基于ALAD算法的数据库MAR均衡分配仿真
2021-11-17宿敬肖张丽娟李明亮
刘 平,宿敬肖*,张丽娟,李明亮
(1.河北工程技术学院,河北 石家庄 050000;2.河北地质大学,河北 石家庄 050030)
1 引言
在信息化影响下,用户的访问需求逐渐增加,但由于大部分数据库中缺乏平衡功能,导致出现高负载问题,严重影响整体性能与用户满意度。而均衡分配策略能够在数据库高负载情况下,将任务从负载繁重的服务器转移到没有负载压力的服务器中,有效控制系统负载情况,因此成为相关学者关注焦点,并研究出一些较好的方法。
文献[1]提出基于主题相关特征挖掘的数据库资源均衡分配方法。利用决策随机变量建立多属性资源关联模型;根据皮尔逊有关系数完成资源间主题相似性度量,获取多样化的多属性资源特性;通过二次聚类得到资源特性训练数据的原始聚类情况,定义神经网络隐含层分配节点,改善资源分配速度。文献[2]利用数据库信道属性权重法实现资源均衡分配。构建数据库干扰模型,根据流量负载与干扰链路设计权重,将属性权重作为判断信道优先级的依据,权重较高的链路具有优先选择权。在此过程中,如果获得的权重是静态的,为改善实用性与动态性,引入动态迭代学习算法,在原有算法上通过梯度下降完成权重调整,达到按权重分配目的。上述两种方法虽然提高了资源分配的均衡度,但是当服务器处于高负载情况时响应延时较长,均衡误差率高,无法实时反映系统真实运行情况。
为解决上述传统方法存在的问题,本文利用ALAD(Application Layer Adaptive Dynamic)算法对数据库多属性资源进行均衡分配,收集服务器负载数据,对这些数据进行计算得出每台服务器负载权重,再结合权重信息实现资源均衡分配。仿真结果证明,该方法可提高数据库资源利用率,有效改善响应延时问题。
2 基于ALAD算法的服务器负载综合权重计算
ALAD为应用层自适应动态负载均衡算法,该算法将不同服务器的响应延时当作参考,以请求处理成功率与运行时间为辅助。在进行分配过程中,使用ALAD方法计算服务器总体响应延迟情况,以此信息作为数据库高负载[3]的首要原因。并获取服务器处理错误率与最大连续运行时间,从而得出数据库中不同服务器权重。详细过程如下所述:
步骤一:计算响应延时原因LatFact。
设定不同服务器处理请求的传输时间表示为rsent,处理时长为rproc,接收时间是rreci,通过式(1)计算所有服务器处理请求的整体延时[4]情况
lat=rsent+rproc+rreci
(1)
lat表示为服务器自身负载情况与各服务器之间的关系。如果lat值较低,则说明服务器处理能力强,结合lat可得到数据库中所有影响服务器延时的因素LatEactK,通过下述公式表示

(2)
步骤二:计算服务器请求处理的成功率SuccFact。
在负载均衡处理器上记录由elct表示的所有服务器处理请求的次数,假设fault为处理出错的次数,结合采集数据,求出SuccFact
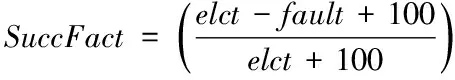
(3)
步骤三:计算影响连续服务时间的因素TimeFact。
采集每个服务器连续运行时间t,根据采集的数据计算全部服务器中持续运行时间的最高值tmax,计算公式如下
tmax=max(t1,t2,t3,…,tn)
(4)
结合上述公式获取TimeFact表达式

(5)

