基于共享BERT和门控多任务学习的事件检测方法
2021-11-16陈佳丽姚建民
王 捷,洪 宇,陈佳丽,姚建民
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
事件抽取是信息抽取研究领域的重要任务之一,旨在从非结构化文本中抽取出事件相关的结构化信息。事件抽取任务由4个子任务组成:触发词识别、触发词类型分类、论元(相关实体)识别及其角色分类。其中,触发词识别及其类型分类两个子任务合并称为事件检测(Event Detection,ED)。简言之,事件检测任务的目标是从文本中识别并分类提取事件的触发词。例如,识别例1中的触发词“dead”,并分类标记其事件类型为“Die(死亡)”。
例1Eighteen people are now reported dead.
近期,神经网络在事件检测任务中得到了广泛运用,有效缓解了传统方法对手工特征的强依赖问题,并且使得模型具有更好的泛化能力。然而,大部分模型受到训练数据规模的制约,感知语义的广度不够宽泛。在预测超出词表(Out of Vocabulary,OOV)或者未曾标注(Out of Label,OOL)的词项时,往往无法做出正确判断。现有训练数据扩展方法[1]能够在一定程度上解决这一问题。但是,数据扩展方式所需的外部数据获取困难,并且需要设计高效的审核机制避免引入额外的噪声信息。在此情况下,多任务学习架构和预训练模型展现了新的潜在应用价值。例如,Liu等[2]提出事件检测和论元检测的多任务[3]模型,并证实在数据未扩展的前提下,多任务学习架构有利于对事件表述中共享知识的深度语义的理解。此外,预训练模型BERT[4]则借助大规模通识数据之上的预训练机制,降低了不同自然语言理解任务对各自训练数据的依赖性,并突破其束缚,为表示学习过程提供更为宽泛的语义信息。
根据上述多任务学习架构和预训练模型的优点,本文提出一种基于共享BERT的多任务(事件和实体识别任务)表示学习模型,并将其应用于事件检测任务场景之中。该模型通过在不同任务之间共享BERT层的学习参数,同时促进表示学习的深度和广度。此外,为了更有效地协调不同任务的训练效率,本文设计了一种预测损失的门控机制,借以同时促进多任务和单任务的最优解逼近。基于ACE2005数据集的实验验证,上述模型取得了明显的性能提升,在F1测度上分别取得79.5%和76.5%的性能。实验证明,性能改进主要来源于召回率的显著提高,反映了该模型能够感知语义范畴更为宽泛的事件信息。更为重要的是,本文实验部分对多任务的学习过程进行了可解释性研究,通过与单任务模型进行对比,从错误样例分布方面进行了多任务特性的详细解析。
本文的组织结构如下:第1节介绍事件检测任务的相关工作;第2节介绍基于BERT的门控多任务学习模型;第3节介绍实验设置、测试结果,以及对多任务学习过程的可解释性分析;第4节总结全文。
1 相关工作
事件检测任务是信息抽取研究中的重点内容。传统的事件检测方法依赖于人工构建的手工特征,无法学习文本的潜在语义。如Liao等[5]利用文档级别的跨事件信息来预测当前事件的触发词。Hong 等[6]利用不同实体和触发词之间的依赖关系,构建了跨实体的事件检测模型。Li等[7]利用全局特征,获得不同事件触发词和论元之间的依赖关系。
