基于RBF神经网络的全局光照实时绘制
2021-11-17刘晓芸姚承宗曾晓勤
刘晓芸,姚承宗,曾晓勤
(河海大学计算机与信息学院,江苏 南京 211100)
1 引言
在真实感图形绘制中,全局光照能够为场景提供更为丰富的光影效果,通过计算光线的多次反射、折射能够产生更为逼真的光影细节。早期实现全局光照绘制的算法主要有光线跟踪[1]、辐射度[2]、光子映射[2]等。这些基于间接光照的算法,需计算光线在物体之间的多次反射、折射,与光源特性、场景中物体的物体特性以及物体的相对空间位置等有关,因而计算量巨大。
随着可编程GPU出现,涌现出一些使用GPU对全局光照进行加速的算法。如周昆[1]等提出了在CUDA上构建KD树的新算法,核心是对KD树中的大结点和小结点分别处理,该方法能够充分利用GPU的并行计算能力,明显提高渲染速度。但大结点分割质量比较低,而且排序过程的计算量比较大。Wang等人[5]提出一种基于GPU的分割数据采样和插值的全局光照方法,该方法通过自适应的K值聚类,将场景分割成条理分明的簇,对每一个簇使用基于GPU的光子图法来计算其辐照度,最终将每一个光子图切片整合。由于分割只进行了极有限次数的采样,该方法会丢失一些几何特征,并且在实现上受限于现存的时序算法。
为了提高渲染速度,有一些通过牺牲渲染精度为代价的方法被提出,如Keller[6]提出将来自一个反射面的反射光线拟合成一组虚拟点光源来简化计算,但这一方法忽视了折射和反射的细节。Dachsbacher[7]通过机器学习的方法,根据不同的能见度对场景进行分层,对能见度较高的层,用精度较高全局光照模型进行计算,对于能见度较低的层,则使用精度较低的模型进行计算。采用该方法渲染的场景部分区域较为精细,而其它部分较为粗糙。Kaplanyan[8]通过三维场景中的光能传播来拟合间接光照值,然而其只能拟合漫反射表面的间接光照。
还有一些方法通过预计算的方法来实现全局光照的实时绘制。如Sloan[9]提出的预计算辐射亮度传输(precomputed radiance transfer PRT),在静态场景中将物体表面的低频光照包括全局光照产生的阴影以及物体相互之间的反射关系等转化成辐射度传输,从而计算静态环境对于各个方向光源的反射数据等,在进行渲染时调用这些计算结果,可以实现动态低频光照的全局光照效果。由于动态的光源和高频发光之间的相互反射,绘制动态场景的效果不理想。Ren等人[10]则构建了一个多层前馈神经网络作为光照回归函数(radiance regression function RRF)来拟合间接光照值,通过预先渲染好的场景作为导师数据对网络进行训练,使用训练好的网络拟合间接光照值,能实现场景的实时渲染,然而其网络过于复杂,冗余数据较多,收敛较慢,并且无法实现动态场景的拟合。
径向基函数(Radial Basis Function, RBF)神经网络[11]能够逼近任意的非线性函数,可以处理难以解析表示的映射,具有良好的泛化能力和较快的学习收敛速度,已成功应用于非线性函数逼近、时间序列分析、数据分类、模式识别、信息处理、图像处理、系统建模、控制和故障诊断等方面。RBF网络是一个局部逼近网络,也就是对输入空间的某个局部区域只有少数几个连接权值影响输出,因此它较每一个权值都要调整的全局逼近网络具有更快的收敛速度。
本文将回归分析方法引入全局光照的渲染过程之中,使用RBF神经网络构建学习模型,对通过蒙特卡洛光线跟踪方法得到的光照样本数据集进行学习,确定每个基函数单元的宽度、中心及隐含层与输出层单元之间的权值矩阵,从而发掘出每个场景对象表面可见点的特征属性之间的非线性关联。实验表明,基于RBF神经网络学习模型的全局光照技术可以很好地拟合蒙特卡洛离线渲染的结果,用其构建神经网络模型来拟合光照计算,可以避免传统光线跟踪过程中繁杂的光线求交计算,在确保渲染精度的同时,提高了场景渲染的速度。
2 光照方程
针对点光源的静态场景,由Peter[12]提出的光照方程,可以得到在视点Θ处观察到场景中点x处的反射光照强度为