(6)
式中,tdiff表示服务器受到的运行压力,此种压力在服务器刚开始运行时较低,随着运行时间推移压力明显增加。
步骤四:计算每个服务器负载综合权重LoadFact。
利用式(6)获取的三个因素值,对服务器负载综合权重进行计算,公式如下
LoadFact=⎣LatEactK×SuccFact×Fact」
(7)
式中,LoadFact的值应和当前阶段服务器与网络负载性能相对应。
利用ALAD算法经过上述过程计算出数据库中各服务器的负载综合权重,为实现资源均衡分配奠定基础。
3 数据库多属性资源均衡分配
3.1 特性提取
本文通过构建TG-LDA模型对多属性资源进行特征提取,利用决策随机变量挖掘多属性资源间共有与独有主题,同时结合皮尔逊相关系数获取资源主题间相似性度量,以此提取资源的不同特性。
设定θ代表对M个资源文本形成的主题分布,针对资源文本生成N′个特征词,利用η描述某个参数,此参数可以调节决策随机变量γ的取值。将决策变量引入到TG-LDA模型中,使不同种类的主题与资源生成过程相结合,则上述过程变换为概率模型[5]形式表示为

(8)
通过多次计算得到最终的资源文本主题分布θd与特征词分布φz的后验预测值

(9)
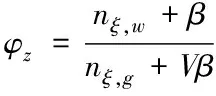
(10)
式中,nd,ξ表示资源文本d分配到主题ξ的词语数量,nd,g代表文本d全部被分配到主题g的词语数量。α、β、T与V均属于参数。
将JSD距离当作多属性资源共有和独有主题间相似度信息,通过下述公式获取两种资源离散概率分布P和Q的JSD距离

(11)


(12)

(13)
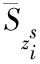


(14)
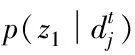

(15)

3.2 多属性资源均衡分配的实现
传统资源分配方式并没有分析数据库节点计算能力的区别,在对不同特征资源进行分配时,容易导致数据倾斜[7],降低数据库整体性能。本文综合考虑上述问题,依据上述特征数据,利用改进的遗传算法实现多属性资源均衡分配。
3.2.1 数据分片
在资源分配过程中,通常是针对数据片进行,结合上述资源特征确定数据分片[8]情况。每片中的信息既要符合完全性又要确保一致性。另外在分片时还需分析分片大小,如果分片太大,则不能很好体现数据库集群性能;反之,分片太小,会导致单个节点启动与终止时间过大。
假设n′个处理器同时对群表进行扫描所需要的时间计算公式表示为
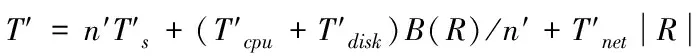
(16)
利用下述公式求导,确保T′具有最小值

(17)
因此n′成为了数据分片的最佳并行度,如果某个关系被划分成多个处理器,这时阈值B(R)必须符合下述条件

(18)
只有满足上述要求,才能实现数据最佳分片,提高资源利用效率。
3.2.2 选取分配属性
在资源分配过程中,需要利用多种属性进行选取。分配属性的选取影响着数据库查询成本,本文按照以下过程进行分配属性选择:
1)获取文本的相关连接属性;
2)查找文本中groupby属性或orderby属性;
3)详细的划分属性选择法表示为:输入关系集合R1,R2,…,R7,连接图G=(V,E),输出属性集合;
4)计算连接图G=(V,E)的连接属性收益,获取收益值最高的属性A′与其关系集合;
5)不断更新收益值,经过上述过程即可确定最佳划分属性。
3.2.3 资源均衡分配
根据代价最低原则,使用改进的遗传算法对所有待分配的数据片进行分配,以此获得数据库多属性资源均衡分配策略。具体步骤如下:
步骤一:资源编码[9]。将资源分配方法当作遗传种群的某个个体,利用二进制编码方式对其编码,保证编码长度和数据库中站点个数相同。假设1表示待分配信息片段被分配的站点位置,0代表某编码个体与一个信息片段分配方法相对应。