近年来,神经网络在事件检测任务中得到了广泛的应用。Nguyen[8]等首次将卷积神经网络用于事件检测任务,缓解了传统方法因为抽取特征带来的错误级联问题。Chen等[9]设计了一个词表示模型自动捕获单词相关的语义规则,并提出动态多池化卷积模型,提升了CNN在多事件样本上的性能。Nguyen等[10]首次采用双向循环神经网络进行事件检测任务,充分利用了单词前后的时序信息。Nguyen等[11]提出用非连续卷积的方式处理文本中非连续的语义信息。Liu等[12]设计了一种有监督的注意力机制,根据论元信息,突出相关词项在句子中的重要性。Hong等[13]提出利用对抗学习方法强化对错误的学习。Chen等[14]提出一种基于多层注意力机制的偏置网络,用以自动提取句子和文档级的信息。Zhao等[15]提出利用文档级向量改进双向RNN方法。Lu等[16]提出了一种新的表示学习框架,该框架可以学习到包含判别知识和生成知识的语义表示。
目前,多任务模型已在事件检测任务中得以应用。如Yang等[17]提出一种自动学习事件和实体之间依赖关系的方法,并提出文档级的事件和实体的联合抽取模型。Sha等[18]提出基于依赖桥的循环神经网络方法,联合抽取事件和实体。Tang等[19]通过多任务的模型架构,将模型输出层同时进行事件检测任务和可解释性的规则生成任务,提升了事件检测的性能。此外,BERT预训练模型在事件抽取的其他子任务中表现出了卓越的性能。Yang等[20]利用BERT的训练过程进行额外的数据扩充,解决了论元角色重叠问题。Tong等[21]利用BERT编码文本信息和图片信息,通过双重注意力机制进行特征选择,达到信息增强的效果。
2 基于BERT的门控多任务学习模型
本文构建了以BERT为共享编码层的双通道多任务神经网络模型(Multi-task Learning on Shareable BERT,MSBERT),模型架构如图1所示。其中,BERT的参数被所有任务所在的编码通道所共享,同时,每个任务在训练过程中都参与BERT的自动参数微调(Fine-tuning)。此外,每个通道都设置了一层非线性全连接网络(Fully-Connected Network,FC),其在训练过程中,都接受来自单一任务的预测损失,并借以独立驱动反向求参。相应地,每个通道都在FC层之后拼接感知机进行任务约定的预测。本文实验部分测试两套MSBERT,两者都将事件检测作为主任务,但分别使用 “事件提及”识别(Mention Identification)和实体识别(Entity Recognition)作为辅助任务。
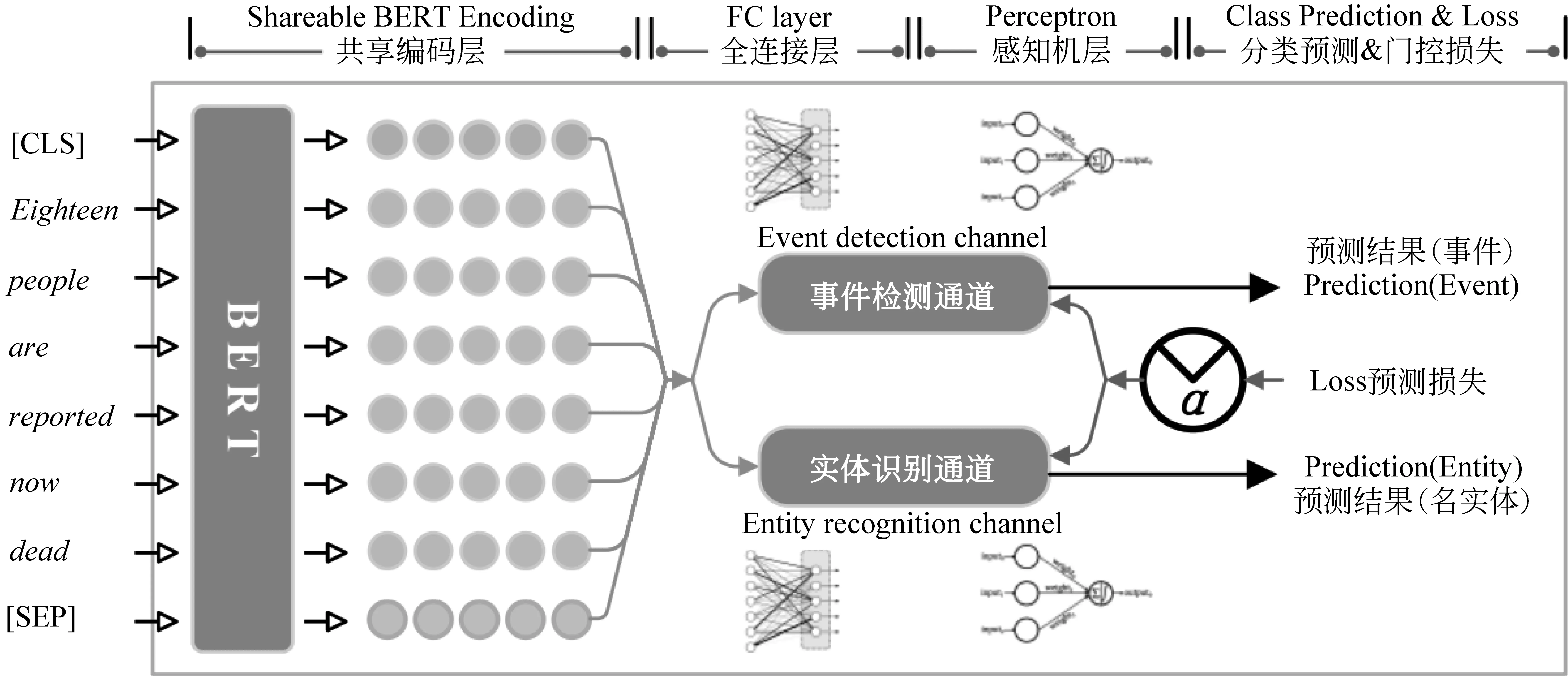
图1 模型总体框架图