(1)
Lr(x→Θ)=Ldirect+Lindirect
(2)
其中Ψ为光源位置,Ωx为x点附近的球面,fr表示点x位置处的双向反射分布函数(Bidirectional Reflectance Distribution Function, BRDF),Nx表示点x位置处的表面法向量,Li表示点x位置处来自方向i的入射光亮度。G(x,y)表示x与y的光线传输几何关系,V(x,y)表示两者的能见度关系。
根据BRDF的定义,有
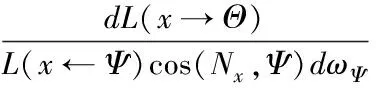
(3)
由于场景中物体表面都是固定的,可以看出,BRDF是一个与点x的位置、入射光线和视点位置有关的函数,因而可以将其简化为如下三元组
fr(x,Ψ→Θ)=fr(f(x),Ψ,Θ)
(4)
式(2)中Ldirect表示直接光照值,Lindirect表示间接光照值。
对于Ldirect部分,本文采用自适应采样的蒙特卡洛方法来进行加速,Lindirect部分则通过RBF网络进行模拟。
为了叙述方便,对公式进行归一化,用n表示x处的单位法向量,s表示光源方向单位向量,v表示视点方向单位向量,可以将Lindirect部分简化为

(5)
3 RBF神经网络学习模型
3.1 构建RBF神经网络
本文对间接光照的解决方法是将其视为一个神经网络的学习问题来解决。
根据式(5)可以定义一个与x,s,v,n,f有关的函数Lin用来拟合Lindirect
Lindirect≈Lin(x,s,v,n,f)
(6)
对于确定的场景,Lin是一个固定的函数,可以通过计算光线传输来得到任意视点、光源以及位置x处的Lin函数。如果采用传统的光线跟踪算法进行计算,因涉及到光线多次求交的问题,算法复杂性很高。
本文采用RBF神经网络方法,根据不同场景的特征值,拟合出一个该场景下计算间接光照值的函数,避免了光线求交计算,实现静态场景的实时渲染。
根据式(6)可以构建如图1所示的RBF神经网络,这是一个R12+nf到R3[r,g,b]的映射。

图1 RBF神经网络
其中x=(a1,a2,a3),s=(a4,a5,a6),v=(a7,a8,a9),n=(a10,a11,a12),f=(a13,…,a12+nf),将训练网络得到的拟合函数记为Lnet。通过拟合函数计算每个像素的间接光照值
B=[r,g,b]=Lnet(x,s,v,n,f)
(7)

3.2 网络参数初始化及训练
采用监督学习算法对网络所有的参数(RBF的宽度、中心及隐含层到输出层的权值矩阵)进行训练。主要工作是对代价函数进行梯度下降,然后修正每个参数。
通过减聚类算法[13],将得到的聚类中心作为RBF的中心Φi(i=1…P)。采用减聚类算法原因在于在该算法中,数据集本身作为聚类中心的候选集。算法所涉及的计算量与数据点的数目之间呈现为简单的线性关联,与维数无关,可以有效减小网络规模。具体过程如下
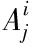


针对ΩZ中的元素,根据减聚类的定义推导出其密度指标计算式(8)

(8)
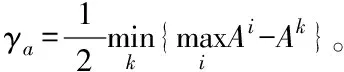
4) 对式(8)密度指标迭代公式进行修正,得到新的密度指标迭代式(9),选取密度指标最高的数据点作为新的聚类中心。

(9)
选取好聚类中心Φi(i=1…P)后,采用随机分布,初始化隐含层到输出层的权值wi。采用梯度下降法对网络中的三种参数都进行监督训练优化,代价函数的表现形式见式(10),表示网络输出和理想输出的方差与输入规模的比值。