(19)
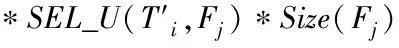
(20)
由此可知,待分配信息片段的更新与检索访问量的比值就是信息片段的更新检索比[10]。
步骤三:种群初始化。种群规模过大或过小均无法获得最优解,所以结合更新检索比完成种群初始化操作。
如果分配的信息片段符合U/Q<1,则需设置大量副本,若U/Q>1,应将副本数量控制在最小范围内。
步骤四:个体评判。利用有关公式获取种群个体适应度,在分配过程中,该值体现分配方法的性能,和总代价之间具有反比关系。代价越大适应度值越小,此个体被留下的可能性就越低;反之,此个体有可能遗传到下一代。
步骤五:选取优良基因。该过程遵循“优胜劣汰”准则,将具有优良基因的个体遗传到下一代。
选取优良基因后,获得个体适应度和种群适应度二者的比值,计算此个体被遗传给下一代的几率,则个体被挑选的概率值表示为

(21)
对比当前个体和下一代个体的最优适应度值,如果当前个体具有优势,则利用该个体替换下一代个体。
步骤六:交叉计算,该过程表示基因重组。不同个体之间结合交叉几率实现随机匹配,概率值越高表示此个体更容易引进新的基因;反之,容易导致搜索停滞。本文利用自适应交叉算子来获得适当的交叉概率:

(22)
式中,Fmax与Favg分别表示种群内个体最高与最低适应度值,Fe则是两个交叉个体中较大的适应度值,本文取Pe1=0.8、Pe2=0.4。
步骤七:变异操作,该操作能确保个体遗传具有多样性。遗传过程根据自适应变异算子完成变异,维持遗传搜索和多样性之间的平衡。变异操作可利用如下公式表示

(23)
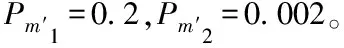
步骤八:通过上述交叉变异等操作形成下一代新种群,根据计算得出的各服务器负载情况,设置最大迭代次数,如果低于设定值,则需返回步骤四重新进行;反之输出结果,在最新种群内,最优个体就是资源最优分配方案。重复以上过程,直到全部待分配资源片段均找到最佳分配方案为止。利用该方法即可实现数据库多属性资源均衡分配。
4 仿真数据分析与研究
为验证提出的基于ALAD算法的数据库多属性资源负载均衡分配方法的可行性,需设置仿真。在Cloud Sim2.0环境下搭建仿真平台。假设所有资源节点均是随机产生的,节点数量在20~100个之间,虚拟节点数量在5~30个之间,虚拟节点同样是随机产生的。
为更好体现本文方法的优势,彰显仿真的公平性与全面性,将实验分为两个不同阶段,并分别利用文献[1]方法、文献[2]方法与本文方法进行对比。首先对三种方法资源利用率与分配均衡程度进行验证,实验结果分别如图1和图2所示。

图1 不同方法下数据库资源利用率对比

图2 不同方法下数据库资源分配均衡度对比
由图1和图2可知,随着用户数量不断增加,所提方法的资源利用率持续提高,分配均衡度较为稳定,表现出良好的资源分配能力,这是因为改进的遗传算法可以获得最佳资源分配策略;文献[1]方法虽然资源利用率也有所提高,但与本文方法相比提高速度较慢;而文献[2]方法由于用户增加,负载过大,均衡度明显下降,因此无法保证资源被有效利用。
此外,在仿真中通过计算机并发大量请求,使数据库处于高负载状态,对比三种方法的平均响应时间,对比结果如图3所示。

图3 不同方法并发响应时间对比图
图3所得实验结果说明,当数据库在较低的并发连接状态下,负载很低,所提方法略高于文献[1]与文献[2]方法,随着并发连接次数不断增多,数据库逐渐处在高负载状态,本文方法响应时间明显低于其它两种方法。主要因为本文方法对不同服务器的负载权重进行计算,可以准确体现出系统运行状况,减少均衡误差,提高响应速度。
5 结论
为提高数据库资源利用率,利用ALAD算法计算不同服务器负载综合权重,再采用改进的遗传算法确定最佳分配策略,实现数据库多属性资源均衡分配,仿真结果证明了该方法的优越性。但是在对数据库的认知方面,本文并没有研究数据库真实架构。所以在下一步的研究中重点分析数据库结构,结合数据库特征进一步完善分配方法,以此满足更多用户需求。