本文遵循基于ACE2005的信息抽取系统的输入惯例,将句子作为输入。输出模式则取决于任务定义,在事件检测和实体识别任务中,词项的标记将被作为基本输出(标记包括触发词的类型和实体的类型),但在“事件提及”任务中,输出的是面向整句话的二元分类标记“是OR否”(“是”代表句子存在事件表述,即“提及”存在,否则不存在)。下文主要以事件抽取和实体识别两个任务为例,对MSBERT各个组成部分的表示和计算方法进行介绍,包括共享编码层、双通道输出层、预测与门控损失计算,以及相应的联合训练方法。“事件提及”任务作为辅助任务的计算方法与已有研究类似,实验部分将给出说明。
2.1 共享编码层
假设输入句子为W:W=(w1,w2,w3,…,wn),其中每个wi表示词项。本文将其组织为BERT的通用输入模式W′=[[CLS],W,[SEP]]。[CLS]是分类标识符,通过W中所有分布式表示向量加权求和得到,其包含了整体句子的语义信息,将用于“事件提及”任务中的编码结果。[SEP]是句子分割符,当BERT的输入为两句话时,起到分割作用。本文所有任务的输入均为一句话,因而[SEP]仅代表结束符。
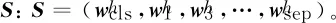
2.2 双通道输出层
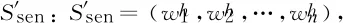
其中,FC为全连接层,不同任务所在的通道使用独立的全连接层,W和b表示全连接层的非线性变换参数,softmax代表对预测概率的归一化函数。P表示预测概率,argmax则表示从N个待预测类别中选择概率P最大的类型标记作为预测结果。ACE2005数据集约定了33类具体的事件类型,附加一种Non-trigger(即“非事件触发词”类),总计有34种(N=34)待测类别标记。此外,ACE2005数据集约定了44类具体的实体类型,同样地,附加“非实体”类之后,总计含有45种(N=45)待测类别标记。
2.3 动态门控损失函数
在 MSBERT的表示学习过程中,往往出现多任务学习效率参差不齐的现象。具体地,不同任务面对的正负例样本分布不均衡,例如,某条输入语句中也许出现多个实体(实体正例样本密集),却不含有事件触发词(语句中所有词项皆为Non-trigger负例),从而使MSBERT在逐条学习输入语句时,其各个任务的实际学习效率并不相同(一条任务通道快,另一条任务通道慢)。尤其,可供不同任务通道进行表示学习的样本总数也差异明显,ACE2005语料的标准训练集中,不同类型的事件触发词总计4 258项,实体总计48 513项。从而,每个批次的训练数据不能给予各个任务等量的正例进行学习,这一现象进一步影响了不同任务通道的学习效率。其导致的负面影响是,如果采用同等的预测损失驱动反向求参,高效学习的任务通道将把大量无关的损失附加在低效学习的任务通道之上,使得后者“超速”学习并偏离其真正的优化学习路线。
针对这一问题,本文定义了一种动态门控损失函数,其本身是对不同任务通道的损失进行加权求和,但扮演门控角色的权重被设定为动态可求解的参数,并令其在训练过程中根据每个通道每个训练批次实际损失的衰退梯度,实时改善下一次训练的损失计算。动态门控损失求解的具体方法如式(2)所示。

2.4 多任务联合训练
本文利用BERT微调(Finetune)[4]的方式进行模型训练,并采用已在大规模外部数据预训练好的BERT参数进行模型初始化,使之具有广域的语义知识计算能力。在训练过程中,梯度求解使用了上述动态门控损失计算方法,各个通道的预测损失采用交叉熵进行量化计算,如式(3)所示。