(10)
4 渲染
4.1 直接光照
在合成一副图像的时候,不同区域的灰度值变化不同,细节的丰富程度也不一样。对于细节比较丰富的图像区域,需要进行较多次数的采样,才能详细的描述出该区域的细节特征。而针对细节比较少的图像区域,进行较少次数的采样就能描述出该区域的细节特征。自适应采样算法[14]就是根据图像当前区域细节的丰富程度决定其采样次数。
具体实现时,首先采用均匀分布的方式分布初始采样点。
然后,采用非局部均值方法去噪,在合成图像的时候,生成两个采样点相同的缓冲区域A和B。
假设在缓冲区A中有两个相邻像素点p和q,在对像素点p进行去噪处理时,首先计算在缓冲区A中以p为中心的区域和以q为中心的区域之间的加权欧氏距离,计算公式见式(11),其中,f为区域大小。
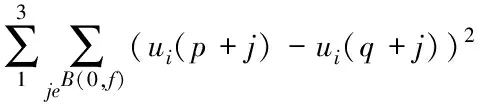
(11)
通过式(12)求出权值。

(12)
将求取的权值代入式(13)去计算B缓冲区的图像。
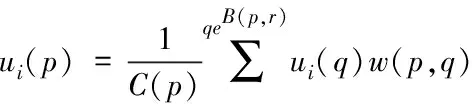
(13)
同理,使用B缓冲区中得到的权值去计算A缓冲区中的图像,这样可以消除滤波系数和噪声之间的相关性。最后利用两幅图像之间的差值来表示错误率,其计算见式(14),其中N(p,f)表示这一区域的均值。

(14)
错误率越高,表示这一区域的细节越丰富,根据错误率来重新分配采样点。
如此反复迭代,完成采样,之后用经典的光线跟踪算法完成直接光照部分的渲染。
4.2 间接光照
完成对RBF网络的训练之后,便得到了拟合函数Lnet,可以用其对间接光照值进行拟合,得到该场景中不同光源位置和视点位置情况下各点的颜色值。
对于一组视点V和光源S,可以得到在该视点下需要渲染的场景点x,计算得到x处的法向量n和纹理映射f,从而对于任意需要渲染的像素点,都有一组归一化的输入向量[x,s,v,n,f],通过拟合函数即可得到该像素点的R、G、B颜色分量,即间接光照值。
将每个场景点的直接光照和间接光照进行叠加,得到最终的渲染图像。
5 实验结果和分析
通过使用Mitsuba进行离线渲染,获取训练数据。使用Matlab对神经网络进行训练。再用训练好的网络对输入数据进行拟合,得到输出的图像。实验平台为: i5处理器、3.3GHz主频、8G内存、2G显存。
本文采用了随机采样和基于高斯分布的采样两种方式选取样本点,两种采样方式在神经网络的训练时间、收敛速度和渲染精度方面均无明显差别。
针对同一场景,由于同一面的单位法向量相同等原因,所以在最终获取到的训练数据中,存在大量冗余数据。在训练前,先将这一部分冗余数据剔除。
分别用BP网络和RBF网络进行了求解,对于Smallpt场景,拟合的间接光照效果如图2所示。

图2 间接光照拟合效果
RBF网络拟合的间接光照与直接光照叠加,得到最终渲染图像,效果如图3所示。

图3 离线渲染效果和本文方法效果
在不同的视点位置下渲染结果如图4所示。

图4 不同视点位置下的渲染效果
图5是 Sponza场景在不同规模训练数据下的渲染效果。

图5 Sponza场景不同规模训练数据下的渲染效果
实验发现,但当训练数据达到一定规模时,单次训练时间不断增加,网络收敛速度越来越慢,错误率下降越来越慢。实验还发现,最终的训练时间与场景大小和离线渲染的训练数据大小无关,而与有效的向量数量有关,以两个不同大小的场景Smallpt和Sponza为例,两者场景大小相差很大,离线渲染得到的训练数据量相差也很大,但是有效向量数量接近,因而其最终的训练消耗时间也类似。由于都是较小规模场景,在相同拟合误差要求下,RBF相对BP网络能更快收敛,其效果好于BP。具体比较见表1。
6 结束语
采用RBF神经网络拟合的方法来实现间接光照,可以避免在传统的光照模型中光线多次求交的问题,实现全局光照的实时绘制。虽然由于RBF网络本身的局限性,在对较为复杂的场景渲染时,输入空间增大,泛化能力下降,训练时间增加。但较之前使用BP网络的拟合方法,不易陷入局部极值,有更快的收敛速度和更好的拟合效果。
在后续工作中,考虑使用多个网络并行对场景中不同的特征值进行处理,以应对更加复杂的场景和动态场景。

表1 不同场景比较
