一种基于程序依赖图的代码聚类方法
2021-11-16刘志国王春晖
翟 晔, 刘志国, 王春晖
(1.内蒙古师范大学 计算机科学技术学院,内蒙古 呼和浩特 010022; 2.内蒙古师范大学 应用数学中心,内蒙古 呼和浩特 010022)
程序设计的学习一直是计算机科学及相关专业学习者面临的重大挑战,学生程序作业的批改和反馈需要花费教师大量的时间。随着MOOC教学方式在程序设计类课程的广泛应用,教师为每一位学生的程序作业给予及时反馈和答疑几乎已经成为不可能的事情。目前,现有的程序设计类辅助教学平台会根据测试用例检查程序的正确性,进而得到程序是否完全通过或部分通过测试的反馈。这些反馈信息对于学生调试程序和判断求解方法的正确性是非常有用的。然而,对于一些学生(特别是初学者),他们可能需要一些更细微的引导(如提供标准案例,或者找出错误)。
目前的代码分类方法主要基于代码相似性检测技术。代码相似度检测主要集中在两个方面:文本相似度检测和程序逻辑相似度检测。文本相似性将代码看成文本,一些学者采用TF-IDF建立文本特征[1-3],也有学者通过语义词权重法对文本进行分类和识别[4-5]。程序逻辑相似性[6]将代码转化为某种中间表示,然后量化相似性。一些研究者将代码表达成抽象语法树(AST)或检测程序依赖图(PDG),然后将动态文本匹配算法与后缀树算法相结合,对源文件中的相似代码进行编码[7]。有研究者将代码表示成函数调用图,从函数级别检测到源代码的相似性[8]。还有一些研究[9-10]根据内部操作指令的相似性确定了两个功能的相似性,并最终获得了两个应用程序的相似性。
本文提出一种基于程序依赖图(program dependence graph,PDG)的学生程序聚类方法。该方法针对求解同一问题的一组程序,表示和识别程序的结构特征,进一步采用聚类算法将求解方案相同的程序聚类,而将求解方案不相同的程序划分到不同的类。首先采用语法分析和语义分析技术将学生C程序代码转换成程序依赖图;然后提取结构特征,表达成特征向量;最后采用k-means聚类算法实现基于语义特征的程序聚类。本文针对一个统计求和的编程问题,对38个学生程序开展实验研究,结果表明该分类方法的有效性。
1 相关工作
1.1 程序依赖图
程序依赖图(PDG)一般以表达式语句(计算表达式或谓词表达式)为节点,节点之间的边代表节点计算表达所依赖的数据关系(数据依赖),或节点执行所依赖的控件关系(控制依赖)[11]。与其他代码表达形式(如源码、AST或控制流图CFG)相比,程序依赖图显示描述了程序语句及其关系,同时隐去对程序执行不产生影响的部分,蕴含了还原程序执行过程所必需的信息,具有更强的表达能力[12]。

表1 PDG中节点类型与对应语句Tab.1 Node types and corresponding sentences in PDG
本文程序依赖图的节点对应到程序中的某个基本语句,如声明语句、赋值语句等,还包含表达程序入口的入口节点。程序依赖图中每个节点都是有类型的,主要表达函数粒度的代码、表达的类型TV见表1。
程序依赖图中的边由程序节点之间的依赖关系确定。依赖关系主要有控制依赖与数据依赖。控制依赖描述程序语句执行过程产生的依赖关系,数据依赖描述程序语句对变量的使用与赋值时产生的数据流关系。
以“统计10以内加法”的编程问题为例,图1展示了其中求解该问题的一个源代码,该代码对应的程序依赖图。