其中,P(yj|xi,θ)为模型预测第i个词表征第j种类型(事件类型或实体类型)的概率。θ表示模型的所有参数。G(yj)表示“零一”真值表征,如果yj为正解,则G(yj)为1,否则为0。k为分类目标的总类别数;n为句子的长度。
值得补充说明的是,本文实验额外考虑了“事件提及”识别任务,并将其与事件检测任务耦合,形成一套新的双通道多任务学习架构。该模型在训练过程中采用了两种损失计算方法,事件检测任务通道依然采用了式(3)中的交叉熵作为预测损失,而“事件提及”任务通道则使用了合页损失函数(Hinge Loss)。后者在判定是否存在“事件提及”的二分类任务上有着较好的表现。合页损失函数的计算方法如式(4)所示(其中,Δ为函数间隔):
3 实验与分析
3.1 语料、评价与超参设置
本文在ACE2005数据集上开展实验,并继承前人的数据集划分方式[20],将训练集、开发集和测试集的文本量划分为529、30和40篇(分别对应249 104、18 281和18 119个词项)。实验使用F1测度作为评价指标,F1为准确率P(precision)和召回率R(recall)的调和平均数。
实验使用的BERT模型为可调版本[4](BERT-based-uncased(1)https://github.com/google-research/bert),其隐含层大小(hidden size)设置为768,批量处理的词一级样本数(batch size)设置为8,学习率γ(learning rate)设置为1e-5,最大句子长度(max sequence length)设置为128。为了避免过拟合问题,在训练过程中,各层之间均加入退化处理(dropout),退化比率设置为0.1,合页损失函数的函数间隔Δ设置为1。
3.2 实验模型及对比对象
实验基于MSBERT架构形成了两个模型,其一是本文第2节重点讲解的事件检测和实体识别双通道模型(MSBERT+Entity),其二是耦合事件检测和“事件提及”识别的双通道模型(MSBERT+CLS)。两者都采用了双通道多任务架构和动态门控损失求解,且都以事件检测为主任务和评测对象。差别在于后者的辅助任务(“事件提及”识别)需要以整句的编码信息作为分类预测的基础。因此,该模型将BERT产生的[CLS]编码向量输入FC层和感知机进行预测,采用合页损失进行“事件提及”识别通道的损失计算。
此外,本文与现有前沿事件检测模型进行了性能对比。由于训练集、开发集和测试集皆一致,因此,本文仅摘录了相关工作报告的性能。
对比模型包括:
• Cross-Event(Liao et al.,2010)[5]利用句子级跨事件信息制造分类特征。
• Cross-Entity(Hong et al.,2011)[6]利用跨实体信息提升事件检测性能。
• MaxEntropy(Li et al.,2013)[7]将触发词识别和事件分类进行联合抽取,并融入全局特征。
上述三种方法皆为特征工程方法。
