域的大小,极大提升图像分割的质量和普适性。1993年刘健庄提出二维otsu算法,这种算法考虑到边缘像素点对中心像素点的影响,具有更佳的抗噪能力[9]。二维otsu将像素灰度值的分布和邻域像素的平均灰度值构成一个二维向量,利用目标和背景区域内的像素点其灰度值和其邻域平均灰度值相似,而边缘和噪声区域内的像素点其灰度值和其邻域平均灰度值有很大的区别的特点。设定阈值向量(s,t)将二维直方图分为四个区域如图7所示,区域Ⅰ和Ⅱ代表目标或者背景类,区域Ⅲ、Ⅳ代表边缘和噪声。通过遍历目标图像找出满足目标类和背景类最大类间方差的(s,t)向量作为最优的分割阈值。

图7 二维直方图的平面投影 图8 判决域划分图
传统的二维otsu算法将区域Ⅲ和Ⅳ的联合概率密度视为0,这种假设在对角线附近区域是不成立的,为此二维otsu斜分快速算法[10]将平行于对角线的窄带区域V作为目标类和背景类,通过与对角线垂直的斜分线来区分目标类和背景类,区域Ⅵ、Ⅶ代表边缘和噪声,如图8所示。本文先统计得到在对角线方向上不同斜率下像素概率密度的分布曲线,在通过多项式拟合得到概率密度分布曲线,对曲线求导,从曲线两端以一定步长(该步长大于1)向内搜索,找出导数变化大的区域,然后再在该区域内以定步长1找出导数变化最大的节点M1和M2,和概率密度分布峰值点N,若|M1N|≠|M2N|则取两者中的最大值作为K1和K2,若|M1N|=|M2N|则K1和K2等于|M1N|完成判决区域自适应划分。最后通过最大类间方差找出斜分线截距,得到斜分线的方程,将区域V划分为前景和背景,实现对目标图像的分割。
分别用传统二维otsu算法和改进的二维otsu算法对Lena图像进行阈值分割,改进的二维otsu算法中计算得到概率密度分布曲线得出K1=K2=20构成判决域时,分割的效果最好,结果如图9所示。

图9 二维otsu算法分割对比图
5 实验结果与分析
分别采用本文的边缘检测算法和传统的边缘检测算子在有噪声干扰下的情况下对采集到的图书图像进行边缘提取得出的结果如下,在本次实验中添加均值为0,方差为0.1的高斯噪声,实验结果如图10所示。

图10 图书的边缘特征提取效果
通过实验直观的发现在有噪声的干扰下,本文中的蚁群算法相对于传统的canny边缘检测算子和传统的蚁群算法所检测提取的边缘特征更加清晰、完整,有一定的抵抗噪声的能力,能满足实际工作过程中的需求。
6 结论
通过以上的实验证明,在蚁群算法的应用中,对蚁群算法初始参数的分析和确定,能提升蚁群算法的鲁棒性,本文通过GA-BP神经网络寻找最优参数组合的范围,而且在图书边缘特征提取的应用中取得良好的处理效果。同时也为蚁群算法在其它领域应用时初始参数的确定提供一种方法,通过高斯金字塔映射优化蚁群初始位置的放置,提高算法的搜索效率,同时也避免蚁群陷入局部最优解。利用改进的二维otsu算法实现判决区域的自适应调整,不仅可有效地较少噪声对检测的边缘的影响,而且使提取的图书边缘特征更丰富完整。