图1 程序依赖图表示Fig.1 PDG representation
1.2 聚类技术
聚类是指对于一个给定集合的点(数据对象),把它们分成几个子集,其中每个子集称为一个组或类簇。一个类簇中的点彼此相似;不同的类簇的点彼此不相似。通常,点处在一个高维空间中,相似性可以使用欧式距离、余弦相似度等方法度量。
聚类方法是一种非监督的学习算法,不需要对输入数据进行标注。常用的聚类方法有基于划分的方法、基于层次分析方法、基于密度方法等。基于划分的方法使用相似度计算方法,将距离近的相似的点聚为一类,而类之间的点都相距较远,如k-means聚类算法。基于层次聚类的方法试图在不同层次对数据集进行划分,从而形成树型的聚类结构,如AGNES聚类算法。基于密度的聚类方法假设聚类结构可以通过样本分布的紧密程度确定,如DBSCAN密度聚类算法。
2 基于程序依赖图的代码聚类方法
本文以一组解决同一个问题的C程序作为输入,使用聚类方法将这些程序自动分成若干个子集,每个子集都被认为是语义上相似的代码。具体包括三个步骤,如图2所示。
(1) 生成程序依赖图: 将每个输入程序代码分别转换成其对应的程序依赖图表示。
(2) 提取关键特征: 读取程序依赖图的语句类型、关系类型等特征,使用特征向量表示每个程序依赖图。
(3) 程序聚类: 使用基于k-means的聚类算法,对一组程序聚类,得到k个聚类的子集。
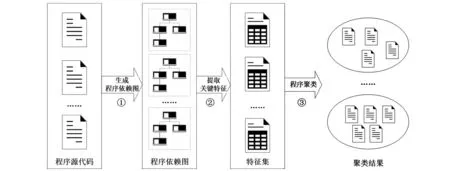
图2 基于聚类方法的代码分类Fig.2 Code classification flowchart based on clustering method
2.1 程序依赖图的自动生成
程序依赖图用点和边表达代码语义。点源自语句,边源自语句之间的关系。为得到程序依赖图,现有方法一般先得到代码的抽象语法树,然后进行控制流分析,得到控制流图(CFG)。随后,在控制流图的基础上,结合抽象语法树,进行数据流分析,进而得到程序依赖图[13-14]。主要步骤如下:
(1) 对程序进行预处理,包括: (a) 对特殊形式的语句(如++,+=)等进行规范化; (b) 将for循环等价替换成while循环; (c) 将声明并赋值的初始化语句拆分为声明语句和赋值语句; (d) 如果一条声明语句中同时声明多个变量,则拆分成每条声明语句仅声明一个变量; (e) 去掉注释和空行。
(2) 对程序代码进行词法、语法分析,获得程序对应的抽象语法树。
(3) 在抽象语法树上,进行控制流分析,获得程序对应的控制流图(CFG)。同时,为每一条程序语句生成一个节点,这些节点最终成为程序依赖图中的节点。
(4) 在CFG上,进行数据流分析。具体通过定义-使用分析与基于程序控制流的到达-定义分析,得到节点之间的数据依赖关系,将这些数据依赖关系添加到CFG上。
(5) 根据数据流分析结果,获得变量定义与使用的关系,进而得到声明依赖关系。
本文基于上述步骤,利用C程序分析的开源工具Pycparse作为词法分析工具,实现了一个将C语言源程序转换成依赖图的生成工具,以方便下一步的分类工作。
2.2 程序依赖图的特征


表2 程序依赖图特征信息及描述Tab.2 Features and description of PDG
为了得到一组程序依赖图的分类,具体包括两个关键问题需要解决,一是特征抽取,二是聚类方法实现。
2.2.1 程序依赖图特征选取与表示 参考基于Metric克隆代码检测方法中对特征的定义[15-16],从PDG中提取表征程序语义信息的特征。具体选取的特征信息见表2。
2.2.2 k-means聚类算法 k-means算法是典型的基于距离的非层次聚类方法,在最小化误差函数的基础上将数据划分为预定的类数K,采用距离作为相似性的评价指标,即认为两个实例的距离越近,其特征相似度就越大[17-18]。
算法输入为程序依赖图特征集合C,输出为簇的集合S。其中集合S={S1,S2,…,Sk},Si集合为第i个簇的集合,其簇心记为Pi。第t次迭代产生的簇的集合记为S(t) (t=0,1,2,…),算法过程如下:
(1) 初始化聚类的集合数k,并输入实例个数n值,输入程序依赖图特征集合C。
(2) 随机选择初始中心向量Pi,作为每个簇的中心点。
(3) 每个实例特征向量与每个簇的中心点向量计算距离值,并选择距离最小的分配到相应类中。
(4) 根据上一步的分类结果,计算对应类中的所有向量的平均值,取这个平均值作为簇的新中心点ki。
(5) 反复执行步骤(3)和(4),直到中心点不再发生改变,聚类完成。
根据算法的描述,k-means聚类算法的时间复杂度是O(nkt)。其中n为实例数量,k为聚类的个数,t是聚类过程迭代执行的次数。
3 实验与分析

图3 使用拐点法确定合适的K值Tab.3 Inflection point method to determine the appropriate K value
为验证分类方法的有效性,从一次学生C程序作业提交的源代码集合中选择38个程序,这些程序解决同一个编程任务,该编程任务的描述如下:
给定一个正整数K,计算一个最小的n,使得当n足够大的时,
Sn=1+1/2+1/3+…+1/n>k。
用本文提出的方法对这38个程序进行聚类。在k-mean算法中,需要设置参数k和迭代次数。将迭代次数iteration设为500。从k=2~10作为预先K值。使用拐点(inflection point)法确定合适的K值。如图3所示,该问题中,k=5为合适的K值。
为检查算法自动聚类的效果,用文献 [19]中提出的基于子类内部对(intra pair)的方法计算准确率和召回率。准确率表示算法反馈的正确分类的占比; 召回率表示算法反馈的人工确认正确分类的占比。

(1)
(2)
先对实验数据集中的38个程序进行人工分组。首先将这些程序分成5类,然后对聚类算法当k=5时的分类结果进行分析。结果发现,在一个聚类子集中有2个程序可以划分到另外两个子类中。最后计算准确率和召回率,结果分别是98%和87%。该结果表明自动分类算法对该程序代码集具有较好的分类效果。
4 结语
程序依赖图与其他表示程序的方法相比具有更明确的语义特征,是程序精确语义分析与相似性判别的常用方法。对于大量的具有相似语义的程序代码,根据程序依赖图语义进行代码分类对减少软件维护代价起重要作用。
本文结合自动化的程序依赖图生成、特征提取以及基于k-means的分类方法,对一组存在相似语义的代码集合进行聚类。结果表明,该方法能够实现基于程序依赖图的特征聚类。
程序依赖图在表达程序语义方法具有明确的信息,本文仅使用了部分特征信息。未来将在特征选取上开展深入研究,同时应用在更多数据集上,以实现更理想的分类效果。