• DMCNN(Chen et al.,2015)[9]自动获取词级以及句子级特征,基于卷积神经网络的动态多池化,捕获句子级的上下文信息。
• JRNN(Nguyen et al.,2016)[10]在双向循环神经网络中加入人工特征。
• HNN(Feng et al.,2018)[22]将循环神经网络和卷积神经网络融合,以此捕获文本中的序列信息和块信息。
• Joint(Yang et al.,2016)[17]自动获取事件和事件的依赖关系,并采用文档级的事件和实体的联合抽取方法。
• dbRNN(Lei et al.,2018)[18]利用基于依赖桥的循环神经网络及句子中词语之间的依赖关系,进行事件和论元的联合抽取。
• AD-DMBERT(Wang et al.,2019)[23]利用对抗模型拓展训练语料。
• DRMM(Tong et al.,2020)[21]:利用注意力机制获取图片信息,融入到事件检测任务中。
表1给出了MSBERT与上述方法的性能对比。Cross-Event等传统基于特征的方法,对人工标注特征的依赖强,语义理解能力相对较弱。相比之下,RNN更容易捕获文本的时序信息,CNN更容易捕获文本的空间信息,融合RNN和CNN的混合神经网络(HNN),同时捕获文本的时序信息和空间信息,从而逐步提升了事件检测任务的性能。但是,ACE2005数据集本身存在规模小、数据不平衡的问题。dbRNN的多任务抽取方法通过共享模型参数,添加触发词间的依赖关系信息,达到较好的模型效果,在一定程度上缓解了这一问题。本文提出的MSBERT模型借助BERT克服了训练数据规模对语义学习效果的制约,同时多任务之间的交叉合作,使得语义表示学习趋向更为深入和可靠的信息。从而,MSBERT取得了总体上最优的性能。

表1 模型性能对比
其中,MSBERT+CLS(结合事件检测与“事件提及”识别的多任务模型)方法,相比于基线模型BERT(Ours)在触发词识别和事件类型分类的任务上F1值分别提高了0.4%和0.7%。MSBERT+Entity(事件检测与实体识别的多任务模型)在触发词识别任务和事件分类任务上均取得了最好的F1值。相比于基线模型BERT,F1值分别提高了1.1%和2.2%。分析发现,总体F1指标的提升,皆受益于召回率R值的大幅提升。该现象说明,MSBERT具有更广泛的语义感知能力,从而额外“捞回”了更多测试集中的OOV和OOL事件触发词。
在上述实验中,实体识别、“事件提及”识别都作为辅助任务,它们分别对提升事件检测任务的总体性能具有帮助作用。其引出一种可能的猜想,即将三个任务进行联合,形成三个通道的多任务学习模型,是否能够进一步提升事件检测性能。为此,本文搭建了基于三通道多任务架构的事件检测模型。然而,实验结果表明,该模型在触发词识别和事件分类上分别取得了77.5%和75.4%的F1值,其低于MSBERT+Entity得出的性能。尤其,即使增加三通道的动态门控机制也并未产生性能提升。由此可见,当任务量增加时,适用于少任务量的多任务方法并不一定能发挥积极效果,其不仅需要使用更健壮的模型以促进不同任务之间的相互影响,也需要用更好的协作机制来管理多重任务的损失差异。
3.3 门控机制的作用分析
如2.3节所述,本文采用了动态门控损失计算方法协助多任务模型的表示学习(训练过程),借以避免学习进度差异导致的“慢速通道超速学习”的弊端。实验检验了动态门控损失对模型性能的影响,如图2所示。其中,横坐标表示训练轮数,纵坐标表示事件检测任务以及实体识别任务的损失。图2(a)展示了不使用门控机制的情况下事件检测和实体识别任务的损失发展状态,即其随训练轮数增加的变化趋势;图2(b)展示了添加门控机制后两个任务损失的变化趋势。由图可见,在门控机制的作用下,两个任务的损失随着训练批次的增加,逐渐趋于一致。该现象说明双通道的表示学习步调逐渐趋近相同,符合门控损失计算的预期效果。

图2 门控机制的作用
表2展示了添加门控机制前后的事件检测性能,结果显示动态门控机制提升了事件检测任务的准确率,但召回率有所下降。结合图2损失的变化可知,动态门控机制通过协调损失,实际上加强了事件检测任务,使得模型能够更准确地做出判断,提升了准确率,但是同时也削弱了实体识别任务,导致模型学习不到更为宽泛的语义表示,召回率变低。

表2 添加门控机制的模型性能对比
3.4 多任务学习能力的可解释性分析1(饱和和半饱和训练的差异)
本节通过对比单任务模型和多任务模型的学习过程,详细分析了多任务学习性能优势的根本来源。其涉及一系列补充实验和量化分析。具体地,本文从训练集中随机选取25%的数据作为临时测试集(Hold-up set),并利用余下的数据继续作为训练集。补充实验将MSBERT(结合实体识别任务的MSBERT)和基线模型(基于BERT的单通道模型)作为考察对象,并将两者在上述训练集和临时测试集之上开展实验。实验采用的超参设置未变,与3.1节所提相同。
图3(a)展示了前20个批次(epochs)中每个批次训练之后,MSBERT和BERT在临时测试集上预测性能的变化趋势。在训练初期,BERT的学习速率远远大于MSBERT,在第4个批次结束就几乎达到了最高性能。而MSBERT的性能直到第9个批次才与BERT持平。在后续训练进程中,MSBERT和BERT的测试性能持平。上述现象说明,相比于认定单一目标的单任务模型,多任务模型同时学习两个任务的知识,需要更多的学习时间,导致单任务模型在训练初期的学习速率大于多任务模型。图3(b)展示了每个批次训练结束后,MSBERT和BERT在新测试集上预测结果不同的样本总量。如图所见,第一个批次因为模型的不同导致预测结果差异极大,并且是MSBERT和BERT差异最大的时刻。但之后,BERT和MSBERT的分歧越来越小,两者预测结果也随之趋于一致。这一现象说明,饱和训练极有可能使得多任务学习效果最终趋近单一任务的学习效果,使得多任务最终的性能优化并不明显。
此外,在第1~4个批次训练过程中,BERT和MSBERT的性能均处于迅速提升阶段(结合图3(a))。此时,虽然两者预测结果的差异波动大(结合图3(b)),但随即进入退化的趋势,两者的差异逐渐变小。该现象说明训练初期(1~4个批次),多任务学习过程不仅能够利用预训练BERT汲取广域的语义信息,同时也能不断学习自身任务涉及的特色语义信息,最大限度地发挥了多任务框架的优势。相比而言,单任务仅仅学习了独立任务涉及的语义信息,且在训练初期感知能力偏弱。从而,此时BERT和MSBERT的性能差距大,波动也较大。在第4~20个批次,结合图3(b)分析,BERT和MSBERT的预测结果差异在持续减小,其说明多任务的优势实际上正在不断削弱。如前所述,饱和训练的直接影响是“实际上拉动多任务学习更加趋近单任务学习的模式”,外部广域语义信息的利用率实际上被逐步降低。

图3 新测试集上MSBERT和BERT的实验结果
3.5 多任务学习能力的可解释性分析2(奇特的纠错器)
为了进一步探究多任务和单任务学习过程的不同,本文检验了MSBERT对BERT的纠错能力。图4(a)展示了BERT预测错误的所有样本数(包括错误判定的触发词和非触发词,图中由浅色柱状体表征),MSBERT预测正确的样本个数(嵌入式深色柱状体表征)及其分布(分布情况取自各个批次训练之后的多组纠错数)。图4(b)则用百分比简化了图4(a)的分布表示。如图所示,BERT产生的错误样本随着训练的持续,不断减少。同时多任务 MSBERT 的纠错能力(即BERT预测错误的样本中MSBERT能预测正确的纠错能力),在训练初期迅速增长到顶峰(第8个训练批次结束之后)并随之衰减。由3.4节可知,随着训练的推进,MSBERT和BERT的预测结果趋于一致,但在这个过程中,多任务模型的纠错能力反而下降了。由此可见,多任务模型在训练初期学到的知识和单任务模型并不相同,多任务模型学习到了更宽泛的语义知识,并且这部分知识能够纠正单任务模型的错误预测结果。然而,随着训练的进行,多任务模型逐渐与单任务模型的判断逐渐趋于一致,对单任务模型的纠错能力也在下降。

图4 BERT预测错误的样本中MSBERT预测正确的样本分布
进一步地,实验将预测样本分为触发词样本和非触发词样本,图5展示了在触发词样本上进行的纠错测试。根据图5(b)中的分布趋势可以发现,在触发词样本上,MSBERT对BERT的纠错能力呈现了相同的先降后升的变化趋势。该现象证明,多任务模型的总体性能优势得益于训练后期对触发词判断误差的纠错能力上。该现象也解释了MSBERT在召回率上更具优势的原因。
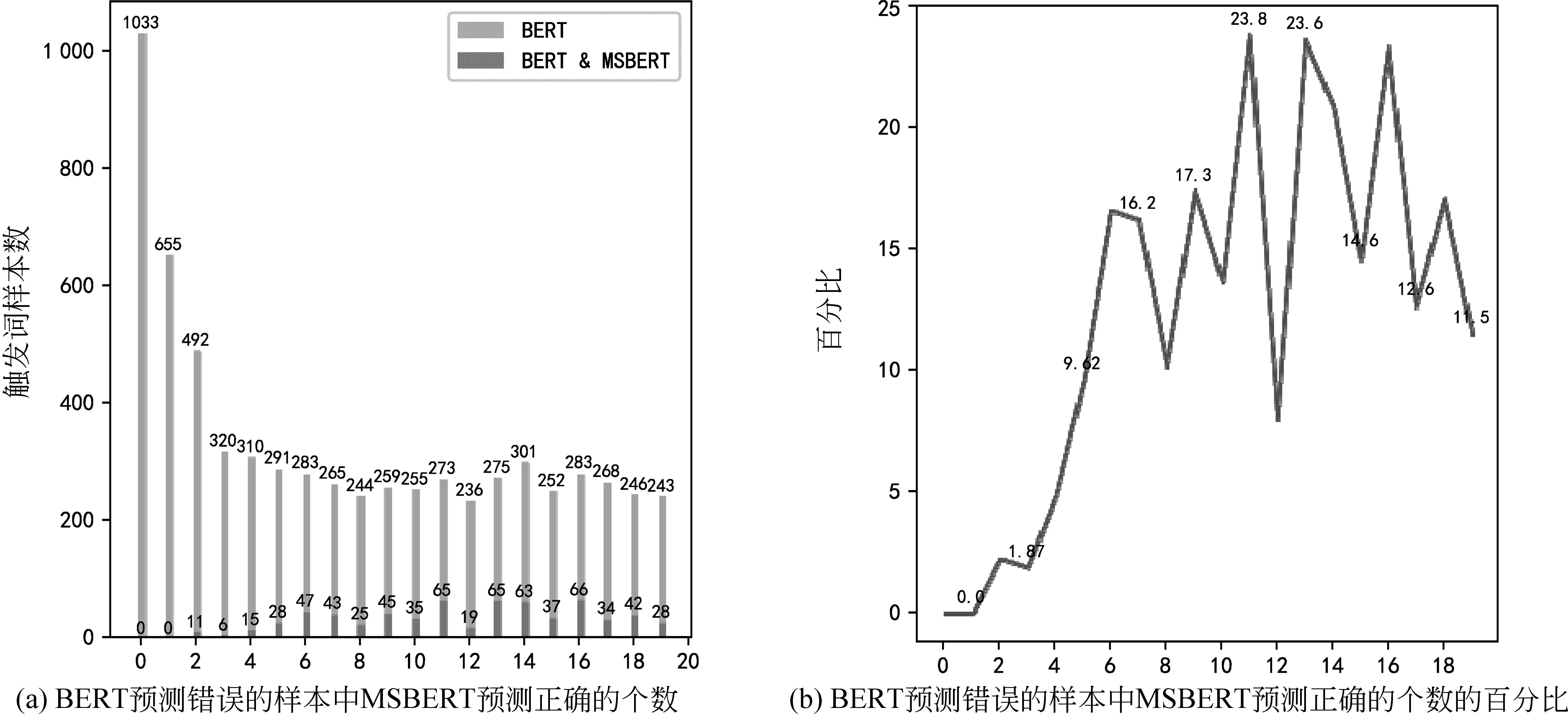
图5 BERT预测错误的触发词样本中MSBERT预测正确的触发词样本情况
结合3.4节的实验分析,本文认为:多任务在非饱和训练情况下有着更加区别于单任务的感知能力,其对非触发词的预测准确度更高,且源于预训练BERT提供的广域的语义知识;相对地,饱和训练情况下,多任务擅于召回触发词,但感知能力却愈加地近似于单任务模型。
4 总结与展望
本文提出一种基于BERT的多任务事件检测方法,其通过协调不同任务之间相互影响,学习共性知识并降低噪声。实验证明,该方法在ACE2005数据集上取得了明显的性能提升。针对多任务学习架构的可解释性实验分析显示,多任务模型相对于单任务模型的纠错优势先提高后下降,以及饱和训练对于发挥多任务框架的学习优势具有负面影响。基于上述发现,未来工作将研究新型的多任务学习机制,侧重将多任务和单任务的学习效率、纠错率和饱和度差异融入多任务学习的采样过程和损失计算之中。
